


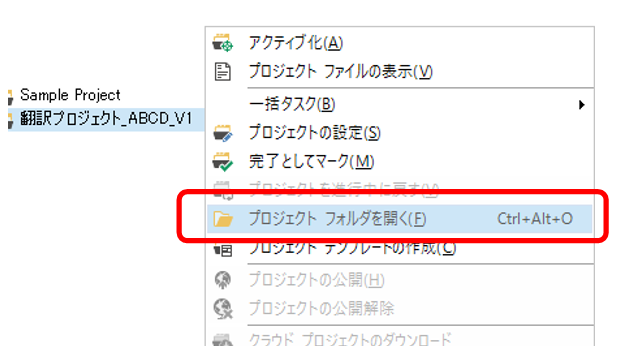
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
�L��
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
posted by fanblog
2024�N02��21��
IR �����̑O���㏑���|��� Trados �Ŋ撣��
���炭�u���O�̍X�V�����ڂ��Ă���Ԃ� IR (Investor Relations) �ƊE�̔ɖZ�������鎞���ɂȂ��Ă��܂��܂����B���͐��N�O�ɂ��̕���ɑ��ݓ��ꂽ�̂ł����A���̋ƊE�́u�ɖZ���v�Ƃ����� 5 �����̖Z�����́A�{���ɂ��̂������A�ŏ��̔N�͏Ռ����܂����B
IR (Investor Relations) �Ƃ́A�����Ƃւ̍L�����Ӗ����A�����Ƃ����ւ̃A�s�[���̂��߂ɂ��܂��܂ȕ����̖|�K�v�Ƃ���܂��B�����A�u�ɖZ���v���������Ȍ����͊��呍��̏��W�ʒm�⌈�Z���ł��B�������������́A���N�K�v�Ƃ���A��^�I�ȕ��������̂ŁACAT �c�[�����������Ɏv���̂ł����A�Ȃ������̕���ł͂��܂� CAT �c�[���̎g�p���L�܂��Ă��܂���B
�ŋ߂� Phrase ���g���Č�����������܂����A�قƂ�ǂ� Word �t�@�C���ł́u�O���㏑���v�|��ł��B�O���̌����A�����̌����A�O���̖A�Ƃ��� 3 �̃t�@�C��������A�O���̖ɍ����̍X�V�ӏ����㏑�����āA�����̖����������܂��B
����́A�O��̋L������� Trados ���G�f�B�^�[�Ƃ��� (�����ɂł�) �g�������̑� 2 �e�Ƃ��āAIR ����́u�O���㏑���v�|��� Trados ���g���čs�����@���Љ�܂��B�Љ�Ƃ����Ă��A����͎������s���낵�Ă���r���̂��̂ł��B���N�̔ɖZ����O�ɁA�����̒��ł̐����Ƃ��Ď菇���܂Ƃ߂Ă����������������ł��B���������I�ȕ��@������܂�����A���ЁA���ЁA���ЁA���ЁA�������������������ł��B


��������Ƃ����菇�́A�ȉ��̂Ƃ���ł��B
�@1. �����̃x�[�X�� Word �ō��
�@2. �Q�l����������ɓ����
�@3. �쐬���������t�@�C���� Trados �Ɏ�荞��
�@4. �|�I�������A�������� Word �ɖ߂�
�ł́A�ڂ������Ă����܂��傤�B
�������r���A�X�V�ӏ���ɔ��f����
�܂��A�O���ƍ����̌������r���A�ǂ����X�V���ꂽ�̂�����肵�܂��B�����āA�X�V���ꂽ�ӏ���������ɓ��{��̂܂ܔ��f���Ă����܂��B
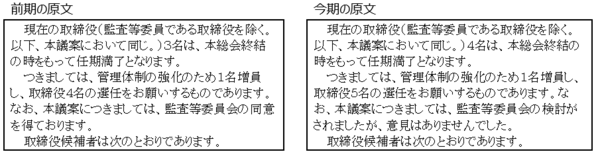
�ڌ��ł͂ǂ����X�V���ꂽ�̂��킩��ɂ����̂ŁA���� WinMerge �Ƃ����e�L�X�g��r�c�[�����g�p���čX�V�ӏ�����肵�Ă��܂��B (���� WinMerge �̑���� AutoHotkey ���g�p���Ă��܂����A����ɂ��ẮA�ȑO�̋L���u��������r���� �\ AutoHotKey �� WinMerge �� Trados �ƃ��r���[�v���Q�Ƃ��Ă��������B)
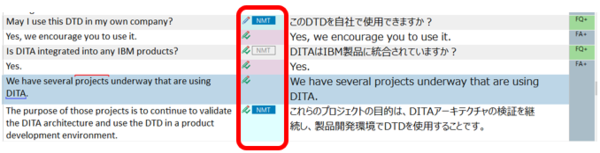
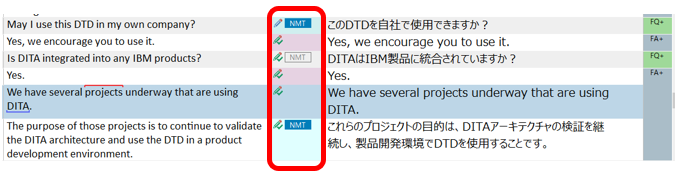
���̔�r���ʂ�����蓮�������̖�ύX���܂��B���������̕ύX�͂��̒i�K�ōς܂��܂����A�����̕ύX������ꍇ�́A���̒i�K�ł͖|���A�����̓��{������̂܂܃R�s�[���܂��B

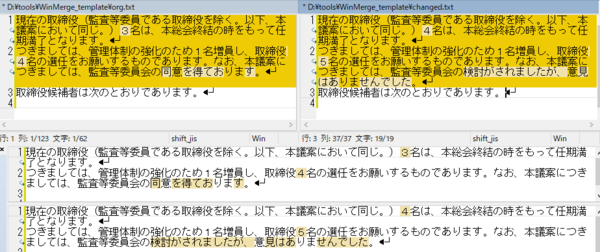
����́A�킩��₷�����邽�ߕύX�ӏ��ɐԐF��t���Ă��܂����A����͓��ɂ��̂悤�Ȏw�����Ȃ���Εs�v�ł��B�����A�������̂悤�Ȏw�����������ꍇ�́ATrados ��ŕҏW���Ă���Ƃ��ɐF��t����ꂽ�����֗��Ȃ̂ŁA��ɁA1) �S�̂����ŁA�ꕔ��Ԃ�����A2) �S�̂��ԂŁA�ꕔ����������A�Ƃ��� 2 �p�^�[���̏�����g�ݍ���ł����܂��B����ŁATrados �Ɏ�荞�Ƃ��ɁA���p�^�[���̃^�O����������܂��B
��L�̗�̏ꍇ�́A�����̕ύX�ӏ����u1) �S�̂����ŁA�ꕔ��Ԃ�����v�ɂ�����̂ŁA�u2) �S�̂��ԂŁA�ꕔ����������v�̃p�^�[���p�Ɉȉ��̂悤�ȃ_�~�[�̃e�L�X�g�����Ă����܂��B
�@�@�Ȃ��A�{�c�Ăɂ��܂��ẮA�č����ψ����̌���������܂������A�ӌ��͂���܂���ł����B
���C�A�E�g�𐮂���
���C�A�E�g�͂ł��邾�����O�Ɋ��������܂��B����ɖ������Ă���C��������@������܂����A���͎��O�ɐ����Ă����悤�ɂ��Ă��܂��B���O�ɐ����Ă����A�|�Ƀv���r���[�������Ƃ����K�ȃ��C�A�E�g�Ŗ��m�F�ł��܂��B
�E�t�H���g�̎�ނƑ傫��
���{�ꂪ�\������Ă��镔�����A���[�}���������������͂��Ă݂āA�p�����p�t�H���g���������ݒ肳��Ă��邱�Ƃ��m�F����B
�E�s��
���낢��ȕ�������R�s�[���Ă���̂ŁA�s�Ԃ�����������A�L�������肷�邱�Ƃ�����B�y�[�W�S�̂����Đ�����B
�E���� or ���[����
������A�R�s�[���̏������c��A���Ɨ��[���������݂��邱�Ƃ��悭����B
�E�C���f���g
�u1 �s�ڂ�������������v�Ƃ������[���̏ꍇ�́A�������Ȃ��� 2 �s�ɂȂ����ꍇ���l�����āA2 �s�ڈȍ~�̐ݒ�����Ă����B
�@�B�I�Ȓu���͂��Ȃ�
Word ��ł͋@�B�I�Ȓu���͂��܂���B�ꊇ�u���Ȃǂ̋@�B�I�ɂł��鑀��́A��������t�B���^�[���g���� Trados �ōs�����������I�ł��B�l����u���s�����v�Ƃ�������E���ȂǁA�J��Ԃ��o�ꂷ��\���͂��u���������Ȃ�܂����A���̏Փ��͂����ł͂����Ƃ������܂��B
���{��̂܂c���� Trados �Ɏ�荞��ł����A��� QA �`�F�b�N���s�����Ƃ��\�ɂȂ�̂ŁAWord ��Œu�����Ă��܂������S�ł��B���̒i�K�ł́A�����܂ŁA�`�}�`�}�Ǝ蓮�ōs��Ȃ���Ȃ�Ȃ���Ƃɐ�O���܂��B
��ƒ��Ɍ����������p��́A�������Ƃ��� Trados �Ɏ�荞�݂܂��B���́AExcel �őΖ�`���̃t�@�C�������A������u�o�C�����K�� Excel�v�Ƃ��� Trados �Ɏ�荞�݁A�������ɕϊ����܂��B�i���̕ӂ�̏ڍׂɂ��ẮA�����u���O�uExcel��|�����ɕϊ��v�A�܂��͎��̈ȑO�̋L���u���ՂɃo�C�����K�� Excel ���g���Ă��܂����v���Q�Ƃ��Ă��������B�j
�Ζ�t�@�C���̍쐬�ɂ� WildLight ��e�L�X�g �G�f�B�^�[���g��
�Ζ�t�@�C���̍쐬�͂Ȃ��Ȃ��ʓ|�ł����A�ߋ���̓��P�͕K�{�ł����A�Q�l�ƂȂ��͂ł��邾����������~�����̂ŁA�c�[���Ȃǂ��g���Ȃ���撣��܂��B�y�[�W�܂邲�ƂȂǁA������x�̗ʂ�����ꍇ�� WildLight ���֗��ł��B�����܂ŗʂ��Ȃ��ꍇ�́A��������e�L�X�g �G�f�B�^�[�ɓ\��t���A���s�̒lj���폜�����Ă��� Excel �ɓ\��t���܂��B(���̉��s�̏����Ȃǂ̂��߂ɁA���͏G�ۃG�f�B�^�[�Ƃ��̃}�N�����g���Ă��܂����A���̏ڍׂɂ��ẮA�ʂ̋@��ɏЉ�ł���Ǝv���܂��B)
�p��x�[�X�͎g�킸�A���ׂă������ɓo�^
���́A�l�����E���Ȃǂ̒Z���t���[�Y���A�ʓ|�Ȃ̂ŗp��x�[�X�͎g�킸�������ɓo�^���Ă��܂��܂��B�{���́A�p��x�[�X���쐬���ėp��F����L���ɂ���̂��x�X�g�ł����A�p��F���̓������̃t���O�����g��v�ł�������x��p�������܂��B�܂��A�Ζ�`���ɂ����Ȃ��Ă���AXbench �̌����@�\���g����̂ŁA�p��x�[�X�̍쐬�͏ȗ����Ă��܂��B
�Q�l��̃��������쐬���A�����̖̃x�[�X�����������炻�̃t�@�C���� Trados �Ɏ�荞�݂܂����A��荞�݂̑O�ɕ��ߋK���̐ݒ�����������ύX���܂��B
���������̋�_�ŕ��߂����Ȃ�
IR �̕����ł́A�ۂ������̒��ɋ�_ �i�B�j ���܂܂�Ă��邱�Ƃ��悭����܂��BTrados �̊���̐ݒ�ł́A�������̒��ł���_������ƕ��߂�����Ă��܂��̂ŁA���������Ȃ��悤�ɂ��܂��B
���Ƃ��A�ȉ��̂悤�Ȍ���������Ƃ��܂��B�ۂ������̒��ɋ�_������܂��B�������A1 �ڂ̕��ł͂���������d�ɂȂ��Ă��܂��B
������A����ݒ�̂܂�荞�ނƈȉ��̂悤�ɂȂ�܂��B��_�ŕ��߂�����Ă��܂��܂��B

���ߋK���̐ݒ��ς��邱�ƂŁA�ȉ��̂悤�ɁA��_�������Ă� 1 �̕��߂Ƃ��Ď�荞�߂܂��B����������d�ɂȂ��Ă��Ă����v�ł��B

���ߋK���̐ݒ�́A�������̌��ꃊ�\�[�X����s���܂��B�ݒ�̏ڍׂɂ��ẮA�����u���O�u�|�����̕��ߋK�����J�X�^�}�C�Y�����v���Q�Ƃ��Ă��������B���݂܂���A����͈ȉ��ɐ}���������A�ڂ��������͏ȗ����܂����A�����u���O�ɏ����Ă���Ƃ���ɐi�߂�Α��v�ł��B
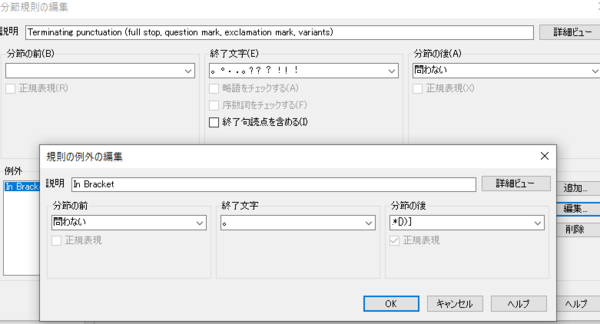
�p��ɂȂ��Ă��镔�������b�N����
���ߋK����ݒ肵�Č�������荞��A�|����J�n����O�ɁA���ɉp��ɂȂ��Ă��镔�������b�N���܂��B��������G���Ė�ύX���Ă��܂��ƍ���̂ŁA���͕K�����b�N���Ă��܂��B
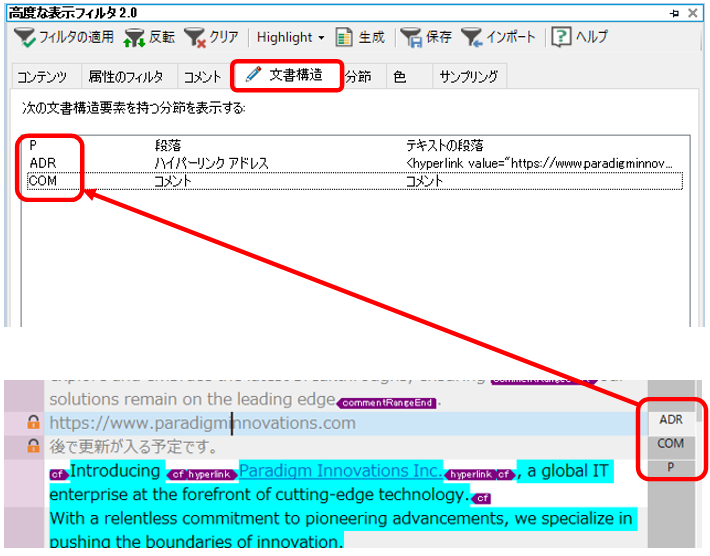
�u���ɉp��ɂȂ��Ă��镔���v�̒��o�ɂ́A���x�ȕ\���t�B���^�[���g���܂��B[�R���e���c] �^�u�� [����:] �ɉp�����A�J�[���[���p���A�~�L�����������K�\��
���̐ݒ�́A�E��� [�ۑ�] ���N���b�N����ƃt�@�C���Ƃ��ĕۑ��ł��܂��B�ۑ������t�@�C���́A���ׂ̗� [�C���|�[�g] ����ǂݍ��߂܂��B������g�������̓t�@�C���Ƃ��ĕۑ����Ă����ƕ֗��ł��B
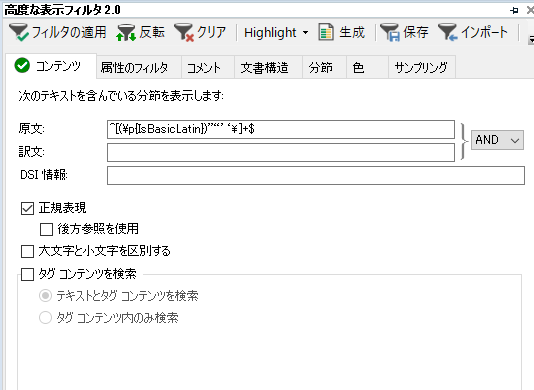
����Œ��o�������߂��A���ׂđI�����ă��b�N����Ί����ł��B���}�̂悤�ɁA���{�ꂪ�c���Ă��镔���̂ݕҏW�\�ȏ�ԂɂȂ��Ă���͂��ł��B���b�N�̓V���[�g�J�b�g �L�[ (Ctrl+Shift+L) �ŊȒP�ɃI���^�I�t���ł���̂ŁA�����ߕs��������Ύ蓮�Œ������܂��B

����Ŗ|��̏����͊����ł��B�������܂߂đS���� Trados �Ɏ�荞�ނƁA�����̕��߂͉p�p�̃y�A�ɂȂ��Ă��܂��܂����A����ł��p��ł̌����͉\�ɂȂ�̂ł��ƕ֗��ł��B
���Ȃ݂ɁA����̃T���v������������Ă��ď��߂ċC�t�����̂ł����A�s���I�h�ŕ��߂�����Ȃ��悤�ł��B����́A��������{��Ƃ��Ă���̂œ��{��̕��ߋK�����K�p����Ă��邩��A�Ǝv���܂����A���݂܂���A�����ł��B�s���I�h�ŋ��ꂽ�����t�B���^�[�Ȃǂ��g���Ƃ��ɕ֗��Ȃ̂ŁA���̓_�͗v���P�ł��B
�|������������������܂����A���̂Ƃ����ӂ���̂��R�����g�ł��BIR �̕����̂Ƃ��́A�\�����莖�����ׂ����L�����邱�Ƃ����߂���̂ŁA�R�����g�����Ȃ�d�v�ɂȂ�܂��B
�R�����g�̃��[�U�[����ύX����
Trados �œ��͂����R�����g�́A�������� Word �t�@�C���̃R�����g�Ƃ��ďo���ł��܂��B�����ŋC��t�������̂��R�����g�̍쐬�҂Ƃ��Đݒ肳��郆�[�U�[���ł��BTrados ��ł́A���̃��[�U�[���� Windows �̃��O�C����������Ɏg���Ă��܂��܂��BTrados �̖{�̂ɂ͂����ύX����ݒ肪�Ȃ��̂ŁA���� Trados Batch Anonymizer �Ƃ����A�v�����g���ă��[�U�[����ύX���Ă��܂��B���̃A�v���ɂ��ẮA�ȑO�̋L���u�R�����g�ɕ\������閼�O�̕ύX�v���Q�Ƃ��Ă��������B
�����������A�R�����g�̖��O���ύX������A�������s���܂��B����ŁATrados �ł̍�Ƃ͊����ł��B��́A���������t�@�C����ōŏI�I�Ȋm�F�����܂��B
����͈ȏ�ł��BTrados ���g�����ƂŌ������ǂ��Ȃ��Ă��邩�ǂ����͔�����������܂��A���͖|�̂��̂̍�ƂƂ���ȊO�̍�Ƃ�蕪����Ƃ����Ӗ��ł� Trados ���g���������悢�Ǝv���Ă��܂��B�X�V�ӏ��������Ȃ���A�|������āA���C�A�E�g�������āA�Ƃ��ׂĂ��ꏏ�ɂ���Ă����̂͂Ȃ��Ȃ���ςł��B��������A�X�V�ӏ���������Ƃ��͂��ꂾ���ɏW�����ATrados ��ł͂Ђ�����|������Ă����A�Ƃ����悤�ɍ�Ƃ��������i�߂₷�����ȂƎv���Ă��܂��B
���N���ɖZ��������Ă��܂����A�����ł������I�ɐi�߂���悤�A�w�߂Ă��������Ǝv���܂��B
IR (Investor Relations) �Ƃ́A�����Ƃւ̍L�����Ӗ����A�����Ƃ����ւ̃A�s�[���̂��߂ɂ��܂��܂ȕ����̖|�K�v�Ƃ���܂��B�����A�u�ɖZ���v���������Ȍ����͊��呍��̏��W�ʒm�⌈�Z���ł��B�������������́A���N�K�v�Ƃ���A��^�I�ȕ��������̂ŁACAT �c�[�����������Ɏv���̂ł����A�Ȃ������̕���ł͂��܂� CAT �c�[���̎g�p���L�܂��Ă��܂���B
�ŋ߂� Phrase ���g���Č�����������܂����A�قƂ�ǂ� Word �t�@�C���ł́u�O���㏑���v�|��ł��B�O���̌����A�����̌����A�O���̖A�Ƃ��� 3 �̃t�@�C��������A�O���̖ɍ����̍X�V�ӏ����㏑�����āA�����̖����������܂��B
����́A�O��̋L������� Trados ���G�f�B�^�[�Ƃ��� (�����ɂł�) �g�������̑� 2 �e�Ƃ��āAIR ����́u�O���㏑���v�|��� Trados ���g���čs�����@���Љ�܂��B�Љ�Ƃ����Ă��A����͎������s���낵�Ă���r���̂��̂ł��B���N�̔ɖZ����O�ɁA�����̒��ł̐����Ƃ��Ď菇���܂Ƃ߂Ă����������������ł��B���������I�ȕ��@������܂�����A���ЁA���ЁA���ЁA���ЁA�������������������ł��B


��������Ƃ����菇�́A�ȉ��̂Ƃ���ł��B
�@1. �����̃x�[�X�� Word �ō��
�@2. �Q�l����������ɓ����
�@3. �쐬���������t�@�C���� Trados �Ɏ�荞��
�@4. �|�I�������A�������� Word �ɖ߂�
�ł́A�ڂ������Ă����܂��傤�B
1. �����̃x�[�X�� Word �ō��
�������r���A�X�V�ӏ���ɔ��f����
�܂��A�O���ƍ����̌������r���A�ǂ����X�V���ꂽ�̂�����肵�܂��B�����āA�X�V���ꂽ�ӏ���������ɓ��{��̂܂ܔ��f���Ă����܂��B

�ڌ��ł͂ǂ����X�V���ꂽ�̂��킩��ɂ����̂ŁA���� WinMerge �Ƃ����e�L�X�g��r�c�[�����g�p���čX�V�ӏ�����肵�Ă��܂��B (���� WinMerge �̑���� AutoHotkey ���g�p���Ă��܂����A����ɂ��ẮA�ȑO�̋L���u��������r���� �\ AutoHotKey �� WinMerge �� Trados �ƃ��r���[�v���Q�Ƃ��Ă��������B)
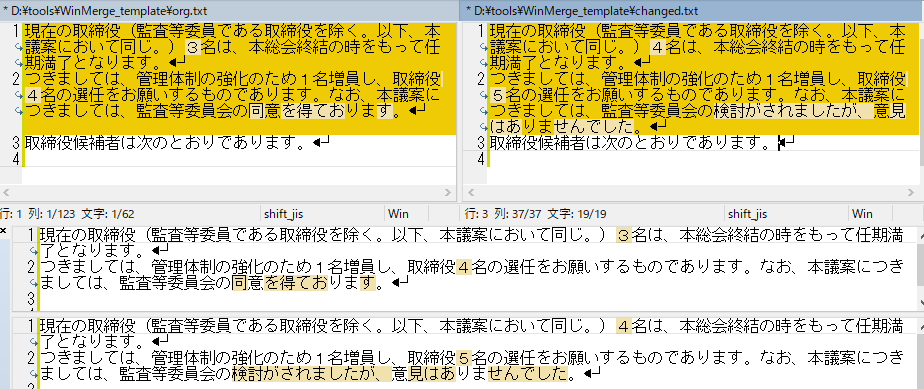
���̔�r���ʂ�����蓮�������̖�ύX���܂��B���������̕ύX�͂��̒i�K�ōς܂��܂����A�����̕ύX������ꍇ�́A���̒i�K�ł͖|���A�����̓��{������̂܂܃R�s�[���܂��B

