


Xbench �Ƃ́H
Xbench �́A���܂��܂Ȗ|��t�@�C���̌����ƃ`�F�b�N��֗��ɍs����c�[���ł��B�o�[�W���� 2.9 �������Œ���A�o�[�W���� 3.0 ����͗L�� (�N�� 99 ���[���̃T�u�X�N���v�V����) �ł��B���̃c�[���͊��ɂ��낢��ȂƂ���Ŏ��グ���Ă���̂ŁA�T�v�Ȃǂɂ��Ă͈ȉ��̃T�C�g���Q�l�ɂ��Ă��������B
�|��������I�ɍs���錍�`Xbench�ҁ` | �|���А쑺�C���^�[�i�V���i��
Xbench �̊T�v���܂Ƃ߂��Ă��܂��BXbench ���ĂȂɁH �Ƃ������́A�܂���������Q�Ƃ��Ă��������B
���������� �ŋ߂̎Q�l�T�C�g��lj����Ă����܂� 2022/05/10 ������������������������������
Xbench �̊�{�I�Ȑ����ɂ��ẮA�ȉ��̃T�C�g�Ȃǂ��Q�l�ɂ��Ă��������B
Xbench �Ƃ����|���Ƃ�����������\�t�g�E�F�A�ɂ��� | �|�V
Xbench �̊T�v���ƂĂ��킩��₷���܂Ƃ߂��Ă��܂��B
�v���|��ҕK�g�IXbench�̊��p���@�ɂ��� | �X�g���e
����������������������������������������������������������������������������������������
�t�N���O �t���[�����X�Ŗ|��&���C�e�B���O
Xbench �̍w�����@����ڂ�����������Ă��܂��B��ɁA�L���� (V3.0) �ɂ��Ă̐����ł��B
Xbench�̂ڂ̋L���ꗗ | �ڃ��O�B | ���l�Ŗ|��Ɩ����s���V�[�u���C���X�^�b�t�ɂ��Z�p���u���O
�����ݒ肩��e��@�\�܂ł��낢��Љ��Ă��܂��B�����A�������t���Â��̂Ŗ����� (V2.9) �ɊY��������e���܂܂�Ă��܂��B
������ (V2.9) �ƗL���� (V3.0)
Xbench �͈ȑO�͖����Ŏg����c�[���ł����B���̖����Ŏg���Ă����o�[�W������ 2.9 �ŁA���̌�̐V�����o�[�W�����͗L���ɂȂ��Ă��܂��B���́A�����̃o�[�W���� (V2.9) ���g�������Ă��܂��B���� V2.9 ���g�p���Ă��邱�Ƃ��A��Ԃ������錴���̂ЂƂ��Ƃ킩���Ă͂���̂ł����A���͐������P�ʂŃI���T�C�g�Ζ��ɂȂ邱�Ƃ�����A�Ȃ��Ȃ��w���ɂ͓��ݐ�܂���B���������Ă��� V2.9 �̖��_�Ƃ��ẮA�ȉ��̂悤�Ȃ��̂�����܂��B
�@�E���K�\�������{��ɑ��ċ@�\���Ȃ�
�@�EQA �� CamelCase Mismatch �� ALLUPPERCASE Mismatch ��L���ɂł��Ȃ�
�@�EMemsource �� memoQ �̃t�@�C���ɑΉ����Ă��Ȃ�
�@�EXbench �� QA ���ʂ��� Trados �̊Y���ӏ��ɒ��ڔ�Ԃ��Ƃ��ł��Ȃ�
Memsource �� memoQ �ɂ��ẮAxliff �t�@�C���Ƃ��ēǂݍ��ނ��Ƃ͂ł���̂ł����A��������������A���܂肤�܂��@�\���܂���B
