


確認ポイント 4 ― ロックされた分節を別に分類して報告する

4 つ目は「ロックされた分節」です。私のこれまでの経験では、この設定が間違っていることが一番多いように思います。
通常、この設定は「はい」で、ロックされた分節を別にカウントします。実際の仕事では、「ロックされている分節は作業対象外で!」と指示されることが多く、ロックとしてカウントされた部分は 0 円となります。まあ、ロックされているので明確ですし、作業対象外と言われればその指示に従うしかありません。
ただ、Trados のデフォルト設定は「いいえ」のようなんです。なので、間違えてロック部分もカウントに含まれていることがたまにあります。カウント数が増えるので、間違っていたらラッキー!なんて考えてはいけません。この設定が間違っていた場合、翻訳会社さんは必ず訂正してきます。たとえ発注書が発行された後でも、あるいは作業を開始した後でも訂正してきますよー。(私も何回かそんなことがありました。)
ロックされているので作業はしないですし、料金が支払われないのは当然ですが、作業の直前や作業の開始後の訂正は翻訳者としてはとても困ります。たとえば、翻訳会社さんから「当初の打診の時点では 10,000 ワードとお伝えしていましたが、実際にファイルを見てロック部分を除外してみたら 5,000 ワードでした」と言われると、10,000 ワード分の時間を確保していたのに!!余った時間はどうすれば??という事態になります。
この設定では、もう 1 つ注意点があります。
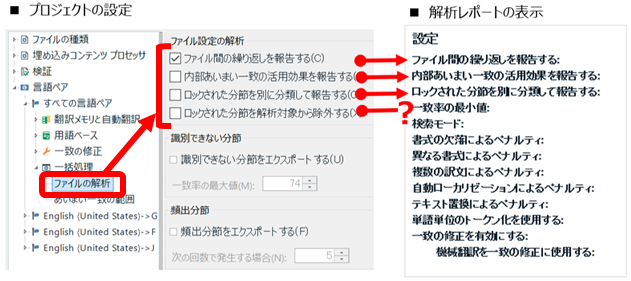
前回の記事で紹介した設定も含め、ファイルの解析のオプションは [プロジェクトの設定] -> [言語ペア] -> [一括処理] -> [ファイルの解析] から設定できます。この設定画面には、ロックされた分節に関するオプションが 2 つあります。
① ロックされた分節を別に分類して報告する
② ロックされた分節を解析対象から除外する
① の「別に分類して報告する」を選択すると、解析レポートに「ロック済み」という欄が増え、そこにカウント数が表示されます。そして、レポート上部のオプションの一覧には「ロックされた分節を別に分類して報告する: はい」と表示されます。
② の「解析対象から除外する」を選択すると、解析レポートではロックされた分節のカウント数は除外され、どこにも表示されません。そして、レポート上部のオプションの一覧にも、このオプションについての表示はありません。本当に、すべてから除外されるんです! 「ロックされた分節を別に分類して報告する」の表示は、② の設定に関係なく、① が選択されていない限り「いいえ」になります。
つまり、② の「解析対象から除外する」が選択されていても、解析レポート上ではそのことがわかりません。この「解析対象から除外する」のオプションは最近追加されたのでしょうか。私がこのオプションに気づいたのは最近です。解析レポートで「ロックされた分節を別に分類して報告する: いいえ」となっていても、翻訳会社さんに連絡する前に、一応「解析対象から除外する」オプションを確認してみましょう。
確認ポイント 5 ― 単語単位のトークン化を使用する

