


���S��v���܂܂�Ă�������̃v���W�F�N�g�́A�悭��������ł̖|��ł����B�\�t�g�E�G�A�̃}�j���A���ŁA�o�[�W���� 1 �̊�����o�[�W���� 2 �ɃA�b�v�f�[�g������̂ł��B����|��o�[�W���� 2 �̃t�@�C���́A���}�̃T���v���̂悤�ɁA�o�[�W���� 1 �Ƃ̊��S��v�Ŋ��Ɉꕔ�������Ă����ԂŎ��܂����B

���S��v�Ƃ́H
��v�̎�ނ̊T�v�ɂ��ẮA�����u���O�́u�u100% ��v�v�Ɓu���S��v�v�̈Ⴂ�v���Q�l�ɂ��Ă��������B���̌����u���O�ł���������Ă��܂����A���S��v (PM) �́u��v�v�́A�������Ƃ̈�v�ł͂Ȃ��A�o�C�����K�� �t�@�C���Ƃ̈�v���Ӗ����Ă��܂��B���S��v�̓���������Ȃ��̂ŁA�^�O��F���ς݃g�[�N���̕ϊ������������A�����ł̖����̉e�����܂���B�Ƃɂ����A���ۂɃo�C�����K�� �t�@�C���Ŏg���Ă�������̂܂܃R�s�[����Ă��܂��B
����ߍ��ވꊇ�^�X�N: �u���S��v�̓K�p�v�Ɓu�ꊇ�|��v
�ŏ��ɋ������}�̂悤�� PM�ACM�A100% �����������o�C�����K�� �t�@�C���́A�|���Ђ��u���S��v�̓K�p�v�Ɓu�ꊇ�|��v�Ƃ��� 2 �̈ꊇ�^�X�N���g���Ċ���ߍ���ō���Ă��܂��B

�܂��A�u���S��v�̓K�p�v�^�X�N�ŁA�o�[�W���� 1 �̃o�C�����K�� �t�@�C�����������R�s�[���܂��B���̂Ƃ��ɃR�s�[���ꂽ���߂��uPM�v�ƂȂ�܂��B���̌�A�u�ꊇ�|��v �^�X�N�ō��x�̓��������������R�s�[���܂��B���ꂪ��ʓI�ȃ}�b�`�ŁuCM�v�܂��́u100%�v�ƂȂ�܂��B
�@�� ���S��v�̓o�C�����K�� �t�@�C������R�s�[
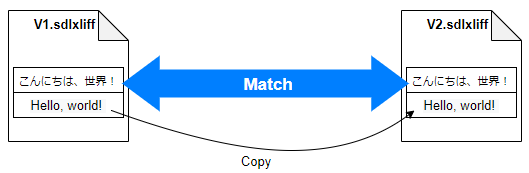
�@�� CM �� 100% �̓���������R�s�[