�܂��AV2.9 �� Trados �̃v���O�C���ɂ�����������܂��BTrados �ł� Xbench ������ ApSIC Xbench Plugin �� Xbench 2.9 Plugin �Ƃ��� 2 �̃v���O�C��������Ă��܂����A�O�҂� V3.0 �ȏ�łȂ��Ǝg���܂���B��҂͂��̖��O�̂Ƃ��� V2.9 �Ŏg�p�ł��܂����A�@�\�͑O�҂ɔ�ׂ�ƌ����Ă���悤�Ɍ����܂��B(���͌�҂̃v���O�C�����g�p���Ă���̂ŁA����ɂ��Ă͌�Ő������܂��B)
Xbench ���g���ړI �\ ��Ɍ����Ɏg��
Xbench ���g�p����ړI�́A��L�ɋ������T�C�g�ł���������Ă���Ƃ���A��Ɍ����ƃ`�F�b�N�ł��B���́A�ǂ��炩�Ƃ����A�����Ɏg�p���邱�Ƃ̕��������ł��BTrados �̓�������p��x�[�X�̌����@�\���n��ł����AXbench ���g���A�|�̃t�@�C���A�������A�p��x�[�X����C�Ɍ����ł��܂��B
�`�F�b�N�@�\���֗��ł����A���� Trados �̌��؋@�\�����C���Ɏg���AXbench �͕⏕�I�Ɏg���Ă��܂��BTrados �� Xbench ������̌����[����o�^�ł��܂����A���[���� 2 �̃c�[���ɕ��U���Ă��܂��ƕs�ւȂ̂ŁA���̓��[���̓o�^�� Trados �����ɂ��Ă��܂��B
�����ƃ`�F�b�N�̋�̓I�ȕ��@������Ő������邱�ƂƂ��āA�܂��́A���̂��߂̏����̕��@������������Ǝv���܂��B���̏������Ȃ��Ȃ��ʓ|�ł��B
Xbench �̐ݒ���@ �\ �g���܂ł̏���
Xbench ���g���ɂ́A�܂��u�v���W�F�N�g�v���쐬���A�g�p����t�@�C���������ɓo�^����K�v������܂��B����̑O�҂ł́A���̃v���W�F�N�g�̐ݒ����������Ƃ���܂ł�������܂��B
�O�����
�EXbench 2.9 (������)
�ETrados Studio 2021 SR1
�g�p����v���O�C���ƃA�v��
�EXbench 2.9 Plugin (�v���W�F�N�g�̍쐬�ƁA�|��t�@�C���̓o�^�Ɏg�p)
�ESDLTMExport (�������̕ϊ��Ɏg�p)
�EGlossary Converter (�p��x�[�X�̕ϊ��Ɏg�p)
��L�� 3 �����O�ɃC���X�g�[�����܂��BTrados 2021 �̏ꍇ�́A[�悤����] > [RWS AppStore] ����ȒP�ɃC���X�g�[���ł��܂��BXbench 2.9 Plugin �̓v���O�C���Ȃ̂ŁATrados ���ɑg�ݍ��܂�܂��BSDLTMExport �� Glossary Converter �̓A�v���Ȃ̂ŁATrados �Ƃ͕ʂ̓Ɨ������A�v���P�[�V�����Ƃ��ăC���X�g�[������܂��B
Glossary Converter �ɂ��ẮARWS �����̃u���O�uGlossary Converter – Excel����p��x�[�X�����TMX�ւ̕ϊ��v���Q�Ƃ��Ă��������B�C���X�g�[�����@�Ȃǂ����������Ă��܂��B�܂��A���̈ȑO�̋L���u�}�C�N���\�t�g�̗p��W���g������ �y�O�ҁz���y��ҁz�v�ł��������Ă��܂��B
�����̎菇
�����̎�Ȏ菇�́A�ȉ��̂悤�ɂȂ�܂��B�v���W�F�N�g���쐬���Ă���A�|��t�@�C���A�������A�p��x�[�X�� 3 ���������܂��B
�@1. �v���W�F�N�g���쐬���āA�|��t�@�C����o�^����
�@2. ���������e�L�X�g�`���ɕϊ����ēo�^����
