


�u�t���O�����g��v�v�́uupLIFT �e�N�m���W�[�v�ɂ���Ď��������@�\�� 1 �ł��BupLIFT �e�N�m���W�[�ł́A�t���O�����g��v�����łȂ��u�����܂���v�̎����C���v�Ƃ����@�\����������Ă��܂��BupLIFT �e�N�m���W�[�Ƃ́A�ȒP�Ɍ����A���߂̒��̒P�� (�t���O�����g) ���x���ň�v�������Ă����e�N�m���W�[�̂悤�ł��B���̋L���̃^�C�g���͂킩��₭���邽�߁u�t���O�����g��v�v�Ƃ��܂������A�L���̓��e�́A�t���O�����g��v�Ɍ��炸�AupLIFT �e�N�m���W�[���W����e��ݒ�Ƃ������ƂŐi�߂����Ǝv���܂��B
upLift �e�N�m���W�[�ɂ��ẮA�ȑO�̋L���u�u2017 SR1 �A�b�v�O���[�h �Z�~�i�[�v�ɎQ�����Ă݂܂����v�ŏ����Љ�܂����B�ڍׂɂ��ẮASDL �̌����u���O�uSDL Trados Studio 2017 SR1�ɂ�����upLIFT�̓��{��Ή��Ɖ�͌��ʂ̍��قɂ����v���Q�l�ɂȂ�܂��B
| ���L�F����̐����Ɏg���Ă��� Trados �́A�o�[�W���� 2017 SR1 (���m�ɂ́A2017 SR1 14.1.10012.29730) �ł��B�ŐV�� 2019 �ł͈ꕔ�ς���Ă���Ƃ��낪����悤�ł��B |
upLIFT �e�N�m���W�[���W����@�\�̐ݒ���ȉ��̕\�ɂ܂Ƃ߂܂��� (����������ꂽ����ł��B�ق��ɂ�����܂�����A���Ђ��ӌ���������)�B����̑O�҂̋L���ł́u�v���W�F�N�g�̐ݒ�v�����グ�܂��B���̂ق��̐ݒ�́A����̌���ŏЉ�����Ǝv���܂��B
�v���W�F�N�g�̐ݒ�F
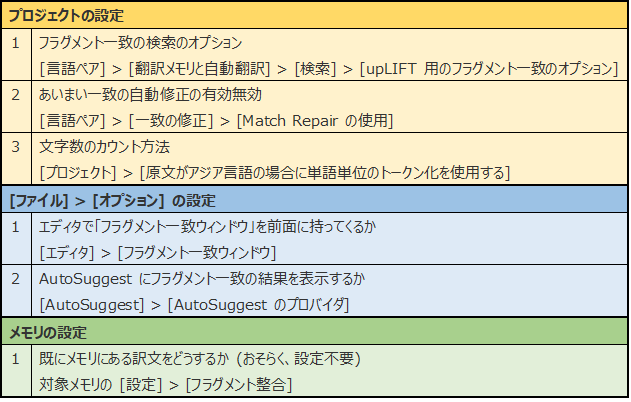
[����y�A] > [�|�����Ǝ����|��] > [����] > [upLIFT �p�̃t���O�����g��v�̃I�v�V����]
[����y�A] > [�|�����Ǝ����|��] > [����] > [upLIFT �p�̃t���O�����g��v�̃I�v�V����]
�������A�t���O�����g��v�̌������삻�̂��̂ɉe����^���郁�C���̐ݒ�ł��B[TU �S��] �̓`�F�b�N�{�b�N�X�ɂȂ��Ă��Ȃ��̂ŁA�L���������ւ��邱�Ƃ͂ł��܂���B�܂�A�u�t���O�����g��v�v�̋@�\���̂��̂��ɂ���ݒ�͂Ȃ��悤�ł��B(�����T��������A����܂���ł����B)
[TU �̃t���O�����g] �́A���ߑS�̂ł͂Ȃ��A���̒��̈ꕔ������v�������̂�\�����邩�ǂ����ł��B����́A�f�t�H���g�ł̓I�t�ł����A�I���ɂ��������q�b�g�������Ȃ�܂��B�܂��A�P�ꐔ�́A�ȑO�� SDL �̃Z�~�i�[�ŁA���{�ꌴ���̂Ƃ��́u2�v�ɐݒ肷��Ƃ悢�Ɛ�������܂����B