����́A�킩��₷�����邽�ߕύX�ӏ��ɐԐF��t���Ă��܂����A����͓��ɂ��̂悤�Ȏw�����Ȃ���Εs�v�ł��B�����A�������̂悤�Ȏw�����������ꍇ�́ATrados ��ŕҏW���Ă���Ƃ��ɐF��t����ꂽ�����֗��Ȃ̂ŁA��ɁA1) �S�̂����ŁA�ꕔ��Ԃ�����A2) �S�̂��ԂŁA�ꕔ����������A�Ƃ��� 2 �p�^�[���̏�����g�ݍ���ł����܂��B����ŁATrados �Ɏ�荞�Ƃ��ɁA���p�^�[���̃^�O����������܂��B
��L�̗�̏ꍇ�́A�����̕ύX�ӏ����u1) �S�̂����ŁA�ꕔ��Ԃ�����v�ɂ�����̂ŁA�u2) �S�̂��ԂŁA�ꕔ����������v�̃p�^�[���p�Ɉȉ��̂悤�ȃ_�~�[�̃e�L�X�g�����Ă����܂��B
�@�@�Ȃ��A�{�c�Ăɂ��܂��ẮA�č����ψ����̌���������܂������A�ӌ��͂���܂���ł����B
���C�A�E�g�𐮂���
���C�A�E�g�͂ł��邾�����O�Ɋ��������܂��B����ɖ������Ă���C��������@������܂����A���͎��O�ɐ����Ă����悤�ɂ��Ă��܂��B���O�ɐ����Ă����A�|�Ƀv���r���[�������Ƃ����K�ȃ��C�A�E�g�Ŗ��m�F�ł��܂��B
�E�t�H���g�̎�ނƑ傫��
���{�ꂪ�\������Ă��镔�����A���[�}���������������͂��Ă݂āA�p�����p�t�H���g���������ݒ肳��Ă��邱�Ƃ��m�F����B
�E�s��
���낢��ȕ�������R�s�[���Ă���̂ŁA�s�Ԃ�����������A�L�������肷�邱�Ƃ�����B�y�[�W�S�̂����Đ�����B
�E���� or ���[����
������A�R�s�[���̏������c��A���Ɨ��[���������݂��邱�Ƃ��悭����B
�E�C���f���g
�u1 �s�ڂ�������������v�Ƃ������[���̏ꍇ�́A�������Ȃ��� 2 �s�ɂȂ����ꍇ���l�����āA2 �s�ڈȍ~�̐ݒ�����Ă����B
�@�B�I�Ȓu���͂��Ȃ�
Word ��ł͋@�B�I�Ȓu���͂��܂���B�ꊇ�u���Ȃǂ̋@�B�I�ɂł��鑀��́A��������t�B���^�[���g���� Trados �ōs�����������I�ł��B�l����u���s�����v�Ƃ�������E���ȂǁA�J��Ԃ��o�ꂷ��\���͂��u���������Ȃ�܂����A���̏Փ��͂����ł͂����Ƃ������܂��B
���{��̂܂c���� Trados �Ɏ�荞��ł����A��� QA �`�F�b�N���s�����Ƃ��\�ɂȂ�̂ŁAWord ��Œu�����Ă��܂������S�ł��B���̒i�K�ł́A�����܂ŁA�`�}�`�}�Ǝ蓮�ōs��Ȃ���Ȃ�Ȃ���Ƃɐ�O���܂��B
2. �Q�l����������ɓ����
��ƒ��Ɍ����������p��́A�������Ƃ��� Trados �Ɏ�荞�݂܂��B���́AExcel �őΖ�`���̃t�@�C�������A������u�o�C�����K�� Excel�v�Ƃ��� Trados �Ɏ�荞�݁A�������ɕϊ����܂��B�i���̕ӂ�̏ڍׂɂ��ẮA�����u���O�uExcel��|�����ɕϊ��v�A�܂��͎��̈ȑO�̋L���u���ՂɃo�C�����K�� Excel ���g���Ă��܂����v���Q�Ƃ��Ă��������B�j
�Ζ�t�@�C���̍쐬�ɂ� WildLight ��e�L�X�g �G�f�B�^�[���g��
�Ζ�t�@�C���̍쐬�͂Ȃ��Ȃ��ʓ|�ł����A�ߋ���̓��P�͕K�{�ł����A�Q�l�ƂȂ��͂ł��邾����������~�����̂ŁA�c�[���Ȃǂ��g���Ȃ���撣��܂��B�y�[�W�܂邲�ƂȂǁA������x�̗ʂ�����ꍇ�� WildLight ���֗��ł��B�����܂ŗʂ��Ȃ��ꍇ�́A��������e�L�X�g �G�f�B�^�[�ɓ\��t���A���s�̒lj���폜�����Ă��� Excel �ɓ\��t���܂��B(���̉��s�̏����Ȃǂ̂��߂ɁA���͏G�ۃG�f�B�^�[�Ƃ��̃}�N�����g���Ă��܂����A���̏ڍׂɂ��ẮA�ʂ̋@��ɏЉ�ł���Ǝv���܂��B)
�p��x�[�X�͎g�킸�A���ׂă������ɓo�^
���́A�l�����E���Ȃǂ̒Z���t���[�Y���A�ʓ|�Ȃ̂ŗp��x�[�X�͎g�킸�������ɓo�^���Ă��܂��܂��B�{���́A�p��x�[�X���쐬���ėp��F����L���ɂ���̂��x�X�g�ł����A�p��F���̓������̃t���O�����g��v�ł�������x��p�������܂��B�܂��A�Ζ�`���ɂ����Ȃ��Ă���AXbench �̌����@�\���g����̂ŁA�p��x�[�X�̍쐬�͏ȗ����Ă��܂��B
3. �쐬���������t�@�C���� Trados �Ɏ�荞��
�Q�l��̃��������쐬���A�����̖̃x�[�X�����������炻�̃t�@�C���� Trados �Ɏ�荞�݂܂����A��荞�݂̑O�ɕ��ߋK���̐ݒ�����������ύX���܂��B
���������̋�_�ŕ��߂����Ȃ�
IR �̕����ł́A�ۂ������̒��ɋ�_ �i�B�j ���܂܂�Ă��邱�Ƃ��悭����܂��BTrados �̊���̐ݒ�ł́A�������̒��ł���_������ƕ��߂�����Ă��܂��̂ŁA���������Ȃ��悤�ɂ��܂��B
���Ƃ��A�ȉ��̂悤�Ȍ���������Ƃ��܂��B�ۂ������̒��ɋ�_������܂��B�������A1 �ڂ̕��ł͂���������d�ɂȂ��Ă��܂��B
- �z�������i��ЈȊO�̎҂Ƃ̍����i���Y�����㓖�Y������Ђ�����������̂Ɍ��顁j���܂ޡ�j���͋z�������ɂ�鑼�̖@�l���̎��ƂɊւ��錠���`���̏��p
- ���̉�Ёi�O����Ђ��܂ޡ�j�̊������̑��̎������͐V���\���̎擾���͏���
������A����ݒ�̂܂�荞�ނƈȉ��̂悤�ɂȂ�܂��B��_�ŕ��߂�����Ă��܂��܂��B

���ߋK���̐ݒ��ς��邱�ƂŁA�ȉ��̂悤�ɁA��_�������Ă� 1 �̕��߂Ƃ��Ď�荞�߂܂��B����������d�ɂȂ��Ă��Ă����v�ł��B

���ߋK���̐ݒ�́A�������̌��ꃊ�\�[�X����s���܂��B�ݒ�̏ڍׂɂ��ẮA�����u���O�u�|�����̕��ߋK�����J�X�^�}�C�Y�����v���Q�Ƃ��Ă��������B���݂܂���A����͈ȉ��ɐ}���������A�ڂ��������͏ȗ����܂����A�����u���O�ɏ����Ă���Ƃ���ɐi�߂�Α��v�ł��B
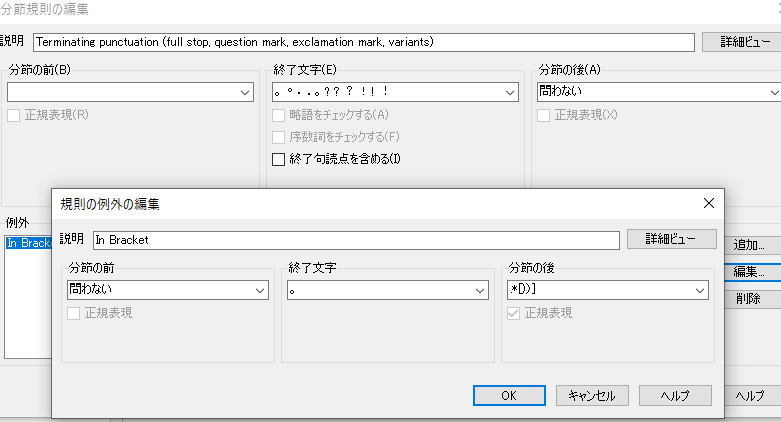
�p��ɂȂ��Ă��镔�������b�N����
���ߋK����ݒ肵�Č�������荞��A�|����J�n����O�ɁA���ɉp��ɂȂ��Ă��镔�������b�N���܂��B��������G���Ė�ύX���Ă��܂��ƍ���̂ŁA���͕K�����b�N���Ă��܂��B
�u���ɉp��ɂȂ��Ă��镔���v�̒��o�ɂ́A���x�ȕ\���t�B���^�[���g���܂��B[�R���e���c] �^�u�� [����:] �ɉp�����A�J�[���[���p���A�~�L�����������K�\��
^[(\p{IsBasicLatin})�h�g�f�e\]+$ ���w�肵�A[���K�\��] �`�F�b�N�{�b�N�X���I���ɂ��܂��B���̐ݒ�́A�E��� [�ۑ�] ���N���b�N����ƃt�@�C���Ƃ��ĕۑ��ł��܂��B�ۑ������t�@�C���́A���ׂ̗� [�C���|�[�g] ����ǂݍ��߂܂��B������g�������̓t�@�C���Ƃ��ĕۑ����Ă����ƕ֗��ł��B

����Œ��o�������߂��A���ׂđI�����ă��b�N����Ί����ł��B���}�̂悤�ɁA���{�ꂪ�c���Ă��镔���̂ݕҏW�\�ȏ�ԂɂȂ��Ă���͂��ł��B���b�N�̓V���[�g�J�b�g �L�[ (Ctrl+Shift+L) �ŊȒP�ɃI���^�I�t���ł���̂ŁA�����ߕs��������Ύ蓮�Œ������܂��B

����Ŗ|��̏����͊����ł��B�������܂߂đS���� Trados �Ɏ�荞�ނƁA�����̕��߂͉p�p�̃y�A�ɂȂ��Ă��܂��܂����A����ł��p��ł̌����͉\�ɂȂ�̂ł��ƕ֗��ł��B
���Ȃ݂ɁA����̃T���v������������Ă��ď��߂ċC�t�����̂ł����A�s���I�h�ŕ��߂�����Ȃ��悤�ł��B����́A��������{��Ƃ��Ă���̂œ��{��̕��ߋK�����K�p����Ă��邩��A�Ǝv���܂����A���݂܂���A�����ł��B�s���I�h�ŋ��ꂽ�����t�B���^�[�Ȃǂ��g���Ƃ��ɕ֗��Ȃ̂ŁA���̓_�͗v���P�ł��B
4. �������� Word �ɖ߂�
�|������������������܂����A���̂Ƃ����ӂ���̂��R�����g�ł��BIR �̕����̂Ƃ��́A�\�����莖�����ׂ����L�����邱�Ƃ����߂���̂ŁA�R�����g�����Ȃ�d�v�ɂȂ�܂��B
�R�����g�̃��[�U�[����ύX����
Trados �œ��͂����R�����g�́A�������� Word �t�@�C���̃R�����g�Ƃ��ďo���ł��܂��B�����ŋC��t�������̂��R�����g�̍쐬�҂Ƃ��Đݒ肳��郆�[�U�[���ł��BTrados ��ł́A���̃��[�U�[���� Windows �̃��O�C����������Ɏg���Ă��܂��܂��BTrados �̖{�̂ɂ͂����ύX����ݒ肪�Ȃ��̂ŁA���� Trados Batch Anonymizer �Ƃ����A�v�����g���ă��[�U�[����ύX���Ă��܂��B���̃A�v���ɂ��ẮA�ȑO�̋L���u�R�����g�ɕ\������閼�O�̕ύX�v���Q�Ƃ��Ă��������B
�����������A�R�����g�̖��O���ύX������A�������s���܂��B����ŁATrados �ł̍�Ƃ͊����ł��B��́A���������t�@�C����ōŏI�I�Ȋm�F�����܂��B
����͈ȏ�ł��BTrados ���g�����ƂŌ������ǂ��Ȃ��Ă��邩�ǂ����͔�����������܂��A���͖|�̂��̂̍�ƂƂ���ȊO�̍�Ƃ�蕪����Ƃ����Ӗ��ł� Trados ���g���������悢�Ǝv���Ă��܂��B�X�V�ӏ��������Ȃ���A�|������āA���C�A�E�g�������āA�Ƃ��ׂĂ��ꏏ�ɂ���Ă����̂͂Ȃ��Ȃ���ςł��B��������A�X�V�ӏ���������Ƃ��͂��ꂾ���ɏW�����ATrados ��ł͂Ђ�����|������Ă����A�Ƃ����悤�ɍ�Ƃ��������i�߂₷�����ȂƎv���Ă��܂��B
���N���ɖZ��������Ă��܂����A�����ł������I�ɐi�߂���悤�A�w�߂Ă��������Ǝv���܂��B
| �@�@ |
�^�O�F Trados Batch Anonymizer ���x�ȕ\���t�B���^ �R�����g�̃��[�U�[�� �o�C�����K�� Excel �R�����g �㏑���|�� WinMerge
Tweet
2023�N12��18��
Trados ���G�f�B�^�[�Ƃ��Ďg�����߂�
�����ԋv���Ԃ�̍X�V�ƂȂ�܂����B���N�́A���낢��ƖZ�����߂����Ă��邤���ɂ����Ƃ����ԂɎ��Ԃ������A���܂�u���O���X�V�ł��܂���ł����B���A���́A�����̓���ւ��Ȃǂ�����A���N���� Trados �̎g�p�p�x���������ƂɂȂ�܂����I ���̐[�� (�ł̐[���H) Trados �ɂǂ��Ղ�Ƃ͂܂��Ă��������Ȋ����ł��B
���āATrados �Ȃǂ� CAT �c�[���̋@�\�Ƃ����A�|���� (Translation Memory�A������ TM) ����\�I�ł����ACAT �c�[���̋@�\�͂��ꂾ���ł͂���܂���B����������؎g��Ȃ��ꍇ�ł��A���܂��܂ȗ��p���l������܂��B���̏ꍇ�ATrados �̎�ȗp�r�́u�G�f�B�^�[�v�ł��B�����ł��B�P�Ȃ�G�f�B�^�[�ł��BWord ���A�e�L�X�g �G�f�B�^�[���A�|���Ƃŕ�������͂���Ȃ� Trados �������I�ł��B�����Ɩ����ŎQ�Ƃł���A�����Ɩ̂ǂ��炩��ł������ł���A���͕⏕�@�\���g�p�ł���A�^�O�������ł���A�Ȃǖ|���ƂɌ������Ȃ��@�\���ŏ����������Ă��܂��B
�������AWord ��e�L�X�g �G�f�B�^�[���A�}�N���ȂǂŃJ�X�^�}�C�Y����Α����֗��Ɏg����Ǝv���܂��B�������A�|����n�߂��������� CAT �c�[�����g���Ă������̏ꍇ�A���̃G�f�B�^�[�̃}�N���Ȃǂ��ATrados �̕�������Ă��܂��B�܂��A�����u����Ă���v�Ƃ������R�����Ŏg�������邱�Ƃ��ǂ��Ƃ͎v���Ă��܂��A���̂Ƃ���킴�킴���̃G�f�B�^�[�ɕς���قǂ̗��R������܂���B
�Ƃ����킯�ŁA���́AWord �t�@�C���Ȃǂ�n����āu�㏑���|��Łv�ƈ˗�����Ă��A�ł��邾�� Trados ���g���悤�ɂ��Ă��܂��B�����A���������Č��́A�����Ŗ����܂ōs���Č��̃t�@�C���`���Ŕ[�i����K�v������̂ŁA��ƑO�ɕK���u�ȒP�Ɍ��̏�Ԃɖ߂��邩�v���m�F���܂��B
���̊m�F�̃|�C���g�́u�ȒP�Ɂv�ł��BTrados �֗̕����ƁA���̃t�@�C���ɖ߂��Ƃ��̎�Ԃ��r���āA�������t�@�C���ɖ߂���Ԃ̕����傫���Ȃ�悤�ł���A�f���Ɂu�㏑���|��v��������܂���B���̂��߁ATrados ���G�f�B�^�[�Ƃ��Ďg�������̂Ȃ�A���t�@�C���ɖ߂��Ƃ��̎�Ԃ��ł��邾�����Ȃ�����K�v������܂��B
����́AWord �t�@�C���Œi�����Ƃ̕��L���˗����ꂽ�ꍇ���Ɂu�ȒP�Ɂv���t�@�C���ɖ߂����߂Ɏg�������ȏ��Z���Љ�܂��B�����܂Łu���Z�v�ł��B�i�����Ƃ̕��L�Ƃ����`���� Trados �Ńp�b�Ɛ����ł���킯�ł͂���܂���B��{�I�ɂ͎蓮�ł̍�ƂɂȂ�܂��B
�ł́A�ȉ��̂悤�� Word �t�@�C����i�����Ƃɉp�����L�Ŗ|�Ă��������Ǝw�����ꂽ�Ƃ��܂��B���̃t�@�C���́A�������ۂɈ˗����ꂽ�t�@�C������ɍ�����T���v���ł��B���ڂ��ׂ��_�́A���͓��Ƀ����N�����邱�ƂƁA�R�����g���t���Ă��邱�Ƃł��B

�܂��́A�i�����ƂɃR�s�y���ĕ��L�̌`�ɂ��A����͂��鑤�Ƀn�C���C�g��t���܂��B���݂܂���A�ł��ʓ|�Ȃ��̍�Ƃ͎蓮�ōs���܂��B(�����A���\�y�[�W������悤�ȑ傫�ȃt�@�C���������玩�������l���܂����A������������Ȉ˗������Ă���t�@�C���� 1 �` 2 �y�[�W���x�̂��̂������̂ŁA�Ƃ肠�����A�蓮�ł����܂��B)

���̗�ł́A�ƂȂ镔���ւ̃}�[�L���O�Ƃ��ăn�C���C�g���g���Ă��܂��B���̃}�[�L���O�́A���̌� Trados ��Ō����Ɩ���ʂ��邽�߂Ɏg���܂��B�}�[�L���O�͍ŏI�I�ɖ�����������ō폜����K�v������̂ŁA���܂��폜�ł������Ȃ��̂��g���K�v������܂��BTrados �̓��삩��l����ƁA�n�C���C�g�ȊO�ɁA�����̐F���}�[�L���O�Ƃ��Ďg�p�ł��܂��B
����̃t�@�C���Ń}�[�L���O�Ƀn�C���C�g��I�̂́A���͓��Ƀ����N������������ł��B�����N�̕����ɈقȂ�F���g���Ă���̂ŁA�}�[�L���O�Ƃ��ĕ����̐F���g���ƁA��Ŗ߂��Ƃ��Ƀ����N�̕��������ʂɐF��ς��Ȃ���Ȃ�Ȃ����ƂɂȂ�܂��B�t�ɁA�����Ƀn�C���C�g���g���Ă�����A�}�[�L���O�ɂ͕����̐F���g���܂��B�����������g���Ă�����A�ʓ|�ł����A�ʂ̐F�̃n�C���C�g���g���A�Ƃ��ł����ˁB���̓s�x�A�����ɍ��킹�ēK���ɍl���܂��B
Word �t�@�C����ŕ��L�̌`�������������� Trados �Ɏ�荞�݂܂����A���̑O�ɂЂƂ����ݒ�����܂��B����̌����ɂ̓R�����g���t���Ă���̂ŁA���̃R�����g�� Trados �Ɏ�荞�ނ悤�ɂ��܂��B�R�����g��K�v���Ȃ��Ƃ��Ă��ATrados �Ɏ�荞��ł����Ȃ��ƁA�������Ăł�������t�@�C���ŃR�����g�������Ă��܂��܂��B
�R�����g����荞�ސݒ�́u�t�@�C���̎�ށv�ōs���܂��B�v���W�F�N�g���쐬����O��������A[�t�@�C��] > [�I�v�V����] > [�t�@�C���̎��] > [Microsoft Word 2007-2019] > [�S�ʐݒ�] �ł��B�v���W�F�N�g���쐬������Őݒ��ς���ꍇ�́A���̃v���W�F�N�g�� [�v���W�F�N�g�̐ݒ�] > [�t�@�C���̎��] �ł��B(���� 2 �̐ݒ�̈Ⴂ�ɂ��ẮA�ȑO�̋L���uTrados �̐ݒ��ς���ɂ� �| [�t�@�C��] �� [�v���W�F�N�g�̐ݒ�]�v���Q�Ƃ��Ă��������B)
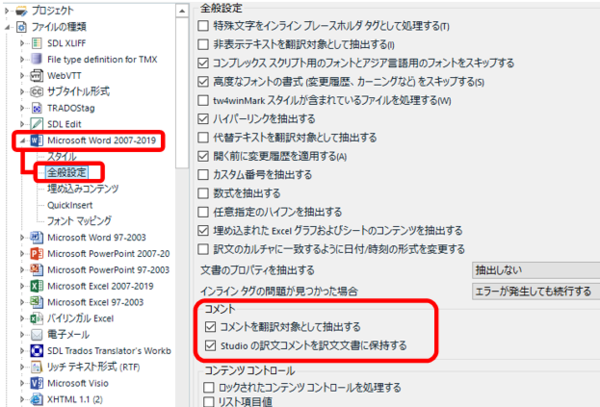
��}�̂悤�ɁA[�R�����g] �� [�R�����g��|��ΏۂƂ��Ē��o����] �`�F�b�N�{�b�N�X���I���ɂ���ƁA�����t�@�C���ɂ���R�����g�� Trados �Ɏ�荞�ނ��Ƃ��ł��܂��B�����Ŏ�荞��ł����A���������Ƃ��ɂ��̂܂܃R�����g���o�͂���܂��B
���̉��� [Studio �̖R�����g������ɕێ�����] �́ATrados ��ŋL�������R�����g����������t�@�C���ɏo�͂��邩�ǂ����̐ݒ�ł��B�`�F�b�N�{�b�N�X���I���ɂ���ƁA�R�����g���o�͂���܂��B
���̐ݒ肪����������ATrados �Ƀt�@�C������荞�݂܂��B���̐ݒ�������Ɏ�荞��ł��܂����ꍇ�́A�������̃t�@�C���͍폜���A�ݒ��ς��Ă�����߂Ď�荞�ݒ����܂��B���̐ݒ�́A��荞�ޑO�ɍs���K�v������܂��B�ォ��ݒ��ς��Ă��A�R�����g�͎�荞�܂�܂���B
Trados �Ńt�@�C�����J���ƁA�ȉ��̂悤�ɂȂ�܂��B���}�́A�S���߂ɂ��Č�����ɃR�s�[������̏�Ԃł��B�^�O�ƃn�C���C�g�̐F���\������Ă���̂́A[�G�f�B�^] �� [�����̕\���X�^�C��] �� [���ׂĂ̏����ƃ^�O��\������] ��I�����Ă��邩��ł� (�ڂ����́A�ȑO�̋L���u�G�f�B�^��̃t�H���g��ς����v���Q�Ƃ��Ă�������)�B�^�̃X�e�[�^�X�̗����F�ɂȂ��Ă���̂́A�������R�s�[�����Ƃ��̐F��ݒ肵�Ă��邩��ł� (�ڂ����́A�ȑO�̋L���u�{���Ɍ�������R�s�[�����܂܂��H�v���Q�Ƃ��Ă�������)�B
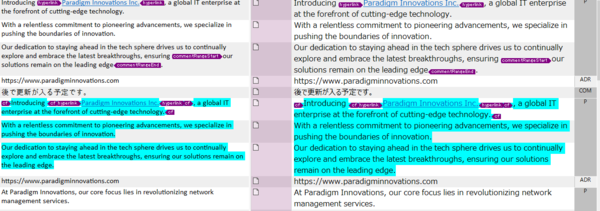
������ɃR�s�[������A�|���Ƃ�����ȊO�̕��߂����b�N���܂��B�Ԉ���ĕҏW���Ă��܂��ƍ���̂ŁA�K�����b�N���܂��B���b�N����ӏ��́A���L�`���̌����ɂ����镔���ƁA���X�����ɓ����Ă����R�����g�ł��B
�n�C���C�g���t���Ă��Ȃ����߂����b�N����
����ɂ́A�u���x�ȕ\���t�B���^ 2.0�v���g���܂��B[�F] �^�u�Ń}�[�L���O�Ɏg�����F��I�����A�㕔�� [���]] �{�^�����N���b�N���܂��B
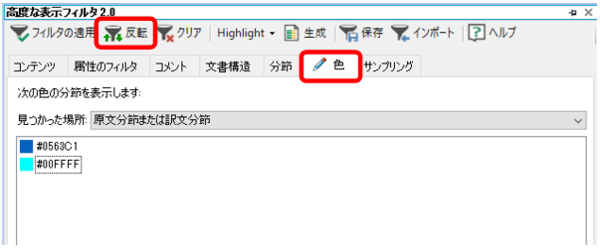
[�F] �^�u�̃��X�g�ɂ́A�n�C���C�g�╶���Ȃǂ̐F�������I�ɕ\������Ă��܂��B���ۂɂǂ̗v�f�̐F���\������Ă���̂��͂悭�킩��܂��A�n�C���C�g�ƕ����̐F�͕\������Ă��܂��B�ł��̂ŁA�Ԏ��̕����̂ݕ\������A�Ƃ�����������\�ł��B[���]] �{�^���́A�I�������F���܂܂�镪�߁g�ȊO�h�𒊏o���邽�߂Ɏg���܂��B�܂�A[���]] �{�^�����g�����ƂŁu�n�C���C�g���t���Ă��Ȃ��v���߂𒊏o�ł��܂��B
�n�C���C�g���t���Ă��Ȃ����߂𒊏o������A���̕��߂����ׂđI�����Ă��̂܂܃��b�N���܂��B����ŁA�]�v�ȕ���������ĕҏW���Ă��܂��S�z���Ȃ��Ȃ�܂��B(���}�́A�X�e�[�^�X�� [�|�F�ς�] �ɕύX���Ă��烍�b�N���Ă��܂��B�X�e�[�^�X�̕ύX�͔C�ӂł����A�|�镔���ȊO��ʂ̃X�e�[�^�X�ɂ��Ă����Ɖ����ƕ֗��ł��B)
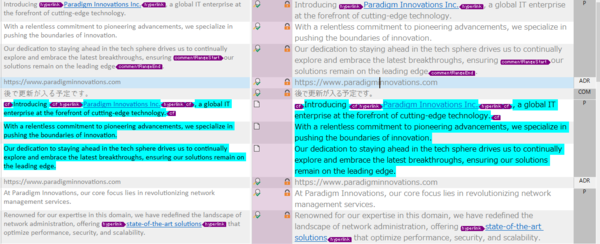
�R�����g�����b�N����
��}�Ŋ��ɃR�����g���������b�N����Ă��܂����A�F���g�킸�ɃR�����g�����𒊏o���邱�Ƃ��ł��܂��B����ɂ́A[�����\��] �^�u���g�p���܂��B[�����\��] �^�u�ɂ́A�G�f�B�^�[�̉E�[�ɕ\������Ă��镶���\���̏�\������Ă��܂��B��������A�K���ȕ����\����I�����āA���̕��߂����𒊏o�ł��܂��B
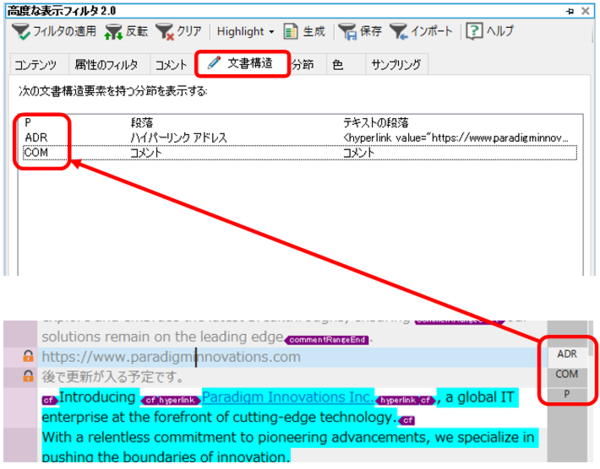
����ŁA�|��̏����������܂����B��́A���b�N����Ă��Ȃ�������|�Ă����܂��B���b�N�ӏ����ז��Ȃ�A�t�B���^�[�Ń��b�N�ӏ����\���ɂł��܂��B�܂��A�n�C���C�g���ڂɂ��邳���悤�Ȃ�A��L�� [�����̕\���X�^�C��] �� [������\�������ɂ��ׂẴ^�O��\������] �ɕύX���܂��B����ŁA�n�C���C�g�̐F�͕\������Ȃ��Ȃ�܂��B
�|������������Ė���������ƁA���}�̂悤�ȃt�@�C�����ł�������܂��B�����͂��̂܂c��A�ɂ̓n�C���C�g���t���Ă��܂��B���X�����Ă����R�����g�����̂܂c���Ă��܂��B2 �ڂ́u�|��ҁv�̃R�����g�́A�|�� Trados ��œ��ꂽ�R�����g�ł��B�Ō�ɁA�n�C���C�g�������Ċ����ł��B

