


��L�̃Z�b�V�����ł������Ă��܂������A�c�[���͎g���ړI���g�������l���ꂼ��ł��B����l���u����͕֗��v�ƌ����Ă��Ă��A���ꂪ�����̖ړI�ɂ͍���Ȃ����Ƃ�����܂��B���̂��̃u���O�S�̂͌l�|��҂�z�肵�Ă��܂����A����� Xbench �̊ϓ_������������ׂ������������Ƃ���Ȋ����ł��B
- Trados �� Xbench �̑g�ݍ��킹������ (= ���� CAT �c�[���̎g�p�p�x�͒Ⴂ)
- ��������͎�ɁA���{�� -> �p��
- Xbench �͖����łōς܂�����
- �|���Ђ���p�b�P�[�W����� (= ������ݒ������ɂ͕ς����Ȃ�)
- ��������p��W���x������� (= ��Ɍ����Ƃ��Ȃ�����������)
- Xbench �̎�ړI�͌��� (= QA �@�\�͕⏕�I�ɂ����g��Ȃ�)
�ȉ��ɂ́A����ȏ̎����֗����Ǝv���Ă��邱�Ƃ��Љ�����Ǝv���܂��B���Ђ��ЁA�����g�ł��낢��Ǝ����Ă݂Ă��������B
�܂��͑�O��@�\�@Trados �ŕ��߂��m�肵�AXbench �Ńt�@�C�����X�V����
Trados �� Xbench ��g�ݍ��킹�Ďg���ꍇ�A�܂��́ATrados ��ŕ��߂��m�肷��K�v������܂��BXbench �ł͊m��ς݂̕��߂��������� QA �̑ΏۂɂȂ�܂���BTrados ��Ŗ���͂��Ă��Ă��A�X�e�[�^�X�����m�肾�� Xbench �ł� Untranslated �ƂȂ�A���F������܂���B
Trados �ŕ��߂��m�肵�ăt�@�C����ۑ�������A���̌�AXbench �Ɉړ����ăt�@�C���̍X�V�����܂��B����ŏ��߂āA�ŐV�̃t�@�C���ɑ��Č����� QA ���s����悤�ɂȂ�܂��B�X�V������ɂ́A[View] > [Refresh] (F5 �L�[) ���A�㕔�ɕ���ł���{�^���� [Reload] �{�^�� (Shift+F5 �L�[) ���g���܂��B[Refresh] �́ATrados �Ŗ|�̃t�@�C�� (Ongoing Translation �ɐݒ肵�Ă���t�@�C��) �݂̂��X�V����ꍇ�Ɏg���܂��B[Reload] �́A�p��W�Ȃǂ��܂߂Ă��ׂčX�V�������ꍇ�Ɏg���܂��B����̎��ԊԊu�Ŏ����X�V���s���I�v�V����������܂����A���́A�X�V�������Ƃ��Ɏ蓮�ōX�V���Ă��܂��B

�v���ӁI�@�\�@�����������߂̖͔F������Ȃ�
Trados ������߂������������Ƃ�����Ǝv���܂��B����́A�|���Ƃł͕֗��ł����AXbench ���g���Ƃ��͖��ɂȂ�܂��BTrados �Ō����������߂́AXbench �ŃX�e�[�^�X�����܂��F������Ȃ��炵���A��L�Ɠ��� Untranslated �ɂȂ��Ă��܂������� QA �̑ΏۂɂȂ�܂���B���̌����Ȃ疳�����Ă�������������܂��A��ʂɂ���Ƃ��̕��߂� QA ������Ȃ����ƂɂȂ�̂Ŗ��ł��B(���ꂪ�A�L���ł� V3 ����������P����Ă���Ƃ��������Ƃ͂Ȃ��ł����ˁH ���������Ȃ�A�w�����������Ă�������������Ȃ��ł��B�����܂ŁA�����ł��� �D�D�D)
�����̂��߂̐ݒ�@�\�@�D��x�Ə���
Trados �ŕ��߂��m�肵�� Xbench �ōX�V�������炢�悢�挟���ł��B�ł��A�܂��������ӂ������ݒ肪����܂��BXbench �ł͑�ʂ̃f�[�^�ł��������ʂ������ɕԂ��Ă��܂����A���̎d�g�݂𗝉����Ă����Ȃ��ƌ����R��ɂȂ���܂��B

Xbench �̃v���W�F�N�g�ł́A��}�̂悤�� Priority �Ƃ��� High�AMedium�ALow �� 3 �̃��x�����w��ł��܂��B����ɁA���̗D��x�̊e���x���̒��ŏ��� (Order) ���w��ł��܂��B�������ʂ́A���� Priority �� Order �̏��Ԃŏォ�珇�ɕ\������܂��B
���́A�����Ă��A�ȉ��̂悤�Ȑݒ�ɂ��Ă��܂��B
- High: �|���Ђ�����ꂽ�������Ɨp��W (= ��Ɍ����������Ȃ�����)
- Medium: �|�̃t�@�C�� (= �����̌��݂̖�)
- Low: ���̑� (= �C�ӂŎQ�l�ɂ��鎑���B�ߋ��̖A�ގ������̃������Ȃ�)
Priority ���Ă����ƁA���}�̂悤�ɐF���ς��̂Ō����Ƃ��S�z������܂���B����ŁA�ΐF�� High �ł��B

