


���̂Ƃ���́A���������A�W�X�ƁA�فX�ƁA�����ɂł��邱�Ƃ𑱂���ȊO�ɂȂ������Ȃ̂ŁA�܂��܂� Trados ����̏d���̃X�~�����Ă������Ǝv���܂��B����́A���؋@�\�ł��B
���؋@�\�ł́A���K�\����m���Ă���Ƃł��邱�Ƃ��ƂĂ������Ȃ�܂��B�ł��A���͂��̐��K�\�����ǂ������ł��B�����ō���́A���K�\���Ȃ��ł������܂łł���I�Ƃ����Ƃ�����Љ�Ă݂����Ǝv���܂��B
�ݒ��ς���O��
Trados �̌��؋@�\�ɂ́AQA Checker�A�^�O���؋@�\�A�p�ꌟ�؋@�\�� 3 ������܂��B�����̊T�v�ɂ��ẮA�ȑO�̋L�� ���؋@�\�̐ݒ������ ���Q�Ƃ��Ă��������B
�ݒ�̕ύX�� [�v���W�F�N�g�̐ݒ�] > [����] ����
�v���W�F�N�g���쐬������A�܂��̓p�b�P�[�W���J������Őݒ��ς������ꍇ�́A[�v���W�F�N�g�̐ݒ�] > [����] �Ɉړ����܂��B[�t�@�C��] > [�I�v�V����] > [����] �ł͂Ȃ��̂Œ��ӂ��Ă��������B���� 2 �̐ݒ�̈Ⴂ�ɂ��ẮA�ȑO�̋L�� Trados �̐ݒ��ς���ɂ� �| [�t�@�C��] �� [�v���W�F�N�g�̐ݒ�] ���Q�Ƃ��Ă��������B
�����̐ݒ���G�N�X�|�[�g���ĕۑ����Ă���
���̐ݒ�́A�|���Ђ��p�b�P�[�W�ɐݒ肵�Ă��Ă��邱�Ƃ�����܂��B�[�i���Ɍ��،��ʂ̃��O���ꏏ�ɔ[�i����悤�ɋ��߂��邱�Ƃ�����̂ŁA�����̐ݒ�Ɏ����Ŏ��������O�ɁA�ݒ���G�N�X�|�[�g���ăt�@�C���Ƃ��ĕۑ����Ă����܂��B�G�N�X�|�[�g���Ă����A�����ł��낢��ݒ��ς��Ă��A�G�N�X�|�[�g���Ă������t�@�C�����C���|�[�g���邱�ƂŌ��̏�Ԃɖ߂��܂��B�G�N�X�|�[�g�ƃC���|�[�g�́A[QA Checker �̃v���t�@�C��] ����s���܂��B
�G�N�X�|�[�g���Đݒ�t�@�C����ۑ�������A���Ƃ͎��R�ɂ��낢�뎎���Ă݂܂��傤�B
���߂̌��� �\ �֎~�������Ȃ����`�F�b�N����
���́A���̋֎~�����̃`�F�b�N���A�ł��ȒP�ŁA�ł��𗧂̂ł͂Ȃ����Ǝv���Ă��܂��BUI �͂Ȃ��悭�킩��Ȃ��\���ɂȂ��Ă��܂����A�`�F�b�N�{�b�N�X���I���ɂ��āA�E���̃e�L�X�g�{�b�N�X�ɋ֎~���������������炸��Ɠ��͂���� OK �ł��B
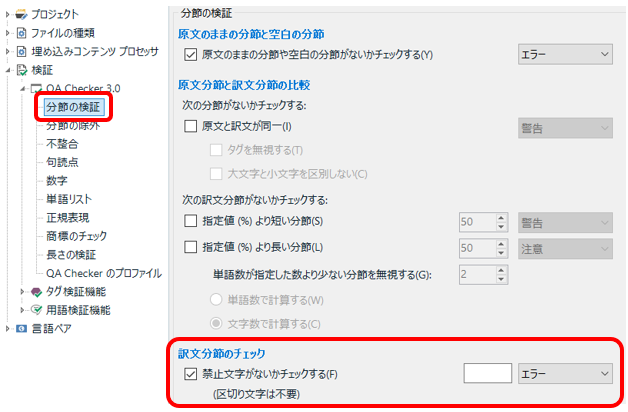
�֎~���镶���́A�X�^�C���K�C�h�ɏ]���āA�S�p�̉p�����A�e��̊��ʁA�R�����A���p���ȂǂȂǂł��B���͂��ʓ|��������A�ȉ����R�s�y���Ă��������B����Ȃɂ���������͂��Ă��܂��������Ȃ��@�\���܂��B���ʂ�R�����ȂǁA�X�^�C���K�C�h�ɂ���ĕς�镶���́A�擪�̕��ɓ��͂��Ă����A���̂��тɏ��������Ďg���ƕ֗��ł��B
