�g���Ă���o�[�W������ SDL Trados Studio 2017 SR1 �ł��B 2015 ���܂��g������ł͂���̂ł����A�t���O�����g��v�֗̕����Ɋ���Ă��܂����̂ŁA�Ȃ��Ȃ� 2015 �ɖ߂�C�ɂ͂Ȃꂸ�A�������P�̕��@���Ȃ����̂��ƍl���Ă��܂����B
�������ݒ��ς��邱�ƂŁA�悤�₭���ʂɑς����铮���ɂȂ����̂ŁA����͂��̕��@���Љ�����Ǝv���܂��B
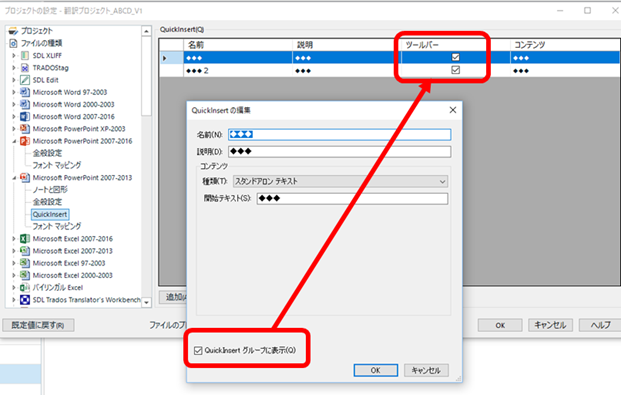
�u�����܂���v�̏C���v���ɂ���
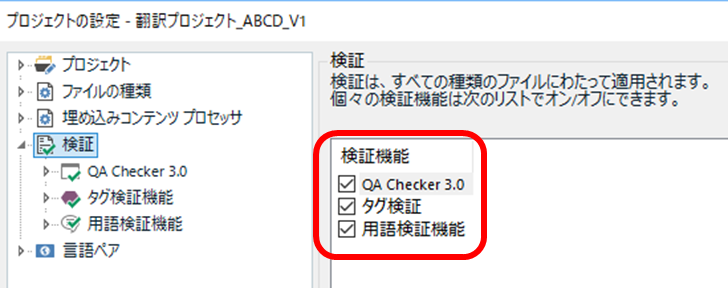
����܂Łu�����܂���v�̏C���v��L���ɂ��Ă����̂ł����A������ƈႤ�Ȃ��Ɗ�����C�������������̂ŁA�v�����Ă��̋@�\�͖����ɂ��܂����B���̍���̃v���W�F�N�g�ł́A���̕ύX�̌��ʂ��ł��傫�������悤�Ɏv���܂��B
�u�����܂���v�̏C���v�̓v���W�F�N�g�̐ݒ�Ŗ����ɂł��܂��B
[�v���W�F�N�g�̐ݒ�] -> [����y�A] -> [���ׂĂ̌���y�A] -> [��v�̏C��]
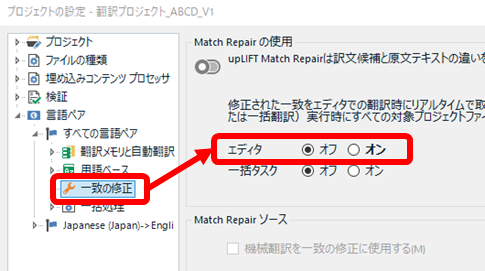
[Match Repair �̎g�p] ���\�������̂ŁA[�G�f�B�^] �̐ݒ�� [�I�t] �ɂ��܂��B
�f�t�H���g�ł́A[�G�f�B�^] �̓I���A[�ꊇ�^�X�N] �̓I�t�ł��B
�p��W�����炷 (�p��W�t�@�C���̐��ƁA�o�^����Ă���p��̐�)
�܂��A�p��W���̂��̂̃t�@�C���̐������炵�܂����B����̃v���W�F�N�g�͖|���Ђ���x���̗p��W������ 4 ���������̂ŁA�����g���Ă��鎩��̗p��W�͊O���A�x�����ꂽ�p��W�����ɂ��܂����B
����ɁA�p��W�̒��̗p������炵�܂����B����̗p��W�͎�� UI �������̂ŁA�����p�ꂪ�����܂܂�Ă��܂����B���̏d�������p����폜���܂����B
MultiTerm �ŏd�����폜������@���Ȃ����̂��Ə����T���Ă݂��̂ł����A���nj����炸
����́A�p��W�̌��f�[�^�� Excel �t�@�C���Ŏx������Ă����̂ŁAExcel �̋@�\�ō폜��1���āA�p��W����蒼���܂����B
����œ����������Ȃ����̂��ǂ����͔����ł����A�u�p��F���v�̉�ʂɗp�ꂪ�d�����ĕ\������邱�Ƃ��Ȃ��Ȃ����̂ŁA���₷���Ȃ�܂����B
���߂��m�肵���Ƃ��̌����ɂ���
��������p��W�̓ǂݍ��݈ȊO�ɂ��A���߂��m�肵���Ƃ��̓��삪�x���Ǝv�����̂ł��̐ݒ��ς��܂����B
[�t�@�C��] -> [�I�v�V����] -> [�G�f�B�^] -> [������] �ŁA[�蓮�ŕ��߂��m�肳�ꂽ�玟�̑�����s��] �� [���߂̌���L���ɂ���] ��I���������܂��B