�������ʂ̉�ʂł́A��}�̂悤�ɁA�E������ [Click here to show all matches] �Ƃ������b�Z�[�W���\������Ă��Ȃ����ɒ��ӂ���K�v������܂��B
�����̂��߂̐ݒ�@�\�@���x�����Ƃ̕\����
���ۂɌ������s���ƁA�E������ [Click here to show all matches] �ƕ\������邱�Ƃ�����܂��B���̃��b�Z�[�W�́A���̌������ʂɕ\������Ă��Ȃ��}�b�`�����邱�Ƃ��Ӗ����Ă��܂��B
��ʂ̃f�[�^����������ƁA���R�Ȃ��猟�����ʂ���ʂɂȂ肪���ł��BXbench �ł́A���������邽�߂� Priority �̃��x�����ƂɌ������ʂ̕\������ݒ�ł��܂��B����ł� (�����炭) 25 �s�ł��BHigh ���������D��ł����AHigh �̌��ʂ� 25 �s�\��������A����ȏ�}�b�`�������Ă�����͕\�������AMedium ��\�����܂��BMedium �� 25 �s�܂ŕ\�����āA���̌�� Low ��\�����܂��B�������邱�Ƃɂ���āA�ǂ�Ȃɑ�ʂ̃}�b�`�������Ă��A�������ʂ̍ŏ��̉�ʂ� High ���� Low �܂ł��ׂẴ��x���̃}�b�`���ꗗ�ł���悤�ɂ��Ă��܂��B
���x�����Ƃ̕\�����̐ݒ�́A[Tools] > [Settings] �ƑI������ [Layout & Hotkeys] �^�u�ōs���܂��B

�������ʂł��ׂẴ}�b�`��\���������Ƃ��́A�ꗗ�̉E�����ɕ\������Ă��� [Click here to show all matches] ���N���b�N���邩�A���}�̂悤�Ɉꗗ��ʼnE�N���b�N���� [Zoom to �`] ��I�����܂��B

Zoom ���g���ƁA����̗D��x���x����t�@�C���ɍi���Ă��ׂẴ}�b�`��\���ł��܂��B
�����̂��߂̐ݒ�@�\�@�������ʂɕ\�������
�p��W�Ȃǂł́A����Ɩ��̂ق��ɃR�����g���܂܂�Ă��āA�������ʂŃR�����g�܂ŎQ�Ƃ������Ƃ�������܂��B���܂Ɂu�g�p�֎~�v�Ȃ�ăR�����g�������Ă��邱�Ƃ�����̂Œ��ӂ��K�v�ł��B���������R�����g�Ȃǂ̂��߂ɁA�������ʂ̉�ʂ� [Source] �� [Target] �ȊO�̗��lj��ŕ\���ł��܂��B

���܂茩�₷���\���ɂ͂Ȃ�܂��A�\������𑝂₷���ƂŒlj�����\���ł��܂��B�ݒ�́A[Project] > [Properties] �ƑI������ [Settings] �^�u�ōs���܂��B[Columns in list] �ɁA[Source] �� [Target] ���܂߂ĉ���\�����邩��ݒ肵�܂��B���́A�����Ă� 4 �炢�ɂ��Ă��܂��B
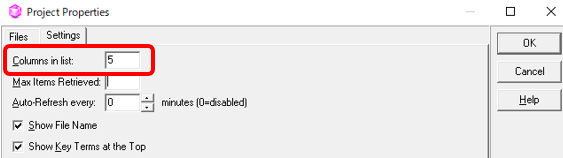
�𑝂₹���낢��\���ł��܂����A���ׂĂ�\���ł���킯�ł͂���܂���B�p��W�̍\���ɂ���ẮA�R�����g��\���ł��Ȃ����Ƃ�A�\���ł��Ă��ǂ݂ɂ������Ƃ�����܂��B�K�v�ł���A�E�[�Ɍ������̃t�@�C�������\������Ă���̂ŁA����𗊂�ɃI���W�i���̃t�@�C�����Q�Ƃ��܂��B
�����u�� (Automatic Substitution)
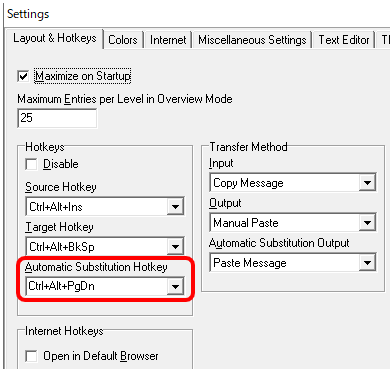
���� Xbench �ŕ֗����Ǝv���Ă���@�\�̂ЂƂɎ����u�� (Automatic Substitution) ������܂��B����́A�������ʂ� 1 �����Ȃ��Ƃ��� Xbench �̉�ʂ�\�������A�G�f�B�^�[��ŗp��ڒu�������Ă����@�\�ł��B���Ƃ��A�u���̃T�[�r�X�́A�ȉ��̌���ł����p���������܂��v�Ƃ������̌��Ɍ��ꖼ�����炸��ƕ���ł��邱�Ƃ��������肵�܂��B���������ꍇ�́A���ꖼ�̗p��W�� Xbench �ɓo�^���AAutomatic Substitution ���g���ĂЂ�����u�����Ă����܂��B��ꂪ���܂��Ă��� UI �� Automatic Substitution ���ƂĂ��֗��ł��BUI ���p��W�Ƃ��Ă����ƒ���Ă���Ƃ��́A���� Xbench �l�X�ł��B�Ώۂ̗p���I�����āAAutomatic Substitution �̃z�b�g�L�[�ł��� Ctrl+Alt+PageDown �������Έꔭ�œ��͊����ł��B