�@3. �p��x�[�X���e�L�X�g�`���ɕϊ����ēo�^����
�ł́A�菇�����ԂɌ��Ă����܂��傤�B
1. �v���W�F�N�g���쐬���āA�|��t�@�C����o�^����
�܂��́AXbench �̃v���W�F�N�g���쐬���܂��B���̑���� Xbench 2.9 Plugin ���g�p���܂��B���̃v���O�C���̓v���W�F�N�g�̍쐬�Ɩ|��t�@�C�� (sdlxliff �t�@�C��) �̓o�^�܂ł������ōs���Ă���܂��B
(1) Trados ��ŁA��ƑΏۂ̃v���W�F�N�g��I�����A[�A�h�C��] > [Check with Xbench 2.9] ���N���b�N���܂��B

(2) Xbench �̃v���W�F�N�g�������I�ɍ쐬����܂��B
�v���O�C���̃A�C�R�����N���b�N���邾���Ńv���W�F�N�g�������I�ɍ쐬����܂��B�����A�t�@�C���̎�ނ�I������悤�ȉ�ʂ��\�����ꂽ��A[Trados Studio File] ��I�����܂��B
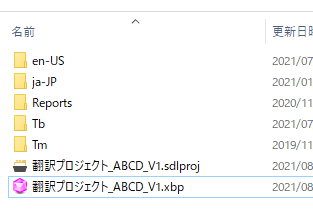
Trados �̃v���W�F�N�g �t�@�C�� (.sdlproj) �Ɠ����ꏊ�ɁA
<Trados �̃v���W�F�N�g��>.xbp �Ƃ����t�@�C�����쐬����܂��B���� xbp �t�@�C���� Xbench �̃v���W�F�N�g �t�@�C���ł��B�����ɁAXbench �̂��܂��܂Ȑݒ�����Ă����܂��B(3) �|��t�@�C�� (sdlxliff) ���o�^����Ă��邱�Ƃ��m�F���܂��B
Xbench �ŁA[Project] > [Properties] �ƑI�����܂��B�����ɁA���̃v���W�F�N�g�ɓo�^����Ă���t�@�C�����ꗗ����܂��BTrados �̃v���W�F�N�g���� sdlxliff �t�@�C�����o�^�ς݂ɂȂ��Ă���͂��ł��B

����ŁAXbench �̃v���W�F�N�g�̍쐬�ƁA�|��t�@�C���̓o�^�͊����ł��B
2. ���������e�L�X�g�`���ɕϊ����ēo�^����
���Ƀ�������o�^���܂��B�������́Asdltm �t�@�C���̂܂܂ł͓o�^�ł��Ȃ��̂ŁA�e�L�X�g�`���� tmx �t�@�C���ɕϊ����܂��B
(1) SDLTMExport ���g���ă��������e�L�X�g�`�� (tmx) �ɕϊ����܂��B
SDLTMExport ���N������ƁA���}�̂悤�ȉ�ʂ��\������܂��B������ sdltm �t�@�C�����h���b�O & �h���b�v���āA[Export] ���N���b�N���܂��B����ŁA���� sdltm �t�@�C���Ɠ����ꏊ�� tmx �t�@�C�����쐬����܂��B�����̃t�@�C�����Ƀh���b�O & �h���b�v���邱�Ƃ��ł��܂��B

(2) �ϊ������������� Xbench �̃v���W�F�N�g�ɓo�^���܂��B
Xbench �� [Project] > [Properties] �ƑI�����āA[Add] ���N���b�N���܂��B���}�̉�ʂ��\�������̂ŁA[TMX Memory] ��I������ [Next] ���N���b�N���܂��B
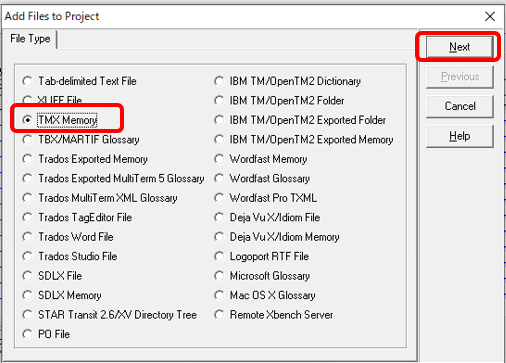
���}�̉�ʂ��\�����ꂽ��A�ϊ����� tmx �t�@�C�����w�肵�܂��B [Add File] �́A�t�@�C���� 1 ���o�^���܂��B[Add Folder] �́A�����̃t�@�C�����t�H���_�[�P�ʂňꊇ�o�^���܂��B