�i�j�F�g�h�`�a�b�c�d�e�f�g�h�i�j�k�l�m�n�o�p�q�r�s�t�u�v�w�x�y�����������������������������������������������������P�Q�R�S�T�U�V�W�X�O�����������������������������������ĂƂȂɂʂ˂̂͂Ђӂւق܂݂ނ߂��������������A�C�E�G�I�J�L�N�P�R�T�V�X�Z�\�^�`�c�e�g�i�j�k�l�m�n�q�t�w�z�}�~�����������������������������[�������������������������ÂłǂтԂׂڃU�W�Y�[�\�^�a�d�f�h�o�r�u�x�{�ς҂Ղۃp�s�v�y�|�������������@�B�D�F�H�b���K�\�����g���Ă������`�F�b�N���ł��܂����A�֎~�����Ƃ��Đݒ肵�������G���[���킩��₷�����S�ł��B���K�\���ł̃`�F�b�N�́A���낢��Ȑݒ肪�ł��邾���ɃG���[�������Ȃ�A�댟�m�������Ȃ肪���ł��B�����Ȃ�ƁA�G���[�Ƃ��Č��o����Ă������Ƃ��댯���o�Ă��܂��B��ɋ֎~�Ƃ킩���Ă��镶���ɂ́A���̋֎~�����̃`�F�b�N�̕��������߂ł��B
��Ǔ_ �| �]���ȃs���I�h�ƃX�y�[�X
�p��̂Ƃ��́A�A������X�y�[�X�̃`�F�b�N���������܂��A����������ʓI�ȃ`�F�b�N�͂�����x�p�ӂ���Ă��܂��B

[��Ǔ_] �ɂ́A��}�̂悤�ɂ��낢��֗������Ȑݒ肪����܂��B���A�֗������Ȃ����ŁA[�]���ȃs���I�h�ƃX�y�[�X] �ȊO�̐ݒ�́A���{��Ɖp��̑g�ݍ��킹�̂Ƃ��͂��܂�𗧂��܂��� (�����܂ŁA�l�I���z�ł�)�B���ɁA[���ʂ̃`�F�b�N] �́A����������Ƃ����ɂ��֗������ł����A���̐����̂Ƃ���ɂ͋@�\���Ă���܂���B���̃`�F�b�N�́A�����Ɩɓ�����ނ̊��ʂ����邩���m�F���Ă���悤�ŁA���Ƃ��A�����͑S�p�̊��ʁA�͔��p�̊��ʂƂ��������ł��G���[�ɂȂ�̂ŁA�����ʂ��Ȃ��Ƃ������P�[�X��������̂ɂ͂��܂�𗧂��܂���B
�@�@
�P�ꃊ�X�g
���O�̂Ƃ���A�`�F�b�N�������P������X�g�A�b�v���ă`�F�b�N���܂��B�������Ȃ��P��ƁA�������P�����͂��邾���Ȃ̂ŁA�ƂĂ��킩��₷���ĊȒP�ł��B�X�^�C���K�C�h�ŁA�u�Ⴆ�v�Ɗ����ł͂Ȃ��u���Ƃ��v�ƂЂ炪�ȏ����ɂ���Ƃ����w��������ꍇ�ȂǂɎg���ƕ֗��ł��B

�����̃`�F�b�N�ɂ͌��E������
�P�ꃊ�X�g�̖��_�Ƃ��Ă悭��������̂������̃`�F�b�N�ł��B�P�ꃊ�X�g�́A�V���v���ɒP������o���邾���Ȃ̂ŁA�u�T�[�o�v���������Ȃ��āA�u�T�[�o�[�v���������Ƃ����P�[�X�ɂ͑Ή��ł��܂���B�������Ȃ��P��́u�T�[�o�v���A�������P��́u�T�[�o�[�v�̒��Ɋ܂܂�Ă���̂ŁA�u�T�[�o�[�v�Ɛ������Ȃ��Ă��Ă��G���[�Ƃ��Č��o����܂��B
������ [�P��P�ʂŌ�������] �Ƃ����`�F�b�N�{�b�N�X������܂����A����͓��{��̏ꍇ�ɂ͂��܂�K�ɋ@�\���܂���B�u�T�[�o�v�����o�������ꍇ�́A���K�\�����g�������Ȃ������ł��B�i��̓I�Ȑ��K�\���ɂ��ẮA������̋L�� �I�����C�������� (2019�N12��) ���Q�Ƃ��Ă��������B�j