����͈ȏ�ł��B�����܂ł��� Trados ���g���K�v������̂��H�H�Ƃ��������������Ă������ł����A���͂��̒��x�̎�ԂȂ� Trados ���g���������悢�Ǝv���Ă��܂��B���� Trados ��ɓ��͕⏕�⌟�̐ݒ�����Ă���̂ŁAWord ��e�L�X�g �G�f�B�^�[�ō�Ƃ�����Ƃ��Ȃ�����������Ă��܂��܂��B��������p��W�̒��Ȃ��Ƃ��Ă��A���̏ꍇ�� Trados ���g�������������ǂ���Ƃ�i�߂��܂��B
Tweet
���āATrados �Ȃǂ� CAT �c�[���̋@�\�Ƃ����A�|���� (Translation Memory�A������ TM) ����\�I�ł����ACAT �c�[���̋@�\�͂��ꂾ���ł͂���܂���B����������؎g��Ȃ��ꍇ�ł��A���܂��܂ȗ��p���l������܂��B���̏ꍇ�ATrados �̎�ȗp�r�́u�G�f�B�^�[�v�ł��B�����ł��B�P�Ȃ�G�f�B�^�[�ł��BWord ���A�e�L�X�g �G�f�B�^�[���A�|���Ƃŕ�������͂���Ȃ� Trados �������I�ł��B�����Ɩ����ŎQ�Ƃł���A�����Ɩ̂ǂ��炩��ł������ł���A���͕⏕�@�\���g�p�ł���A�^�O�������ł���A�Ȃǖ|���ƂɌ������Ȃ��@�\���ŏ����������Ă��܂��B
�������AWord ��e�L�X�g �G�f�B�^�[���A�}�N���ȂǂŃJ�X�^�}�C�Y����Α����֗��Ɏg����Ǝv���܂��B�������A�|����n�߂��������� CAT �c�[�����g���Ă������̏ꍇ�A���̃G�f�B�^�[�̃}�N���Ȃǂ��ATrados �̕�������Ă��܂��B�܂��A�����u����Ă���v�Ƃ������R�����Ŏg�������邱�Ƃ��ǂ��Ƃ͎v���Ă��܂��A���̂Ƃ���킴�킴���̃G�f�B�^�[�ɕς���قǂ̗��R������܂���B
�Ƃ����킯�ŁA���́AWord �t�@�C���Ȃǂ�n����āu�㏑���|��Łv�ƈ˗�����Ă��A�ł��邾�� Trados ���g���悤�ɂ��Ă��܂��B�����A���������Č��́A�����Ŗ����܂ōs���Č��̃t�@�C���`���Ŕ[�i����K�v������̂ŁA��ƑO�ɕK���u�ȒP�Ɍ��̏�Ԃɖ߂��邩�v���m�F���܂��B
���̊m�F�̃|�C���g�́u�ȒP�Ɂv�ł��BTrados �֗̕����ƁA���̃t�@�C���ɖ߂��Ƃ��̎�Ԃ��r���āA�������t�@�C���ɖ߂���Ԃ̕����傫���Ȃ�悤�ł���A�f���Ɂu�㏑���|��v��������܂���B���̂��߁ATrados ���G�f�B�^�[�Ƃ��Ďg�������̂Ȃ�A���t�@�C���ɖ߂��Ƃ��̎�Ԃ��ł��邾�����Ȃ�����K�v������܂��B
����́AWord �t�@�C���Œi�����Ƃ̕��L���˗����ꂽ�ꍇ���Ɂu�ȒP�Ɂv���t�@�C���ɖ߂����߂Ɏg�������ȏ��Z���Љ�܂��B�����܂Łu���Z�v�ł��B�i�����Ƃ̕��L�Ƃ����`���� Trados �Ńp�b�Ɛ����ł���킯�ł͂���܂���B��{�I�ɂ͎蓮�ł̍�ƂɂȂ�܂��B
�ł́A�ȉ��̂悤�� Word �t�@�C����i�����Ƃɉp�����L�Ŗ|�Ă��������Ǝw�����ꂽ�Ƃ��܂��B���̃t�@�C���́A�������ۂɈ˗����ꂽ�t�@�C������ɍ�����T���v���ł��B���ڂ��ׂ��_�́A���͓��Ƀ����N�����邱�ƂƁA�R�����g���t���Ă��邱�Ƃł��B

1. �i�����ƂɃR�s�y���A���n�C���C�g�Ń}�[�L���O����
�܂��́A�i�����ƂɃR�s�y���ĕ��L�̌`�ɂ��A����͂��鑤�Ƀn�C���C�g��t���܂��B���݂܂���A�ł��ʓ|�Ȃ��̍�Ƃ͎蓮�ōs���܂��B(�����A���\�y�[�W������悤�ȑ傫�ȃt�@�C���������玩�������l���܂����A������������Ȉ˗������Ă���t�@�C���� 1 �` 2 �y�[�W���x�̂��̂������̂ŁA�Ƃ肠�����A�蓮�ł����܂��B)

���̗�ł́A�ƂȂ镔���ւ̃}�[�L���O�Ƃ��ăn�C���C�g���g���Ă��܂��B���̃}�[�L���O�́A���̌� Trados ��Ō����Ɩ���ʂ��邽�߂Ɏg���܂��B�}�[�L���O�͍ŏI�I�ɖ�����������ō폜����K�v������̂ŁA���܂��폜�ł������Ȃ��̂��g���K�v������܂��BTrados �̓��삩��l����ƁA�n�C���C�g�ȊO�ɁA�����̐F���}�[�L���O�Ƃ��Ďg�p�ł��܂��B
����̃t�@�C���Ń}�[�L���O�Ƀn�C���C�g��I�̂́A���͓��Ƀ����N������������ł��B�����N�̕����ɈقȂ�F���g���Ă���̂ŁA�}�[�L���O�Ƃ��ĕ����̐F���g���ƁA��Ŗ߂��Ƃ��Ƀ����N�̕��������ʂɐF��ς��Ȃ���Ȃ�Ȃ����ƂɂȂ�܂��B�t�ɁA�����Ƀn�C���C�g���g���Ă�����A�}�[�L���O�ɂ͕����̐F���g���܂��B�����������g���Ă�����A�ʓ|�ł����A�ʂ̐F�̃n�C���C�g���g���A�Ƃ��ł����ˁB���̓s�x�A�����ɍ��킹�ēK���ɍl���܂��B
2. �R�����g���܂߂� Trados �Ɏ�荞��
Word �t�@�C����ŕ��L�̌`�������������� Trados �Ɏ�荞�݂܂����A���̑O�ɂЂƂ����ݒ�����܂��B����̌����ɂ̓R�����g���t���Ă���̂ŁA���̃R�����g�� Trados �Ɏ�荞�ނ悤�ɂ��܂��B�R�����g��K�v���Ȃ��Ƃ��Ă��ATrados �Ɏ�荞��ł����Ȃ��ƁA�������Ăł�������t�@�C���ŃR�����g�������Ă��܂��܂��B
�R�����g����荞�ސݒ�́u�t�@�C���̎�ށv�ōs���܂��B�v���W�F�N�g���쐬����O��������A[�t�@�C��] > [�I�v�V����] > [�t�@�C���̎��] > [Microsoft Word 2007-2019] > [�S�ʐݒ�] �ł��B�v���W�F�N�g���쐬������Őݒ��ς���ꍇ�́A���̃v���W�F�N�g�� [�v���W�F�N�g�̐ݒ�] > [�t�@�C���̎��] �ł��B(���� 2 �̐ݒ�̈Ⴂ�ɂ��ẮA�ȑO�̋L���uTrados �̐ݒ��ς���ɂ� �| [�t�@�C��] �� [�v���W�F�N�g�̐ݒ�]�v���Q�Ƃ��Ă��������B)

��}�̂悤�ɁA[�R�����g] �� [�R�����g��|��ΏۂƂ��Ē��o����] �`�F�b�N�{�b�N�X���I���ɂ���ƁA�����t�@�C���ɂ���R�����g�� Trados �Ɏ�荞�ނ��Ƃ��ł��܂��B�����Ŏ�荞��ł����A���������Ƃ��ɂ��̂܂܃R�����g���o�͂���܂��B
���̉��� [Studio �̖R�����g������ɕێ�����] �́ATrados ��ŋL�������R�����g����������t�@�C���ɏo�͂��邩�ǂ����̐ݒ�ł��B�`�F�b�N�{�b�N�X���I���ɂ���ƁA�R�����g���o�͂���܂��B
���̐ݒ肪����������ATrados �Ƀt�@�C������荞�݂܂��B���̐ݒ�������Ɏ�荞��ł��܂����ꍇ�́A�������̃t�@�C���͍폜���A�ݒ��ς��Ă�����߂Ď�荞�ݒ����܂��B���̐ݒ�́A��荞�ޑO�ɍs���K�v������܂��B�ォ��ݒ��ς��Ă��A�R�����g�͎�荞�܂�܂���B
3. Trados �Ŗ|�镔���ȊO�����b�N����
Trados �Ńt�@�C�����J���ƁA�ȉ��̂悤�ɂȂ�܂��B���}�́A�S���߂ɂ��Č�����ɃR�s�[������̏�Ԃł��B�^�O�ƃn�C���C�g�̐F���\������Ă���̂́A[�G�f�B�^] �� [�����̕\���X�^�C��] �� [���ׂĂ̏����ƃ^�O��\������] ��I�����Ă��邩��ł� (�ڂ����́A�ȑO�̋L���u�G�f�B�^��̃t�H���g��ς����v���Q�Ƃ��Ă�������)�B�^�̃X�e�[�^�X�̗����F�ɂȂ��Ă���̂́A�������R�s�[�����Ƃ��̐F��ݒ肵�Ă��邩��ł� (�ڂ����́A�ȑO�̋L���u�{���Ɍ�������R�s�[�����܂܂��H�v���Q�Ƃ��Ă�������)�B

������ɃR�s�[������A�|���Ƃ�����ȊO�̕��߂����b�N���܂��B�Ԉ���ĕҏW���Ă��܂��ƍ���̂ŁA�K�����b�N���܂��B���b�N����ӏ��́A���L�`���̌����ɂ����镔���ƁA���X�����ɓ����Ă����R�����g�ł��B
�n�C���C�g���t���Ă��Ȃ����߂����b�N����
����ɂ́A�u���x�ȕ\���t�B���^ 2.0�v���g���܂��B[�F] �^�u�Ń}�[�L���O�Ɏg�����F��I�����A�㕔�� [���]] �{�^�����N���b�N���܂��B
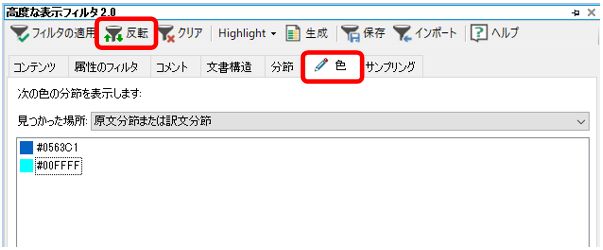
[�F] �^�u�̃��X�g�ɂ́A�n�C���C�g�╶���Ȃǂ̐F�������I�ɕ\������Ă��܂��B���ۂɂǂ̗v�f�̐F���\������Ă���̂��͂悭�킩��܂��A�n�C���C�g�ƕ����̐F�͕\������Ă��܂��B�ł��̂ŁA�Ԏ��̕����̂ݕ\������A�Ƃ�����������\�ł��B[���]] �{�^���́A�I�������F���܂܂�镪�߁g�ȊO�h�𒊏o���邽�߂Ɏg���܂��B�܂�A[���]] �{�^�����g�����ƂŁu�n�C���C�g���t���Ă��Ȃ��v���߂𒊏o�ł��܂��B
�n�C���C�g���t���Ă��Ȃ����߂𒊏o������A���̕��߂����ׂđI�����Ă��̂܂܃��b�N���܂��B����ŁA�]�v�ȕ���������ĕҏW���Ă��܂��S�z���Ȃ��Ȃ�܂��B(���}�́A�X�e�[�^�X�� [�|�F�ς�] �ɕύX���Ă��烍�b�N���Ă��܂��B�X�e�[�^�X�̕ύX�͔C�ӂł����A�|�镔���ȊO��ʂ̃X�e�[�^�X�ɂ��Ă����Ɖ����ƕ֗��ł��B)

�R�����g�����b�N����
��}�Ŋ��ɃR�����g���������b�N����Ă��܂����A�F���g�킸�ɃR�����g�����𒊏o���邱�Ƃ��ł��܂��B����ɂ́A[�����\��] �^�u���g�p���܂��B[�����\��] �^�u�ɂ́A�G�f�B�^�[�̉E�[�ɕ\������Ă��镶���\���̏�\������Ă��܂��B��������A�K���ȕ����\����I�����āA���̕��߂����𒊏o�ł��܂��B
����ŁA�|��̏����������܂����B��́A���b�N����Ă��Ȃ�������|�Ă����܂��B���b�N�ӏ����ז��Ȃ�A�t�B���^�[�Ń��b�N�ӏ����\���ɂł��܂��B�܂��A�n�C���C�g���ڂɂ��邳���悤�Ȃ�A��L�� [�����̕\���X�^�C��] �� [������\�������ɂ��ׂẴ^�O��\������] �ɕύX���܂��B����ŁA�n�C���C�g�̐F�͕\������Ȃ��Ȃ�܂��B
4. ���������āA�n�C���C�g������
�|������������Ė���������ƁA���}�̂悤�ȃt�@�C�����ł�������܂��B�����͂��̂܂c��A�ɂ̓n�C���C�g���t���Ă��܂��B���X�����Ă����R�����g�����̂܂c���Ă��܂��B2 �ڂ́u�|��ҁv�̃R�����g�́A�|�� Trados ��œ��ꂽ�R�����g�ł��B�Ō�ɁA�n�C���C�g�������Ċ����ł��B

����͈ȏ�ł��B�����܂ł��� Trados ���g���K�v������̂��H�H�Ƃ��������������Ă������ł����A���͂��̒��x�̎�ԂȂ� Trados ���g���������悢�Ǝv���Ă��܂��B���� Trados ��ɓ��͕⏕�⌟�̐ݒ�����Ă���̂ŁAWord ��e�L�X�g �G�f�B�^�[�ō�Ƃ�����Ƃ��Ȃ�����������Ă��܂��܂��B��������p��W�̒��Ȃ��Ƃ��Ă��A���̏ꍇ�� Trados ���g�������������ǂ���Ƃ�i�߂��܂��B
| �@�@ |
2023�N09��13��
�y�����I�z�e���L�[���琔���̓��͂��ł��Ȃ�
�O��̋L���ŋ����Ă�����肪 1 �������܂����B������A�ő�̖��Ƃ��Ă����u�e���L�[���琔���̓��͂��ł��Ȃ��v���ł��B����A�u���O�������Ă݂����ł��B
�����̓V���[�g�J�b�g �L�[�̋����ł����B�킩���Ă��܂��A�Ȃ�Ă��Ƃ͂Ȃ��悭������ł��BTrados �ɂ͎����|��p�� Studio Subtitling �Ƃ����v���O�C��������܂��B����̉f���𑀍삷��V���[�g�J�b�g �L�[������Ńe���L�[�Ɋ��蓖�Ă��Ă��܂����B�V���[�g�J�b�g �L�[�� [�t�@�C��] > [�I�v�V����] > [�G�f�B�^] > [�V���[�g�J�b�g �L�[] �Ŋm�F�ł��܂��B
�������̃v���O�C�����C���X�g�[�������̂͐����O�������̂ŁA�������葶�݂�Y��Ă��܂����B����A�v���Ԃ� (���Ԃ�A1 �N�Ԃ肭�炢) �ɂ��̃v���O�C�����g���Č�������A�V���[�g�J�b�g �L�[�����������Ȃ��Ǝv���Č��Ă݂���A��}�̐ݒ�ɂȂ��Ă����̂Łu���ꂩ�I�I�I�v�ƈ�l�Ŏv�킸����ł��܂��܂����B
���̃V���[�g�J�b�g �L�[�̐ݒ��ύX����e���L�[����̓��͂͂ł���悤�ɂȂ�܂����A�S���̐ݒ��ς���̂͏����ʓ|�ł��B�܂��A�f���̍Đ��𑀍삷����̂Ȃ̂ŁA�L�[�� 2 �� 3 ����������������A1 �̃L�[�ő���ł�������f�R�֗��ł��B�Ƃ����킯�ŁAStudio Subtitling ���g���Ƃ��́A�e���L�[����̓��͂͂�����߁A���̃V���[�g�J�b�g �L�[�����̂܂g�����Ƃɂ��܂����B
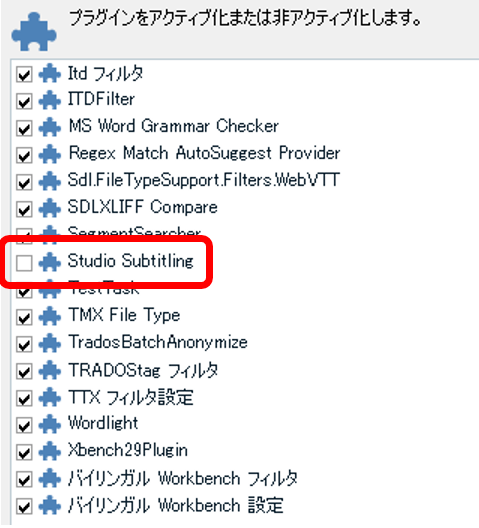
�ŁA�V���[�g�J�b�g �L�[�̐ݒ���c�����܂܋������������ɂ͂ǂ����邩�Ƃ����ƁA�v���O�C�����ɂ��܂��B���j���[�� [�A�h�C��] > [�v���O�C��] ����A�v���O�C���͌ʂɗL��/�������ւ����܂� (��ւ��ɂ� Trados �̍ċN�����K�v�ł�)�B
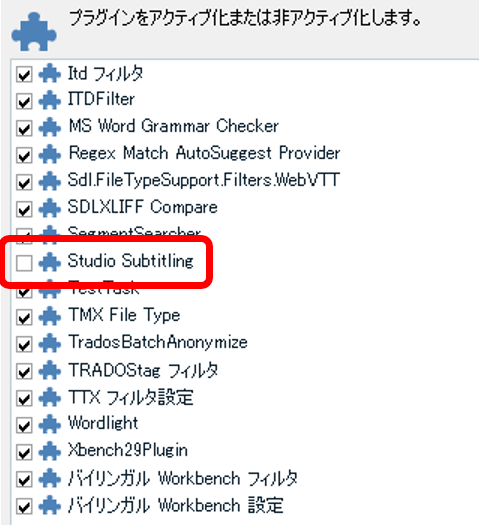
Studio Subtitling ���ɂ���V���[�g�J�b�g �L�[�̐ݒ�������ɂȂ�̂ŁA�������Ȃ��Ȃ�A����Ƀe���L�[���琔������͂ł���悤�ɂȂ�܂��B�L��/�����̐�ւ��͏�����Ԃł����A�V���[�g�J�b�g �L�[��ݒ肵�������͏��Ȃ���Ԃōς݂܂��B�܂��AStudio Subtitling ��L���ɂ���Ƃ܂��������������܂����A����͎d���Ȃ��̂ł�����߂܂��B
����̎����Č��͉p���|�����̂ŁAIME �œ��{����͂��I���ɂ��Ă��鎞�Ԃ������Ȃ�܂����B���́A���{����͂��I���ɂ��Ă���ꍇ�A���� Studio Subtitling �̃V���[�g�J�b�g �L�[�͋@�\���܂���B�L�[���^�C�v���Ă��m��O�̏�Ԃ��ƃV���[�g�J�b�g �L�[�Ƃ��ĔF������Ȃ��悤�ł��B
���Ȃ݂ɁA���̓��{����͂��I���̂Ƃ��ɃV���[�g�J�b�g �L�[�������Ȃ����ۂ� Studio Subtitling �Ɍ��������̂ł͂Ȃ��A���̃v���O�C���ł� (���邢�� Trados �ȊO�̃A�v���P�[�V�����ł�) �������邱�Ƃ�����܂��B�����炭�A�v���O�C���̊J������ IME �̂��ƂȂǂ��܂�l�����Ă��Ȃ��̂ł͂Ȃ����Ǝv���܂��B�p��̏ꍇ�͉p�����͂���̂ł��܂���ɂȂ�܂��A�a��̏ꍇ�͍��邱�Ƃ����\����܂��B
�����A�e���L�[�Ɍ����ẮA��������܂��B���� ATOK ���g���Ă���̂� ATOK �ł̕��@�ɂȂ�܂����A�ȉ��̂悤�Ȑݒ肪����܂��B
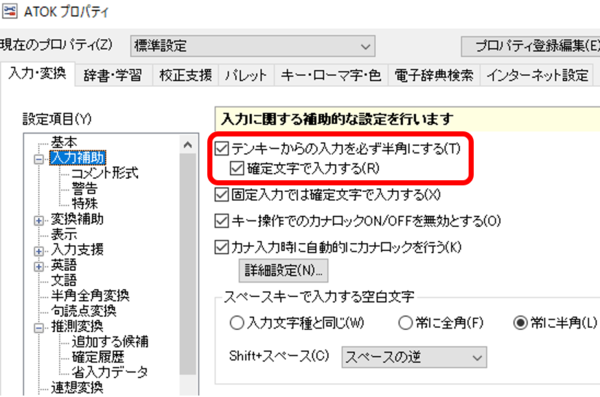
[�m�蕶���œ��͂���] �`�F�b�N�{�b�N�X���I���ɂ��Ă����ƁA���{����͂��I���ɂȂ��Ă����Ԃł��e���L�[����̓��͂͊m�肵����Ԃœ��͂���A�V���[�g�J�b�g �L�[�Ƃ��ĔF������܂��B
����͈ȏ�ł��B�����V���[�g�J�b�g �L�[�̋����ɂȂ��Ȃ��C�t���Ȃ������̂́ATrados �̎g�p�p�x���S�̓I�ɗ����Ă��Ă��邱�Ƃ�������������܂���B���܂�g��Ȃ��̂Ō����ɍl�����y�Ȃ����A��肪�����Ă��Ƃ肠���������Ă������ƂɂȂ肪���ł��B���₢��A����ł����̂Ƃ��� Trados �ȏ�ɕ֗��ȃc�[���͂Ȃ��Ǝv���Ă���̂ŁATrados ����A�Ȃ�Ƃ��撣���Ă��������B
Tweet
�����̓V���[�g�J�b�g �L�[�̋����ł����B�킩���Ă��܂��A�Ȃ�Ă��Ƃ͂Ȃ��悭������ł��BTrados �ɂ͎����|��p�� Studio Subtitling �Ƃ����v���O�C��������܂��B����̉f���𑀍삷��V���[�g�J�b�g �L�[������Ńe���L�[�Ɋ��蓖�Ă��Ă��܂����B�V���[�g�J�b�g �L�[�� [�t�@�C��] > [�I�v�V����] > [�G�f�B�^] > [�V���[�g�J�b�g �L�[] �Ŋm�F�ł��܂��B
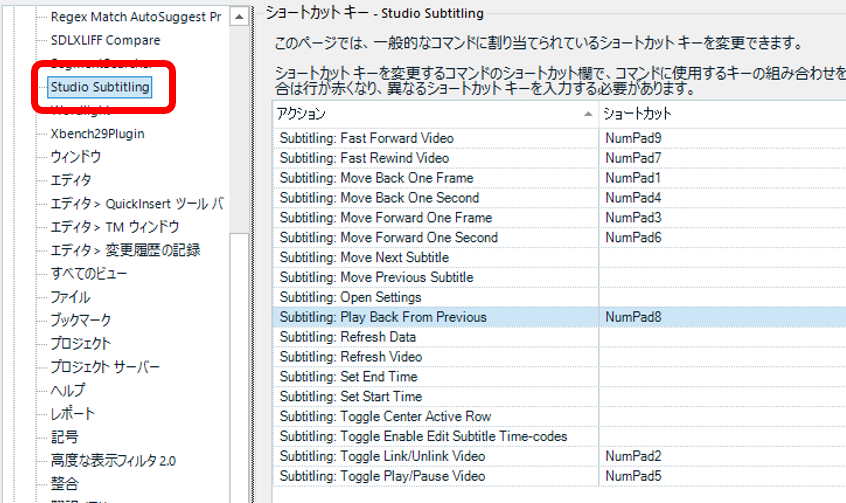
�������̃v���O�C�����C���X�g�[�������̂͐����O�������̂ŁA�������葶�݂�Y��Ă��܂����B����A�v���Ԃ� (���Ԃ�A1 �N�Ԃ肭�炢) �ɂ��̃v���O�C�����g���Č�������A�V���[�g�J�b�g �L�[�����������Ȃ��Ǝv���Č��Ă݂���A��}�̐ݒ�ɂȂ��Ă����̂Łu���ꂩ�I�I�I�v�ƈ�l�Ŏv�킸����ł��܂��܂����B
���̃V���[�g�J�b�g �L�[�͂��̂܂g��
���̃V���[�g�J�b�g �L�[�̐ݒ��ύX����e���L�[����̓��͂͂ł���悤�ɂȂ�܂����A�S���̐ݒ��ς���̂͏����ʓ|�ł��B�܂��A�f���̍Đ��𑀍삷����̂Ȃ̂ŁA�L�[�� 2 �� 3 ����������������A1 �̃L�[�ő���ł�������f�R�֗��ł��B�Ƃ����킯�ŁAStudio Subtitling ���g���Ƃ��́A�e���L�[����̓��͂͂�����߁A���̃V���[�g�J�b�g �L�[�����̂܂g�����Ƃɂ��܂����B
�g��Ȃ��Ƃ��̓v���O�C�����ɂ���
�ŁA�V���[�g�J�b�g �L�[�̐ݒ���c�����܂܋������������ɂ͂ǂ����邩�Ƃ����ƁA�v���O�C�����ɂ��܂��B���j���[�� [�A�h�C��] > [�v���O�C��] ����A�v���O�C���͌ʂɗL��/�������ւ����܂� (��ւ��ɂ� Trados �̍ċN�����K�v�ł�)�B
Studio Subtitling ���ɂ���V���[�g�J�b�g �L�[�̐ݒ�������ɂȂ�̂ŁA�������Ȃ��Ȃ�A����Ƀe���L�[���琔������͂ł���悤�ɂȂ�܂��B�L��/�����̐�ւ��͏�����Ԃł����A�V���[�g�J�b�g �L�[��ݒ肵�������͏��Ȃ���Ԃōς݂܂��B�܂��AStudio Subtitling ��L���ɂ���Ƃ܂��������������܂����A����͎d���Ȃ��̂ł�����߂܂��B
���{����͂̂Ƃ��̃V���[�g�J�b�g �L�[
����̎����Č��͉p���|�����̂ŁAIME �œ��{����͂��I���ɂ��Ă��鎞�Ԃ������Ȃ�܂����B���́A���{����͂��I���ɂ��Ă���ꍇ�A���� Studio Subtitling �̃V���[�g�J�b�g �L�[�͋@�\���܂���B�L�[���^�C�v���Ă��m��O�̏�Ԃ��ƃV���[�g�J�b�g �L�[�Ƃ��ĔF������Ȃ��悤�ł��B
���Ȃ݂ɁA���̓��{����͂��I���̂Ƃ��ɃV���[�g�J�b�g �L�[�������Ȃ����ۂ� Studio Subtitling �Ɍ��������̂ł͂Ȃ��A���̃v���O�C���ł� (���邢�� Trados �ȊO�̃A�v���P�[�V�����ł�) �������邱�Ƃ�����܂��B�����炭�A�v���O�C���̊J������ IME �̂��ƂȂǂ��܂�l�����Ă��Ȃ��̂ł͂Ȃ����Ǝv���܂��B�p��̏ꍇ�͉p�����͂���̂ł��܂���ɂȂ�܂��A�a��̏ꍇ�͍��邱�Ƃ����\����܂��B
�����A�e���L�[�Ɍ����ẮA��������܂��B���� ATOK ���g���Ă���̂� ATOK �ł̕��@�ɂȂ�܂����A�ȉ��̂悤�Ȑݒ肪����܂��B