�܂��A[TU �̃t���O�����g] �`�F�b�N�{�b�N�X���I���ɂ���ƁA���}�̉E���̂悤�ɐԐF�̃}�[�N�̕t�����q�b�g���\�������悤�ɂȂ�܂��B���ꂪ�uTU �̃t���O�����g�v�ł��B��ԏ�ɕ\������Ă���F�̃}�[�N�́A�u�X�y�[�X�v�Ƃ����������̕��߂����邱�Ƃ��Ӗ����Ă���uTU �S�́v�Ƃ��ĕ\������Ă��܂��B

����ɁA�P�ꐔ��ς���Ɖ��}�̂悤�ɂȂ�܂� (�����ł́A[��v�̍ŏ��P�ꐔ] �� [��v�Ɋ܂߂�ŏ��d�v�P�ꐔ] �̗����ɓ����l��ݒ肵�܂���)�B�P�ꐔ�����Ȃ����������q�b�g�������Ȃ�܂��B�u2�v�ɂ���ƁA������������悤�ɂ��v���܂����A�u�ݒ�v�Ƃ��� 2 �����̒P��̖�ꂪ�\������Ă��܂��B���{��̏ꍇ�A���� 2 �����̒P��͂悭����̂ł�����ƕ֗���������܂���B

�u�P�ꐔ�v�̐ݒ�Ȃ̂ɕ������ɂȂ��Ă�H�H�Ƃ����^�₪�N���Ă͂��܂����A���܂�[���l���Ȃ����Ƃɂ��܂��B�܂��́u2�v�ɐݒ肵�Ă݂�A�q�b�g����������悤��������u3�v�ɂ��Ă݂�A�Ƃ��������Ŏ��͎g���Ă��܂��B
�v���W�F�N�g�̐ݒ�F
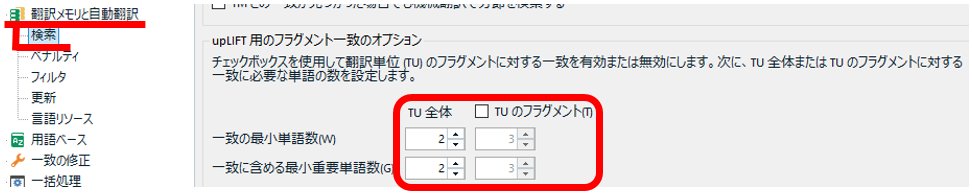
[����y�A] > [��v�̏C��] > [Match Repair �̎g�p] �� [Match Repair �\�[�X]
[����y�A] > [��v�̏C��] > [Match Repair �̎g�p] �� [Match Repair �\�[�X]
[Match Repair �̎g�p] �ł́A�u�����܂���v�̎����C���v�̗L���������ւ��܂��B�f�t�H���g�� [�G�f�B�^] �̂݃I���ɂȂ��Ă��܂��B�܂�A�G�f�B�^�ŕ��ʂɍ�Ƃ���Ƃ��ɁA���̋@�\���L���Ƃ������Ƃł��B���ꂪ�L���̏ꍇ�A�������̌������ʂɁA�����ŏC����������ꂽ���\������Ă��܂��B�C�����������Ă��邩�ǂ����́A��v���̂Ƃ����
 �̂悤�ɃX�p�i�̃A�C�R�������邱�Ƃł킩��܂��B
�̂悤�ɃX�p�i�̃A�C�R�������邱�Ƃł킩��܂��B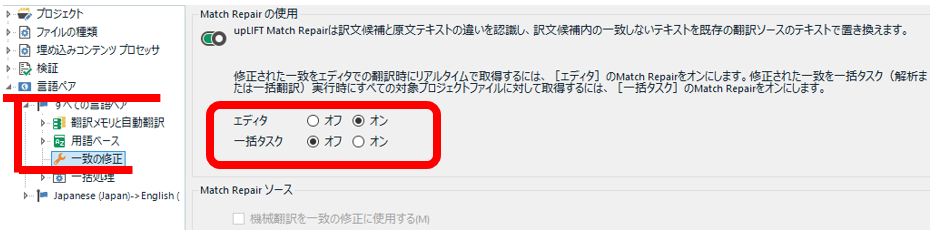
���́u�����܂���v�̎����C���v�ł����A�G�f�B�^�ŗL���ɂ��Ă���ƁA�G�f�B�^�̓������������x���Ȃ邱�Ƃ�����܂��B���̌o���ł́A�����������܂��Ă��Ď����C�������܂��@�\����悤�ɂȂ��Ă������Ȃ��A�Ƃ��傤�ǎv�������猟�����ʂ��Ȃ��Ȃ��Ԃ��Ă��Ȃ��Ȃ�A�ς����Ȃ��Ȃ邱�Ƃ������ł��B���̂悤�ȏꍇ�́A�ȑO�̋L���uTrados �̃G�f�B�^�̓������x���I�v�ł��Љ�܂������A���̋@�\���I�t�ɂ��܂��B
