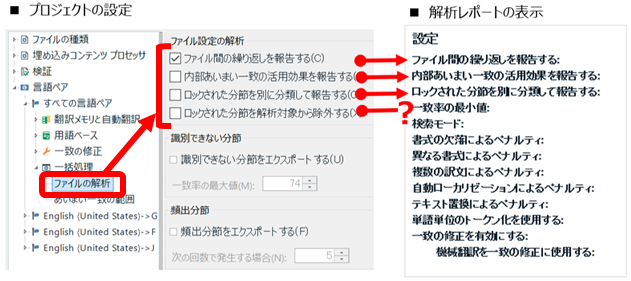
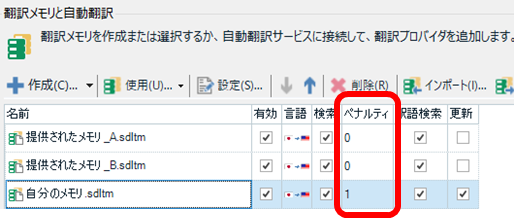
�p�b�P�[�W�́A�e��̃t�@�C�����ЂƂ܂Ƃ߂ɂł���̂Ńf�[�^�̎n���ɂ͂ƂĂ��֗��ł��B�����A���Ɋi�[����Ă���t�@�C���ɒ��ڃA�N�Z�X�ł��Ȃ��Ƃ����_�ɏ����s�ւ��������邱�Ƃ�����܂��B���Ƃ��A�|���Ƃ̓r���ł́A�ςȈꊇ�u�������Ă��܂����̂ňꕔ�̃t�@�C���������ɖ߂������Ƃ��A�v���W�F�N�g�̐ݒ��ς��Ă݂͂�����ǂ��ŏ��̐ݒ��������x�������Ƃ������悤�ɁA���̏�Ԃ̃t�@�C���ɃA�N�Z�X�������Ȃ邱�Ƃ����܂ɂ���܂��B�܂��A�|���Ƃ̊�����́A�ԋp�p�b�P�[�W�ɐ������t�@�C�����i�[�������ǂ����s���ɂȂ��ăp�b�P�[�W�̒����m�F�������Ȃ邱�Ƃ������ł��B
����́A���̂悤�ȏꍇ�̎肾�ĂƂ��āA�p�b�P�[�W�̒��̃t�@�C����ݒ���m�F������@�� 3 �Љ�����Ǝv���܂��B1 �ڂ́A�����I�ɉ𓀂�����@�A2 �ڂ́ASDL AppStore �Œ���Ă���c�[�����g�p������@�A�����čŌ�̓p�b�P�[�W��ʃv���W�F�N�g�Ƃ��ĊJ���������@�ł��B
�p�b�P�[�W�������I�ɉ𓀂���
�p�b�P�[�W �t�@�C���́A���́A�P�Ȃ� zip �t�@�C���̂悤�ł��B�ł��̂ŁA��ʓI�� zip �c�[���ʼn𓀂ł��܂��B���͎����ł͂��̎����ɂ܂������C�t���Ȃ������̂ł����A���ŋ߂ɂȂ��āA����R�[�f�B�l�[�^�[����Ɂu���ʂɉ𓀂ł��܂���v�Ƌ������A���Ȃ�A���Ȃ�A�����܂����I
�p�b�P�[�W �t�@�C���̊g���q���u.zip�v�ɕύX����A�G�N�X�v���[���[�t���̉𓀃c�[���ł��̂܂܉𓀂ł��܂��B�|���Ђ��瑗���Ă����܂܂̃I���W�i���ȏ�Ԃ̃o�C�����K�� �t�@�C����������������Ƃ����P�[�X�ł́A���̕��@���葁���ĕ֗��ł��B
�����A���{��̕������܂ރt�@�C�����͕����������Ă��܂��ꍇ������܂��B�t�@�C���̒��g���̂��̂ɉe���͂Ȃ��悤�ł����A�t�@�C�����������������Ċe�t�@�C�������ʂł��Ȃ��Ȃ�̂ŁA���O�ɓ��{����܂ރt�@�C�����������݂���ꍇ�͌�������������܂���B�t�@�C���������p�p�����݂̂ō\������Ă���ꍇ�͖��Ȃ��𓀂ł���Ǝv���܂��B
SDL AppStore �Œ���Ă��� PackageReader ���g��
SDL AppStore �� PackageReader �Ƃ����c�[���������Œ���Ă��܂��B����́A�p�b�P�[�W�̒��g���Q�Ƃ��邽�߂̃c�[���ŁA�ȒP�Ɏg�p�ł��ĂƂĂ��֗��ł��B
���̃c�[���́ATrados �̒��ɑg�ݍ��܂��v���O�C���ł͂Ȃ��ATrados �̊O���œƗ����ē����A�v���P�[�V�����ł��BAppStore �̃y�[�W�� [�_�E�����[�h] �{�^�����N���b�N����� zip �t�@�C�����_�E�����[�h����Ă��܂��B���̒��� exe �t�@�C�������s���ăC���X�g�[�����J�n���܂��B�C���X�g�[�����Ƀt�@�C���̊֘A�t���������I�ɍs����̂ŁA�C���X�g�[����̓G�N�X�v���[���[��ʼnE�N���b�N���邾���ŊȒP�Ɏg�p�ł��܂��B