����́A���߂��m�肵���^�C�~���O�Ŗ������s����Ƃ����@�\�ł����A���͂��ƍD���Ȃ̂ŕ��i�͗L���ɂ��Ă��܂��B�����A����͓������x���ς����Ȃ������̂Ŗ����ɂ��܂����B���ۂ̌��ʂ͔�����������܂��A�u�p�ꌟ�v�����͂��Ȃ�e��������̂ł́H�I�Ǝv���܂����B�p��W�̐ݒ�ɂ����܂����A�u�p�ꌟ�v���ɂ�����2�����ŏ��������Ȃ�悤�ȋC�����܂��B
����͈ȏ�ł��B2017 SR1 �͕֗��Ȃ̂ł����A��͂菭���������x���悤�Ɏv���܂��B�u�t���O�����g��v�v�͂���ł��g�������ł����A�u�����܂���v�̏C���v�͂����܂ł��Ďg�����ʂ͂Ȃ����Ȃ��A�Ƃ����̂����̂Ƃ���̎��̈�ۂł��B
�Ȃ��A����̃P�[�X�͓�->�p�̖|��� AutoSuggest ���֗��ɋ@�\���邱�Ƃ��O��̘b�ł��B�p->���̏ꍇ�͋�J���� 2017 SR1 �ɂ������K�v�͂Ȃ���������Ȃ��ł��B
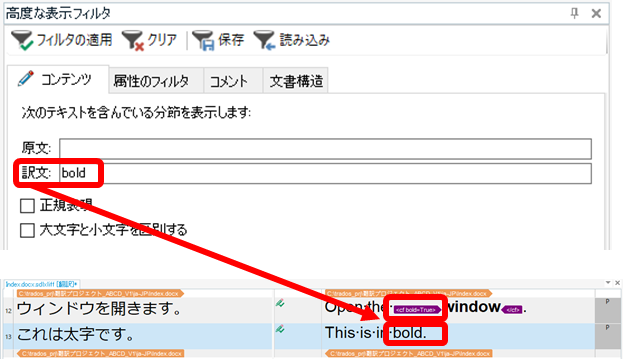
���L��1�FExcel �ɂ͏d���f�[�^���폜����@�\������̂ŁA������g���ΊȒP�ł��B(�������A���̕��@�ł́A�啶���������͋�ʂ���܂���B)
���{���� [�f�[�^] -> [�d���̍폜] �ƑI������Ɖ��}�̐ݒ��ʂ��\�������̂ŁA�u�d���v�Ɣ��f�������w�肵�܂��B

���̗�ł́A�u���l�v�����I�����������Ă��܂��B����ŁA�u���l�v�̒l������Ă��Ă��u�d���v�Ɣ��f����܂��B���ʂ́A1 �s�ڂ� 2 �s�ڂ́uChange�v�ƁuEdit�v���c��A3 �s�ڂ́uChange�v�������폜����܂��B
���Ȃ݂ɁAExcel �t�@�C������p��W�ւ̕ϊ��ɂ́ASDL MultiTerm Convert ���g���܂����B���̕ӂ�̏ڍׂ́A�܂�����A�@�����B
���L��2�F���؋@�\�� 3 ��ނ���A���ꂼ��ʁX�ɗL���������ւ����܂��B

[�v���W�F�N�g�̐ݒ�] �� [����] �ŁA�g�p��������������I�����܂��B�f�t�H���g�ł͂��ׂėL���ɂȂ��Ă��܂����A�s�v�Ȃ�I�����������܂��B
�^�O�FupLIFT �e�N�m���W�[ �����܂���v�̎����C�� �t���O�����g��v �x�� �������Ă��܂� ���� 2017 SR1 2015 Match Repair �̎g�p ���߂̌���L���ɂ���
Tweet