[�m�蕶���œ��͂���] �`�F�b�N�{�b�N�X���I���ɂ��Ă����ƁA���{����͂��I���ɂȂ��Ă����Ԃł��e���L�[����̓��͂͊m�肵����Ԃœ��͂���A�V���[�g�J�b�g �L�[�Ƃ��ĔF������܂��B
����͈ȏ�ł��B�����V���[�g�J�b�g �L�[�̋����ɂȂ��Ȃ��C�t���Ȃ������̂́ATrados �̎g�p�p�x���S�̓I�ɗ����Ă��Ă��邱�Ƃ�������������܂���B���܂�g��Ȃ��̂Ō����ɍl�����y�Ȃ����A��肪�����Ă��Ƃ肠���������Ă������ƂɂȂ肪���ł��B���₢��A����ł����̂Ƃ��� Trados �ȏ�ɕ֗��ȃc�[���͂Ȃ��Ǝv���Ă���̂ŁATrados ����A�Ȃ�Ƃ��撣���Ă��������B
| �@�@ |
2023�N08��28��
�����������Ă����肢�낢��
���̃u���O�̋L���������Ƃ��́A���������ł��𗧂����܂߂����ƍl���A�o�O��s������グ��Ƃ����A�Ȃ�ׂ��������@������i���ꏏ�ɏ����悤�ɂ��Ă��܂����B�����A���݂܂���A���̂Ƃ��뎄�p�ł��낢�날�肠�܂莞�Ԃ����Ȃ��̂ŁA����͎��������������Ƃ̂�������Ƃ肠�������Ă݂����Ǝv���܂��B
�{���Ȃ班�����������Ă���L���������Ƃ���ł����A����͂قƂ�lj������ׂ��肵�Ă��܂���B���̊����L�̂��̂��܂܂�Ă��邩�Ǝv���܂����A�����u�����悤�Ȗ�肪��������I�v�Ƃ��A�u����������璼�����I�v�Ȃǂ̏����܂����狤�L���Ă��炦��Ɗ������ł��B
���C�Z���X�̃A�N�e�B�x�[�V������ʂŁA�V���[�g�J�b�g �L�[���g���ă��C�Z���X �L�[��\��t�����Ȃ�
���C�Z���X �L�[��\��t����Ƃ��ɃL�[�{�[�h�� Ctrl+V �͋@�\�����A�\��t���̃A�C�R�����}�E�X�ŃN���b�N����K�v������܂��B�}�E�X��������Ȃ���Ȃ�Ȃ��̂́A���ɂƂ��Ă͔��ɖʓ|�ł��B
�X�y�� �`�F�b�J�[�� MS Word ��I���ł��Ȃ�
MS Word ��I������ƃG���[�ɂȂ�̂ŁA�d���Ȃ������ Hunspell ���g���Ă��܂��BMS Word �̕������x���ǂ������ȋC������̂� MS Word �ɐ�ւ������̂ł����A���ꂪ�ł��܂���B
Trados ������������āAWord ���J���Ă���t�@�C�������ׂĕ��āA���̌�ʼn��߂� Trados ���N������ƁAMS Word ��I���ł��邱�Ƃ� (���܂�) ����܂��B
�ύX�������I���ɂ��č�Ƃ��Ă���Ƃ��ɁA�G�f�B�^�[���悭�����I������
���b�Z�[�W�������Ȃ���ʂ������Ă��܂����Ƃ�����܂��B���ɁAShift+F3 �ő啶���������̕ϊ��������Ƃ��ɉ�ʂ������邱�Ƃ������C�����܂��B�����AShift+F3 ���������Ƃ��͗��Ɂu���߂�}���ł��܂���v�Ƃ������b�Z�[�W���\������Ă��邱�Ƃ�����܂��B
�ύX�������I���ɂ��č�Ƃ��Ă���Ƃ��ɁA�������I�����ăR�����g��lj��ł��Ȃ�
���ߑS�̂ɑ���R�����g�͒lj��ł��܂����A���ߓ��̕�����ɑ��ẴR�����g�͒lj��ł��Ȃ����Ƃ������ł��B
Quick Insert �ŁA�V���[�g�J�b�g �L�[�� Ctrl+Shift+0 �Ɋ��蓖�Ă���Ƌ@�\���Ȃ�
����͈ȑO�̋L���uQuickInsert ��ݒ肷��Ƃ��ɒ��ӂ����������v�ł��Љ�܂����B�������Ȃ蒷���Ԃ��̏�Ԃ������Ă���C�����܂��B1 ��o�^���āACtrl+Shift+0 �����蓖�Ă�ꂽ��A����͂��̂܂܂ɂ��Ă�����x�o�^���܂��B�ʓ|�ł��B
Word �t�@�C�����v���r���[������A�v���r���[�̃t�@�C�������Ƃ��ɁuNormal.dot �� �`�`�v�Ƃ������b�Z�[�W���\������ăE�B���h�E�������ɕ����Ȃ�
����� Word �̃}�N����ݒ肵�Ă���̂��������Ǝv���܂��B�����Őݒ肷��}�N���� Normal.dot �ȊO�ɓo�^��������̂ł͂Ȃ����A�Ǝv���Ă͂���̂ł����A���̂Ƃ�����u���Ă��܂��B
Trados �̉�ʂ��ő剻���Ă��A��ʉ����̕������Ȃǂ̐��������S�ɕ\������Ȃ�
Trados ���N����������͉�ʉE���̐������������炢�����\������܂���B���������ʂ̑傫�����蓮�ŕς��āA���߂čő剻����Ɗ��S�ɕ\�������悤�ɂȂ�܂��B
�e���L�[���琔���̓��͂��ł��Ȃ�
���݂̂Ƃ���A���ɂƂ��čő�̖��͂��ꂩ������Ȃ��ł��BTrados ��Ńe���L�[����̓��͂��ł��Ȃ��ꍇ�ł��A���̃A�v���ɉ�ʂ��ւ���Ɛ���ɓ��͂��ł���̂ŁANumLock �Ƃ��̖��ł͂Ȃ��Ǝv���̂ł����悭�킩��܂���B
���Ȃ݂ɁA���������͂ł��Ȃ������ŁA�e���L�[�� Enter �L�[�Ȃǂ͋@�\���܂��B���ꂪ�܂���������ŁA��������͂��� Enter �L�[�����������肪�AEnter �L�[�����������ꂽ��ԂɂȂ�܂��B
�v���W�F�N�g�̐ݒ��ʂŁA��ʂ̑J�ڂ����̂������x���Ȃ�Ƃ�������
�ǂ������Ƃ��ɒx���Ȃ�̂��Ȃǂ͂킩��Ȃ��̂ł����A�Ƃɂ����A���̂������x���đ҂�����Ȃ��Ƃ�������܂��B
�t�@�C�� ���X�g��ʂŁA�u�X�e�[�^�X���v�^�u�̐�����P�ꐔ�ƕ������Ő�ւ����Ȃ�
���p�|��̏ꍇ�͊���P�ꐔ�ł͂Ȃ��������ɂȂ�̂ŁA�X�e�[�^�X�Ȃǂ��������ŕ\�����Ăق����̂ł����A������ւ���h���b�v�_�E�� ���X�g���\������܂���B��������ʂ̃^�u��\�����Ă���߂��Ă���ƁA���̃h���b�v�_�E�� ���X�g���\������܂��B
���A���^�C�� �v���r���[���g���ƁATrados �̃G�f�B�^�[��̃J�[�\���������Ă��܂�
�o�[�W���� 2022 �Ńv���r���[�͉��P����Ă���炵���̂ł����A�{���ł��傤�� �B(��������������͉��P����Ă��Ȃ��悤�ł����B)
�J�[�\���������Ă��܂����ꍇ�́ACtrl+0 �������ƃJ�[�\�������ɕ������܂��B�����͂��܂����A���������ʓ|�������Ă���Ă��܂���B
�v���O�C���� MSWord Grammer Checker ���x�����Ďg���Ȃ�
�����Ђ���� MSWord Grammer Checker ���g���Č����s���悤�Ɏw�����ꂽ�̂ł����A���ɂ����鎞�Ԃ��ƂĂ������Ȃ�܂��B�傫�ȃt�@�C���ɂȂ�ƁA�܂��A�҂��Ă����܂���B
�v���O�C���� SDLXLIFF Compare ���g���ƁA�G�f�B�^�[��ʂɈڂ��Ă��A���̃v���O�C���̎c�����\�������
SDLXLIFF Compare ���g������A�G�f�B�^�[��ɂ��̃v���O�C���̑����ʂ��\������Ă��܂��A���܂��܂��̕������N���b�N�����肷��ƁA���̃N���b�N���v���O�C���ɑ��Č����Ă��܂��܂��B�����A���炭����Ƃ��̌��ۂ͂Ȃ��Ȃ�C�����܂��B
�ȏ�ł��B��������������ڍׂ��킩�����肵����A�܂����߂ċL�������������Ǝv���܂��B����Ȃɂ��낢�날���Ă� Trados ���g�������Ă����Ԃ͂ǂ��Ȃ낤�Ǝv��Ȃ����Ȃ��ł����A���Ԃ�A�܂����炭�͎g�������Ă��܂��C�����܂��B

�{���Ȃ班�����������Ă���L���������Ƃ���ł����A����͂قƂ�lj������ׂ��肵�Ă��܂���B���̊����L�̂��̂��܂܂�Ă��邩�Ǝv���܂����A�����u�����悤�Ȗ�肪��������I�v�Ƃ��A�u����������璼�����I�v�Ȃǂ̏����܂����狤�L���Ă��炦��Ɗ������ł��B
���C�Z���X�̃A�N�e�B�x�[�V������ʂŁA�V���[�g�J�b�g �L�[���g���ă��C�Z���X �L�[��\��t�����Ȃ�
���C�Z���X �L�[��\��t����Ƃ��ɃL�[�{�[�h�� Ctrl+V �͋@�\�����A�\��t���̃A�C�R�����}�E�X�ŃN���b�N����K�v������܂��B�}�E�X��������Ȃ���Ȃ�Ȃ��̂́A���ɂƂ��Ă͔��ɖʓ|�ł��B
�X�y�� �`�F�b�J�[�� MS Word ��I���ł��Ȃ�
MS Word ��I������ƃG���[�ɂȂ�̂ŁA�d���Ȃ������ Hunspell ���g���Ă��܂��BMS Word �̕������x���ǂ������ȋC������̂� MS Word �ɐ�ւ������̂ł����A���ꂪ�ł��܂���B
Trados ������������āAWord ���J���Ă���t�@�C�������ׂĕ��āA���̌�ʼn��߂� Trados ���N������ƁAMS Word ��I���ł��邱�Ƃ� (���܂�) ����܂��B
�ύX�������I���ɂ��č�Ƃ��Ă���Ƃ��ɁA�G�f�B�^�[���悭�����I������
���b�Z�[�W�������Ȃ���ʂ������Ă��܂����Ƃ�����܂��B���ɁAShift+F3 �ő啶���������̕ϊ��������Ƃ��ɉ�ʂ������邱�Ƃ������C�����܂��B�����AShift+F3 ���������Ƃ��͗��Ɂu���߂�}���ł��܂���v�Ƃ������b�Z�[�W���\������Ă��邱�Ƃ�����܂��B
�ύX�������I���ɂ��č�Ƃ��Ă���Ƃ��ɁA�������I�����ăR�����g��lj��ł��Ȃ�
���ߑS�̂ɑ���R�����g�͒lj��ł��܂����A���ߓ��̕�����ɑ��ẴR�����g�͒lj��ł��Ȃ����Ƃ������ł��B
Quick Insert �ŁA�V���[�g�J�b�g �L�[�� Ctrl+Shift+0 �Ɋ��蓖�Ă���Ƌ@�\���Ȃ�
����͈ȑO�̋L���uQuickInsert ��ݒ肷��Ƃ��ɒ��ӂ����������v�ł��Љ�܂����B�������Ȃ蒷���Ԃ��̏�Ԃ������Ă���C�����܂��B1 ��o�^���āACtrl+Shift+0 �����蓖�Ă�ꂽ��A����͂��̂܂܂ɂ��Ă�����x�o�^���܂��B�ʓ|�ł��B
Word �t�@�C�����v���r���[������A�v���r���[�̃t�@�C�������Ƃ��ɁuNormal.dot �� �`�`�v�Ƃ������b�Z�[�W���\������ăE�B���h�E�������ɕ����Ȃ�
����� Word �̃}�N����ݒ肵�Ă���̂��������Ǝv���܂��B�����Őݒ肷��}�N���� Normal.dot �ȊO�ɓo�^��������̂ł͂Ȃ����A�Ǝv���Ă͂���̂ł����A���̂Ƃ�����u���Ă��܂��B
Trados �̉�ʂ��ő剻���Ă��A��ʉ����̕������Ȃǂ̐��������S�ɕ\������Ȃ�
Trados ���N����������͉�ʉE���̐������������炢�����\������܂���B���������ʂ̑傫�����蓮�ŕς��āA���߂čő剻����Ɗ��S�ɕ\�������悤�ɂȂ�܂��B
�e���L�[���琔���̓��͂��ł��Ȃ�
���݂̂Ƃ���A���ɂƂ��čő�̖��͂��ꂩ������Ȃ��ł��BTrados ��Ńe���L�[����̓��͂��ł��Ȃ��ꍇ�ł��A���̃A�v���ɉ�ʂ��ւ���Ɛ���ɓ��͂��ł���̂ŁANumLock �Ƃ��̖��ł͂Ȃ��Ǝv���̂ł����悭�킩��܂���B
���Ȃ݂ɁA���������͂ł��Ȃ������ŁA�e���L�[�� Enter �L�[�Ȃǂ͋@�\���܂��B���ꂪ�܂���������ŁA��������͂��� Enter �L�[�����������肪�AEnter �L�[�����������ꂽ��ԂɂȂ�܂��B
�v���W�F�N�g�̐ݒ��ʂŁA��ʂ̑J�ڂ����̂������x���Ȃ�Ƃ�������
�ǂ������Ƃ��ɒx���Ȃ�̂��Ȃǂ͂킩��Ȃ��̂ł����A�Ƃɂ����A���̂������x���đ҂�����Ȃ��Ƃ�������܂��B
�t�@�C�� ���X�g��ʂŁA�u�X�e�[�^�X���v�^�u�̐�����P�ꐔ�ƕ������Ő�ւ����Ȃ�
���p�|��̏ꍇ�͊���P�ꐔ�ł͂Ȃ��������ɂȂ�̂ŁA�X�e�[�^�X�Ȃǂ��������ŕ\�����Ăق����̂ł����A������ւ���h���b�v�_�E�� ���X�g���\������܂���B��������ʂ̃^�u��\�����Ă���߂��Ă���ƁA���̃h���b�v�_�E�� ���X�g���\������܂��B
���A���^�C�� �v���r���[���g���ƁATrados �̃G�f�B�^�[��̃J�[�\���������Ă��܂�
�o�[�W���� 2022 �Ńv���r���[�͉��P����Ă���炵���̂ł����A�{���ł��傤�� �B(��������������͉��P����Ă��Ȃ��悤�ł����B)
�J�[�\���������Ă��܂����ꍇ�́ACtrl+0 �������ƃJ�[�\�������ɕ������܂��B�����͂��܂����A���������ʓ|�������Ă���Ă��܂���B
�v���O�C���� MSWord Grammer Checker ���x�����Ďg���Ȃ�
�����Ђ���� MSWord Grammer Checker ���g���Č����s���悤�Ɏw�����ꂽ�̂ł����A���ɂ����鎞�Ԃ��ƂĂ������Ȃ�܂��B�傫�ȃt�@�C���ɂȂ�ƁA�܂��A�҂��Ă����܂���B
�v���O�C���� SDLXLIFF Compare ���g���ƁA�G�f�B�^�[��ʂɈڂ��Ă��A���̃v���O�C���̎c�����\�������
SDLXLIFF Compare ���g������A�G�f�B�^�[��ɂ��̃v���O�C���̑����ʂ��\������Ă��܂��A���܂��܂��̕������N���b�N�����肷��ƁA���̃N���b�N���v���O�C���ɑ��Č����Ă��܂��܂��B�����A���炭����Ƃ��̌��ۂ͂Ȃ��Ȃ�C�����܂��B
�ȏ�ł��B��������������ڍׂ��킩�����肵����A�܂����߂ċL�������������Ǝv���܂��B����Ȃɂ��낢�날���Ă� Trados ���g�������Ă����Ԃ͂ǂ��Ȃ낤�Ǝv��Ȃ����Ȃ��ł����A���Ԃ�A�܂����炭�͎g�������Ă��܂��C�����܂��B
�^�O�FMSWord Grammer Checker SDLXLIFF Compare �v���r���[ ���A���^�C�� �v���r���[ �X�e�[�^�X��� Normal.dot �g���u���V���[�e�B���O �ύX���� �R�����g
Tweet
2023�N07��03��
Xbench �� TBX �t�@�C��
Trados �̃�������p��x�[�X�̌����@�\�͂��Ȃ�n��Ȃ̂ŁA���� Xbench ���悭�g�p���Ă��܂��BXbench �̎g�p���@�ɂ��Ă��ȑO�ɋL���������Ă��܂����A���́A�����Ő����������@�ł͂��܂������ł��Ȃ��p��x�[�X�����邱�Ƃɍ����ɂȂ��ċC�t�����̂ŁA����͂��̑Ώ��@�Ȃǂ��Љ�����Ǝv���܂��B
�O���Ƃ��āA���� Xbench �̖����� (�o�[�W���� 2.9) ���g�p���Ă��܂��B�L���ł�������A�����������獡��̖��͋N���Ȃ��̂�������Ȃ��ł����A�ǂ��ł��傤�B������Ǝ����ł͎����Ȃ��̂ŁA���������܂����為�Ђ����������B
���āAXbench �ł��܂������ł��Ȃ��̂́A����Ɩ��̑g�ݍ��킹�� 1 �� 1 �łȂ��p��x�[�X�ł��B���̂悤�ȗp��x�[�X (.sdltb) �� Glossary Converter ���g���� TBX �t�@�C���ɕϊ����AXbench �Ō������s���ƁA�����̖�ꂪ�����Ă� 1 �̖�ꂵ���q�b�g���Ă��܂���B
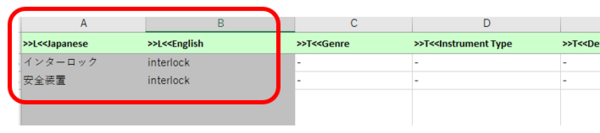
���Ƃ��A�p��x�[�X�ŁA�ȉ��̂悤�� interlock �ɑ��āu�C���^�[���b�N�v�Ɓu���S���u�v�Ƃ��� 2 �̒P�ꂪ�o�^����Ă����Ƃ��܂��B

�����P���� TBX �t�@�C���ɕϊ����� Xbench �Ɏ�荞�ނƁA�u���S���u�v�����q�b�g���Ă��܂���B
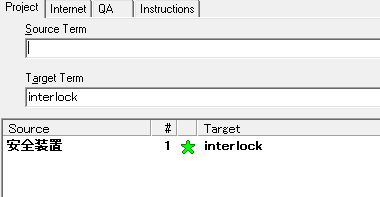
�������A���̏ꍇ�ł� TBX �t�@�C���ɂ́u�C���^�[���b�N�v�Ɓu���S���u�v�̗���������ɋL�q����Ă��܂��B�܂�AXbench �̌����@�\�� 1 �����������Ȃ��Ƃ������Ƃ̂悤�ł��B
�ŁA�ǂ��������̂��ƍl�������A����́ATBX �t�@�C���ł͂Ȃ��A�^�u���t�@�C�����g�����Ƃɂ��܂����B�菇�͂���Ȋ����ł��B
�@1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
�@2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�ł́A�菇�����Ԃɐ������Ă����܂��傤�B
Glossary Converter �ł̕ϊ����@�ɂ��ẮA�ȑO�̋L���u�y�O�ҁzXbench ��֗��Ɏg���v�Ɓu�y��ҁz�}�C�N���\�t�g�̗p��W���g�������v���Q�l�ɂ��Ă��������B
�܂��A[setting] > [General] �� �uExcel 2007 Workbook�v��I�����܂��B����ŁA�p��x�[�X (.sdltb �t�@�C��) �� Excel �t�@�C���ɕϊ������悤�ɂȂ�܂��B
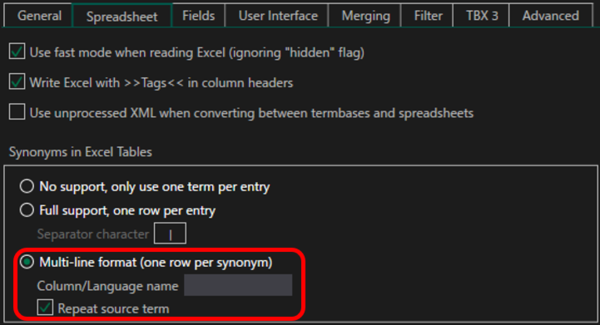
����ɁA[Spreadsheet] �^�u�� [Synonyms in Excel Tables] ��ݒ肵�܂��B[Multi-line format (one row per synonym)] �I�v�V������I�����A[Repeat source term] �`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA�����̗p�ꂪ����ꍇ�͕����̍s���쐬����A���ꂼ��̍s�Ɍ��ꂪ�L�q�����悤�ɂȂ�܂��B([Column/Language name] �͋̂܂܂ł����v�ł��B�ݒ肪�K�v�ȏꍇ�ɂ́A�ϊ��̎��s���Ƀv�����v�g���\������Ă��܂��B)
�����܂Őݒ��������AGlossary Converter �̃A�v����ɑΏۂ̗p��x�[�X �t�@�C�����h���b�O�A���h�h���b�v���܂��B����ŁA���̗p��x�[�X�Ɠ����t�H���_�[�� Excel �t�@�C�����쐬����܂��B
�쐬���ꂽ Excel �t�@�C�����J���āAXbench �������ł���`�Ƀf�[�^�𐮂��܂��B��̍���ł���p��x�[�X�̏ꍇ�́A�����Ă��A����Ɩ��ȊO�ɎQ�l���̃t�B�[���h���������ݒ肳��Ă��܂��B�����̃t�B�[���h�� Excel �t�@�C���̗�Ƃ��ďo�͂���܂����AXbench �͏�� A �������AB �����Ƃ��Č������s���̂ŁAExcel �t�@�C����ł��̂悤�ɗ����וς���K�v������܂��B�s�v�ȗ�͍폜���č\���܂��A�Q�l���� Xbench �ŕ\���������ꍇ�� C ��ȍ~�ɂ��̏����c���Ă����܂��B
��𐮂����� [���O��t���ĕۑ�] �����܂����A���̂Ƃ��� [�t�@�C���̎��] �Ƃ��āu�e�L�X�g (�^�u���) (*.txt)�v��I�����܂��B����ŁAXbench �ɓǂݍ��߂�^�u���t�@�C�����ł�������܂��B
�쐬�����^�u���t�@�C�� (.txt) �� Xbench �ɁuTab-delimited Text File�v�Ƃ��Ď�荞�ނƁA�ȉ��̂悤�ɕ����̗p�ꂪ�q�b�g���Ă��܂��B����Ŋ����ł��B
����͈ȏ�ł��B1 �� 1 �łȂ��p��x�[�X�� TBX �t�@�C�������܂������ł��Ȃ����ƂɂȂ����܂ŋC�t���Ȃ������̂��A������Ƌ��낵���Ȃ����̂Ŋm�F���Ă݂��Ƃ���A����Ȍ`���̗p��x�[�X�͎��͂قƂ�ǂ���܂���ł����B�����Ă��̏ꍇ�AExcel �t�@�C������ɂ���A���̎��_�� 1 �� 1 �ɂȂ��Ă��邩�A�Ȃ��Ă��Ȃ��ꍇ�� Excel �t�@�C����ŕҏW�����Ė������ 1 �� 1 �ɂ��Ă��܂����B�Ƃ͂����A����������h�����߁ATBX �t�@�C���� 1 �� 1 �ł��邱�Ƃ��m�F���Ă��� Xbench �Ɏ�荞�ޕK�v������܂��B
Tweet
�O���Ƃ��āA���� Xbench �̖����� (�o�[�W���� 2.9) ���g�p���Ă��܂��B�L���ł�������A�����������獡��̖��͋N���Ȃ��̂�������Ȃ��ł����A�ǂ��ł��傤�B������Ǝ����ł͎����Ȃ��̂ŁA���������܂����為�Ђ����������B
���āAXbench �ł��܂������ł��Ȃ��̂́A����Ɩ��̑g�ݍ��킹�� 1 �� 1 �łȂ��p��x�[�X�ł��B���̂悤�ȗp��x�[�X (.sdltb) �� Glossary Converter ���g���� TBX �t�@�C���ɕϊ����AXbench �Ō������s���ƁA�����̖�ꂪ�����Ă� 1 �̖�ꂵ���q�b�g���Ă��܂���B
���Ƃ��A�p��x�[�X�ŁA�ȉ��̂悤�� interlock �ɑ��āu�C���^�[���b�N�v�Ɓu���S���u�v�Ƃ��� 2 �̒P�ꂪ�o�^����Ă����Ƃ��܂��B

�����P���� TBX �t�@�C���ɕϊ����� Xbench �Ɏ�荞�ނƁA�u���S���u�v�����q�b�g���Ă��܂���B

�������A���̏ꍇ�ł� TBX �t�@�C���ɂ́u�C���^�[���b�N�v�Ɓu���S���u�v�̗���������ɋL�q����Ă��܂��B�܂�AXbench �̌����@�\�� 1 �����������Ȃ��Ƃ������Ƃ̂悤�ł��B
�ŁA�ǂ��������̂��ƍl�������A����́ATBX �t�@�C���ł͂Ȃ��A�^�u���t�@�C�����g�����Ƃɂ��܂����B�菇�͂���Ȋ����ł��B
�@1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
�@2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�ł́A�菇�����Ԃɐ������Ă����܂��傤�B
1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
Glossary Converter �ł̕ϊ����@�ɂ��ẮA�ȑO�̋L���u�y�O�ҁzXbench ��֗��Ɏg���v�Ɓu�y��ҁz�}�C�N���\�t�g�̗p��W���g�������v���Q�l�ɂ��Ă��������B
�܂��A[setting] > [General] �� �uExcel 2007 Workbook�v��I�����܂��B����ŁA�p��x�[�X (.sdltb �t�@�C��) �� Excel �t�@�C���ɕϊ������悤�ɂȂ�܂��B
����ɁA[Spreadsheet] �^�u�� [Synonyms in Excel Tables] ��ݒ肵�܂��B[Multi-line format (one row per synonym)] �I�v�V������I�����A[Repeat source term] �`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA�����̗p�ꂪ����ꍇ�͕����̍s���쐬����A���ꂼ��̍s�Ɍ��ꂪ�L�q�����悤�ɂȂ�܂��B([Column/Language name] �͋̂܂܂ł����v�ł��B�ݒ肪�K�v�ȏꍇ�ɂ́A�ϊ��̎��s���Ƀv�����v�g���\������Ă��܂��B)