���݂܂���A�G�X�P�[�v���������͎g���܂�
���̒P�ꃊ�X�g�ł����A���́A���͂ɂ͐��K�\�����g���K�v������܂��B�ǂ��ɂ�����Ȃ��Ƃ͏����ĂȂ��ł����A�u���K�\���v�Ƃ����`�F�b�N�͕ʂɓƗ����Ă���̂ł����A�Ȃ����P�ꃊ�X�g�ł����K�\�����g���K�v������܂��B�Ƃ����Ă��A����قǐS�z����K�v�͂���܂���B�u�T�[�o�[�v��u���Ƃ��v�ȂǁA���ʂ̕������琬��P�����͂���Ƃ��͉����ӎ����Ȃ��đ��v�ł��B���ӂ��K�v�ɂȂ�̂́A���p�̊ۊ��ʁA�s���I�h�A�^�╄�ȂǁA���K�\���Ɏg����L�����܂ޏꍇ�����ł��B
���Ƃ��A�ȉ��̂悤�ɐݒ肵���Ƃ��܂��B
�@�@�������Ȃ���`�F
(�t�@�C��)�@�@��������`�F
�t�@�C��(�t�@�C��) �Ɗۊ��ʕt���̕\�L�͐������Ȃ��A�t�@�C�� �Ɗ��ʂȂ����������Ƃ��܂��B�������A��L�̂悤�ɓ��͂���ƁA
(�t�@�C��) �̊ۊ��ʂ͐��K�\���̋L���Ƃ��ĉ��߂����̂ŁA���ۂɊۊ��ʕt���� (�t�@�C��) ���G���[�Ƃ��Č��o���邱�Ƃ͂ł��܂���B���̊ۊ��ʂ��A���K�\���ł͂Ȃ��A�������̂��̂Ƃ��ĔF�����������Ƃ��Ɏg���̂��A�G�X�P�[�v�����ƌĂ��~�}�[�N \ �ł��B�@�@�L�����ۂ����̂̑O�ɂ́A�~�}�[�N
\ ��t�������[���͂��ꂾ���ł��B�ۊ��ʁA�^�╄�A�A�X�^���X�N�ȂǁA���K�\���Ɏg��ꂻ���ȋL���̑O�ɂ͉~�}�[�N
\ ��t���Ă����܂��B�����t����ƁA���̋L���́A���K�\���̎��ł͂Ȃ��A�������̂��̂Ƃ��ĉ��߂���܂��B�@�@
\(�t�@�C��\) --> (�t�@�C��) �Ƃ����ۊ��ʕt���̒P�ꂪ���o������@�@
\\n --> ���s�}�[�N�ł͂Ȃ��A\n �Ƃ����������̂��̂����o��������́A���K�\���Ȃ�Č��������Ȃ��I�Ǝv���Ă���l�Ԃł����A���̃G�X�P�[�v���������͎g�킴��܂���B����̋L���́A���K�\�����g�킸�ɂȂ�Ƃ��撣��Ƃ�����|�ł͂���܂����A���݂܂���A�G�X�P�[�v���������͎g���Ă��������B
���K�\��
�ł́A���悢��u���K�\���v�ł��B���K�\���Ɩ��t�����Ă��܂����A���́A���K�\�����g��Ȃ��`�F�b�N���\�ł��B�O�q�̒P�ꃊ�X�g�̂悤�ɁA���ʂ̕������琬��P������o���邾���Ȃ�A���K�\���͕s�v�ł� (���݂܂���A�����ł��A�G�X�P�[�v�����͕K�v�ł�)�B�u���K�\���v�́A�u�P�ꃊ�X�g�v��肢�낢��Ȑݒ肪�ł���̂ŁA��蕡�G�ȃ`�F�b�N���\�ł��B
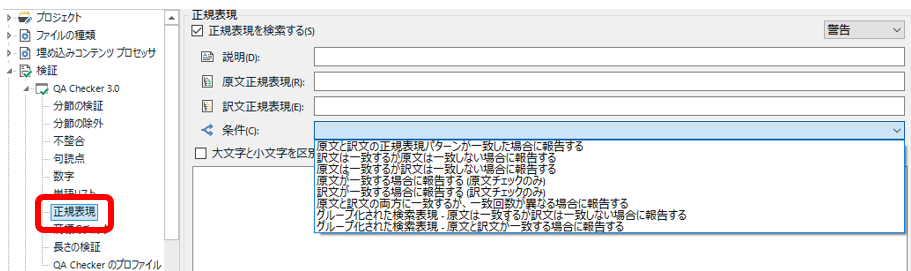
��}�̂悤�ɁA[����] �h���b�v�_�E���ɂ��낢��ȏ������ŏ�����p�ӂ���Ă��܂��B[�������K�\��] �� [���K�\��] �̂��ꂼ��Ɍ����ƖŌ��o���������ʂɓ��͂��āA���Ƃ͓K�ȏ�����I�ׂA�ݒ�͊����ł��B