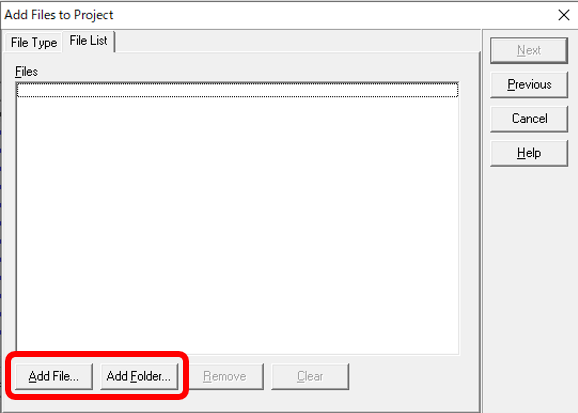
[Add Folder] ���g���ēo�^����ƁA�D��x�Ȃǂ����̃t�H���_�[�P�ʂł����ݒ�ł��Ȃ��Ȃ�܂��B�t�@�C�����ƂɗD��x�Ȃǂ�ς������Ƃ��́A[Add File] ���g���� 1 �� 1 �w�肵�Ă��������B�Q�Ƃ����������������ׂēo�^������A�����ł��B
3. �p��x�[�X���e�L�X�g�`���ɕϊ����ēo�^����
�Ō�ɗp��x�[�X��o�^���܂��B�p��x�[�X�� sdltb �t�@�C���̂܂܂ł͓o�^�ł��Ȃ��̂ŁA�܂��e�L�X�g�`���ɕϊ����܂��B�p��W�̃e�L�X�g�`���Ƃ��Ďg�p�ł�����̂͂���������A�J���}����^�u���AMultiTerm �� XML �`���ATBX �`���Ȃǂ�����܂��B
Excel �t�@�C���Ƃ��ėp��W������Ă���Ƃ��́A�J���}��肩�^�u���ɕϊ�����̂��֗��ł��B�����A���̏ꍇ�́A�u�p��v��u���{��v�Ƃ���������̑������Ȃ��Ȃ�A�P���� 1 ��ڂ�����A2 ��ڂ����ƂȂ�܂��B
Trados �̗p��x�[�X (sdltb) �́A����Ȃǂ̑�����������������̂ŁAMultiTerm �� XML �`�����ATBX �`���ɕϊ����܂��B�ǂ���ł��卷�Ȃ��ł����A���� TBX �`�����悭�g���܂��B�Ȃ��Ȃ�A���̌o����AGlossary Converter �ō쐬����� XML �t�@�C���� Xbench �ł��܂���������Ȃ����Ƃ���������ł� (���R�͂悭�킩��܂���)�B
XML �`���ɕϊ�����Ƃ��́AGlossary Converter �ł͂Ȃ��ATrados �ɕt���� Multiterm Convert ���g���܂��BMultiterm Convert �ō쐬���� XML �t�@�C���� Xbench �Ő���ɏ����ł��܂��B�����AMultiterm Convert �ł̓h���b�O & �h���b�v�ňꊇ�ϊ��Ƃ��������Ƃ͂ł��Ȃ��̂ŁAGlossary Converter �ɔ�ׂ�Ǝ�Ԃ�������܂��B
���������� �NjL 2023/07/03 ����������������������������������������������������������
���݂܂���A���́A����̖��̑g�ݍ��킹�� 1 �� 1 �ɂȂ��Ă��Ȃ��p��x�[�X�̏ꍇ�AGlossary Converter �ŕϊ����� TBX �t�@�C���� Xbench (������) �Ő���Ɍ����ł��Ȃ����ƂɁA������ł����C�t���܂����B�ڂ����́A������̋L���uXbench �� TBX �t�@�C���v���Q�Ƃ��Ă��������B�z���g������ŁA���݂܂���B
��������������������������������������������������������������������������������������
�ł́A��̓I�Ȏ菇�����Ă����܂��B�������Ɠ��l�A�ϊ����āA�o�^���܂����A�p��x�[�X�̏ꍇ�́A���̌�ŏ����ݒ肪�K�v�ł��B
(1) Glossary Converter ���g���ėp��x�[�X���e�L�X�g�`�� (tbx) �ɕϊ����܂��B