�����y�[�W�̉����ɂ́A[Match Repair �\�[�X] �Ƃ����ݒ���2������܂��B����́A�C���̎Q�l�ɂ���\�[�X�Ƃ����Ӗ����Ǝv���܂��B�|�����ŋ@�B�|����g�p����悤�ɐݒ肵�Ă���ꍇ�Ɍ���A�L���������ւ����܂��B���́A�@�B�|����g���Ďd�������邱�Ƃ����܂�Ȃ��̂ł����A�����g������Ȃ�L���ɂ������������̂�������Ȃ��ł��B
��2 �o�[�W���� 2019 �ł́A���̐ݒ�̃I�v�V�����������Ă���A�p��W�ɂ��Ă��L���������ւ�����悤�ł��B
�v���W�F�N�g�̐ݒ�F
[�v���W�F�N�g] > [�������A�W�A����̏ꍇ�ɒP��P�ʂ̃g�[�N�������g�p����]
[�v���W�F�N�g] > [�������A�W�A����̏ꍇ�ɒP��P�ʂ̃g�[�N�������g�p����]

����́A�������̃J�E���g���@�Ɋւ���ݒ�ŁA�������Ƃ̈�v���ɉe�����łĂ��܂��B�v���W�F�N�g�̐ݒ�̈�ԏ�ɂ��� [�v���W�F�N�g] ����ݒ肵�܂��B�I�t (= �g�p���Ȃ�) �ɂ���ƁAupLIFT �e�N�m���W�[���L���ł����Ă������P�ʂň�v�����v�Z����܂��B���ꂪ���{��Ȃǂ̃A�W�A����̂Ƃ��ɂ̂ݍl������K�v�̂���ݒ�ŁA���ꂪ�p��̂Ƃ��͖����ł���Ǝv���܂��B�ڍׂ́ASDL �̌����u���O�uSDL Trados Studio 2017 SR1�ɂ�����upLIFT�̓��{��Ή��Ɖ�͌��ʂ̍��قɂ����v���Q�Ƃ��Ă��������B���p�|��̂Ƃ��A�����������x�[�X�Ȃ�A�����̓I�t�ɂȂ��Ă���ׂ��ł��B
���̐ݒ�́A�ȑO�� SDL �̃Z�~�i�[�Łu�J�E���g�ɉe������v�Ɛ������ꂽ�L��������̂Ŏ��͂��̂悤�ɗ������Ă��܂����AUI �̕����ɂ́u�J�E���g�v��u��́v�Ƃ��������t�͈�ؓ����Ă��炸�A�J�E���g�ɉe�����邾���Ȃ̂��A�����@�\���̂��̂ɉe��������̂��A���ۂɂ͂悭�킩��܂���B�����A����܂ł̎��̌o���ł́A�������I�t�ł��A�G�f�B�^�ł͕��ʂ� upLIFT �e�N�m���W�[���@�\����悤�Ɏv���܂��B
�O�҂̍���͈ȏ�ł��B�c��̐ݒ�͎��̌�҂̋L���Ő����������Ǝv���܂��B�Ƃ����Ă��A���́A�f�t�H���g����ύX����K�v�̂���ݒ�́A�ŏ��ɐ������������I�v�V������ [TU �̃t���O�����g] ���炢�ł��B��́A���܂�C�ɂ����A�f�t�H���g�̂܂܂łȂ�ƂȂ��K���ɓ����悤�ȋC�����܂��B
�^�O�F2017 SR1 �t���O�����g��v upLIFT �e�N�m���W�[ TU �̃t���O�����g ��v�̏C�� Match Repair �̎g�p �������A�W�A����̏ꍇ�ɒP��P�ʂ̃g�[�N�������g�p���� ������ �J�E���g �����܂���v�̎����C��
Tweet