�����Ɩ̐��K�\���p�^�[������v�����ꍇ�ɕ���
���̏����́A�P��̌��ԈႢ�̌��o�Ɏg���܂��B���Ƃ��Avirtually �� vertically �͎��Ă܂���ˁB���́A�������茩�ԈႦ�Ă��܂������Ƃ�����̂ŁA�ȉ��̂悤�ɐݒ肵�Ă��܂��B
�@�@�������K�\���F
vertically�@�@���K�\���F
���z�@�@�����F �����Ɩ̐��K�\���p�^�[������v�����ꍇ�ɕ���
����ŁA������ vertically ������̂ɁA�ɂ� ���z ���܂܂�Ă��镪�߂��G���[�ɂȂ�܂��B����ł��S�z�ȏꍇ�́A������ [��������v����ꍇ�ɕ��� (�����`�F�b�N�̂�)] �ɕύX���܂��B��������A������ vertically ���܂܂�镪�߂��A���Ȃ�ł��낤�ƊW�Ȃ��A���ׂČ��o�ł��܂��B���o���ꂽ��A���Ƃ� 1 �� 1 �m�F���Ă����܂��Bvertically �Ȃ�Ă߂����ɏo�Ă��Ȃ��A�Ƃ���������������A�����Ȃ����o�ł��邱�̏����̕������S�ł��B
�����Ɩ̗����Ɉ�v���邪�A��v���قȂ�ꍇ�ɕ���
�����ƖŁA���̓o����`�F�b�N���Ă���܂��B���Ƃ��A���߂̃A�X�^���X�N�̌��������Ă����A�Ƃ����悤�ȕ\�L���g���Ă���Ƃ��ɕ֗��ł��B�i�A�X�^���X�N�����o�������ꍇ�́A���L�̂悤�ɃG�X�P�[�v�����̉~�}�[�N��t���܂��B�j
�@�@�������K�\���F
\*�@�@���K�\���F
\*�@�@�����F �����Ɩ̗����Ɉ�v���邪�A��v���قȂ�ꍇ�ɕ���

��}�̂悤�ɐݒ肷��ƁA�ȉ��̂悤�Ȍ��ʂɂȂ�܂��B

1 �s�ڂ́A�A�X�^���X�N�������� 1 �A�ɂ� 1 �Ȃ̂ŁA�G���[�ł͂���܂���B2 �s�ڂ́A�����ɂ� 2 �ł����A�ɂ� 1 �Ȃ̂ŁA�G���[�ɂȂ�܂��B3 �s�ڂ̂悤�ɂ��������Đ�����̂��ʓ|�ȂƂ��͓��ɕ֗��ł��B
���āA�����ŏ����̕�����������x�悭�ǂ�ł݂܂��B�������ɋC�t���Ă����������������Ǝv���܂����A�u�����Ɩ̗����Ɉ�v���邪�v�ƂȂ��Ă���̂ŁA�����Ɉ�v���Ȃ��P�[�X�͂��̏����ł͌��o�ł��܂���B�܂�A�ɃA�X�^���X�N�� 1 ���Ȃ����߂̓G���[�ɂȂ�܂���B

��}�� 2 �s�ڂ悤�ɁA�A�X�^���X�N����͂��Y��Ă��܂��Ă��G���[�ɂ͂Ȃ�܂���B��������o����ɂ́A[�����Ɩ̗����Ɉ�v���邪�`] �̏����Ƃ͕ʂ� [�����͈�v���邪�͈�v���Ȃ��ꍇ�ɕ���] �Ƃ����������g���K�v������܂��B
����͈ȏ�ł��B���K�\����m��Ȃ��Ă��A���\���낢��ł��܂��B�|���Ђ�����炤�p�b�P�[�W�ɂ͌��̐ݒ肪�܂܂�Ă��邱�Ƃ�����̂ŁA���������ݒ���Q�l�ɂ��낢�뎎���Ă݂�̂��������Ǝv���܂��B
| �@�@ |
�^�O�F�֎~���� �P�ꃊ�X�g ���K�\�� ���� QA Checker �p�b�P�[�W �v���W�F�N�g�̐ݒ� �t�@�C���̃I�v�V���� [�t�@�C��] ����̐ݒ�
Tweet