���Ȃ݂ɁA���̎g���Ă���t���[�����X�łł́u���S��v�̓K�p�v�^�X�N�͎��s�ł��܂��� (��}�̂悤�ɃO���[�A�E�g����Ă��܂�)�B���̃^�X�N�̓v���t�F�b�V���i���łł̂ݎg�p�\�ł��B�l�ł��g���������Ƃ͂���̂ŁA���̐����͂��Ђ��Љ������ė~�����̂ł����A�����ł����ˁA���߂ł����ATrados ����H
�ŗD��ŎQ�l�ɂ��ׂ��͊��S��v
����̂悤�ȉ����ł̖|��ł́A�p���\����O�łɍ��킹��K�v������܂����A���̂Ƃ��ŗD��ɂ��ׂ��́APM �̖ł��BCM �� 100% ���APM �ł��B
CM �� 100% �̓������Ƃ̈�v�Ȃ̂ŁA���ꂪ�{���Ƀo�[�W���� 1 �Ɏg���Ă����Ȃ̂��͂킩��܂���B���������o�[�W���� 1 �̃t�@�C������̂ݍ���Ă���̂ł���ACM �� 100% �� PM �͂قړ������ʂɂȂ�܂����A����ȒP�������ꂢ�Ƀ�����������Ă��邱�Ƃ͂܂�ł��B�����Ă��̃������́A�Q�l�̂��߂ɂƕʃ}�j���A���̖������Ă�����A�����Ȃǂ̗��R�ŕ����̖������Ă����肵�܂��B�܂��A�v���W�F�N�g�ɂ���Ă̓������������w�肳��Ă��邱�Ƃ�����A���̏ꍇ�́ACM �� 100% �ƕ\������Ă��Ă��ǂ̃������Ƃ̈�v�Ȃ̂��͂킩��܂���B
����APM �́A�������ł͂Ȃ��A�o�[�W���� 1 �̃t�@�C�����璼�ڃR�s�[���ꂽ�Ȃ̂ŁA�ԈႢ�Ȃ��o�[�W���� 1 �Ŏg���Ă����Ƃ������ƂɂȂ�܂��B���̂��߁A�o�[�W���� 2 ��|��Ƃ��ɍł��Q�l�ɂ��Ȃ���Ȃ�Ȃ��̂� PM �ł��B
���S��v�̓������ɓ����Ă��Ȃ����Ƃ�����
�Ƃ����킯�ŁAPM �̖��Q�l�ɂ����������̂ł����A����͂��ꂪ�������ɓ����Ă��܂���ł����B���ʁA�o�[�W���� 2 ��Ƃ��̓o�[�W���� 1 �̖��������ɓ������̂ł����A�u���S��v�̓K�p�v�^�X�N�ł̓��������g��Ȃ��̂Łu�o�C�����K�� �t�@�C���ɂ͓K�p��������ǂ��A�������ɂ͓���Ȃ������v�Ƃ������Ƃ��N���蓾�܂� (�N���蓾�邾���ŁA�Ӑ}�I�ɂ���ȏ�Ԃ����Ƃ͍l���ɂ����̂ŁA�����炭�~�X�ł�)�B
PM �Ƃ��ăo�C�����K�� �t�@�C���ɃR�s�[����Ă��邾���ł́A�������̈�v�Ƃ��ăq�b�g���Ă��܂��A��ꌟ���ł��g���܂���B���̂悤�ȏ�Ԃł́APM �̖��ŗD�悵�����Ă��ł��܂���B
���S��v�̃������������ō��
�uPM�v�ƕ\������Ă��镪�߂̖��������ɓ����Ă��Ȃ����ƂɋC�t�����ꍇ�́A������ PM �̖��������Ɏ�荞��Ń������Ƃ��ĎQ�Ƃł���悤�ɂ��܂��B�菇�͊ȒP�ł��B
�@�@1�D�V�������������쐬����B
�@�@�@�EPM �ł��邱�Ƃ���ʂł���悤�ɁA�t�B�[���h��lj�����B
�@�@2�D�쐬�����������ɁA�o�[�W���� 2 �̃o�C�����K�� �t�@�C�����C���|�[�g����B
�@�@�@�E�C���|�[�g����X�e�[�^�X�Ƃ��āu�����[�X�v���w�肷��B
�@�@�@�E�t�B�[���h�ɁA�uPM�v�ȂǁA�킩��₷���l����͂���B
1�D�V�������������쐬
�܂��A���ꂽ�������Ƃ͕ʂɐV�������������쐬���܂��B�����ɁAPM �̖������C���|�[�g���܂��B�V�����������ɂ́A�ォ�� PM �Ƃ킩��悤�ɂ��邽�߃t�B�[���h��lj����܂��B�t�B�[���h�͐V�K�쐬�̃E�B�U�[�h�ɏ]���đ��삷��ΊȒP�ɒlj��ł��܂����A�쐬������ł� [�ݒ�] ��ʂ���lj��ł��܂��B(�t�B�[���h�ɂ��ẮA�ȑO�̋L���u���ꂽ�Ǝ����̖���ʂ��� �[ �A �ǂ̃������̖���\�������v���Q�l�ɂ��Ă��������B)
2�D�o�C�����K�� �t�@�C�����C���|�[�g
�쐬�����������Ƀo�C�����K�� �t�@�C�����C���|�[�g���܂��B���̂Ƃ��A�X�e�[�^�X���u�����[�X�v�̕��߂݂̂��C���|�[�g����悤�ɐݒ肵�܂��BPM �̕��߂́A�ʏ�A�X�e�[�^�X���u�����[�X�v�ɂȂ��Ă��܂� (�����A�Ȃ��Ă��Ȃ��ꍇ�́A���L�́u�X�e�[�^�X�́u�����[�X�v���g�p�ł��Ȃ��ꍇ�v���Q�l�ɂ��Ă�������)�B

