


Trados �̗p��x�[�X��p��F���̋@�\�͂ƂĂ��֗��ł����A�ݒ�⓮��𗝉����Ȃ��܂g���Ă���ƁA���������̏������܂����������p��̌����Ƃ��ȂǂɂȂ��邱�Ƃ�����܂��B���l�I�ɂ́A�p��F���@�\�͂����܂ŕ⏕�I�Ȃ��̂ƍl���A�ʓ|�ł������Ō�������̂����S���ȂƎv���Ă��܂��B
����́A�}�C�N���\�t�g�̗p��W���g���Ƃ��ɓ��ɒ��ӂ������ݒ���܂߁A�p��x�[�X�S�ʂ̐ݒ���������Љ�܂��B
�p��̏d����������
�܂��A[�v���W�F�N�g�̐ݒ�] > [����y�A] > [�p��x�[�X] > [�����ݒ�] �̐ݒ�ł��B�����ɂ��� [�p��̏d����������] ���I���ɂ��܂��B���̐ݒ�́A�ȑO�̋L���u�p�b�P�[�W���������A�R�R�̐ݒ��ς��܂��v�ł��Љ�܂������A���̓p�b�P�[�W���������K���ύX���Ă��܂��B
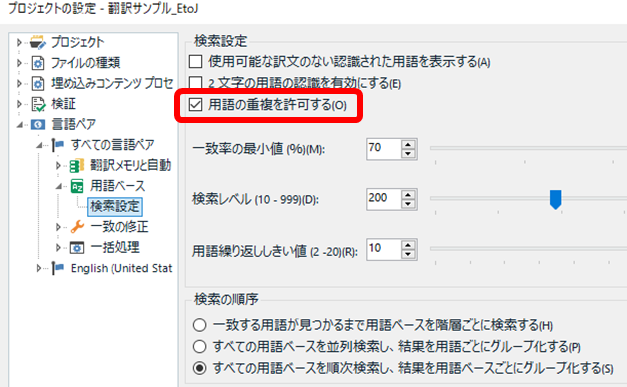
�����Ɂusystem administrator�v�Ƃ����p�ꂪ�������Ƃ��܂��B[�p��̏d����������] ���I�t�̏ꍇ�́A���}�̍����̂悤�Ɂusystem administrator�v�Ƃ��� 2 ��̈�v�����\������Ă��܂���B�p��W�Ɂusystem�v��uadministrator�v�Ƃ��� 1 �ꂾ���œo�^�������Ă��A����͗p��F���E�B���h�E�ɕ\������Ă��܂���B�܂�A�����p�ꂪ��v����Ƃ��̒����p�ꂾ�����\������A�Z���p��͕\������Ă��Ȃ��̂ł��B[�p��̏d����������] ���I���ɂ��Ă����ƁA�E���̂悤�ɁA�����p��ɉ����ĒZ���p����\������Ă��܂��B
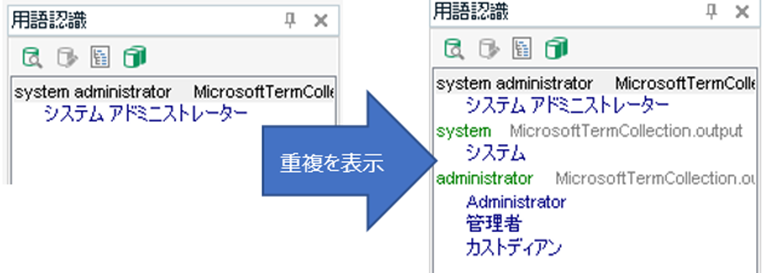
�����p�ꂾ���\�������Ώ\�����Ǝv�������ł����A�|���Ђ�����ꂽ�p��W�ƃ}�C�N���\�t�g�̗p��W�̗������g���ꍇ�͂��̃I�v�V�������������܂���B���Ƃ��A�ȉ��̂悤�� administrator �������̗p��W�ɓo�^����Ă���Ƃ��܂��B
�E�}�C�N���\�t�g�̗p��W: system administrator -> �V�X�e�� �A�h�~�j�X�g���[�^�[
�E�|���В̗p��W: administrator -> �Ǘ���
[�p��̏d����������] ���I�t�̏ꍇ�A�usystem administrator�v�Ƃ��������ɑ��ėp��F���E�B���h�E�ɕ\������Ă���̂́u�V�X�e�� �A�h�~�j�X�g���[�^�[�v�����ł��B���ꂽ�p��W�ɂ���u�Ǘ��ҁv�͕\������Ă��܂���B����͔��ɍ���܂��B���ꂽ�p��W�̗p��������Ƃ������ƂȂ��Ă��܂��܂��B
�p��x�[�X���ƂɃO���[�v������
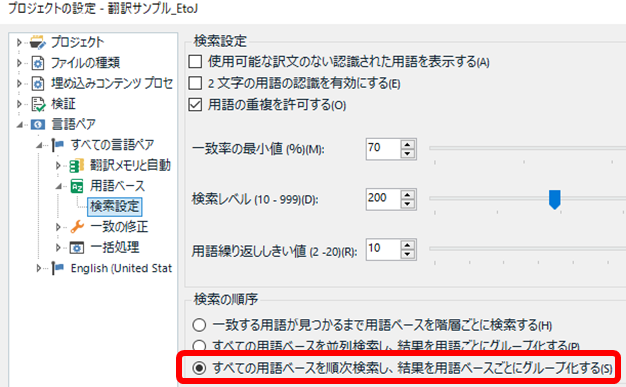
[�v���W�F�N�g�̐ݒ�] > [����y�A] > [�p��x�[�X] > [�����ݒ�] �̐ݒ������ 1 �Љ�܂��B
�}�C�N���\�t�g�̗p��W�͑�ʂȂ̂Ńq�b�g����p�ꂪ���Ȃ葽���Ȃ�܂��B�܂��A��L�� [�p��̏d����������] ���I���ɂ��邱�Ƃ��q�b�g�������Ȃ�v���ɂȂ�܂��B�ꗗ�ɗp�ꂪ��ʂɕ\������Ă���ƁA�p��������Ƃ��댯�������܂�̂Œ��ӂ��K�v�ł��B
�|���Ђ�����ꂽ�p��W�ƃ}�C�N���\�t�g�̗p��W�̗������g���ꍇ�́A�p��x�[�X���Ƃɕ\������ƈ��S�ł��B���̂��߂̐ݒ肪 [�p��x�[�X���ƂɃO���[�v������] �ł��B

�����p�ꂪ�㉺�ɕ��ԕ\���̕����킩��₷���Ƃ�������܂����A�}�C�N���\�t�g�̗p��W�͂��Ȃ��ʂɃq�b�g���Ă���̂ŁA�u�p�ꂲ�ƂɃO���[�v���v�ɂ��Ă���ƁA�}�C�N���\�t�g�̗p�ꂪ������ƕ��Ԓ��ɕʂ̗p�ꂪ�|�c�|�c�Ƌ��܂�Ƃ����\���ɂȂ肪���ł��B�����Ȃ�ƁA�ǂ����Ă������Ƃ��댯��������̂ŁA���́u�p��x�[�X���ƂɃO���[�v���v���g���Ă��܂��B
�������A���̐ݒ�ɂ� 1 ��肪����܂��B����́A���̐ݒ肪���͕⏕�p�̃��X�g ([�|��̕\��] �R�}���h�܂��� Ctrl+Shif+L �ŕ\�������) �ɂ͓K�p����Ȃ����Ƃł��B���͕⏕�p�̃��X�g�Ɨp��F���E�B���h�E�ŕ\���������Ⴄ���ƂɂȂ�̂ŁA�I�����ē��͂���Ƃ��ɒ��ӂ��K�v�ł��B�q�b�g����ʂɂ���ƃX�N���[���̗ʂ����Ȃ葝���A�Ԃ��Ď�ԂɂȂ邱�Ƃ�����܂��B
�t�B�[���h��\������
���́A�}�C�N���\�t�g�̗p��W�ł͂Ȃ��A��ɖ|���Ђ�������p��W�ɖ𗧂ݒ�ł��B�p��F���E�B���h�E�ɂ͗p��x�[�X�ɐݒ肳��Ă���u�t�B�[���h�v��\���ł��܂��B���}�́uUI�����v��u��ʗp��v�ƕ\������Ă��镔�����t�B�[���h�ł��B�e�p��ɂ��ẴR�����g�Ȃǂ��ݒ肳��Ă��邱�Ƃ������ł��B
�@�@�@�@�@�@�@
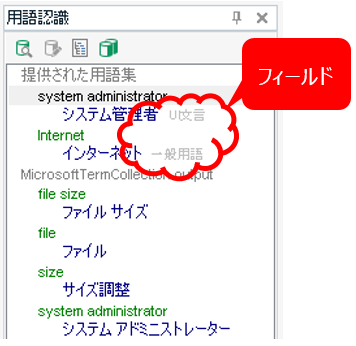