さて、最後のポイントは「単語単位のトークン化」です。これは、SDL Trados 2017 SR1 以降で、原文が日本語か中国語のときに関係してきます。原文が英語のときは気にする必要がないので、解析表にこのオプションは表示されてきません。
この設定は、単語ベースで解析するか、文字ベースで解析するかの選択ですが、詳細については、SDL のこちらのブログが参考になります。このブログの最後に「以前の解析方法(文字ベース)と新しい解析方法をユーザーが選択できるような仕組みを開発中です」とありますが、これで開発されたのがこの設定だと思います。
通常、これは「いいえ」です。原文が日本語の場合、料金は一般的に文字単価で計算されるので、当然ながら解析も文字ベースであるべきです。単語ベースで一致率を計算して、そこに文字単価を適用するとおかしなことになります。
ただ、上記のブログにもあるように、この設定は初期の SR 1 にはありませんでした。翻訳会社さんの使っている Trados のバージョンによってはこの設定がなく、単語ベースの解析が行われている可能性があります。(が、なかなか、翻訳者としてはそこまで確認しにくいですね~)
自分でカウントする場合、この設定は「プロジェクトの設定」から行います。[プロジェクトの設定] の最初の画面 [プロジェクト] で、[原文がアジア言語の場合に単語単位のトークン化を使用する] チェックボックスをオフにします。(デフォルトでオフのようです。)
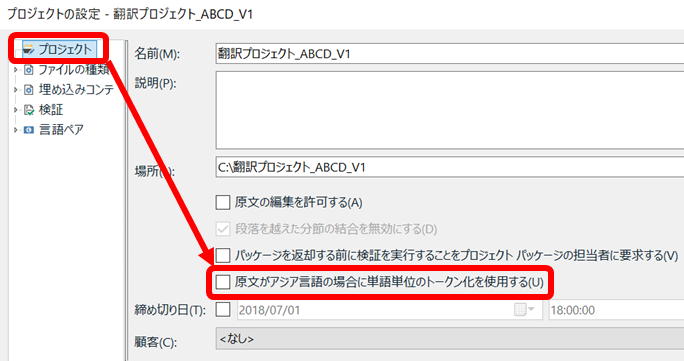
この設定が、解析結果だけでなくプロジェクト全体に何か影響するのかはちょっと不明です。これをオフにすると、解析レポートの「単語単位のトークン化を使用する」は「いいえ」になります。その状態でも、upLift の機能であるフラグメント一致などは有効に機能する気がします。
なお、プロジェクトの設定やファイルの大きさによるかもしれませんが、「単語単位のトークン化を使用する」がオンになっているとファイルの解析にかかる時間が異常に長くなることがあります。ファイルの解析は、もともと少し時間のかかるタスクですが、この時間がさらに長くなります。(私は、20 分以上かかったことがあり、失敗したぁと思いました。)
※※※ 追記 2018/11/21 ※※※
この設定をオンにすると処理時間が長くなるのかと思っていたのですが、これをオンにしなくても処理時間は長くなることがあります。フラグメント一致のカウント数は料金に関係しないので、この機能なしでカウントできればいいのですが、、、
※※※※※※※※※※※※※※※
あまり確認しないポイント ― 各種ペナルティ

最後に、私があえてあまり気にしないようにしているポイントを挙げておきます。それは、上記の図に赤枠で示した各種のペナルティです。
数字がうまく変換されないとか、書式が違ったら文のスタイルも違ってくるとか、タグが挿入されてこないとか、複数の選択肢があったら困るとか、翻訳者としてはいろいろ主張したいところではありますが、正直に言って、私は最近あきらめぎみです。それぞれについて細かく調べて理路整然と翻訳会社さんに異議を申し立てるのは簡単ではありません。
ただ、翻訳会社さんも深く検討したうえでこのペナルティを決定しているとは限らないと思います。Trados のデフォルト設定は、上記のとおり、上の 3 つが 1% で、下の 2 つが 0% です。デフォルト設定のままの場合もありますが、設定が変えられている場合もかなりの頻度であります。どちらにしても、私は、これまで、これこれこういう理由でこのペナルティを設定しています、というような説明を翻訳会社さんから受けたことはありません。同じコーディネーターさんでも、デフォルト設定のままだったり、設定が変更されていたりといろいろです。(もちろん、それぞれのファイルを検討したうえで最適な設定にしている、という可能性もなくはないですが。)
結局、私は、コンテキスト マッチや 100% マッチが作業対象である場合は、ペナルティを深く考えないようにしています。100% でも 99% でも作業することに変わりはないので、多少のレートの差はあきらめます。
もし、コンテキスト マッチや 100% マッチが作業対象に含まれない場合は、ここのペナルティをどうこうするのではなく、とにかく作業対象外の部分を事前にロックしてくれるように翻訳会社さんにお願いします。ロックされていれば明確なので、それを信じて作業します。
以上です。前回の記事から引き続きカウント表について説明してきました。カウントは毎回毎回のことなので、重要とはわかっていても、ついつい確認を怠ってしまうことがあります。翻訳会社さんへの連絡は、遅くなればなるほど行いにくくなるものです。作業ファイルを受け取ったら、なるべくすぐに確認することをお勧めします。(私も、そうしたいと常々思ってはいます。)
タグ:upLIFT テクノロジー 文字数 ワードカウント ワード数 ファイルの解析 SDL Trados Studio カウント ロックされた分節 ロック 単語単位のトークン化 プロジェクトの設定 Trados Studio 2017 SR1 ペナルティ
Tweet
カウント表の数字、難しいですよね。
私は、基本的には翻訳会社さんを信用しますが、一応確認はした方がいいと思っています。
誰でも、間違えることは、ありますので。
今回はじめてTrados案件をもらい、カウント方法がわからず大変困っていたところ、こちらのサイトで命拾いしました。
普段このようなところにコメントするタイプではありませんが、思わずお礼をさせていただきました。とても有益な情報をたくさん、有難うございます。