


�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
�L��
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
posted by fanblog
2023�N07��03��
Xbench �� TBX �t�@�C��
Trados �̃�������p��x�[�X�̌����@�\�͂��Ȃ�n��Ȃ̂ŁA���� Xbench ���悭�g�p���Ă��܂��BXbench �̎g�p���@�ɂ��Ă��ȑO�ɋL���������Ă��܂����A���́A�����Ő����������@�ł͂��܂������ł��Ȃ��p��x�[�X�����邱�Ƃɍ����ɂȂ��ċC�t�����̂ŁA����͂��̑Ώ��@�Ȃǂ��Љ�����Ǝv���܂��B
�O���Ƃ��āA���� Xbench �̖����� (�o�[�W���� 2.9) ���g�p���Ă��܂��B�L���ł�������A�����������獡��̖��͋N���Ȃ��̂�������Ȃ��ł����A�ǂ��ł��傤�B������Ǝ����ł͎����Ȃ��̂ŁA���������܂����為�Ђ����������B
���āAXbench �ł��܂������ł��Ȃ��̂́A����Ɩ��̑g�ݍ��킹�� 1 �� 1 �łȂ��p��x�[�X�ł��B���̂悤�ȗp��x�[�X (.sdltb) �� Glossary Converter ���g���� TBX �t�@�C���ɕϊ����AXbench �Ō������s���ƁA�����̖�ꂪ�����Ă� 1 �̖�ꂵ���q�b�g���Ă��܂���B
���Ƃ��A�p��x�[�X�ŁA�ȉ��̂悤�� interlock �ɑ��āu�C���^�[���b�N�v�Ɓu���S���u�v�Ƃ��� 2 �̒P�ꂪ�o�^����Ă����Ƃ��܂��B