�Q�Ƃ���K�v�̂���t�B�[���h������ꍇ�́A�����Ă��A�|���Ђ��炻�̂悤�Ɏw������܂��B�����炭�A�p�b�P�[�W�Ŏ��O�ɐݒ肳��Ă��邱�Ƃ������Ǝv���܂����A�����Őݒ肷��ꍇ�́A�ȉ��̂悤�ɂ��܂��B
- �p��F���E�B���h�E�̏㕔�ɂ��� [�������ʂ̐ݒ�] �A�C�R�����N���b�N����B
- [�������ʂ̐ݒ�] �E�B���h�E���J���̂ŁA[�t�B�[���h] �{�^�����N���b�N����B
- [�t�B�[���h�̑I��] �E�B���h�E���\�����ꂽ��A�K�v�ȃt�B�[���h�̃`�F�b�N�{�b�N�X���I���ɂ���B

����ŁA�ݒ肳��Ă���t�B�[���h�̓��e���\�������悤�ɂȂ�܂��B�����A�p��F���E�B���h�E�͏������̂ŕ\���ł��Ă����܂�ǂ݂₷���Ƃ͌����܂���B�p��x�[�X�̌��f�[�^�� Excel �ȂǂŒ���Ă���Ȃ猳�f�[�^�ڎQ�Ƃ�������֗��ȏꍇ������܂��B
�p��F����M�p�������Ȃ�
���āA�p��F���E�B���h�E�̐ݒ�����낢��������Ă��܂������A��ԏd�v�ȃ|�C���g�́u�p��F����M�p�������Ȃ����Ɓv�ł��B���̋@�\�͕֗��ł����A���ׂĂ̗p�ꂪ�K���F������Ă���킯�ł͂���܂���B
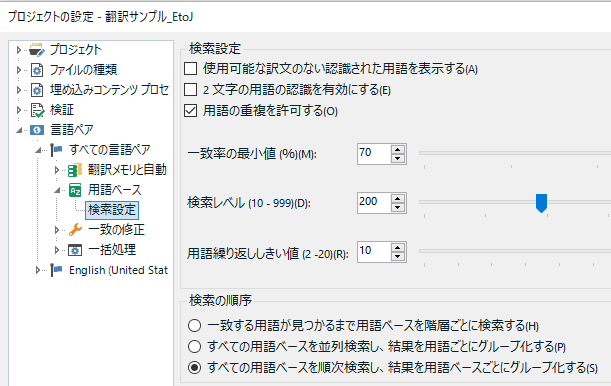
�p��x�[�X�� [�����ݒ�] ������Ƃ킩��܂����A���낢��ݒ肪����A���̐ݒ�ɂ���ėp��F���̓���͕ς��܂��B�p��F���͒P���ȃe�L�X�g�̈�v�ŗp��������Ă���킯�ł͂���܂���B
[2 �����̗p��̔F����L���ɂ���] �̓f�t�H���g�ŃI�t�ł��B���ꂪ�I�t�̏ꍇ�A�uin�v��umy�v�Ȃ� 2 �����̗p��͗p��W�ɓo�^����Ă��Ă��p��F���E�B���h�E�ɂ͕\������Ă��܂���B
�܂� [��v���̍ŏ��l] �Ƃ����ݒ肩��킩��Ƃ���A�p��F���̓������Ɠ����悤�ɂ����܂���v�̗p����\�����Ă��܂��B�P���`�ƕ����`�⓮���̊��p�Ȃǂ��l����Ƃ����܂���v�͕֗��ł����A�����܂���v�ƋC�t�������̂܂g���Ă���Ɗ댯�ł��B
���̑��̐ݒ�ɂ��Ă��w���v�ɂ͂��낢��Ɛ���������܂����A�Ƃɂ����ʏ�̃e�L�X�g�����Ƃ͓������Ⴄ�Ƃ������Ƃ��ӎ����Ă����K�v������܂��B���́A�p��F���͂����܂ŕ⏕�I�Ȃ��̂ƍl���A�P���ȃe�L�X�g�������s���� Xbench �Ȃǂ̃c�[���p���Ă��܂��B