Glossary Converter ���N�������� [settings] ���N���b�N���āA[General] �^�u�� [TBX (Term Base eXchange)] ��I�����܂��B([TBX (Term Base eXchange V3)] �Ƃ����I�v�V����������܂����A���݂܂���A����͐V�����I�v�V�����̂悤�ŁA���͎g�������Ƃ�����܂���B)

��L�̐ݒ��������A�ϊ��������p��x�[�X (sdltb) �t�@�C�����h���b�O & �h���b�v���܂��B�����̃t�@�C�����܂Ƃ߂ăh���b�O & �h���b�v���Ă����v�ł��B
(2) �ϊ������p��x�[�X�� Xbench �̃v���W�F�N�g�ɓo�^���܂��B
Xbench �� [Project] > [Properties] �ƑI�����āA[Add] ���N���b�N���܂��B���}�̉�ʂ��\�������̂ŁA���x�� [TBX/MSRTIF Glossary] ��I������ [Next] ���N���b�N���܂��B

�p��x�[�X�̏ꍇ�́A[Add File] �̂ݗL���ŁA[Add Folder] �͎g�p�ł��܂���B�t�H���_�[�P�ʂł͂Ȃ��A�t�@�C���P�ʂ� 1 �� 1 �lj�����K�v������܂��B(�����A�������̏ꍇ�����l�ł����A[Add File] �̃t�@�C���I����ʂŕ����̃t�@�C������C�ɑI�����邱�Ƃ͂ł��܂��B)
(3) ����Ɩ��̐ݒ�����܂��B
�t�@�C����lj����āA��ʂ̎w���ɏ]���đ��삵�Ă����ƁASpecial Settings �ɂ��Ẵv�����v�g���\�������̂ŁA�����Ō���̐ݒ�����܂��B�ȉ��̂悤�ȉ�ʂł��B

[Source] �� [Target] �ɕ\������錾��̖��O�́A�e�p��x�[�X�Őݒ肳��Ă�����̂ł��B��}�ɕ\������Ă���uen-US�v�Ɍ��炸�A�uEnglish�v��u�p��v��������A�uSource�v��u����v��������ƁA�p��x�[�X�ɂ���Ă��܂��܂ł��BXbench �̌����ŗp��x�[�X���q�b�g���Ă��Ȃ��Ƃ��́A���̌���̐ݒ肪�Ԉ���Ă��邱�Ƃ��悭����܂��B
(4) Key Terms �Ɏw�肵�܂��B
�p��W�́A�������ʂŃ�������|��t�@�C���Ƌ�ʂ��������Ƃ������̂ŁuKey Terms�v�Ƃ��Ďw�肵�܂��B
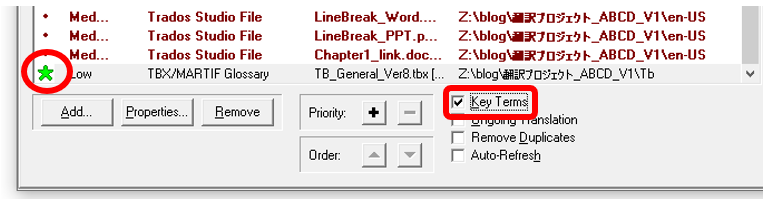
Key Terms �Ƃ��Đݒ肵�Ă����ƁA���}�[�N���t���A�������ʂł����Ƌ�ʂ����̂ŕ֗��ł��B���Ȃ݂ɁA���̉�ʂ� [Properties] �{�^�����N���b�N����ƁA��L�̌���̐ݒ��ʂ��ĕ\���ł��܂��B
����ŁA�v���W�F�N�g�̐ݒ�͂ЂƂ܂������ł��B�Ō�ɕۑ��{�^�����N���b�N���ăv���W�F�N�g��ۑ����܂��B�ׂ����ݒ�͂܂�����܂����A���������ŐG�ꂽ���Ǝv���܂��B
����͈ȏ�ł��B�����Ԃ��L���ɂȂ��Ă��܂��܂����B�V�����d�����n�܂邽�тɂ��̐ݒ������̂͑����Ȏ�Ԃł����A����ł� Xbench �͕֗��ł��B����́A�����������҂����������܂��B
| �@�@ |
�^�O�FMultiterm Convert TMX TBX �p��x�[�X �A�v�� �v���O�C�� Glossary Converter Xbench SDLTMExport Xbench 2.9 Plugin
Tweet