Automatic Substitution �̃z�b�g�L�[�́A���x�����Ƃ̕\�����̐ݒ�Ɠ����A[Tools] > [Settings] �� [Layout & Hotkeys] �^�u�ōs���܂��B���̃^�u�ł́AAutomatic Substitution �ȊO�ɂ��A���ꌟ���Ɩ�ꌟ���̃z�b�g�L�[�₻�̃A�N�V�����̏ڍׂ�ݒ�ł��܂��B(���݂܂���A[Transfer Method] �̏ڍׂ͂悭�킩��Ȃ��̂ł����A���͈ȉ��̂悤�Ȑݒ�ɂ��Ă��܂��B)
QA �@�\�@�\�@���s�O�̊m�F
���āA�Ō�� QA �@�\�����������Љ�܂��B�O���ɂ������Ă��܂����A���͖|��`�F�b�N�̗p�r�ɂ� Trados �̌��؋@�\����Ɏg���AXbench �͕⊮�Ƃ��Ďg���Ă��܂��BTrados �̌��؋@�\�ł͕s�ւȂƂ���� Xbench �ŕ₤�`�ł��B
QA �@�\���g���O�ɁA�܂��́A�`�F�b�N�Ώۂ̃t�@�C���� Ongoing Translation �ɐݒ肵�Ă��邱�Ƃ��m�F���܂��BQA �@�\�� Ongoing Translation �̃t�@�C���̂ݑΏۂƂ��܂��B�܂��A���̋L���̍ŏ��ɐ������܂������ATrados ��ŕ��߂��m��ς݂ɂ��Ă��邱�ƁA�����āAXbench �ōŐV�̃t�@�C���ɍX�V���Ă��邱�Ƃ��m�F���Ă��������B
QA �@�\�@�\�@��h��̃`�F�b�N
�܂��A�����悭�g���`�F�b�N�� [Basic] �� [Inconsistency in Source�n�� [Inconsistency in Target] �ł��B(���Ȃ݂ɁA�I�v�V������ [Exclude ICE Segments] ��I������ƁATrados ��Ń��b�N����Ă���Z�O�����g�����O�ł��܂��B)
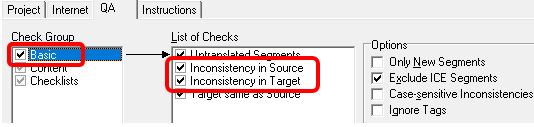
Trados �ł����l�̃`�F�b�N�͂ł��܂����A���ʂ̕\���� Xbench �̕����f�R�킩��₷���̂ŁA���� Xbench ���g���Ă��܂��B
QA �@�\�@�\�@�����̃`�F�b�N
[Content] �� [Numeric Mismatch] ���悭�g���܂��B������ATrados �łł��Ȃ��킯�ł͂���܂��AXbench �ł͌����Ɩ��㉺�ɕ\�������̂Ő����̔�r�����₷���ł��B

�����̃`�F�b�N�́ATrados �⑼�� CAT �c�[���Ɠ��l�A10���� October �̓G���[�ɂȂ�܂����A�S�p�̐����ɂ��Ή����Ă��܂���B�Ȃ̂Ō댟�o�������������܂����A�����̃~�X�͒v���I�ɂȂ�̂ŁA���S�̂��߂Ɏ��� Trados �� Xbench �̗����Ń`�F�b�N���邱�Ƃ������ł��B
����͈ȏ�ł��BXbench �ɂ́A�����ŏЉ���ȊO�ɂ��܂��܂���������̋@�\������܂��B������ Power Search �͕֗��ł����ATMX �`���ւ̕ϊ����ł��܂����A�u���E�U�[�̑���ɂ��Ȃ�܂��B�����Ȃ�ɕ֗��Ȏg��������������Ɗy�����Ǝv���܂��B
| �@�@ |
Tweet