�lj��������ꍇ�́A�p��x�[�X�̏����ɒ���
�Ō�ɁA�|���ƒ��ɗp��x�[�X�ɗp���lj�����Ƃ��̒��ӓ_�ł��B�����Ɩł��ꂼ��̗p���I������ Ctrl+Shift+F2 �܂��� Ctrl+F2 �������ƁA�I�������p���p��x�[�X�ɒlj��ł��܂��B���̋@�\�̓����A�N�V�����ŗp���o�^�ł���̂łƂĂ��֗��ł����A[�v���W�F�N�g�̐ݒ�] �Őݒ肵�Ă���p��x�[�X�̏����ɒ��ӂ��Ă����K�v������܂��BCtrl+Shift+F2 �� Ctrl+F2 �͂ǂ�����A�v���W�F�N�g�̐ݒ�̈ꗗ�ň�ԏ�ɂ���p��x�[�X�ɒlj����s���܂��B�ǂ̗p��x�[�X�ɒlj����邩��I�Ԃ��Ƃ͂ł��܂���B
���̂��߁A�|���ƒ��ɗp���lj��������ꍇ�́A���炩���ߒlj��p�̗p��x�[�X����ԏ�ɒu���Ă����K�v������܂��B�|���Ђ�����ꂽ�p��x�[�X�͎����ł͕ύX���������Q�Ƃ�������������S�Ȃ̂ŁA�lj��p�̗p��x�[�X�������ō쐬���A�v���W�F�N�g�̐ݒ�ňꗗ�̈�ԏ�ɐݒ肵�Ă����܂��B
�����A�lj��p�̗p��x�[�X����ԏ�ɒu�����Ƃɂ͏�����肪����܂��B����́A�v���W�F�N�g�̐ݒ�̏����͗p��F���E�B���h�E�ɕ\������鏇���ɉe�����邩��ł��B�v���W�F�N�g�̐ݒ�ň�ԏ�ɒu�����p��x�[�X�́A�p��F���E�B���h�E�̈�ԍŏ��ɕ\������Ă��܂��B�Ȃ̂ŁA�{���Ȃ�A�|���Ђ�����ꂽ�p��x�[�X����ԏ�ɒu�������Ƃ���ł��B�ł����A��������ƃ����A�N�V�����ŗp���o�^���邱�Ƃ��ł��܂���B�܂��A�������������ɂȂ�̂͂Ȃ�ƂȂ������͂ł���̂ł����A���ۂɍ�Ƃ��Ă���ƁA���ꂪ�ǂ����C�ɂȂ��ċC�ɂȂ��ăC���b�Ƃ��Ă��܂��B
�ȏ�ł��B������ƒ����Ȃ�܂����B�p��x�[�X�̋@�\�͂ƂĂ��֗��ł����A���ꂾ���ł͕s���Ȃ��Ƃ�����܂��B�|���Ђ���ɂ���ẮA�p��x�[�X���v���W�F�N�g�ɐݒ肵�Ă��邾���ŁA�p��x�[�X�̌��f�[�^����Ă���Ȃ��ꍇ������܂��B�p��x�[�X�̐ݒ�͂������K�{�ł����A����ƍ��킹�Č��f�[�^���Q�Ƃł�����������S�ł��B
�^�O�F�p��̏d���������� �d���������� �p�ꂲ�ƂɃO���[�v������ �p��x�[�X���ƂɃO���[�v������ �t�B�[���h �p��W �}�C�N���\�t�g�̗p��W �p��F�� Xbench �|��̕\��
Tweet