�����܂Őݒ��������AGlossary Converter �̃A�v����ɑΏۂ̗p��x�[�X �t�@�C�����h���b�O�A���h�h���b�v���܂��B����ŁA���̗p��x�[�X�Ɠ����t�H���_�[�� Excel �t�@�C�����쐬����܂��B
2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�쐬���ꂽ Excel �t�@�C�����J���āAXbench �������ł���`�Ƀf�[�^�𐮂��܂��B��̍���ł���p��x�[�X�̏ꍇ�́A�����Ă��A����Ɩ��ȊO�ɎQ�l���̃t�B�[���h���������ݒ肳��Ă��܂��B�����̃t�B�[���h�� Excel �t�@�C���̗�Ƃ��ďo�͂���܂����AXbench �͏�� A �������AB �����Ƃ��Č������s���̂ŁAExcel �t�@�C����ł��̂悤�ɗ����וς���K�v������܂��B�s�v�ȗ�͍폜���č\���܂��A�Q�l���� Xbench �ŕ\���������ꍇ�� C ��ȍ~�ɂ��̏����c���Ă����܂��B

��𐮂����� [���O��t���ĕۑ�] �����܂����A���̂Ƃ��� [�t�@�C���̎��] �Ƃ��āu�e�L�X�g (�^�u���) (*.txt)�v��I�����܂��B����ŁAXbench �ɓǂݍ��߂�^�u���t�@�C�����ł�������܂��B
�쐬�����^�u���t�@�C�� (.txt) �� Xbench �ɁuTab-delimited Text File�v�Ƃ��Ď�荞�ނƁA�ȉ��̂悤�ɕ����̗p�ꂪ�q�b�g���Ă��܂��B����Ŋ����ł��B

����͈ȏ�ł��B1 �� 1 �łȂ��p��x�[�X�� TBX �t�@�C�������܂������ł��Ȃ����ƂɂȂ����܂ŋC�t���Ȃ������̂��A������Ƌ��낵���Ȃ����̂Ŋm�F���Ă݂��Ƃ���A����Ȍ`���̗p��x�[�X�͎��͂قƂ�ǂ���܂���ł����B�����Ă��̏ꍇ�AExcel �t�@�C������ɂ���A���̎��_�� 1 �� 1 �ɂȂ��Ă��邩�A�Ȃ��Ă��Ȃ��ꍇ�� Excel �t�@�C����ŕҏW�����Ė������ 1 �� 1 �ɂ��Ă��܂����B�Ƃ͂����A����������h�����߁ATBX �t�@�C���� 1 �� 1 �ł��邱�Ƃ��m�F���Ă��� Xbench �Ɏ�荞�ޕK�v������܂��B
| �@�@ |
Tweet
2023�N06��09��
Trados �����̕⑫
�v���Ԃ�� Trados �̎�������J�Â��ꂽ�̂ŎQ�����Ă݂܂����B����A�Ȃ�ƂȂ����ꂽ�����鎿���ł����A�Q�l�ɂȂ��Ȃ��킯�ł͂���܂���B
���̋L���ł́A���̊��z�ƕ⑫�������ȒP�ɂ܂Ƃ߂܂����B�ȉ��ɋ���������̃^�C�g������e�͂����܂Ŏ��̉��߂ł��B���̎��̉��߂��A���ۂɂ���������ꂽ���̐^�ӂ��炸��Ă��邩������܂��A���̕ӂ�͂��������������B
�|��A���r���[�A�����[�X�Ƃ������[�h���Ƃɉ�ʂ��J�X�^�}�C�Y�ł��邻���ł��B�������i�g���Ă����ʂ̃��C�A�E�g�͈ȑO�̋L���u�f���A�� �f�B�X�v���C�ł̍���v�ŏЉ�Ă���̂ł������������B
���̎���Ŏ����ł��C�ɂȂ����̂́A����̓��e���̂��̂ł͂Ȃ��ASDL �̕��́u���r���[�̂Ƃ��̓��������g���Ă��낢�낷�邱�Ƃ͂Ȃ��ł��傤����`�v�Ƃ����悤�Ȕ����ł��B���r���[�̂Ƃ��́A�����������܂�g��Ȃ����烁���� �y�C���͊���ʼn�ʉ����ɕ\������d�l�Ȃ̂������ł��B
���͈ȑO����A���r���[ ���[�h�̂Ƃ��ɂȂ������� �y�C������ʉ����ɕ\�������̂��^�₾�����̂ł����A���������J����Ђ̒��ł��������F���������̂ł��ˁB���������F����������A������r���[�������}�b�`���Ŋ���������肷�邱�Ƃ��Ȃ��ł���ˁH �����ł���ˁB�����āA���������g��Ȃ���ł�����B(���Ȃ݂ɁA�����Ȃ�����Ȃ��Ƃ������Ă���̂���������̋L�������ǂ݂��������B)
sdlxliff �t�@�C���������o�b�N�A�b�v���Ă��邪�A���ۂɕ�������Ƃ��͂ǂ�����悢�̂��Ƃ������₪����܂����B
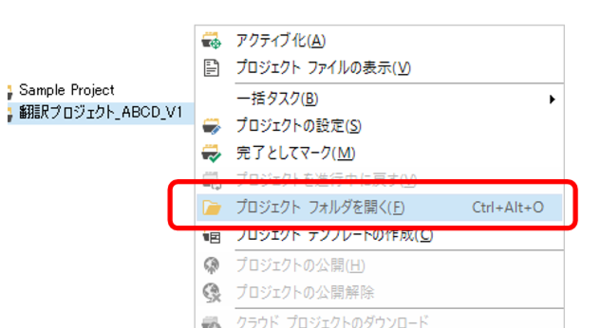
�v���W�F�N�g�̊e�t�@�C�����ǂ��Ɋi�[����Ă��邩��m��ɂ́A�v���W�F�N�g �r���[�őΏۂ̃v���W�F�N�g���E�N���b�N���A�\������郁�j���[���� [�v���W�F�N�g �t�H���_���J��] ��I�����܂��B����ŁA�v���W�F�N�g���i�[����Ă���t�H���_�[���G�N�X�v���[���[�ŊJ����܂��B
�J���ꂽ�t�H���_�[�̒��Ɂuen-US�v��uja-JP�v�ȂǁA���ꂲ�Ƃ̃t�H���_�[������Asdlxliff �t�@�C���͂��̌��ꂲ�Ƃ̃t�H���_�[�̒��Ɋi�[����Ă��܂��B
�����A�����̍�Ƃł� sdlxliff �t�@�C�����o�b�N�A�b�v�Ƃ��ĕۑ����Ă��܂��B�������≽���̐ݒ肪���Ă��܂������Ȃ��Ƃ��́A�|���Ђ�����ꂽ�p�b�P�[�W���J���Ȃ����A�o�b�N�A�b�v���Ă����� sdlxliff �t�@�C���������ɏ㏑�����܂��B����ŁA��������ݒ�͍ŏ��̏�Ԃɖ߂��A�͍��܂Ŗ����̂��ێ��ł��܂��B
Trados �ɂ́A������v���r���[�̕��@����������܂��B�v���r���[�Ɩ����̈Ⴂ�͎����������������̂ł����A����̉͂����܂ŏڂ������̂ł͂���܂���ł����B
��\��������@�ɂ��ẮA�ȑO�̋L�� �u�݂̂ŕۑ��v���g���Ă݂� �� �u�̕\���v���g���Ă݂� ���Q�Ƃ��Ă��������B
���������Љ��Ă����u�G�N�X�|�[�g�v�@�\�͏o�͐�Ȃǂ�ݒ�ł���̂łƂĂ��֗��ł��B�ȑO�̋L���u�����ɕ����̉�ʂ��J���v�ŊȒP�ɏЉ�Ă��܂��B
�u�R�����ŕ�����Ȃ��悤�ɂ������v�u���ʓ��̋�_�ł͕�����Ăق����Ȃ��v�ȂǁA���ߋK���̐ݒ�͂Ȃ��Ȃ��ʓ|�ł��B�ݒ肷��ꏊ�́A�Ő�������Ă����Ƃ���A�|������ [���ꃊ�\�[�X] > [���ߋK��] �ł��B(�ڍׂȐݒ���@�́A���݂܂���A�Z�~�i�[�ł̉̂Ƃ��茟�����Ă��������B)
���̕��ߋK���ɂ��āA���͂��� SDL ����ɋ������Đ������Ăق����Ȃ��Ǝv���Ă��邱�Ƃ�����܂��B����́u���ߋK���͌�������荞�ޑO�ɐݒ肷��K�v������v���Ƃł��B�܂�A�p�b�P�[�W��n���ꂽ�|��҂͐ݒ��ς��邱�Ƃ��ł��܂���B�|���Ђ��p�b�P�[�W�����i�K�Őݒ������K�v������܂��B
�܂��A�ŋ߂́A�@�B�|���O�ɑ}������Ă��邱�Ƃ�����܂����A���ʓ��̋�_�ŕ������Ȃ��Ƃ����ݒ肪����Ă��Ȃ����߂ɁA�����r���Ő�A�@�B�|���܂��@�\���Ă��Ȃ����Ƃ��悭����܂��B���̐ݒ�������ɋ@�B�|���K�p���āA�����͊�������܂��˂��Č����Ă����Ђ��������܂��B�������̂��ƁA���ʓ��̋�_�ŕ������Ȃ��ݒ������ɂ������������C�����܂����A���߂ł����ˁB
���╶���ȒP�Ȃ��̂ł������A���u�w���v�����Ă��������v�Ƃ����ȒP�Ȃ��̂ł����B�����������₵�Ă���̂�����A�������������Ă����Ă�������Ȃ����Ɗ������̂Ŗ|��҂̗��ꂩ�班���⑫���܂��B
���b�N�������Ԃ̖ړI�́A�����炭�u��ƑΏۊO�ł��邱�Ƃ������v���Ƃł��B�|���Ђ���Ƃ̎d���̏ꍇ�A���b�N����Ă��镪�߂͊�{�I�ɍ�Ƃ����Ȃ��̂ŗ������������܂���B�܂�A���b�N�̗L���͗����ɒ��ڂ������܂��B���̂��߁A�|��ґ��Ń��b�N����������A���������肷�邱�Ƃ͌����֎~�ł��B
����ɁA���b�N�������Ă���̂��A�|���Ђł͂Ȃ��A���̐�̃\�[�X �N���C�A���g�ł���ꍇ������܂��B���̏ꍇ�A�|���Ђ����b�N�����ɂ��Ă͗�����������Ă��Ȃ��\��������̂ŁA�����|��҂�����ɕς��Ă��܂������ςȂ��ƂɂȂ�܂��B��낤�ƁA�Ȃ낤�ƁA���b�N����Ă��镔���ɏ���ɐG���̂͌��ւł��B
�܂��A�t�ɁA���b�N����Ă��Ȃ��̂ɍ�ƑΏۊO�Ƃ������Ƃ���������܂���B100% �}�b�`����ƑΏۊO�Ƃ���Ȃ�A���̕��߂̓��b�N���ꂽ��ԂŃt�@�C����n�����̂��ʏ�ł��B���́A��ƑΏۊO�ɂ�������炸���b�N����Ă��Ȃ��ꍇ�́A�K����ƑO�ɃR�[�f�B�l�[�^�[����Ɋm�F����悤�ɂ��Ă��܂��B
����́u���x�ȕ\���t�B���^�v�̉E�N���b�N �R�}���h�ł��B�ڂ����́u2021 �ŐV�����Ȃ����\���t�B���^�v���Q�Ƃ��Ă��������B
��L�̋L���ł��������Ă��܂����A���̉E�N���b�N �R�}���h�ɂ̓V���[�g�J�b�g �L�[�����蓖�Ă��܂��B���� Phrase �Ɠ�������ɂȂ�悤�Ɂu�I���t�B���^�v�� Ctrl+Shift+F �����蓖�ĂĂ��܂��B�܂��A�t�B���^�[�̉����� Ctrl+Alt+F6 �ʼn\�ł��B(���Ȃ�֗��ł��B)
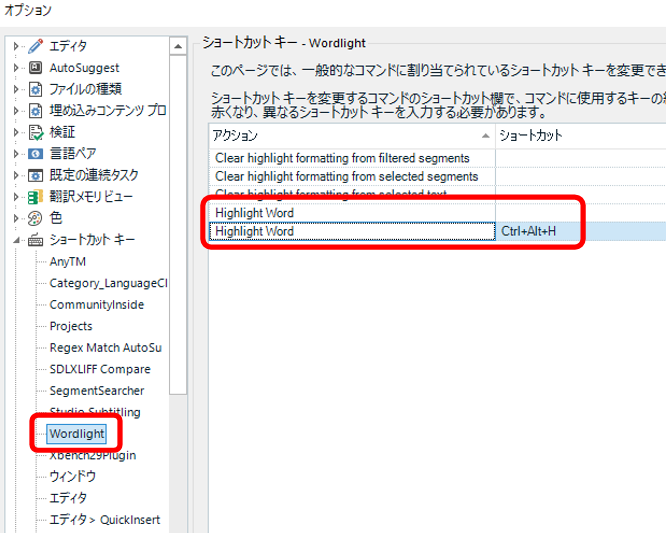
����̉ł̓G�f�B�^�[��� 1 �F�Ȃ�n�C���C�g��t������Ƃ̂��Ƃł����B����ȋ@�\�����������ǂ������̋L���ł͂悭�킩��܂��A�ЂƂ܂��A�Љ��Ă����v���O�C�� Wordlight ���C���X�g�[�����Ă݂܂����B������A�V���[�g�J�b�g �L�[��ݒ肷��ƂĂ��֗������ł��B
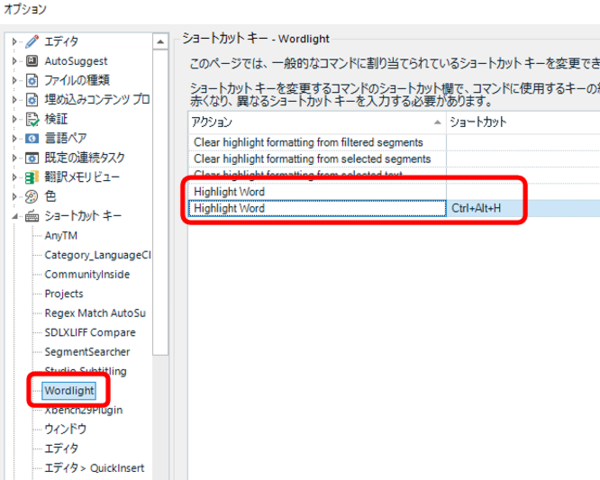
�V���[�g�J�b�g �L�[�̐ݒ��ʂɂ́uHighlight Word�v�Ƃ����������O�̃A�N�V������ 2 �\������Ă��܂��B���ۂɐݒ肵�Ă݂��Ƃ���A��̃A�N�V�����ł͐F�̑I����ʂ��\������܂����B���̃A�N�V�����ł́A�F�̑I����ʂ͕\�����ꂸ�A���̂܂܃n�C���C�g��t���邱�Ƃ��ł��܂����B
�u�p��x�[�X�̒P�ꐔ�ɐ����͂���܂����v�Ƃ�������ɑ��āu�o�^���ɐ����͂���܂���v�Ƃ���������Ă��܂������A���́A���̎���͗p��x�[�X���̗p�� 1 �� 1 �̒����ɐ����͂���̂��A�Ƃ����Ӗ��������̂ł͂Ȃ����Ǝv���܂����B
�ȑO�A�|���Ђ�����ꂽ�p�b�P�[�W�� UI �������������ɓo�^����Ă������Ƃ�����A���́u�������ł͒Z���p�ꂪ�q�b�g���Ȃ��̂ŗp��x�[�X�ɓo�^���Ă��炦�܂��v�Ƃ��肢�������Ƃ�����܂��B���̂Ƃ��ɖ|���Ђ���Ԃ��Ă����������u�G���[ ���b�Z�[�W�Ȃǂ̒������������Ă���̂ŁA�p��x�[�X�ł͂��܂��q�b�g���Ȃ��\��������܂��v�Ƃ������̂ł����B���ǁA�|���Ђ��u�������܂��v�ƌ����Ă���Ԃɂ��̃v���W�F�N�g�͏I�����A���������ł����B
�m���ɁA�p��x�[�X�ɒ�����������Ƃǂ��Ȃ�̂�������ƕs���ł��B�����ƃq�b�g���Ă���ł��傤���B���ہA�G���[ ���b�Z�[�W�ȂǁA������x�̒������������q�b�g���Ă��邱�Ƃ͂���̂ŁA�����炭���v���낤�ƌl�I�ɂ͍l���Ă��܂��B���̕ӂ�̂��Ƃ����̎���̓����ł͊��҂��Ă��܂����B
�Ȃ��A�p��F���̐ݒ�Ȃǂɂ��Ắu�p��x�[�X�̐ݒ��v���ǂ����Q�l�ɂ��Ă��������B
�܂��܂�����͂�������܂������A����͂����܂łƂ��܂��B���̎����Řb��ɏ�������Ŏ����~�����Ǝv�����@�\�́A�G�f�B�^�[��Ńt�H���g���w�肷��@�\�ƁA�J��Ԃ��̓K�p���ɖ��C���ł���@�\�ł��B�uIdeas �ɓ��e���Ă��������v�Ɖ������Ă��܂������A���������܂ł̓��̂�͒������ł��B
���̋L���ł́A���̊��z�ƕ⑫�������ȒP�ɂ܂Ƃ߂܂����B�ȉ��ɋ���������̃^�C�g������e�͂����܂Ŏ��̉��߂ł��B���̎��̉��߂��A���ۂɂ���������ꂽ���̐^�ӂ��炸��Ă��邩������܂��A���̕ӂ�͂��������������B
��ʂ̃J�X�^�}�C�Y
�|��A���r���[�A�����[�X�Ƃ������[�h���Ƃɉ�ʂ��J�X�^�}�C�Y�ł��邻���ł��B�������i�g���Ă����ʂ̃��C�A�E�g�͈ȑO�̋L���u�f���A�� �f�B�X�v���C�ł̍���v�ŏЉ�Ă���̂ł������������B
���̎���Ŏ����ł��C�ɂȂ����̂́A����̓��e���̂��̂ł͂Ȃ��ASDL �̕��́u���r���[�̂Ƃ��̓��������g���Ă��낢�낷�邱�Ƃ͂Ȃ��ł��傤����`�v�Ƃ����悤�Ȕ����ł��B���r���[�̂Ƃ��́A�����������܂�g��Ȃ����烁���� �y�C���͊���ʼn�ʉ����ɕ\������d�l�Ȃ̂������ł��B
���͈ȑO����A���r���[ ���[�h�̂Ƃ��ɂȂ������� �y�C������ʉ����ɕ\�������̂��^�₾�����̂ł����A���������J����Ђ̒��ł��������F���������̂ł��ˁB���������F����������A������r���[�������}�b�`���Ŋ���������肷�邱�Ƃ��Ȃ��ł���ˁH �����ł���ˁB�����āA���������g��Ȃ���ł�����B(���Ȃ݂ɁA�����Ȃ�����Ȃ��Ƃ������Ă���̂���������̋L�������ǂ݂��������B)
�v���W�F�N�g�̍\���ƃo�b�N�A�b�v����̕������@
sdlxliff �t�@�C���������o�b�N�A�b�v���Ă��邪�A���ۂɕ�������Ƃ��͂ǂ�����悢�̂��Ƃ������₪����܂����B
�v���W�F�N�g�̊e�t�@�C�����ǂ��Ɋi�[����Ă��邩��m��ɂ́A�v���W�F�N�g �r���[�őΏۂ̃v���W�F�N�g���E�N���b�N���A�\������郁�j���[���� [�v���W�F�N�g �t�H���_���J��] ��I�����܂��B����ŁA�v���W�F�N�g���i�[����Ă���t�H���_�[���G�N�X�v���[���[�ŊJ����܂��B
�J���ꂽ�t�H���_�[�̒��Ɂuen-US�v��uja-JP�v�ȂǁA���ꂲ�Ƃ̃t�H���_�[������Asdlxliff �t�@�C���͂��̌��ꂲ�Ƃ̃t�H���_�[�̒��Ɋi�[����Ă��܂��B
�����A�����̍�Ƃł� sdlxliff �t�@�C�����o�b�N�A�b�v�Ƃ��ĕۑ����Ă��܂��B�������≽���̐ݒ肪���Ă��܂������Ȃ��Ƃ��́A�|���Ђ�����ꂽ�p�b�P�[�W���J���Ȃ����A�o�b�N�A�b�v���Ă����� sdlxliff �t�@�C���������ɏ㏑�����܂��B����ŁA��������ݒ�͍ŏ��̏�Ԃɖ߂��A�͍��܂Ŗ����̂��ێ��ł��܂��B
�����̕��@�A�v���r���[�Ɩ����̈Ⴂ
Trados �ɂ́A������v���r���[�̕��@����������܂��B�v���r���[�Ɩ����̈Ⴂ�͎����������������̂ł����A����̉͂����܂ŏڂ������̂ł͂���܂���ł����B
��\��������@�ɂ��ẮA�ȑO�̋L�� �u�݂̂ŕۑ��v���g���Ă݂� �� �u�̕\���v���g���Ă݂� ���Q�Ƃ��Ă��������B
���������Љ��Ă����u�G�N�X�|�[�g�v�@�\�͏o�͐�Ȃǂ�ݒ�ł���̂łƂĂ��֗��ł��B�ȑO�̋L���u�����ɕ����̉�ʂ��J���v�ŊȒP�ɏЉ�Ă��܂��B
�Z�O�����e�[�V���� (���ߋK��)
�u�R�����ŕ�����Ȃ��悤�ɂ������v�u���ʓ��̋�_�ł͕�����Ăق����Ȃ��v�ȂǁA���ߋK���̐ݒ�͂Ȃ��Ȃ��ʓ|�ł��B�ݒ肷��ꏊ�́A�Ő�������Ă����Ƃ���A�|������ [���ꃊ�\�[�X] > [���ߋK��] �ł��B(�ڍׂȐݒ���@�́A���݂܂���A�Z�~�i�[�ł̉̂Ƃ��茟�����Ă��������B)
���̕��ߋK���ɂ��āA���͂��� SDL ����ɋ������Đ������Ăق����Ȃ��Ǝv���Ă��邱�Ƃ�����܂��B����́u���ߋK���͌�������荞�ޑO�ɐݒ肷��K�v������v���Ƃł��B�܂�A�p�b�P�[�W��n���ꂽ�|��҂͐ݒ��ς��邱�Ƃ��ł��܂���B�|���Ђ��p�b�P�[�W�����i�K�Őݒ������K�v������܂��B
�܂��A�ŋ߂́A�@�B�|���O�ɑ}������Ă��邱�Ƃ�����܂����A���ʓ��̋�_�ŕ������Ȃ��Ƃ����ݒ肪����Ă��Ȃ����߂ɁA�����r���Ő�A�@�B�|���܂��@�\���Ă��Ȃ����Ƃ��悭����܂��B���̐ݒ�������ɋ@�B�|���K�p���āA�����͊�������܂��˂��Č����Ă����Ђ��������܂��B�������̂��ƁA���ʓ��̋�_�ŕ������Ȃ��ݒ������ɂ������������C�����܂����A���߂ł����ˁB
�u���߂̃��b�N�v�̗p�r
���╶���ȒP�Ȃ��̂ł������A���u�w���v�����Ă��������v�Ƃ����ȒP�Ȃ��̂ł����B�����������₵�Ă���̂�����A�������������Ă����Ă�������Ȃ����Ɗ������̂Ŗ|��҂̗��ꂩ�班���⑫���܂��B
���b�N�������Ԃ̖ړI�́A�����炭�u��ƑΏۊO�ł��邱�Ƃ������v���Ƃł��B�|���Ђ���Ƃ̎d���̏ꍇ�A���b�N����Ă��镪�߂͊�{�I�ɍ�Ƃ����Ȃ��̂ŗ������������܂���B�܂�A���b�N�̗L���͗����ɒ��ڂ������܂��B���̂��߁A�|��ґ��Ń��b�N����������A���������肷�邱�Ƃ͌����֎~�ł��B
����ɁA���b�N�������Ă���̂��A�|���Ђł͂Ȃ��A���̐�̃\�[�X �N���C�A���g�ł���ꍇ������܂��B���̏ꍇ�A�|���Ђ����b�N�����ɂ��Ă͗�����������Ă��Ȃ��\��������̂ŁA�����|��҂�����ɕς��Ă��܂������ςȂ��ƂɂȂ�܂��B��낤�ƁA�Ȃ낤�ƁA���b�N����Ă��镔���ɏ���ɐG���̂͌��ւł��B
�܂��A�t�ɁA���b�N����Ă��Ȃ��̂ɍ�ƑΏۊO�Ƃ������Ƃ���������܂���B100% �}�b�`����ƑΏۊO�Ƃ���Ȃ�A���̕��߂̓��b�N���ꂽ��ԂŃt�@�C����n�����̂��ʏ�ł��B���́A��ƑΏۊO�ɂ�������炸���b�N����Ă��Ȃ��ꍇ�́A�K����ƑO�ɃR�[�f�B�l�[�^�[����Ɋm�F����悤�ɂ��Ă��܂��B
�E�N���b�N�́u�I���t�B���^�v�u�����t�B���^�v�u�t�B���^�v
����́u���x�ȕ\���t�B���^�v�̉E�N���b�N �R�}���h�ł��B�ڂ����́u2021 �ŐV�����Ȃ����\���t�B���^�v���Q�Ƃ��Ă��������B
��L�̋L���ł��������Ă��܂����A���̉E�N���b�N �R�}���h�ɂ̓V���[�g�J�b�g �L�[�����蓖�Ă��܂��B���� Phrase �Ɠ�������ɂȂ�悤�Ɂu�I���t�B���^�v�� Ctrl+Shift+F �����蓖�ĂĂ��܂��B�܂��A�t�B���^�[�̉����� Ctrl+Alt+F6 �ʼn\�ł��B(���Ȃ�֗��ł��B)
�n�C���C�g
����̉ł̓G�f�B�^�[��� 1 �F�Ȃ�n�C���C�g��t������Ƃ̂��Ƃł����B����ȋ@�\�����������ǂ������̋L���ł͂悭�킩��܂��A�ЂƂ܂��A�Љ��Ă����v���O�C�� Wordlight ���C���X�g�[�����Ă݂܂����B������A�V���[�g�J�b�g �L�[��ݒ肷��ƂĂ��֗������ł��B
�V���[�g�J�b�g �L�[�̐ݒ��ʂɂ́uHighlight Word�v�Ƃ����������O�̃A�N�V������ 2 �\������Ă��܂��B���ۂɐݒ肵�Ă݂��Ƃ���A��̃A�N�V�����ł͐F�̑I����ʂ��\������܂����B���̃A�N�V�����ł́A�F�̑I����ʂ͕\�����ꂸ�A���̂܂܃n�C���C�g��t���邱�Ƃ��ł��܂����B
�p��x�[�X�̒P�ꐔ
�u�p��x�[�X�̒P�ꐔ�ɐ����͂���܂����v�Ƃ�������ɑ��āu�o�^���ɐ����͂���܂���v�Ƃ���������Ă��܂������A���́A���̎���͗p��x�[�X���̗p�� 1 �� 1 �̒����ɐ����͂���̂��A�Ƃ����Ӗ��������̂ł͂Ȃ����Ǝv���܂����B
�ȑO�A�|���Ђ�����ꂽ�p�b�P�[�W�� UI �������������ɓo�^����Ă������Ƃ�����A���́u�������ł͒Z���p�ꂪ�q�b�g���Ȃ��̂ŗp��x�[�X�ɓo�^���Ă��炦�܂��v�Ƃ��肢�������Ƃ�����܂��B���̂Ƃ��ɖ|���Ђ���Ԃ��Ă����������u�G���[ ���b�Z�[�W�Ȃǂ̒������������Ă���̂ŁA�p��x�[�X�ł͂��܂��q�b�g���Ȃ��\��������܂��v�Ƃ������̂ł����B���ǁA�|���Ђ��u�������܂��v�ƌ����Ă���Ԃɂ��̃v���W�F�N�g�͏I�����A���������ł����B
�m���ɁA�p��x�[�X�ɒ�����������Ƃǂ��Ȃ�̂�������ƕs���ł��B�����ƃq�b�g���Ă���ł��傤���B���ہA�G���[ ���b�Z�[�W�ȂǁA������x�̒������������q�b�g���Ă��邱�Ƃ͂���̂ŁA�����炭���v���낤�ƌl�I�ɂ͍l���Ă��܂��B���̕ӂ�̂��Ƃ����̎���̓����ł͊��҂��Ă��܂����B
�Ȃ��A�p��F���̐ݒ�Ȃǂɂ��Ắu�p��x�[�X�̐ݒ��v���ǂ����Q�l�ɂ��Ă��������B
�܂��܂�����͂�������܂������A����͂����܂łƂ��܂��B���̎����Řb��ɏ�������Ŏ����~�����Ǝv�����@�\�́A�G�f�B�^�[��Ńt�H���g���w�肷��@�\�ƁA�J��Ԃ��̓K�p���ɖ��C���ł���@�\�ł��B�uIdeas �ɓ��e���Ă��������v�Ɖ������Ă��܂������A���������܂ł̓��̂�͒������ł��B
| �@�@ |
�^�O�F����� �\���t�B���^ �v���O�C�� ���x�ȕ\���t�B���^ �p��x�[�X �n�C���C�g Wordlight ���ߋK�� �t�@�C���̃G�N�X�|�[�g
Tweet
2023�N04��24��
���ՂɃo�C�����K�� Excel ���g���Ă��܂���
�ŋ߁A��������X�V�p�x�������Ă��܂����ATrados �̃l�^���s�����킯�ł͂���܂���B���v�ł��B�����������Ƃ͂܂�������������܂��̂ŁA�ǂ����C���ɂ��t���������������܂��B
����� Excel �t�@�C���̖|��ɂ��Ăł��BTrados �� Excel �t�@�C���ɑ��Ă����Ȃ�L�x�ȋ@�\������Ă��܂��B���ɁA���}�̂悤�Ɍ����ƖL����`���ɂ́u�o�C�����K�� Excel�v�Ƃ����t�@�C���̎�ނ��֗��ł� (�o�C�����K�� Excel �ɂ��ẮA�����T�C�g�̃u���O�u�Ζ�`���� Excel ��|�����ɕϊ��v����сuTrados Studio 2022 �ő����� Excel �t�@�C����|����@�v���Q�Ƃ��Ă�������)�B ���A���L�̌`��������Ƃ����āA���ՂɃo�C�����K�� Excel ���g�����Ƃ͂��܂肨���߂ł��܂���B
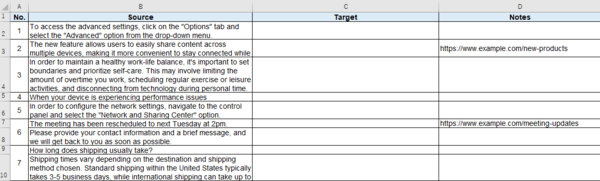
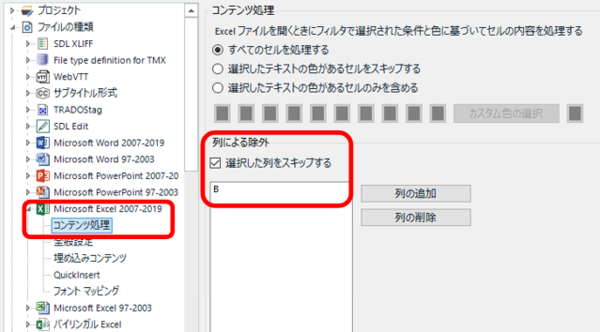
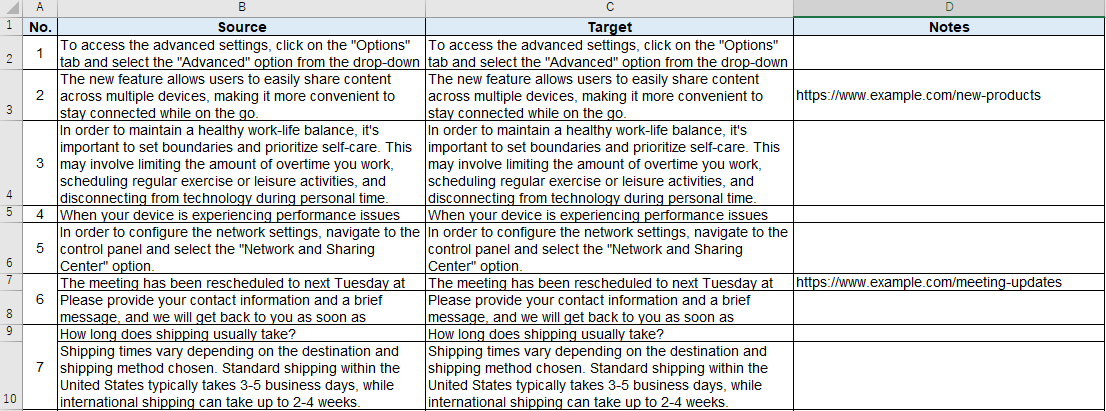
��Ƃ��āA�ȉ��̃t�@�C������Ƃ��l���Ă݂܂��傤�BA ��ɂ́A���ʎq�ƂȂ�ԍ����U���Ă��܂��BD ��ɂ́A�Q�Ƃ��� URL ���L�ڂ���Ă��܂��BNo. 3 �̃Z���ɂ́A���������܂܂�Ă��܂��B
���āA���̃t�@�C�����u�o�C�����K�� Excel�v�Ƃ��� Trados �Ɏ�荞�ނƈȉ��̂悤�ɂȂ��Ă��܂��܂��B
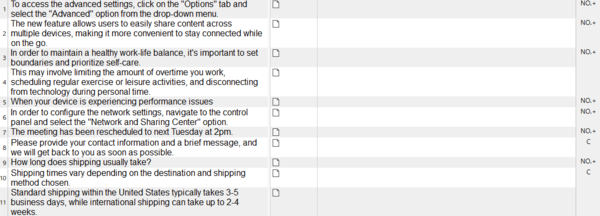
�ő���ɐݒ���{���Ă����ꂪ���E�ł� (�ݒ�̏ڍׂ͌�q���܂�)�B�ǂ��ł��傤�H�H ����Ŗ�ł��傤���B�ԍ���Q�Ƃ� URL �͂Ȃ��Ȃ��Ă��܂��BNo. 3 �̃Z�����A�����̕�����荞�܂�Ă͂��܂����A���̃Z���Ƃ̋�肪�킩��Ȃ��Ȃ��Ă��܂��B
���ꂪ�A���}�̂悤�ɂȂ��Ă�����ǂ��ł��傤���B������̕����₷���Ȃ��ł��傤���B
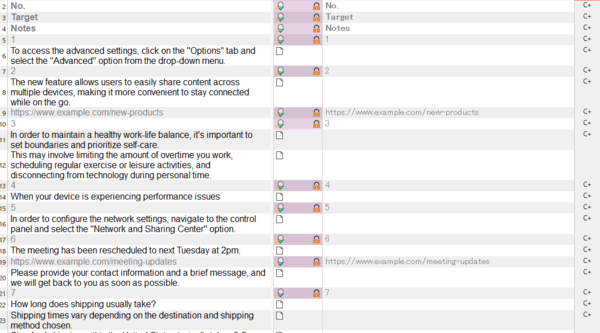
��}�́uMicrosoft Excel 2007-2019�v�Ƃ����t�@�C���̎�ނ��g���Ēʏ�� Excel �t�@�C���Ƃ��Ď�荞��ł��B�ԍ��� URL ���G�f�B�^�[�ɕ\������Ă��܂��B�����A���b�N����Ă���̂ŁA������Ă��܂��S�z�͂���܂���B�ԍ����\������Ă��邱�Ƃɂ���āA�Z���̋�肪�킩��₷���Ȃ�A�ԍ��Ō��������邱�Ƃ��\�ɂȂ�܂��B�N�G���������Ƃ��ɂ͔ԍ��Ȃǂ��L�����Ȃ���Ȃ�Ȃ����Ƃ�����̂ŁA���������ꍇ�ɂ��ԍ����\������Ă��������֗��ł��B
�u�o�C�����K�� Excel�v�Ƃ����t�@�C���̎�ނ́A��y�Ŏg���₷���͂���܂����A���ۂɖ|���Ƃ��s�����Ƃ��l����ƕK�������֗��ł͂���܂���B�ԍ���Z���̋��ȂǁA�|��ɕK�v�ȏ�����Ă��܂��܂��B�o�C�����K�� Excel ���ł��L���ɋ@�\����̂́u�����Ɩ̃e�L�X�g�����݂��邩�牽�Ƃ��������ɂ������v�Ƃ����Ƃ����Ǝv���܂��B�|���Ƃ�����Ȃ�A���ՂɃo�C�����K�� Excel ��I������̂ł͂Ȃ��A���̌`���̋@�\�������čl���A�{���ɖ|�₷�����ɂȂ�悤�ɑ����̍H�v���{�����Ƃ��K�v�ł��B
�Ƃ����킯�ŁA���܂肨���߂͂��Ȃ��o�C�����K�� Excel �ł����A�ݒ�͂��낢��Ɨp�ӂ���Ă���̂ŏ��������Љ�܂��B��ɋ�������ł́A�ȉ��̐ݒ���g���Ă��܂��B
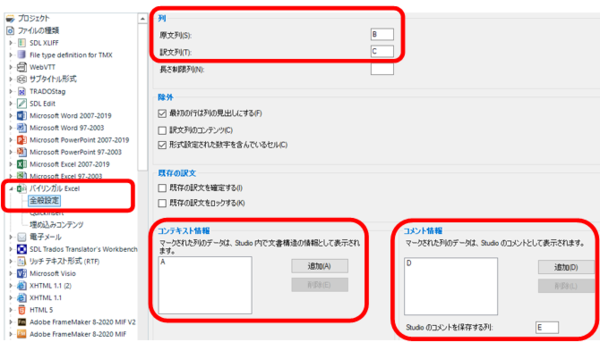
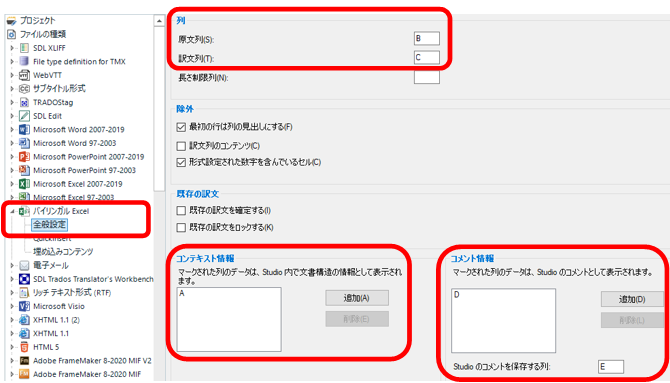
�� (������Ɩ�)
�����Ɩ̗���w�肵�܂��B�����Ɩ� Excel �� 1 ��ڂ� 2 ��ڂł���K�v�͂���܂���B�ǂ��ɂ����Ă��A�ǂ��炪��ɂ����Ă����܂��܂���B���̐ݒ���g���A�����Ɩ��ȒP�ɓ���ւ������Ƃ��ł��܂��B
�R���e�L�X�g���
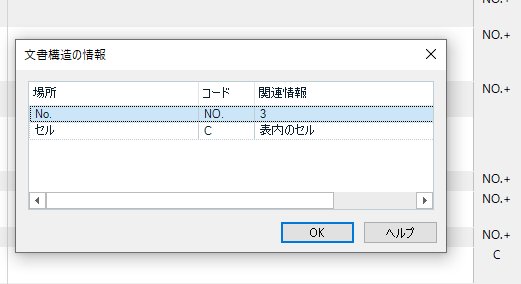
���́AA ��ɂ���ԍ��́u�����\���v�Ƃ��Ď�荞��ł��܂��B�G�f�B�^�[�̉E�[�ɕ\������Ă���uNO.�v������ł��B�N���b�N����ƁA���}�̂悤�ɁuNo. 3�v�Ƃ�����\������܂��B
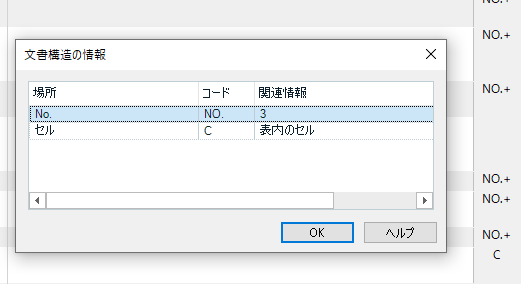
�����A���������N���b�N���邱�Ƃ͂��蓾�Ȃ��̂ŁA�����ɏ�����荞��ł��܂��𗧂��܂���B�ꉞ�ARWS AppStore �ɂ́A���̕����\����� (Document Structure Information) ���킩��₷���\�����邽�߂̃A�v���uDSI Viewer�v���p�ӂ���Ă��܂��B(���݂܂���A���͎g���Ă��Ȃ��̂ŏڂ��������͏ȗ����܂��B)
�R�����g���
����Ɏ��́AD ��̎Q�� URL �̓R�����g�Ƃ��Ď�荞��ł��܂��B�����A�R�����g���A�|���Ƃ�����G�f�B�^�[�Ƃ͕ʃ^�u�ɕ\�������̂ł��܂茩�₷���Ƃ͂����܂���B
�Ȃ��A�ݒ�̈�ԉ��ɂ��� [Studio �̃R�����g��ۑ������] ���w�肷��ƁATrados ��Œlj������R�����g�� Excel �t�@�C����̓���̗�ɏo�͂ł��܂��B
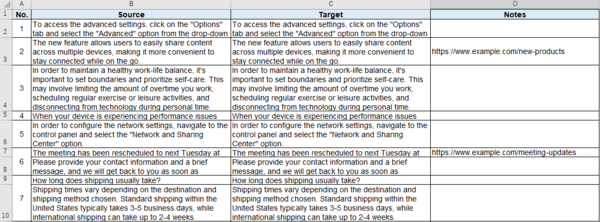
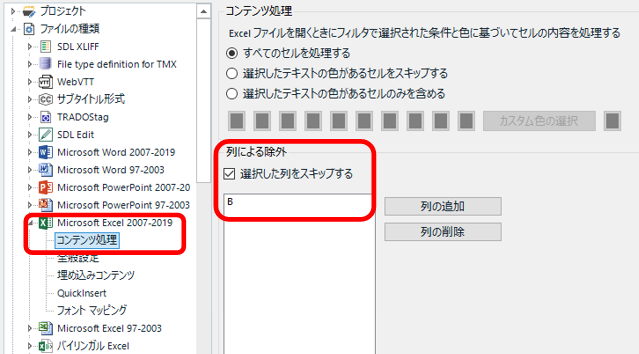
�ł́A���ɕ��ʂ� Excel �t�@�C���Ƃ��Ď�荞�ނƂ��̐ݒ���Љ�܂��B�g�p����t�@�C���̎�ނ́uMicrosoft Excel 2007-2019�v�ł��B�܂��A��荞�ޑO�ɁA������ Excel �t�@�C���� 1 �������H�����܂��B���}�̂悤�ɁASource ������̂܂� Target ��ɃR�s�[���܂��B���ꂾ���ł��BTrados ��ł́A���X�� Source ��͖������āA�R�s�[���� Target ���|�Ă����܂��B
�R���e���c���� -> ��ɂ�鏜�O
����̗�����O�ł��܂��B����̗�ł́ASource �̗s�v�Ȃ̂ŁAB ����X�L�b�v���܂��BNotes �̗�͏��O�����ɂ��̂܂�荞�݂܂��B����� Notes �� URL �݂̂Ȃ̂Ŏ�荞��ł��܂����A�������͂ł̐����̂悤�ȏꍇ�ɂ͎�荞�ނƕԂ��Ė|���Ƃ����ɂ����Ȃ邱�Ƃ�����܂��B�ɉ����āA��荞�ނ��A���O���邩�f���܂��B
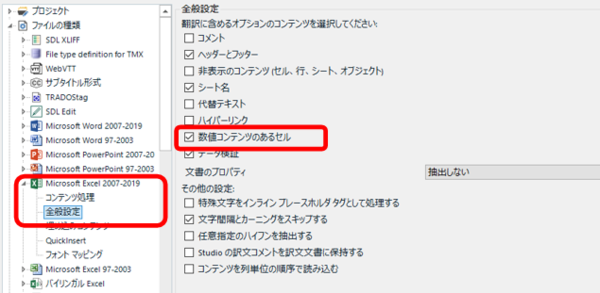
�S�ʐݒ� -> ���l�R���e���c�̂���Z��
����̗�ł́AA ��̔ԍ������l�Ȃ̂� [���l�R���e���c�̂���Z��] �`�F�b�N�{�b�N�X���I���ɂ��܂��B���ꂪ�I�t�̏ꍇ�A���l�݂̂̃Z���� Trados �Ŗ|��ΏۂɂȂ�܂���B
�ݒ�͈ȏ�ł��B����� Excel �t�@�C������荞�݂܂��B��荞��́A���l�݂̂̕��߂� URL �݂̂̕��߂��t�B���^�[�Œ��o���A���b�N���Ċ����ł��B
�ԍ��� Notes ������̗�̂悤�ɒP���łȂ��ꍇ�A�t�B���^�[�ł��܂����o����ɂ͐��K�\���Ȃǂ��K�v�ɂȂ邩������܂���B���̒��o���ł��邩�ǂ������A�ʏ�� Excel �t�@�C�����g�����A������߂ăo�C�����K�� Excel ���g�����̕�����ڂɂȂ�܂��B�ォ�璊�o���ă��b�N�ł���Ȃ�A�e�L�X�g�Ƃ��� Trados �Ɏ�荞��ł��܂��܂��B���o�ł��Ȃ��Ȃ�A�ŏ������荞�܂Ȃ��悤�ɂ��邵������܂���BNotes �͖����Ƃ��Ă��A�`���̌��܂��Ă���ԍ��� ID �Ȃǂ͒��o����r�I�ȒP�Ȃ̂ŁA�ł��邾�� Trados �Ɏ�荞�ޕ����ōl����悤�ɂ��܂��B
����͈ȏ�ł��B�|���Ђ�������p�b�P�[�W�ł̓o�C�����K�� Excel ���g���Ă��邱�Ƃ������ł����A���낢��ȏ����̂ĂĂ����āA�R���e�L�X�g�����낾�́A�N�G���ɂ� ID ���L�����낾�́A����Ȃ��Ƃ��茾���Ă��A�|��҂����đΉ�������Ȃ��ł���`
Tweet
����� Excel �t�@�C���̖|��ɂ��Ăł��BTrados �� Excel �t�@�C���ɑ��Ă����Ȃ�L�x�ȋ@�\������Ă��܂��B���ɁA���}�̂悤�Ɍ����ƖL����`���ɂ́u�o�C�����K�� Excel�v�Ƃ����t�@�C���̎�ނ��֗��ł� (�o�C�����K�� Excel �ɂ��ẮA�����T�C�g�̃u���O�u�Ζ�`���� Excel ��|�����ɕϊ��v����сuTrados Studio 2022 �ő����� Excel �t�@�C����|����@�v���Q�Ƃ��Ă�������)�B ���A���L�̌`��������Ƃ����āA���ՂɃo�C�����K�� Excel ���g�����Ƃ͂��܂肨���߂ł��܂���B
��Ƃ��āA�ȉ��̃t�@�C������Ƃ��l���Ă݂܂��傤�BA ��ɂ́A���ʎq�ƂȂ�ԍ����U���Ă��܂��BD ��ɂ́A�Q�Ƃ��� URL ���L�ڂ���Ă��܂��BNo. 3 �̃Z���ɂ́A���������܂܂�Ă��܂��B
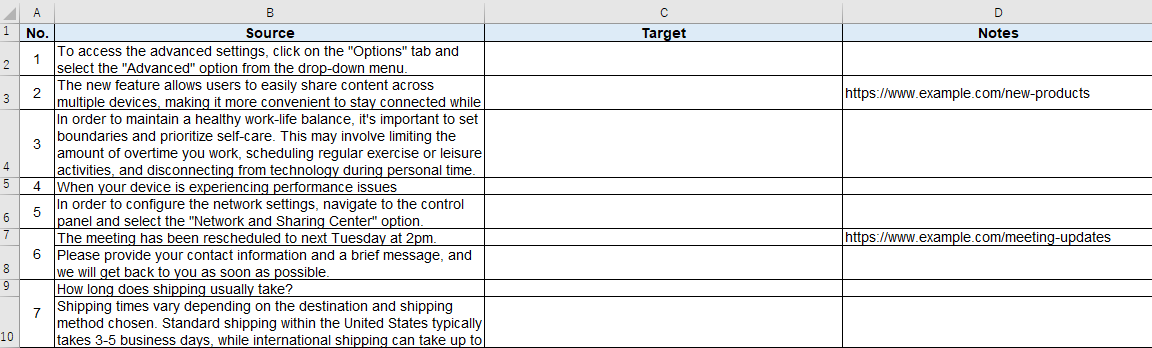
���āA���̃t�@�C�����u�o�C�����K�� Excel�v�Ƃ��� Trados �Ɏ�荞�ނƈȉ��̂悤�ɂȂ��Ă��܂��܂��B
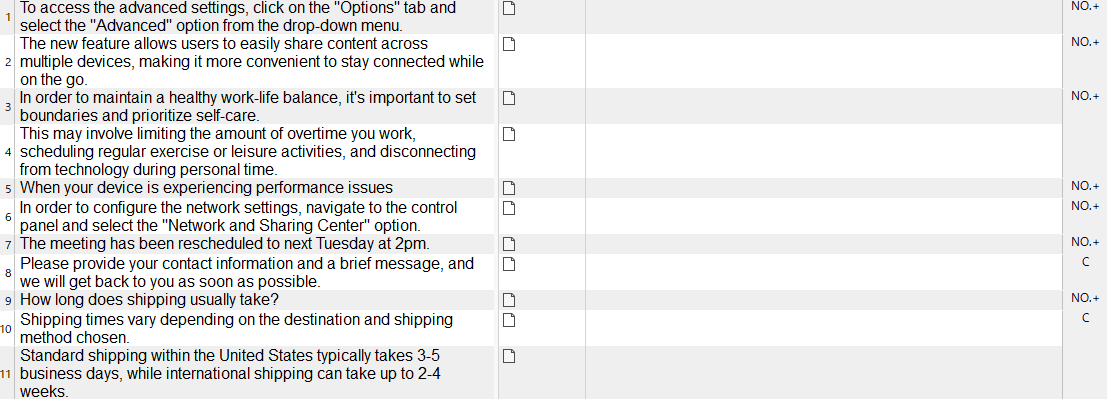
�ő���ɐݒ���{���Ă����ꂪ���E�ł� (�ݒ�̏ڍׂ͌�q���܂�)�B�ǂ��ł��傤�H�H ����Ŗ�ł��傤���B�ԍ���Q�Ƃ� URL �͂Ȃ��Ȃ��Ă��܂��BNo. 3 �̃Z�����A�����̕�����荞�܂�Ă͂��܂����A���̃Z���Ƃ̋�肪�킩��Ȃ��Ȃ��Ă��܂��B
���ꂪ�A���}�̂悤�ɂȂ��Ă�����ǂ��ł��傤���B������̕����₷���Ȃ��ł��傤���B

