


具体的には、次の 2 つのことを行います。
- 提供されたメモリは更新せず、自分の訳文は別のメモリに保存する。
- ヒットしてきた訳文が、どのメモリのものなのかひと目でわかるようにする。
この記事では、1 つ目の「提供されたメモリは更新せず、自分の訳文は別のメモリに保存する」方法を紹介します。2 つ目については、また次の記事で取り上げたいと思います。
まず、翻訳会社さんからメモリを提供された場合、そのメモリは更新せず、そのままとっておく方が安全です。後になってから、もともとの訳文を見たいと思うことはよくあるので、自分の訳文で更新してしまうのは避けたいところです。
じゃあ、自分の訳文はどうするかというと、別のメモリを作成してそこに保存するようにします。
| 注記: 一部の翻訳会社さんのパッケージには「プロジェクト用メモリ」が設定されている場合があります。プロジェクト用メモリは、まさに、「自分の訳文をメインメモリとは別に保存する」ということをやってくれるのだと思いますが、私は、この「プロジェクト用メモリ」の動きがどうも理解できず、、、 結局、「プロジェクト用メモリ」が設定されていても、新たにメモリを作り、自分の訳文はそちらに保存するようにしています。 |
では、手順を説明しましょう。
1. 新しいメモリを作成する

まず、自分のメモリを保存するための新しいメモリを作成します。[プロジェクトの設定] -> [言語ペア] -> [翻訳メモリと自動翻訳] と選択して、メモリの設定画面を表示します。 [作成] -> [翻訳メモリの作成] をクリックして、表示された画面の指示に従ってメモリを作成します。いろいろ設定はありますが、とりあえず、画面の指示に従ってそのまま作成します。
新しく作成したメモリは、リストの最後に表示されます。このリストの順序はメモリの検索順序に影響します。一番上にあるメモリが最初に検索されるので、提供されたメモリを上に、自分のメモリは下に置いておくのがいいと思います。
2. 更新するメモリを設定する
メモリを作成したら、[更新] 列で、作成した自分のメモリだけをチェックし、ほかのメモリはチェックを外します。
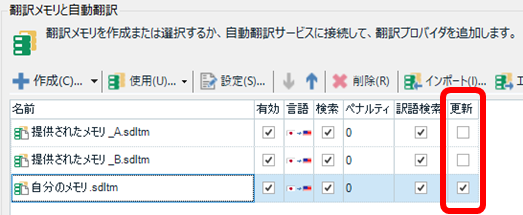
これで、エディタで入力した訳文は「自分のメモリ.sdltm」だけに登録され、提供されたメモリには何の変更も加えられないことになります。
翻訳会社さんによっては、この状態まで設定したうえでパッケージを送ってきてくれることがあります。その場合、自分でメモリを作成する必要はないので、すぐに作業を開始できます。(助かります!)
また、翻訳会社さんからのパッケージでは、たまに、どのメモリにも [更新] のチェックが入っていないことがあります。翻訳会社さんはバイリンガル ファイルさえあればメモリはいらないので、「いずれのメモリも更新しない」という設定にしてくるのもわからなくはありません。ただ、作業を進めてしまってから、訳文がメモリに登録されていないことに気づくとちょっと悲しいので、更新されるメモリが設定されているどうかを作業前に確認しておくことをお勧めします。
3. ペナルティを設定する
[更新] のチェックさえ設定すれば作業を開始できますが、必要に応じて [ペナルティ] を設定しておくと便利です。このペナルティは、メモリのマッチ率を差し引くペナルティです。メモリごとに設定できるので、「特定メモリからのヒットについてはマッチ率を下げる」ということができます。
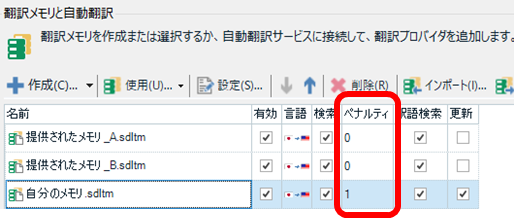
私は、自分のメモリにはペナルティ「1」を設定することが多いです。このようにしておくと、自分のメモリからのヒットがエディタ上で 100% マッチやコンテキスト マッチとなることを避けられます。
100% マッチやコンテキスト マッチは「作業対象外で!」と指示されることがあると思いますが、エディタ上で自分のメモリからのヒットが「100%」や「CM」と表示されてしまうと、どこが作業対象外だったのかわからなくなってしまいます。また、「作業対象外」でないとしても、提供されたメモリとの 100% マッチと、自分の訳文との 100% マッチでは、まったく意味が違ってきます。提供されたメモリとの 100% マッチなら、まあ軽く見直す感じですが、自分の訳文のときはそうはいかないですよね。
作業対象外の分節については、あらかじめロックしてきてくれる翻訳会社さんもありますが、なかなかそんな会社さんばかりではありません。Trados のデフォルト設定では、完全一致はロックがかかりますが、100% マッチとコンテキスト マッチはロックがかかりません。そのためか、「100% マッチとコンテキスト マッチは作業対象外だけどロックされていない」という状態のパッケージを受け取ることがたまにあります。(翻訳者としては、この状態はとても困ります。)
安全のため、ロックを使用する方が私は好きですが、ロックはマッチ率以外の条件で使用されることもあり、パッケージを受け取った翻訳者が勝手にロックをかけるわけにはいかない場合もあります。そのようなときでも、このペナルティを設定しておけば、自分の作業中に 100% マッチやコンテキスト マッチが新たに発生することがないので安心して作業できます。
今回は、以上です。メモリの作成は慣れてしまえばとても簡単です。ちょっとひと手間ではありますが、あとあとのことを考えると、やはり自分用のメモリを作成して作業するのが安全かと思います。
次回は、2 つ目の「ヒットしてきた訳文が、どのメモリのものなのかひと目でわかるようにする」方法を紹介したいと思います。これも、設定の手間はかかりますが、私はとても便利に感じています!
Tweet
ほんとに、Trados の細かい情報って意外と少ないですよね。
私も、いつもいつも手探り状態です。
今後も、ぜひぜひご意見をお聞かせください!
TradosのこういったTipsはネット上にもあまり転がっていないので、とても助かります。
いつも有益な情報ありがとうございます!