�p�b�P�[�W �t�@�C�����E�N���b�N���� [�v���O��������J��] > [PackageReader] �ƑI������ƁA�ȉ��̂悤�ȉ�ʂ��\������A�p�b�P�[�W���̃o�C�����K�� �t�@�C���A�������A�p��W���ꗗ�\���ł��܂��B����ɁA�o�C�����K�� �t�@�C���ɂ��ẮA���ዾ�A�C�R�����N���b�N���ăt�@�C���̒��g���Q�Ƃ��邱�Ƃ��ł��܂��B
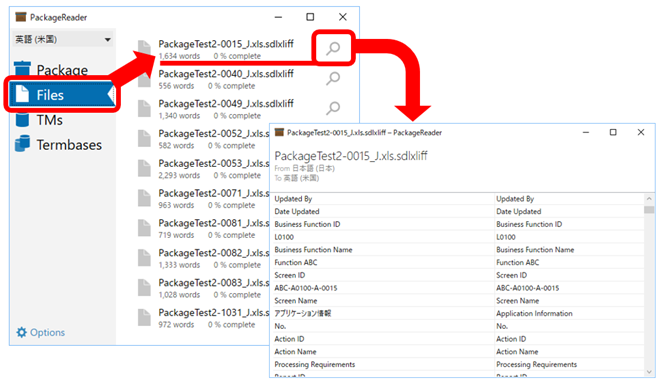
���́A�ԋp�p�b�P�[�W�̒��g���m�F�������Ƃ��ɂ��� PackageReader ���悭�g���܂��B�ԋp�p�b�P�[�W���쐬������APackageReader �Ńp�b�P�[�W���J���A�i�[�����t�@�C���ɉߕs�����Ȃ������m�F���܂��B
�����A���̃c�[���́A�p�b�P�[�W�Ɋ܂܂�Ă���t�@�C�����ꗗ�\�����Ă���邾���ŁA����̃t�@�C�������o������A�v���W�F�N�g�̐ݒ���e���m�F�����肷�邱�Ƃ͂ł��܂���B����̃t�@�C�������o�������Ƃ��́A�ŏ��ɐ������������I�ɉ𓀂�����@���̂�K�v������܂��B�܂��A�t�@�C�����ɓ��{�ꂪ�܂܂��ꍇ��A�v���W�F�N�g�̐ݒ���e���������ꍇ�́A����ɕʂ̕��@���K�v�ɂȂ�܂��B
�p�b�P�[�W��ʃv���W�F�N�g�Ƃ��ĊJ������
���āA�u����ɕʂ̕��@�v�Ƃ́u�ʃv���W�F�N�g�Ƃ��ĊJ�������v�ł��B�p�b�P�[�W�́A��������J���ăv���W�F�N�g���쐬���Ă��܂��ƁA���̌�ŒP���ɂ�����x�J���Ă��A�v���W�F�N�g�̕ۑ�����w��ł����A�ʃv���W�F�N�g�Ƃ��ĊJ���������Ƃ͂ł��܂���B�ʃv���W�F�N�g�Ƃ��ĊJ�������ɂ́A�����̃v���W�F�N�g����������u�폜�v����K�v������܂��B

��̐}�̂悤�ɁA�v���W�F�N�g���E�N���b�N���� [���X�g����폜] ��I�����܂��B[���X�g����폜] �����s���Ă��v���W�F�N�g���͍̂폜����Ȃ��̂ł����S���������B(���� UI �̕����͐M�p���đ��v�ł��B�����ǂ���A���X�g����폜����邾���ŁA���ۂ̃t�@�C���͍폜����܂���B)
�v���W�F�N�g���ꗗ�ɕ\������Ă��Ȃ����Ƃ��m�F������A�p�b�P�[�W�����߂ĊJ���܂��B���x�́A�v���W�F�N�g�̕ۑ�����w��ł���̂ŁA�����̃v���W�F�N�g�Ƃ͕ʂ̃t�H���_�[���w�肵�ăv���W�F�N�g���쐬���܂��B����ŁA�ʃv���W�F�N�g�Ƃ��ĊJ�����Ƃ��ł��܂��B
���̃v���W�F�N�g�ɖ߂������Ƃ��́A[���X�g����폜] ���ēx���s���āA�ォ�������v���W�F�N�g�����X�g����폜���܂��B���̌�ŁA���̃v���W�F�N�g�̕ۑ���ɂ���v���W�F�N�g �t�@�C�� (.sdlproj) ����v���W�F�N�g���J���܂��B����ŁA���̃v���W�F�N�g�ɖ߂邱�Ƃ��ł��܂��B
�c�O�Ȃ���A���̃v���W�F�N�g�ƌォ�������v���W�F�N�g���Ƀ��X�g�ɕ\�����邱�Ƃ͂ł��Ȃ����ł��B(���������Ă݂�����ł́A�ł��܂���ł����B) �t�@�C�����͕̂ۑ���Ɏc���Ă�����̂ŁA���X�g�ɕ\������v���W�F�N�g��K�v�ɉ����Đ�ւ��鑀�삪�K�v�ɂȂ�܂��B
����́A�ȏ�ł��B���낢�돑���܂������A�܂Ƃ߂�ƁA�܂��� zip �c�[���ʼn𓀂��Ă݂�A���߂Ȃ� [���X�g����폜] �����Ă���p�b�P�[�W���J�������A���g���ꗗ�\�������������Ȃ� PackageReader ���֗��A�Ƃ��������ł��傤���B���́A�u�p�b�P�[�W�v�Ƃ������̂��o�ꂵ�Ĉȍ~�A�����Ȃ�ɂ����܂ŗ�������̂ɑ����Ȏ��Ԃ�������܂��� (
Tweet