��}�́uMicrosoft Excel 2007-2019�v�Ƃ����t�@�C���̎�ނ��g���Ēʏ�� Excel �t�@�C���Ƃ��Ď�荞��ł��B�ԍ��� URL ���G�f�B�^�[�ɕ\������Ă��܂��B�����A���b�N����Ă���̂ŁA������Ă��܂��S�z�͂���܂���B�ԍ����\������Ă��邱�Ƃɂ���āA�Z���̋�肪�킩��₷���Ȃ�A�ԍ��Ō��������邱�Ƃ��\�ɂȂ�܂��B�N�G���������Ƃ��ɂ͔ԍ��Ȃǂ��L�����Ȃ���Ȃ�Ȃ����Ƃ�����̂ŁA���������ꍇ�ɂ��ԍ����\������Ă��������֗��ł��B
�u�o�C�����K�� Excel�v�Ƃ����t�@�C���̎�ނ́A��y�Ŏg���₷���͂���܂����A���ۂɖ|���Ƃ��s�����Ƃ��l����ƕK�������֗��ł͂���܂���B�ԍ���Z���̋��ȂǁA�|��ɕK�v�ȏ�����Ă��܂��܂��B�o�C�����K�� Excel ���ł��L���ɋ@�\����̂́u�����Ɩ̃e�L�X�g�����݂��邩�牽�Ƃ��������ɂ������v�Ƃ����Ƃ����Ǝv���܂��B�|���Ƃ�����Ȃ�A���ՂɃo�C�����K�� Excel ��I������̂ł͂Ȃ��A���̌`���̋@�\�������čl���A�{���ɖ|�₷�����ɂȂ�悤�ɑ����̍H�v���{�����Ƃ��K�v�ł��B
�u�o�C�����K�� Excel�v�̐ݒ�
�Ƃ����킯�ŁA���܂肨���߂͂��Ȃ��o�C�����K�� Excel �ł����A�ݒ�͂��낢��Ɨp�ӂ���Ă���̂ŏ��������Љ�܂��B��ɋ�������ł́A�ȉ��̐ݒ���g���Ă��܂��B
�� (������Ɩ�)
�����Ɩ̗���w�肵�܂��B�����Ɩ� Excel �� 1 ��ڂ� 2 ��ڂł���K�v�͂���܂���B�ǂ��ɂ����Ă��A�ǂ��炪��ɂ����Ă����܂��܂���B���̐ݒ���g���A�����Ɩ��ȒP�ɓ���ւ������Ƃ��ł��܂��B
�R���e�L�X�g���
���́AA ��ɂ���ԍ��́u�����\���v�Ƃ��Ď�荞��ł��܂��B�G�f�B�^�[�̉E�[�ɕ\������Ă���uNO.�v������ł��B�N���b�N����ƁA���}�̂悤�ɁuNo. 3�v�Ƃ�����\������܂��B
�����A���������N���b�N���邱�Ƃ͂��蓾�Ȃ��̂ŁA�����ɏ�����荞��ł��܂��𗧂��܂���B�ꉞ�ARWS AppStore �ɂ́A���̕����\����� (Document Structure Information) ���킩��₷���\�����邽�߂̃A�v���uDSI Viewer�v���p�ӂ���Ă��܂��B(���݂܂���A���͎g���Ă��Ȃ��̂ŏڂ��������͏ȗ����܂��B)
�R�����g���
����Ɏ��́AD ��̎Q�� URL �̓R�����g�Ƃ��Ď�荞��ł��܂��B�����A�R�����g���A�|���Ƃ�����G�f�B�^�[�Ƃ͕ʃ^�u�ɕ\�������̂ł��܂茩�₷���Ƃ͂����܂���B
�Ȃ��A�ݒ�̈�ԉ��ɂ��� [Studio �̃R�����g��ۑ������] ���w�肷��ƁATrados ��Œlj������R�����g�� Excel �t�@�C����̓���̗�ɏo�͂ł��܂��B
�uMicrosoft Excel 2007-2019�v�̐ݒ�
�ł́A���ɕ��ʂ� Excel �t�@�C���Ƃ��Ď�荞�ނƂ��̐ݒ���Љ�܂��B�g�p����t�@�C���̎�ނ́uMicrosoft Excel 2007-2019�v�ł��B�܂��A��荞�ޑO�ɁA������ Excel �t�@�C���� 1 �������H�����܂��B���}�̂悤�ɁASource ������̂܂� Target ��ɃR�s�[���܂��B���ꂾ���ł��BTrados ��ł́A���X�� Source ��͖������āA�R�s�[���� Target ���|�Ă����܂��B
�R���e���c���� -> ��ɂ�鏜�O
����̗�����O�ł��܂��B����̗�ł́ASource �̗s�v�Ȃ̂ŁAB ����X�L�b�v���܂��BNotes �̗�͏��O�����ɂ��̂܂�荞�݂܂��B����� Notes �� URL �݂̂Ȃ̂Ŏ�荞��ł��܂����A�������͂ł̐����̂悤�ȏꍇ�ɂ͎�荞�ނƕԂ��Ė|���Ƃ����ɂ����Ȃ邱�Ƃ�����܂��B�ɉ����āA��荞�ނ��A���O���邩�f���܂��B
�S�ʐݒ� -> ���l�R���e���c�̂���Z��
����̗�ł́AA ��̔ԍ������l�Ȃ̂� [���l�R���e���c�̂���Z��] �`�F�b�N�{�b�N�X���I���ɂ��܂��B���ꂪ�I�t�̏ꍇ�A���l�݂̂̃Z���� Trados �Ŗ|��ΏۂɂȂ�܂���B