�����P���� TBX �t�@�C���ɕϊ����� Xbench �Ɏ�荞�ނƁA�u���S���u�v�����q�b�g���Ă��܂���B
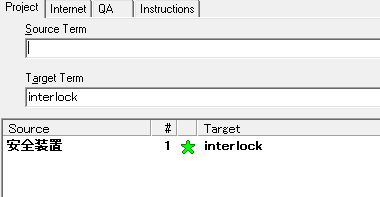
�������A���̏ꍇ�ł� TBX �t�@�C���ɂ́u�C���^�[���b�N�v�Ɓu���S���u�v�̗���������ɋL�q����Ă��܂��B�܂�AXbench �̌����@�\�� 1 �����������Ȃ��Ƃ������Ƃ̂悤�ł��B
�ŁA�ǂ��������̂��ƍl�������A����́ATBX �t�@�C���ł͂Ȃ��A�^�u���t�@�C�����g�����Ƃɂ��܂����B�菇�͂���Ȋ����ł��B
�@1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
�@2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�ł́A�菇�����Ԃɐ������Ă����܂��傤�B
Glossary Converter �ł̕ϊ����@�ɂ��ẮA�ȑO�̋L���u�y�O�ҁzXbench ��֗��Ɏg���v�Ɓu�y��ҁz�}�C�N���\�t�g�̗p��W���g�������v���Q�l�ɂ��Ă��������B
�܂��A[setting] > [General] �� �uExcel 2007 Workbook�v��I�����܂��B����ŁA�p��x�[�X (.sdltb �t�@�C��) �� Excel �t�@�C���ɕϊ������悤�ɂȂ�܂��B
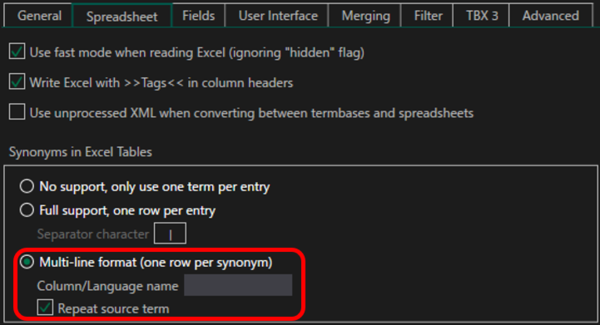
����ɁA[Spreadsheet] �^�u�� [Synonyms in Excel Tables] ��ݒ肵�܂��B[Multi-line format (one row per synonym)] �I�v�V������I�����A[Repeat source term] �`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA�����̗p�ꂪ����ꍇ�͕����̍s���쐬����A���ꂼ��̍s�Ɍ��ꂪ�L�q�����悤�ɂȂ�܂��B([Column/Language name] �͋̂܂܂ł����v�ł��B�ݒ肪�K�v�ȏꍇ�ɂ́A�ϊ��̎��s���Ƀv�����v�g���\������Ă��܂��B)
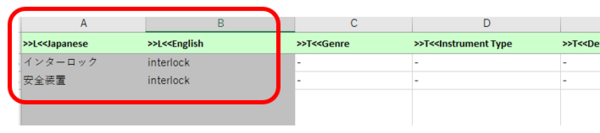
�����܂Őݒ��������AGlossary Converter �̃A�v����ɑΏۂ̗p��x�[�X �t�@�C�����h���b�O�A���h�h���b�v���܂��B����ŁA���̗p��x�[�X�Ɠ����t�H���_�[�� Excel �t�@�C�����쐬����܂��B
�쐬���ꂽ Excel �t�@�C�����J���āAXbench �������ł���`�Ƀf�[�^�𐮂��܂��B��̍���ł���p��x�[�X�̏ꍇ�́A�����Ă��A����Ɩ��ȊO�ɎQ�l���̃t�B�[���h���������ݒ肳��Ă��܂��B�����̃t�B�[���h�� Excel �t�@�C���̗�Ƃ��ďo�͂���܂����AXbench �͏�� A �������AB �����Ƃ��Č������s���̂ŁAExcel �t�@�C����ł��̂悤�ɗ����וς���K�v������܂��B�s�v�ȗ�͍폜���č\���܂��A�Q�l���� Xbench �ŕ\���������ꍇ�� C ��ȍ~�ɂ��̏����c���Ă����܂��B
��𐮂����� [���O��t���ĕۑ�] �����܂����A���̂Ƃ��� [�t�@�C���̎��] �Ƃ��āu�e�L�X�g (�^�u���) (*.txt)�v��I�����܂��B����ŁAXbench �ɓǂݍ��߂�^�u���t�@�C�����ł�������܂��B
�쐬�����^�u���t�@�C�� (.txt) �� Xbench �ɁuTab-delimited Text File�v�Ƃ��Ď�荞�ނƁA�ȉ��̂悤�ɕ����̗p�ꂪ�q�b�g���Ă��܂��B����Ŋ����ł��B
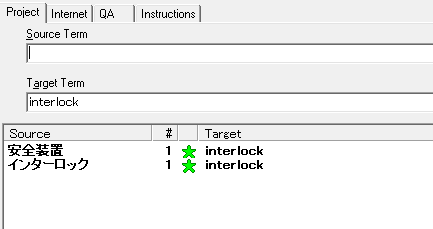
����͈ȏ�ł��B1 �� 1 �łȂ��p��x�[�X�� TBX �t�@�C�������܂������ł��Ȃ����ƂɂȂ����܂ŋC�t���Ȃ������̂��A������Ƌ��낵���Ȃ����̂Ŋm�F���Ă݂��Ƃ���A����Ȍ`���̗p��x�[�X�͎��͂قƂ�ǂ���܂���ł����B�����Ă��̏ꍇ�AExcel �t�@�C������ɂ���A���̎��_�� 1 �� 1 �ɂȂ��Ă��邩�A�Ȃ��Ă��Ȃ��ꍇ�� Excel �t�@�C����ŕҏW�����Ė������ 1 �� 1 �ɂ��Ă��܂����B�Ƃ͂����A����������h�����߁ATBX �t�@�C���� 1 �� 1 �ł��邱�Ƃ��m�F���Ă��� Xbench �Ɏ�荞�ޕK�v������܂��B
Tweet
�O���Ƃ��āA���� Xbench �̖����� (�o�[�W���� 2.9) ���g�p���Ă��܂��B�L���ł�������A�����������獡��̖��͋N���Ȃ��̂�������Ȃ��ł����A�ǂ��ł��傤�B������Ǝ����ł͎����Ȃ��̂ŁA���������܂����為�Ђ����������B
���āAXbench �ł��܂������ł��Ȃ��̂́A����Ɩ��̑g�ݍ��킹�� 1 �� 1 �łȂ��p��x�[�X�ł��B���̂悤�ȗp��x�[�X (.sdltb) �� Glossary Converter ���g���� TBX �t�@�C���ɕϊ����AXbench �Ō������s���ƁA�����̖�ꂪ�����Ă� 1 �̖�ꂵ���q�b�g���Ă��܂���B
���Ƃ��A�p��x�[�X�ŁA�ȉ��̂悤�� interlock �ɑ��āu�C���^�[���b�N�v�Ɓu���S���u�v�Ƃ��� 2 �̒P�ꂪ�o�^����Ă����Ƃ��܂��B