�E�B�U�[�h�ɏ]���Đi�ނƃt�B�[���h��ݒ肷���ʂ��\�������̂ŁA[�ҏW] �{�^�����N���b�N���ăt�B�[���h��ݒ肵�܂��B���}�ł́A�uFlg�v�Ƃ������O�̃t�B�[���h�ɁuPM�v�Ƃ����l��ݒ肵�Ă��܂��B

����ɃC���|�[�g�ł�����A���̃��������v���W�F�N�g�ɒlj����āA�|���ƂŎQ�Ƃ���悤�ɂ��܂��B�t�B�[���h��ݒ肵�Ă����ƁA�����̖��}�b�`���Ă��Ă��A�ȉ��̂悤�ɉE�[�Ƀt�B�[���h���\�������̂ŁA�ǂ̃���������̃}�b�`�Ȃ̂����킩��₷���Ȃ�܂��B���}�ł́A��i�̖� PM �̖A���i�̖͑��̃���������̖ł��B

�X�e�[�^�X�́u�����[�X�v���g�p�ł��Ȃ��ꍇ
��L�̎菇�ł́A�C���|�[�g����Ƃ��ɃX�e�[�^�X���u�����[�X�v�ł��邱�Ƃ������ɂ��܂����B����́A�C���|�[�g����Ƃ��̃I�v�V�����Ƃ��Ă͂��ꂵ���Ȃ��̂Ŏg�p���������ł��B�ʏ�APM �̕��߂̓X�e�[�^�X���u�����[�X�v�ƂȂ��ă��b�N����Ă��܂����A���̏�Ԃ͐�ł͂���܂���BPM �ł��X�e�[�^�X���u�����[�X�v�łȂ����Ƃ͂��蓾�܂��B�܂��APM �ȊO�̕��߂̃X�e�[�^�X���u�����[�X�v�ɂȂ��Ă���ꍇ������܂��B
�����Ƃ��āu�����[�X�v���g�p�ł��Ȃ��ꍇ�́A���x�ȕ\���t�B���^���g�p���܂��BPM �̕��߂݂̂𒊏o���āA�o�C�����K�� �t�@�C�������܂��B

[�����̃t�B���^] �^�u�� [���f�[�^] �� [���S��v] ��I�����ăt�B���^�������A���̌� [����] �{�^�����N���b�N���܂��B����ŁA�t�B���^�Œ��o���ꂽ���߂������o�C�����K�� �t�@�C���Ƃ��ăG�N�X�|�[�g�ł��܂��B���̕��@�ŃG�N�X�|�[�g�����t�@�C�����������ɃC���|�[�g���܂��B
�������̃t�B�[���h��ݒ肵�Ȃ������ꍇ
���������C���|�[�g����Ƃ��Ƀt�B�[���h��ݒ肵�Y��Ă����v�ł��B�t�B�[���h�̒l�͌ォ��ꊇ�œ��͂ł��܂��B�|���� �r���[�̃��{������ [�ꊇ�ҏW] �{�^�����N���b�N����ƁA���������̖�t�B�[���h���ꊇ�ŕҏW�ł��܂��B

[�lj�] �{�^�����N���b�N����ƁA[�t�B�[���h�̒l�̕ύX] �Ƃ����I�v�V�������\������܂��B�����I�����āA���͂������t�B�[���h�ƒl��ݒ肵�܂��B
����͈ȏ�ł��BPM �͉����|��Ȃǂł͂ƂĂ��֗��ȋ@�\�ł��B�����A��Ƃ���Ƃ��͂��̈Ӗ��𗝉�������ŗL���Ɏg���K�v������Ǝv���܂��BTrados �́A�������G�ɂȂ邱�Ƃ�����܂����A�����Ŏ��R�ɑ���ł��邱�Ƃ��ő�̃����b�g�ł��B�p�b�P�[�W������č�Ƃ���ꍇ�ł��A�ł���͈͂ōH�v�����Ă݂邱�Ƃ����������܂���B
| �@�@ |
�^�O�FPerfect Match CM �ꊇ�ҏW �����[�X PM �t�B�[���h �ꊇ�|�� ���S��v�̓K�p 100%�}�b�` 100%��v �R���e�L�X�g �}�b�` ���S��v ���x�ȕ\���t�B���^ �����̃t�B���^ �t�B�[���h�̒l�̕ύX �ꊇ�ҏW�X�N���v�g �g���u���V���[�e�B���O ���������q�b�g���Ă��Ȃ�
Tweet