�ݒ�͈ȏ�ł��B����� Excel �t�@�C������荞�݂܂��B��荞��́A���l�݂̂̕��߂� URL �݂̂̕��߂��t�B���^�[�Œ��o���A���b�N���Ċ����ł��B
�ԍ��� Notes ������̗�̂悤�ɒP���łȂ��ꍇ�A�t�B���^�[�ł��܂����o����ɂ͐��K�\���Ȃǂ��K�v�ɂȂ邩������܂���B���̒��o���ł��邩�ǂ������A�ʏ�� Excel �t�@�C�����g�����A������߂ăo�C�����K�� Excel ���g�����̕�����ڂɂȂ�܂��B�ォ�璊�o���ă��b�N�ł���Ȃ�A�e�L�X�g�Ƃ��� Trados �Ɏ�荞��ł��܂��܂��B���o�ł��Ȃ��Ȃ�A�ŏ������荞�܂Ȃ��悤�ɂ��邵������܂���BNotes �͖����Ƃ��Ă��A�`���̌��܂��Ă���ԍ��� ID �Ȃǂ͒��o����r�I�ȒP�Ȃ̂ŁA�ł��邾�� Trados �Ɏ�荞�ޕ����ōl����悤�ɂ��܂��B
����͈ȏ�ł��B�|���Ђ�������p�b�P�[�W�ł̓o�C�����K�� Excel ���g���Ă��邱�Ƃ������ł����A���낢��ȏ����̂ĂĂ����āA�R���e�L�X�g�����낾�́A�N�G���ɂ� ID ���L�����낾�́A����Ȃ��Ƃ��茾���Ă��A�|��҂����đΉ�������Ȃ��ł���`
| �@�@ |
2023�N03��17��
�̃t�H���g��ς�����
�����Ԃ�v���Ԃ�̍X�V�ɂȂ��Ă��܂��܂����B����́ATrados �Ŗ������̃t�H���g�ɂ��Ăł��B�ŋ߂̎d���ŁA�|���Ђ��� Trados �̃p�b�P�[�W�ł͂Ȃ��AWord �� PowerPoint �̃t�@�C�������̂܂ܓn����Ė|�邱�Ƃ�������܂����B�����̃t�@�C�������̂܂ܓn�����ꍇ�A�ׂ������C�A�E�g�͕ʍ�ƂƂ��Ă��A�t�H���g�̎w�肭�炢�͂���邱�Ƃ��悭����܂��B����́A������ Trados �Ƀt�@�C������荞��ŖƂ��ɁA�̃t�H���g��ݒ肷����@��������܂��B
����̋L���ł́A������ Trados �Ƀt�@�C������荞��ō�Ƃ���ꍇ�̕��@���Љ�܂��B�c�O�Ȃ���A�|���Ђ���p�b�P�[�W��n���ꂽ�ꍇ�͎����Ō����t�@�C������荞�ނ��Ƃ��ł��Ȃ��̂ŁA�p�b�P�[�W���̃t�@�C�������̂܂g�p���邵������܂���B�u�t�@�C���̎�ށv�ɂ���t�H���g �}�b�s���O�������ŕύX���邱�Ƃ͂ł��܂����A�u�t�@�C���̎�ށv�ɂ͖|���Ђ����炩�̐ݒ�����Ă��Ă���ꍇ������܂��B���̒��̐ݒ��ύX����ꍇ�́A���ꂮ����T�d�ɍs���Ă��������B
����̋L���́A�v���r���[������̏����ō����t�@�C���̃t�H���g�ɂ��Ă̐����ł��B�G�f�B�^�[�ɕ\������镶���̃t�H���g�ł͂���܂���B�G�f�B�^�[�̕\���Ŏg����t�H���g�ɂ��ẮA�ȑO�̋L���u�G�f�B�^��̃t�H���g��ς����v���Q�l�ɂ��Ă��������B
�ł́A�t�H���g��ݒ肷����@��������Ă����܂��傤�B�܂��́A�p���|��̏ꍇ�ł��B
PowerPoint �t�@�C���̉p���|������Ă���Ƃ��ɁA�t�@�C���œ��{��̃t�H���g�������ɂȂ�v���[���e�[�V�����̌����ڂ������c�O�Ȋ����ɂȂ��Ă��܂������Ƃ͂���܂��B����́u�t�@�C���̎�ށv�̃t�H���g �}�b�s���O�ł��ׂẴt�H���g�ɁuMS Mincho�v���ݒ肳��Ă��邩��ł��B
�����炭����ŁA���}�̂悤�ɁA[�v���W�F�N�g�̐ݒ�] > [�t�@�C���̎��] > [PowerPoint 2007-2019] > [�t�H���g �}�b�s���O] �̓��{��ɑ��� <AllFonts> �� MS Mincho �ɕϊ�����ݒ肪����Ă��܂��B
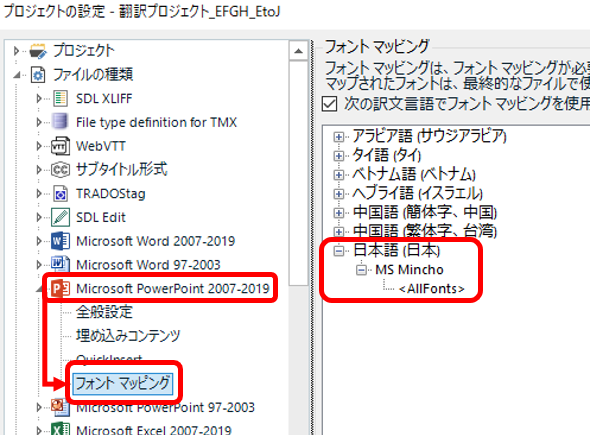
���̃}�b�s���O���L���ɂȂ��Ă���ƁA�t�@�C���ł��ׂẴt�H���g�������ɕϊ�����܂��B
�� ���ׂẴt�H���g�������ɕϊ������

�����ł͂Ȃ��ʂ̃t�H���g�ɕϊ��������ꍇ�́A��}�̉�ʂ� [MS Mincho] ���E�N���b�N���� [�I�������A�C�e���̍폜] ��I�����A�t�H���g�̐ݒ����������폜���܂��B���̌�� [���{��] ���E�N���b�N���� [�V�K�t�H���g�̒lj�] ��I�����A�t�H���g��lj����܂��B���}�̂悤�ȉ�ʂ��\�������̂ŁA[�����̃t�H���g] �ł͉����� [�����̃t�H���g�����ׂă}�b�v] ��I�����A[�̃t�H���g] �Ŏg�p�������t�H���g��I�����܂� (���̗�ł́AMeiryo UI ��I�����Ă��܂�)�B
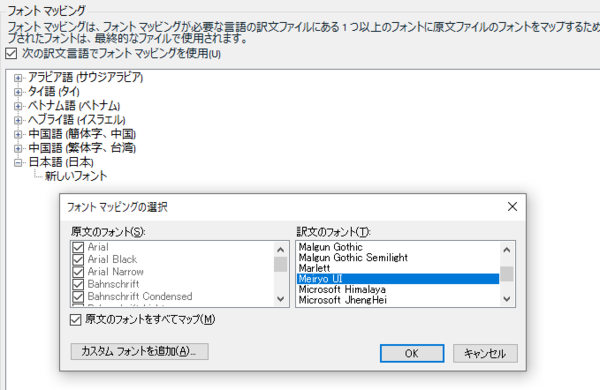
����ŁA[OK] ���N���b�N����ƁA���}�̂悤�� <AllFonts> �� Meiryo UI �ɕϊ�����ݒ�ɂȂ�܂��B
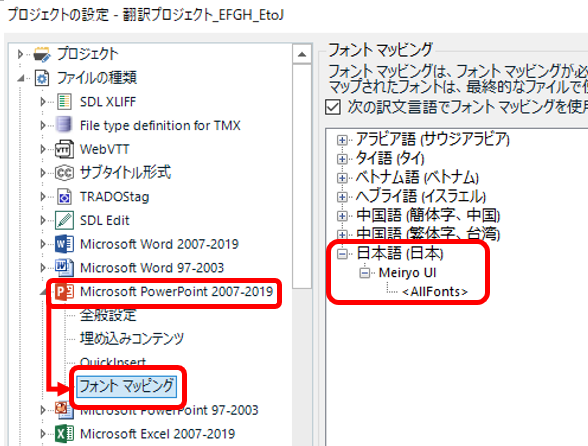
���̐ݒ�Ŗ���������ƁA���x�͂��ׂẴt�H���g�� Meiryo UI �ɕϊ�����܂��B
�� ���ׂẴt�H���g�� Meiryo UI �ɕϊ������

��}�� [�t�H���g �}�b�s���O�̑I��] ��ʂł́A�������u���ׂẴt�H���g�v�ł͂Ȃ��A�ʂ̃t�H���g��ݒ肷�邱�Ƃ��ł��܂��B�t�H���g���Ƃɕϊ����[�������܂��Ă���ꍇ�͌X�ɐݒ���s���܂��B
���Ȃ݂ɁA��L�Ŏg�p���� Meiryo UI �ɂ͎Α̂����݂��܂���BTrados �̃G�f�B�^�[��Ń^�O���g�p���ĎΑ̂�ݒ肵�Ă��Ă��A�t�@�C���� Meiryo UI �ɕύX���Ă��܂��Ɛ��̂ŕ\������܂� (���́ATrados �̃o�O�Ȃ�Ȃ����Ǝv���Ă����̂ł����A�����ł͂���܂���ł���)�B���{�ꕶ���ŎΑ̂��Ӑ}�I�Ɏg�����Ƃ͏��Ȃ��Ǝv���܂����A�����Α̂��g�������ꍇ�͑��̃t�H���g���g�p����K�v������܂��B
�t�H���g �}�b�s���O�̐ݒ�ł́ATrados �ł̃t�H���g�ϊ�����ؖ����ɂ��邱�Ƃ��ł��܂��B�t�H���g�ϊ����ɂ������ꍇ�́A��}�̉�ʂ� [���{��] ���E�N���b�N���� [�I�������A�C�e���̍폜] ��I�����A���{��̐ݒ肻�̂��̂��폜���܂��B����ŁA�t�H���g�̕ϊ��͍s��ꂸ�A������ PowerPoint �t�@�C���Őݒ肳��Ă�����{��p�t�H���g���g�p�����悤�ɂȂ�܂��B
�� �t�H���g�ϊ����ɂ���ƁA�����t�@�C���Őݒ肳��Ă���t�H���g���g�p�����

�����t�@�C���ɓ��{��p�t�H���g��������Ɛݒ肳��Ă���ꍇ�́ATrados �ł̕ϊ��͖����ɂ���̂������߂ł��B�����A�p��̌����t�@�C���œ��{��p�̃t�H���g���ݒ肳��Ă��邱�Ƃ͂܂�ł��B�����Ă��́A�ݒ肪����Ă��Ȃ����߂ɁA���炩�̊���l���g�p����Ă��܂����ƂɂȂ�܂��B���̂��߁ATrados �ł̃t�H���g�ϊ����ɂ���ꍇ�́A�����t�@�C���ɑ��Ď����Ńt�H���g�̐ݒ���s���Ă����K�v������܂��B
�t�H���g �}�b�s���O�ɂ��ϊ����s��Ȃ��ꍇ�́ATrados �Ƀt�@�C������荞�ޑO�ɁA�����t�@�C���łł��邾���t�H���g�̐ݒ���s���Ă����܂��B���O�Ɍ����t�@�C���Őݒ���s���Ă����A�t�H���g �}�b�s���O��ݒ肵�Ȃ��Ă��v���r���[���Ƀt�H���g���ϊ����ꂽ���\�������̂ŁA�|���̌����ڂ��m�F���₷���Ȃ�܂��B
�܂��ATrados �̃t�H���g �}�b�s���O�@�\�����ۂɂǂ̂悤�Ƀt�H���g��ύX���Ă���̂��͂킩��܂��A���̋@�\�� Word �� PowerPoint �̖t�@�C���ɓK�ȓ��{��p�t�H���g��ݒ肷��킯�ł͂���܂���B�����ڏ�͕ϊ����ꂽ�t�H���g���\������Ă��Ă��A�t�H���g�ݒ莩�̂͌����̂܂܂������肷�邱�Ƃ�����܂��B
�Ƃ����킯�ŁA�����t�@�C���Ńt�H���g�̐ݒ���s���̂����z�ł͂���̂ł����A���͂��ꂪ�Ȃ��Ȃ���ςł��BWord �� PowerPoint �̖{�i�I�ȕ����ł́u�X�^�C���v��u�}�X�^�[�v�Ȃǂ��g���Ă��Ȃ蕡�G�Ȑݒ肪�{����Ă��邱�Ƃ�����܂��B���̂悤�ȏꍇ�A�t�H���g�����Ƃ͂����Ă������œK�Ȑݒ������͓̂���A����� Trados �̖����̓�����������Ȃ邱�Ƃ�����܂��B
���́A�P���ȃt�@�C���������猴���t�@�C���Őݒ���s���܂����A���ꂪ����ꍇ�� Trados �̃t�H���g �}�b�s���O�@�\���g���Ă��܂��܂��B�����āA����ł����܂������Ȃ��ꍇ�́A�ŏI��i�Ƃ��āA������Ɏ蓮�Ńt�H���g��ύX���܂��B
���āA�����܂ł͉p���|��Ŗ����{��̏ꍇ�̐����ł������A���p�|��̏ꍇ�͖��p��ɂȂ�܂��B��ɋ������t�H���g �}�b�s���O�̐}�ŋC�t���Ă���������邩������܂��A����̃t�H���g �}�b�s���O�Ɂu�p��v�͑��݂��܂���B���̂��߁A���p��̏ꍇ�A�t�H���g�̕ϊ��͍s���܂���B�p��ɑ��ăt�H���g�̕ϊ����s�������ꍇ�́A��}�� [�t�H���g �}�b�s���O] �̉�ʂ��E�N���b�N���� [�V��������̒lj�] ��I�����A�u�p��v��lj�����K�v������܂��B
����͈ȏ�ł��B�t�H���g�̕ϊ��͐��m�ɍs�����Ƃ���ƂȂ��Ȃ���ςł��B�����t�@�C���̍������A�|��҂ɋ��߂����Ɣ͈͂��l�����āA�Ȃ�ƂȂ����������Ɏd�グ�邱�Ƃ�ڎw���܂��傤�B
Tweet
�p�b�P�[�W��n���ꂽ��A��������̂܂g��
����̋L���ł́A������ Trados �Ƀt�@�C������荞��ō�Ƃ���ꍇ�̕��@���Љ�܂��B�c�O�Ȃ���A�|���Ђ���p�b�P�[�W��n���ꂽ�ꍇ�͎����Ō����t�@�C������荞�ނ��Ƃ��ł��Ȃ��̂ŁA�p�b�P�[�W���̃t�@�C�������̂܂g�p���邵������܂���B�u�t�@�C���̎�ށv�ɂ���t�H���g �}�b�s���O�������ŕύX���邱�Ƃ͂ł��܂����A�u�t�@�C���̎�ށv�ɂ͖|���Ђ����炩�̐ݒ�����Ă��Ă���ꍇ������܂��B���̒��̐ݒ��ύX����ꍇ�́A���ꂮ����T�d�ɍs���Ă��������B
�G�f�B�^�[���̃t�H���g�w��́A�ʂ̐ݒ�ōs��
����̋L���́A�v���r���[������̏����ō����t�@�C���̃t�H���g�ɂ��Ă̐����ł��B�G�f�B�^�[�ɕ\������镶���̃t�H���g�ł͂���܂���B�G�f�B�^�[�̕\���Ŏg����t�H���g�ɂ��ẮA�ȑO�̋L���u�G�f�B�^��̃t�H���g��ς����v���Q�l�ɂ��Ă��������B
�ł́A�t�H���g��ݒ肷����@��������Ă����܂��傤�B�܂��́A�p���|��̏ꍇ�ł��B
�u�t�H���g �}�b�s���O�v�̐ݒ�Ńt�H���g��ς���
PowerPoint �t�@�C���̉p���|������Ă���Ƃ��ɁA�t�@�C���œ��{��̃t�H���g�������ɂȂ�v���[���e�[�V�����̌����ڂ������c�O�Ȋ����ɂȂ��Ă��܂������Ƃ͂���܂��B����́u�t�@�C���̎�ށv�̃t�H���g �}�b�s���O�ł��ׂẴt�H���g�ɁuMS Mincho�v���ݒ肳��Ă��邩��ł��B
�����炭����ŁA���}�̂悤�ɁA[�v���W�F�N�g�̐ݒ�] > [�t�@�C���̎��] > [PowerPoint 2007-2019] > [�t�H���g �}�b�s���O] �̓��{��ɑ��� <AllFonts> �� MS Mincho �ɕϊ�����ݒ肪����Ă��܂��B

���̃}�b�s���O���L���ɂȂ��Ă���ƁA�t�@�C���ł��ׂẴt�H���g�������ɕϊ�����܂��B
�� ���ׂẴt�H���g�������ɕϊ������

�����ł͂Ȃ��ʂ̃t�H���g�ɕϊ��������ꍇ�́A��}�̉�ʂ� [MS Mincho] ���E�N���b�N���� [�I�������A�C�e���̍폜] ��I�����A�t�H���g�̐ݒ����������폜���܂��B���̌�� [���{��] ���E�N���b�N���� [�V�K�t�H���g�̒lj�] ��I�����A�t�H���g��lj����܂��B���}�̂悤�ȉ�ʂ��\�������̂ŁA[�����̃t�H���g] �ł͉����� [�����̃t�H���g�����ׂă}�b�v] ��I�����A[�̃t�H���g] �Ŏg�p�������t�H���g��I�����܂� (���̗�ł́AMeiryo UI ��I�����Ă��܂�)�B

����ŁA[OK] ���N���b�N����ƁA���}�̂悤�� <AllFonts> �� Meiryo UI �ɕϊ�����ݒ�ɂȂ�܂��B

���̐ݒ�Ŗ���������ƁA���x�͂��ׂẴt�H���g�� Meiryo UI �ɕϊ�����܂��B
�� ���ׂẴt�H���g�� Meiryo UI �ɕϊ������

��}�� [�t�H���g �}�b�s���O�̑I��] ��ʂł́A�������u���ׂẴt�H���g�v�ł͂Ȃ��A�ʂ̃t�H���g��ݒ肷�邱�Ƃ��ł��܂��B�t�H���g���Ƃɕϊ����[�������܂��Ă���ꍇ�͌X�ɐݒ���s���܂��B
���Ȃ݂ɁA��L�Ŏg�p���� Meiryo UI �ɂ͎Α̂����݂��܂���BTrados �̃G�f�B�^�[��Ń^�O���g�p���ĎΑ̂�ݒ肵�Ă��Ă��A�t�@�C���� Meiryo UI �ɕύX���Ă��܂��Ɛ��̂ŕ\������܂� (���́ATrados �̃o�O�Ȃ�Ȃ����Ǝv���Ă����̂ł����A�����ł͂���܂���ł���)�B���{�ꕶ���ŎΑ̂��Ӑ}�I�Ɏg�����Ƃ͏��Ȃ��Ǝv���܂����A�����Α̂��g�������ꍇ�͑��̃t�H���g���g�p����K�v������܂��B
�u�t�H���g �}�b�s���O�v�̐ݒ�Ńt�H���g�ϊ����ɂ���
�t�H���g �}�b�s���O�̐ݒ�ł́ATrados �ł̃t�H���g�ϊ�����ؖ����ɂ��邱�Ƃ��ł��܂��B�t�H���g�ϊ����ɂ������ꍇ�́A��}�̉�ʂ� [���{��] ���E�N���b�N���� [�I�������A�C�e���̍폜] ��I�����A���{��̐ݒ肻�̂��̂��폜���܂��B����ŁA�t�H���g�̕ϊ��͍s��ꂸ�A������ PowerPoint �t�@�C���Őݒ肳��Ă�����{��p�t�H���g���g�p�����悤�ɂȂ�܂��B
�� �t�H���g�ϊ����ɂ���ƁA�����t�@�C���Őݒ肳��Ă���t�H���g���g�p�����

�����t�@�C���ɓ��{��p�t�H���g��������Ɛݒ肳��Ă���ꍇ�́ATrados �ł̕ϊ��͖����ɂ���̂������߂ł��B�����A�p��̌����t�@�C���œ��{��p�̃t�H���g���ݒ肳��Ă��邱�Ƃ͂܂�ł��B�����Ă��́A�ݒ肪����Ă��Ȃ����߂ɁA���炩�̊���l���g�p����Ă��܂����ƂɂȂ�܂��B���̂��߁ATrados �ł̃t�H���g�ϊ����ɂ���ꍇ�́A�����t�@�C���ɑ��Ď����Ńt�H���g�̐ݒ���s���Ă����K�v������܂��B
Trados �Ɏ�荞�ޑO�ɁA�����t�@�C���Ńt�H���g��ݒ肷��
�t�H���g �}�b�s���O�ɂ��ϊ����s��Ȃ��ꍇ�́ATrados �Ƀt�@�C������荞�ޑO�ɁA�����t�@�C���łł��邾���t�H���g�̐ݒ���s���Ă����܂��B���O�Ɍ����t�@�C���Őݒ���s���Ă����A�t�H���g �}�b�s���O��ݒ肵�Ȃ��Ă��v���r���[���Ƀt�H���g���ϊ����ꂽ���\�������̂ŁA�|���̌����ڂ��m�F���₷���Ȃ�܂��B
�܂��ATrados �̃t�H���g �}�b�s���O�@�\�����ۂɂǂ̂悤�Ƀt�H���g��ύX���Ă���̂��͂킩��܂��A���̋@�\�� Word �� PowerPoint �̖t�@�C���ɓK�ȓ��{��p�t�H���g��ݒ肷��킯�ł͂���܂���B�����ڏ�͕ϊ����ꂽ�t�H���g���\������Ă��Ă��A�t�H���g�ݒ莩�̂͌����̂܂܂������肷�邱�Ƃ�����܂��B
�Ƃ����킯�ŁA�����t�@�C���Ńt�H���g�̐ݒ���s���̂����z�ł͂���̂ł����A���͂��ꂪ�Ȃ��Ȃ���ςł��BWord �� PowerPoint �̖{�i�I�ȕ����ł́u�X�^�C���v��u�}�X�^�[�v�Ȃǂ��g���Ă��Ȃ蕡�G�Ȑݒ肪�{����Ă��邱�Ƃ�����܂��B���̂悤�ȏꍇ�A�t�H���g�����Ƃ͂����Ă������œK�Ȑݒ������͓̂���A����� Trados �̖����̓�����������Ȃ邱�Ƃ�����܂��B
���́A�P���ȃt�@�C���������猴���t�@�C���Őݒ���s���܂����A���ꂪ����ꍇ�� Trados �̃t�H���g �}�b�s���O�@�\���g���Ă��܂��܂��B�����āA����ł����܂������Ȃ��ꍇ�́A�ŏI��i�Ƃ��āA������Ɏ蓮�Ńt�H���g��ύX���܂��B
�p��̃t�H���g �}�b�s���O�͊���Ŗ���
���āA�����܂ł͉p���|��Ŗ����{��̏ꍇ�̐����ł������A���p�|��̏ꍇ�͖��p��ɂȂ�܂��B��ɋ������t�H���g �}�b�s���O�̐}�ŋC�t���Ă���������邩������܂��A����̃t�H���g �}�b�s���O�Ɂu�p��v�͑��݂��܂���B���̂��߁A���p��̏ꍇ�A�t�H���g�̕ϊ��͍s���܂���B�p��ɑ��ăt�H���g�̕ϊ����s�������ꍇ�́A��}�� [�t�H���g �}�b�s���O] �̉�ʂ��E�N���b�N���� [�V��������̒lj�] ��I�����A�u�p��v��lj�����K�v������܂��B
����͈ȏ�ł��B�t�H���g�̕ϊ��͐��m�ɍs�����Ƃ���ƂȂ��Ȃ���ςł��B�����t�@�C���̍������A�|��҂ɋ��߂����Ɣ͈͂��l�����āA�Ȃ�ƂȂ����������Ɏd�グ�邱�Ƃ�ڎw���܂��傤�B
 | �@�@ |  |
Tweet
2023�N01��30��
�{���Ɍ�������R�s�[�����܂܂��H
�N���̃A�h�x���g �J�����_�[�ł�������L�����������̂ł�����Ƃ��x�݂����炠���Ƃ����Ԃ� 1 �����ȏオ�����Ă��܂��܂����B�l�^���s�����킯�ł͂Ȃ��ł����A����͂�����ƊȒP�ȋL���ɂ��܂��B
IT �n�̖|������Ă���ƁA�v���O�����̃\�[�X�R�[�h�Ȃnj����̂܂c���Ȃ���Ȃ�Ȃ����߂����܂ɂ���܂��B�������R�s�[ (Ctrl+Ins) �����邾���Ȃ̂Ŗ|��҂Ƃ��Ă͂����ł����A��Ō����������Ă���Ƃ��ɁA�{���ɃR�s�[�������A�R�s�[������ɂ�������G���Ă��Ȃ����ƕs���ɂȂ�A���ǂ�����x Ctrl+Ins �������Ă��܂����Ƃ��悭����܂��B
����ȕs�����������Ă����@�\�Ƃ��āATrados �ł͌������R�s�[�������߂̐F��ς��邱�Ƃ��ł��܂��B���͂��̋@�\�ɂ܂������C�t���Ă��Ȃ������̂ł����A�����O�� Twitter ���|�����̕����Ԃ₢�Ă����̂ŁA������q���g�ɑ��������Ă݂܂����B
�ݒ�̏ꏊ�� [�t�@�C��] > [�I�v�V����] > [�F] �ł��B�����ŁA���܂��܂ȐF��ݒ�ł��܂��B[�|��X�e�[�^�X] �� [�w�i�F] �� [��������R�s�[] �Ƃ����I�v�V����������̂ŁA���������̔�����ʂ̐F�ɕύX���܂��B���͉��}�̂悤�ɔ����F���ۂ����Ă��܂��B
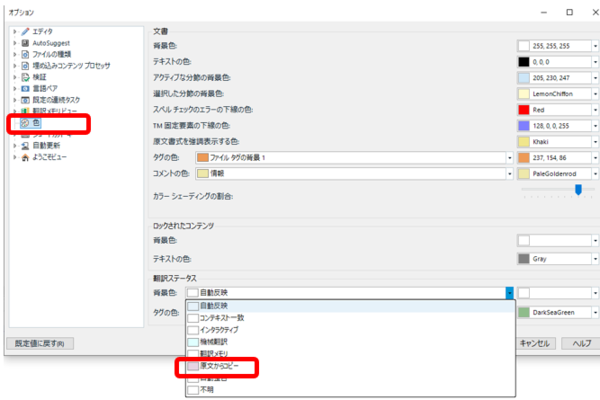
���̐ݒ�����Ă����ƁA�ȉ��̂悤�Ɍ�������R�s�[�����܂܂̕��߂ɐF���t���悤�ɂȂ�܂��B
�����F�ɂȂ��Ă��镪�߂͌�������R�s�[�����܂܈�ؐG���Ă��Ȃ����߂ł��B����������́uWe have several �c�v�̕��߂͌����Ɩ������悤�Ɍ����܂����A���͌�������R�s�[��������ɃX�y�[�X�����č폜����Ƃ����ҏW���������̂Ŕ����F�ɂȂ��Ă��܂���B
���̋@�\�́A�����Ɩ����������`�F�b�N���Ă���̂ł͂Ȃ��A�u��������R�s�[�v�Ƃ���������������ǂ����ŐF��t���Ă��܂��B�u��������R�s�[�v�̑�����������_�ŐF���t���A���̑�����s���Ƃ��̎��_�ŐF�͏����܂��B
�n���ȋ@�\�ł����ƂĂ��֗��ŁA���͂��Ȃ菕�����Ă��܂��B���ɂ����낢��Ȑݒ�ŐF���ς�����悤�Ȃ̂ŁA�ǂ������������������B
Tweet
IT �n�̖|������Ă���ƁA�v���O�����̃\�[�X�R�[�h�Ȃnj����̂܂c���Ȃ���Ȃ�Ȃ����߂����܂ɂ���܂��B�������R�s�[ (Ctrl+Ins) �����邾���Ȃ̂Ŗ|��҂Ƃ��Ă͂����ł����A��Ō����������Ă���Ƃ��ɁA�{���ɃR�s�[�������A�R�s�[������ɂ�������G���Ă��Ȃ����ƕs���ɂȂ�A���ǂ�����x Ctrl+Ins �������Ă��܂����Ƃ��悭����܂��B
����ȕs�����������Ă����@�\�Ƃ��āATrados �ł͌������R�s�[�������߂̐F��ς��邱�Ƃ��ł��܂��B���͂��̋@�\�ɂ܂������C�t���Ă��Ȃ������̂ł����A�����O�� Twitter ���|�����̕����Ԃ₢�Ă����̂ŁA������q���g�ɑ��������Ă݂܂����B
�ݒ�̏ꏊ�� [�t�@�C��] > [�I�v�V����] > [�F] �ł��B�����ŁA���܂��܂ȐF��ݒ�ł��܂��B[�|��X�e�[�^�X] �� [�w�i�F] �� [��������R�s�[] �Ƃ����I�v�V����������̂ŁA���������̔�����ʂ̐F�ɕύX���܂��B���͉��}�̂悤�ɔ����F���ۂ����Ă��܂��B