�����P���� TBX �t�@�C���ɕϊ����� Xbench �Ɏ�荞�ނƁA�u���S���u�v�����q�b�g���Ă��܂���B

�������A���̏ꍇ�ł� TBX �t�@�C���ɂ́u�C���^�[���b�N�v�Ɓu���S���u�v�̗���������ɋL�q����Ă��܂��B�܂�AXbench �̌����@�\�� 1 �����������Ȃ��Ƃ������Ƃ̂悤�ł��B
�ŁA�ǂ��������̂��ƍl�������A����́ATBX �t�@�C���ł͂Ȃ��A�^�u���t�@�C�����g�����Ƃɂ��܂����B�菇�͂���Ȋ����ł��B
�@1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
�@2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�ł́A�菇�����Ԃɐ������Ă����܂��傤�B
1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
Glossary Converter �ł̕ϊ����@�ɂ��ẮA�ȑO�̋L���u�y�O�ҁzXbench ��֗��Ɏg���v�Ɓu�y��ҁz�}�C�N���\�t�g�̗p��W���g�������v���Q�l�ɂ��Ă��������B
�܂��A[setting] > [General] �� �uExcel 2007 Workbook�v��I�����܂��B����ŁA�p��x�[�X (.sdltb �t�@�C��) �� Excel �t�@�C���ɕϊ������悤�ɂȂ�܂��B
����ɁA[Spreadsheet] �^�u�� [Synonyms in Excel Tables] ��ݒ肵�܂��B[Multi-line format (one row per synonym)] �I�v�V������I�����A[Repeat source term] �`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA�����̗p�ꂪ����ꍇ�͕����̍s���쐬����A���ꂼ��̍s�Ɍ��ꂪ�L�q�����悤�ɂȂ�܂��B([Column/Language name] �͋̂܂܂ł����v�ł��B�ݒ肪�K�v�ȏꍇ�ɂ́A�ϊ��̎��s���Ƀv�����v�g���\������Ă��܂��B)

�����܂Őݒ��������AGlossary Converter �̃A�v����ɑΏۂ̗p��x�[�X �t�@�C�����h���b�O�A���h�h���b�v���܂��B����ŁA���̗p��x�[�X�Ɠ����t�H���_�[�� Excel �t�@�C�����쐬����܂��B
2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�쐬���ꂽ Excel �t�@�C�����J���āAXbench �������ł���`�Ƀf�[�^�𐮂��܂��B��̍���ł���p��x�[�X�̏ꍇ�́A�����Ă��A����Ɩ��ȊO�ɎQ�l���̃t�B�[���h���������ݒ肳��Ă��܂��B�����̃t�B�[���h�� Excel �t�@�C���̗�Ƃ��ďo�͂���܂����AXbench �͏�� A �������AB �����Ƃ��Č������s���̂ŁAExcel �t�@�C����ł��̂悤�ɗ����וς���K�v������܂��B�s�v�ȗ�͍폜���č\���܂��A�Q�l���� Xbench �ŕ\���������ꍇ�� C ��ȍ~�ɂ��̏����c���Ă����܂��B

��𐮂����� [���O��t���ĕۑ�] �����܂����A���̂Ƃ��� [�t�@�C���̎��] �Ƃ��āu�e�L�X�g (�^�u���) (*.txt)�v��I�����܂��B����ŁAXbench �ɓǂݍ��߂�^�u���t�@�C�����ł�������܂��B
�쐬�����^�u���t�@�C�� (.txt) �� Xbench �ɁuTab-delimited Text File�v�Ƃ��Ď�荞�ނƁA�ȉ��̂悤�ɕ����̗p�ꂪ�q�b�g���Ă��܂��B����Ŋ����ł��B

����͈ȏ�ł��B1 �� 1 �łȂ��p��x�[�X�� TBX �t�@�C�������܂������ł��Ȃ����ƂɂȂ����܂ŋC�t���Ȃ������̂��A������Ƌ��낵���Ȃ����̂Ŋm�F���Ă݂��Ƃ���A����Ȍ`���̗p��x�[�X�͎��͂قƂ�ǂ���܂���ł����B�����Ă��̏ꍇ�AExcel �t�@�C������ɂ���A���̎��_�� 1 �� 1 �ɂȂ��Ă��邩�A�Ȃ��Ă��Ȃ��ꍇ�� Excel �t�@�C����ŕҏW�����Ė������ 1 �� 1 �ɂ��Ă��܂����B�Ƃ͂����A����������h�����߁ATBX �t�@�C���� 1 �� 1 �ł��邱�Ƃ��m�F���Ă��� Xbench �Ɏ�荞�ޕK�v������܂��B
| �@�@ |
Tweet