���̐ݒ�����Ă����ƁA�ȉ��̂悤�Ɍ�������R�s�[�����܂܂̕��߂ɐF���t���悤�ɂȂ�܂��B
�����F�ɂȂ��Ă��镪�߂͌�������R�s�[�����܂܈�ؐG���Ă��Ȃ����߂ł��B����������́uWe have several �c�v�̕��߂͌����Ɩ������悤�Ɍ����܂����A���͌�������R�s�[��������ɃX�y�[�X�����č폜����Ƃ����ҏW���������̂Ŕ����F�ɂȂ��Ă��܂���B
���̋@�\�́A�����Ɩ����������`�F�b�N���Ă���̂ł͂Ȃ��A�u��������R�s�[�v�Ƃ���������������ǂ����ŐF��t���Ă��܂��B�u��������R�s�[�v�̑�����������_�ŐF���t���A���̑�����s���Ƃ��̎��_�ŐF�͏����܂��B
�n���ȋ@�\�ł����ƂĂ��֗��ŁA���͂��Ȃ菕�����Ă��܂��B���ɂ����낢��Ȑݒ�ŐF���ς�����悤�Ȃ̂ŁA�ǂ������������������B
 | �@�@ |  |
Tweet
2022�N12��25��
�y��ҁz�^�C�s���O�����炻��
Advent Calendar �u�|��ɖ𗧂��Ă��ꂻ���ȃc�[���v�̋L���ł��B�L���̌��J���x���Ȃ��Ă��܂��܂����B������A������ Trados �ł��B
�O���Ɉ��������ATrados ���Ń^�C�s���O�����炷���@���l���Ă݂܂��B����́A�v���W�F�N�g�̐ݒ�ł͂Ȃ��A[�t�@�C��] > [�I�v�V����] ����s�� Trados ���S�̂̐ݒ�ł��B�����̐ݒ�̏ڍׂɂ��ẮA�ȑO�̋L���uTrados �̐ݒ��ς���ɂ� �| [�t�@�C��] �� [�v���W�F�N�g�̐ݒ�]�v���Q�Ƃ��Ă��������B
[�t�@�C��] > [�I�v�V����] �̐ݒ�́A�v���W�F�N�g�̐ݒ�ƈقȂ�A��x�ݒ肷��ǂ̃v���W�F�N�g�ō�Ƃ����Ă��L���ł��B����͕֗��ł��锽�ʁA�v���W�F�N�g���Ƃɐݒ��ς��邱�Ƃ͂ł��Ȃ��Ƃ������Ƃł�����܂��B����̕��� (���p���A�p����) �ɂ���Đݒ��ς������Ȃ邱�Ƃ͂���܂����A�v���W�F�N�g��ς��Ă��ݒ�͕ς��Ȃ��̂ŁA���������ꍇ�͎蓮�Őݒ��ς��邵������܂���B(���ǁA�v���W�F�N�g���Ƃɐݒ��ς�����I �Ƃ������Ƃł��B)
����Љ��@�\�́A��� AutoSuggest �ł��BAutoSuggest �́A�p������� (�p�����͂���) �Ƃ��͂��܂��@�\���܂����A�a������� (���{�����͂���) �Ƃ��́AIME �Ƃ̊W��A���܂���҂ǂ���̓���ɂȂ�܂���B�a��̏ꍇ�́AAutoSuggest �͖����ɂ��� IME �̋@�\�����p����̂���̑I�����ł��B���̋L���̈ȉ��̐����́A�p������� (�p�����͂���) �ꍇ��O��Ƃ��Ă��܂��B�ł́A�n�߂Ă����܂��傤�B
AutoSuggest �̗L�������̐�ւ���ڍׂ̐ݒ�́A[�t�@�C��] > [�I�v�V����] > [AutoSuggest] ����s���܂��B
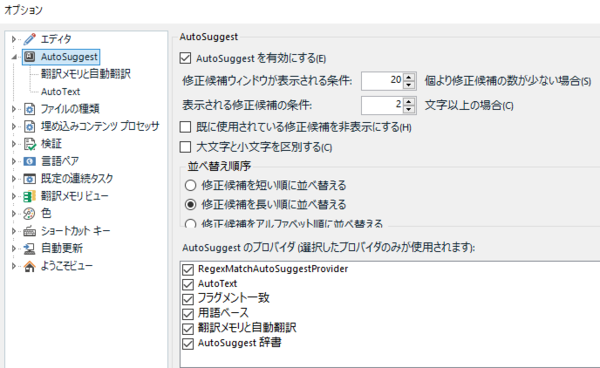
��ʉ����� [AutoSuggest �̃v���o�C�_] ���X�g�ŁAAutoSuggest �̌����ǂ����玝���Ă���̂����w��ł��܂��B���Ԃ��ύX�ł��܂��B���͂��ׂẴ`�F�b�N�{�b�N�X���I���ɂ��Ă��邱�Ƃ������ł����A�s�v�Ȃ��̂̓I�t�ɂł��܂��B
���̃��X�g�̈�ԏ�ɕ\������Ă��� [RegexMatchAutoSuggestProvider] �́AAutoSuggest �����������v���O�C���ł��B����ɂ��Ă͌�Ő������܂��B[AutoText] �� [�|�����Ǝ����|��] �ɂ��ẮA�ʂ̉�ʂŏڍׂ�ݒ�ł��܂��B�������q���܂��B
[AutoSuggest ����] �́A����̃���������p��𒊏o�����Ζ�W (.bpm �t�@�C��) �̂悤�Ȃ��̂ł��B���炭�A�t���[�����X�łł͂��̎��������邱�Ƃ��ł��Ȃ������̂ł����A�Ȃ�� Trados Studio 2021 ����͐����ł����悤�ɂȂ��Ă��܂��B(���́A���̋L���������Ă��āA���������@�\���t���[�����X�łɒlj�����Ă��邱�Ƃ����߂Ēm��܂����B�т����肵�܂����B) �������ŊȒP�ɐ������܂��B
���̉�ʂׂ̍����ݒ�́A�����Ɍ����āA�l�̍D�݂ł��B��������p��W�̏[���x�ɂ����܂����A����̖�������܂��B��₪���܂�ɑ����\�������悤�Ȃ� [�|�����Ǝ����|��] ���I�t�ɂ���Ƃ��A��Ƃ��Ă���v���W�F�N�g�ɍ��킹�Ėʓ|���炸�ɐݒ��ς��Ă��������B(�܂��A���ǁA�v���W�F�N�g���Ƃɐݒ��ς��邱�ƂɂȂ�̂Ŗʓ|�ł��B)
�ł́A�������̋@�\���ڂ������Ă����܂��B
���̋@�\��L���ɂ���ƁA�\��������₪���Ȃ葽���Ȃ�܂��B���́A�������炷���߁A�����Ă��u�����܂���v�v�̃`�F�b�N�{�b�N�X�̓I�t�ɂ��Ă��܂��B
�ł悭�g�����������œo�^���Ă������Ƃ��ł��܂��BAutoText �́A�����ɊW�Ȃ��\�������̂������ł��B��������p��W�͌����ɊY�������傪�Ȃ���@�\���܂��AAutoText �͖̌���o�^���Ă���̂ŁA�ŏ��̐���������͂���Ό����ɊW�Ȃ���₪�\������Ă��܂��B�uperson in charge�v��ucompany/organization�v�ȂǁA��X���b�V�����܂ތ����o�^�ł��܂��B
AutoText �̃��X�g�̓t�@�C���Ƃ��ĕۑ��ł��܂��B�E���ɂ��� [�C���|�[�g]��[�G�N�X�|�[�g] �̃{�^�����g���܂��B���̃��X�g�́ATrados ���������肷��ƁA�V�����lj�������傪�����Ă��܂����Ƃ�����̂ŁA���܂߂ɃG�N�X�|�[�g���Ă������Ƃ������߂��܂��B
Regex Match AutoSuggest Provider �́AAutoSuggest ���������Ă����v���O�C���ł��B�����Ŏg�p�ł��܂��B�ڍׂɂ��ẮA�ȑO�̋L���u���v���O�C���� �����ɂ���p������ɃR�s�[���� (���ˉp�̏ꍇ)�v���Q�Ƃ��Ă��������B
�ȑO�̋L���ł͉p�������R�s�[������@�����������Ă��܂��A�������A���낢��Ȏg�������ł��܂��B��{�I�ɂ͐��K�\���ł����A���ʂ̌���o�^���邾���Ȃ琳�K�\������Ɉӎ�����K�v�͂���܂���B
���Ƃ��A���{��ł悭�g����ۈ͂ݐ������ȉ��̂悤�ɕϊ��ł��܂� (�@ �� (1) �ɕϊ�����)�B
�ȉ��́A�����������ɕϊ����Ă��܂��B�S�p�ɑΉ����邽�ߏ����������K�\�����g���Ă��܂� (���݂܂���A���Ԃ����Ȃ��Ƃɓ��ɈӖ��͂���܂���)�B
��}�̂悤�ɐݒ肵���ꍇ�A11 �ɑ��Ă� November �� January �̗��������Ƃ��ĕ\������܂��B�܂��A�P�ɐ������w�肵�Ă��邾���Ȃ̂ŁA�����Ƃ͊W�̂Ȃ������̏ꍇ�����������Ƃ��ĕ\������܂��B���̕ӂ�́A���Ƃ��Ă͋��e�͈͓��ł��B
�Ō�� AutoSuggest �����ł��B�O�q�̂Ƃ���A���̎����͂���܂Ńt���[�����X�łł͍쐬�ł��Ȃ������̂ŁA���͎g�������Ƃ�����܂���B�ǂ̒��x�𗧂̂��͖��m���ł����A�傫�ȃ�����������Ă���ꍇ�͕֗��ɋ@�\����̂ł͂Ȃ����Ǝv���܂��B
AutoSuggest �����̌X�̐ݒ�́A[�t�@�C��] > [�I�v�V����] �ł͂Ȃ��A�v���W�F�N�g�̐ݒ肩��s���܂��B�v���W�F�N�g�̐ݒ�� [����y�A] > [����̌���y�A] > [AutoSuggest ����] ���N���b�N����ƈȉ��̉�ʂ��\������܂� (����Ɉˑ�������̂Ȃ̂ŁA[���ׂĂ̌���y�A] �ł͂Ȃ��AJapanese �ȂǓ���̌���y�A����ݒ肵�܂�)�B
�܂��A�������쐬���܂��B���̉�ʂ� [����] �{�^�����N���b�N����ƃE�B�U�[�h���J�n����܂��B�E�B�U�[�h��i�߂Ă����A�����t�@�C�� (.bpm) ���ł�������܂��B���������傫���Ƃ��Ȃ莞�Ԃ�������Ǝv����̂ŁA�ݒ��K�X�������Ă݂Ă��������B�܂��A�����̍쐬�́A���̉�ʂł͂Ȃ��A[�|����] �r���[����s�����Ƃ��ł��܂��B
�����t�@�C�����쐬���ꂽ��A[�lj�] �{�^�����N���b�N���Ă��̃t�@�C����o�^���܂��B����ŁA�����͊����ł��B�����̓��e�����ɕ\������Ă���͂��ł��B
����͈ȏ�ł��BAutoSuggest �́A�ݒ�ɂ���ẮA���҂ǂ���̌�₪�\������Ȃ�������A�\��������₪���������肷�邱�Ƃ�����܂��B�x�X�g�Ȑݒ��������̂͂Ȃ��Ȃ�����ł����A���낢��Ƃ��������������B��Ƃ��Ă���v���W�F�N�g�ɉ����āA���܂߂ɐݒ��ς��邱�Ƃ�����Ǝv���܂� (�����v���Ă͂��܂����A���ۂ̂Ƃ���͖ʓ|�ł�)�B
�O���Ɉ��������ATrados ���Ń^�C�s���O�����炷���@���l���Ă݂܂��B����́A�v���W�F�N�g�̐ݒ�ł͂Ȃ��A[�t�@�C��] > [�I�v�V����] ����s�� Trados ���S�̂̐ݒ�ł��B�����̐ݒ�̏ڍׂɂ��ẮA�ȑO�̋L���uTrados �̐ݒ��ς���ɂ� �| [�t�@�C��] �� [�v���W�F�N�g�̐ݒ�]�v���Q�Ƃ��Ă��������B
[�t�@�C��] > [�I�v�V����] �̐ݒ�́A�v���W�F�N�g�̐ݒ�ƈقȂ�A��x�ݒ肷��ǂ̃v���W�F�N�g�ō�Ƃ����Ă��L���ł��B����͕֗��ł��锽�ʁA�v���W�F�N�g���Ƃɐݒ��ς��邱�Ƃ͂ł��Ȃ��Ƃ������Ƃł�����܂��B����̕��� (���p���A�p����) �ɂ���Đݒ��ς������Ȃ邱�Ƃ͂���܂����A�v���W�F�N�g��ς��Ă��ݒ�͕ς��Ȃ��̂ŁA���������ꍇ�͎蓮�Őݒ��ς��邵������܂���B(���ǁA�v���W�F�N�g���Ƃɐݒ��ς�����I �Ƃ������Ƃł��B)
����Љ��@�\�́A��� AutoSuggest �ł��BAutoSuggest �́A�p������� (�p�����͂���) �Ƃ��͂��܂��@�\���܂����A�a������� (���{�����͂���) �Ƃ��́AIME �Ƃ̊W��A���܂���҂ǂ���̓���ɂȂ�܂���B�a��̏ꍇ�́AAutoSuggest �͖����ɂ��� IME �̋@�\�����p����̂���̑I�����ł��B���̋L���̈ȉ��̐����́A�p������� (�p�����͂���) �ꍇ��O��Ƃ��Ă��܂��B�ł́A�n�߂Ă����܂��傤�B
AutoSuggest
AutoSuggest �̗L�������̐�ւ���ڍׂ̐ݒ�́A[�t�@�C��] > [�I�v�V����] > [AutoSuggest] ����s���܂��B
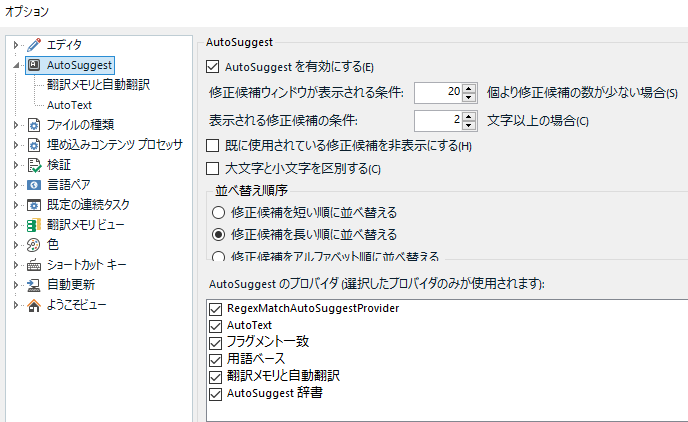
��ʉ����� [AutoSuggest �̃v���o�C�_] ���X�g�ŁAAutoSuggest �̌����ǂ����玝���Ă���̂����w��ł��܂��B���Ԃ��ύX�ł��܂��B���͂��ׂẴ`�F�b�N�{�b�N�X���I���ɂ��Ă��邱�Ƃ������ł����A�s�v�Ȃ��̂̓I�t�ɂł��܂��B
���̃��X�g�̈�ԏ�ɕ\������Ă��� [RegexMatchAutoSuggestProvider] �́AAutoSuggest �����������v���O�C���ł��B����ɂ��Ă͌�Ő������܂��B[AutoText] �� [�|�����Ǝ����|��] �ɂ��ẮA�ʂ̉�ʂŏڍׂ�ݒ�ł��܂��B�������q���܂��B
[AutoSuggest ����] �́A����̃���������p��𒊏o�����Ζ�W (.bpm �t�@�C��) �̂悤�Ȃ��̂ł��B���炭�A�t���[�����X�łł͂��̎��������邱�Ƃ��ł��Ȃ������̂ł����A�Ȃ�� Trados Studio 2021 ����͐����ł����悤�ɂȂ��Ă��܂��B(���́A���̋L���������Ă��āA���������@�\���t���[�����X�łɒlj�����Ă��邱�Ƃ����߂Ēm��܂����B�т����肵�܂����B) �������ŊȒP�ɐ������܂��B
���̉�ʂׂ̍����ݒ�́A�����Ɍ����āA�l�̍D�݂ł��B��������p��W�̏[���x�ɂ����܂����A����̖�������܂��B��₪���܂�ɑ����\�������悤�Ȃ� [�|�����Ǝ����|��] ���I�t�ɂ���Ƃ��A��Ƃ��Ă���v���W�F�N�g�ɍ��킹�Ėʓ|���炸�ɐݒ��ς��Ă��������B(�܂��A���ǁA�v���W�F�N�g���Ƃɐݒ��ς��邱�ƂɂȂ�̂Ŗʓ|�ł��B)
�ł́A�������̋@�\���ڂ������Ă����܂��B
�|�����Ǝ����|��
���̋@�\��L���ɂ���ƁA�\��������₪���Ȃ葽���Ȃ�܂��B���́A�������炷���߁A�����Ă��u�����܂���v�v�̃`�F�b�N�{�b�N�X�̓I�t�ɂ��Ă��܂��B
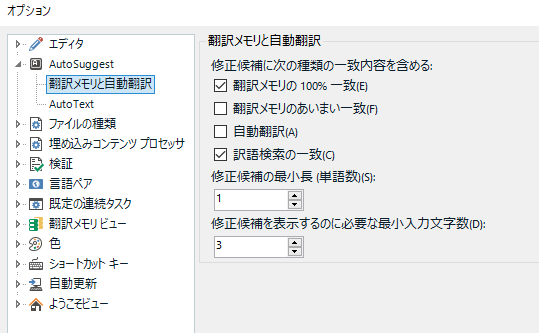
AutoText
�ł悭�g�����������œo�^���Ă������Ƃ��ł��܂��BAutoText �́A�����ɊW�Ȃ��\�������̂������ł��B��������p��W�͌����ɊY�������傪�Ȃ���@�\���܂��AAutoText �͖̌���o�^���Ă���̂ŁA�ŏ��̐���������͂���Ό����ɊW�Ȃ���₪�\������Ă��܂��B�uperson in charge�v��ucompany/organization�v�ȂǁA��X���b�V�����܂ތ����o�^�ł��܂��B

AutoText �̃��X�g�̓t�@�C���Ƃ��ĕۑ��ł��܂��B�E���ɂ��� [�C���|�[�g]��[�G�N�X�|�[�g] �̃{�^�����g���܂��B���̃��X�g�́ATrados ���������肷��ƁA�V�����lj�������傪�����Ă��܂����Ƃ�����̂ŁA���܂߂ɃG�N�X�|�[�g���Ă������Ƃ������߂��܂��B
Regex Match AutoSuggest Provider
Regex Match AutoSuggest Provider �́AAutoSuggest ���������Ă����v���O�C���ł��B�����Ŏg�p�ł��܂��B�ڍׂɂ��ẮA�ȑO�̋L���u���v���O�C���� �����ɂ���p������ɃR�s�[���� (���ˉp�̏ꍇ)�v���Q�Ƃ��Ă��������B
�ȑO�̋L���ł͉p�������R�s�[������@�����������Ă��܂��A�������A���낢��Ȏg�������ł��܂��B��{�I�ɂ͐��K�\���ł����A���ʂ̌���o�^���邾���Ȃ琳�K�\������Ɉӎ�����K�v�͂���܂���B
���Ƃ��A���{��ł悭�g����ۈ͂ݐ������ȉ��̂悤�ɕϊ��ł��܂� (�@ �� (1) �ɕϊ�����)�B
�ȉ��́A�����������ɕϊ����Ă��܂��B�S�p�ɑΉ����邽�ߏ����������K�\�����g���Ă��܂� (���݂܂���A���Ԃ����Ȃ��Ƃɓ��ɈӖ��͂���܂���)�B

��}�̂悤�ɐݒ肵���ꍇ�A11 �ɑ��Ă� November �� January �̗��������Ƃ��ĕ\������܂��B�܂��A�P�ɐ������w�肵�Ă��邾���Ȃ̂ŁA�����Ƃ͊W�̂Ȃ������̏ꍇ�����������Ƃ��ĕ\������܂��B���̕ӂ�́A���Ƃ��Ă͋��e�͈͓��ł��B
AutoSuggest ����
�Ō�� AutoSuggest �����ł��B�O�q�̂Ƃ���A���̎����͂���܂Ńt���[�����X�łł͍쐬�ł��Ȃ������̂ŁA���͎g�������Ƃ�����܂���B�ǂ̒��x�𗧂̂��͖��m���ł����A�傫�ȃ�����������Ă���ꍇ�͕֗��ɋ@�\����̂ł͂Ȃ����Ǝv���܂��B
AutoSuggest �����̌X�̐ݒ�́A[�t�@�C��] > [�I�v�V����] �ł͂Ȃ��A�v���W�F�N�g�̐ݒ肩��s���܂��B�v���W�F�N�g�̐ݒ�� [����y�A] > [����̌���y�A] > [AutoSuggest ����] ���N���b�N����ƈȉ��̉�ʂ��\������܂� (����Ɉˑ�������̂Ȃ̂ŁA[���ׂĂ̌���y�A] �ł͂Ȃ��AJapanese �ȂǓ���̌���y�A����ݒ肵�܂�)�B

�܂��A�������쐬���܂��B���̉�ʂ� [����] �{�^�����N���b�N����ƃE�B�U�[�h���J�n����܂��B�E�B�U�[�h��i�߂Ă����A�����t�@�C�� (.bpm) ���ł�������܂��B���������傫���Ƃ��Ȃ莞�Ԃ�������Ǝv����̂ŁA�ݒ��K�X�������Ă݂Ă��������B�܂��A�����̍쐬�́A���̉�ʂł͂Ȃ��A[�|����] �r���[����s�����Ƃ��ł��܂��B
�����t�@�C�����쐬���ꂽ��A[�lj�] �{�^�����N���b�N���Ă��̃t�@�C����o�^���܂��B����ŁA�����͊����ł��B�����̓��e�����ɕ\������Ă���͂��ł��B
����͈ȏ�ł��BAutoSuggest �́A�ݒ�ɂ���ẮA���҂ǂ���̌�₪�\������Ȃ�������A�\��������₪���������肷�邱�Ƃ�����܂��B�x�X�g�Ȑݒ��������̂͂Ȃ��Ȃ�����ł����A���낢��Ƃ��������������B��Ƃ��Ă���v���W�F�N�g�ɉ����āA���܂߂ɐݒ��ς��邱�Ƃ�����Ǝv���܂� (�����v���Ă͂��܂����A���ۂ̂Ƃ���͖ʓ|�ł�)�B
| �@�@ |
�^�O�FAutoText Regex Match AutoSuggest Provider AutoSuggest���� AutoSuggest [�t�@�C��] > [�I�v�V����]
Tweet