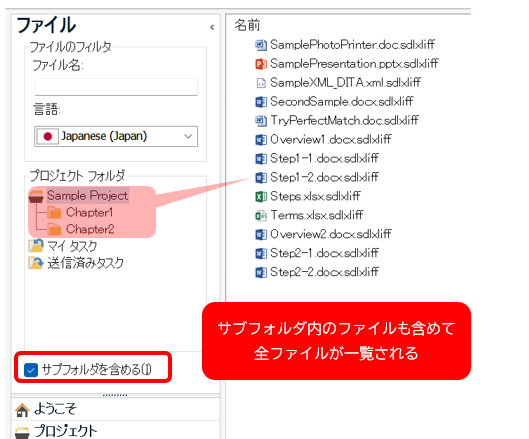
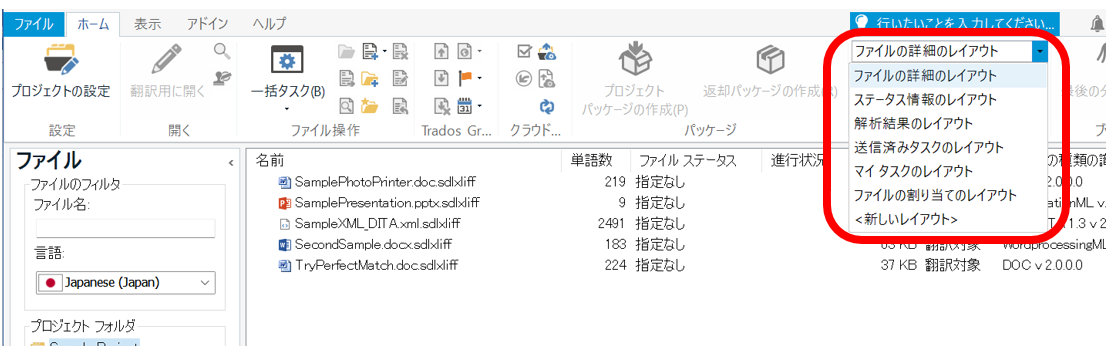
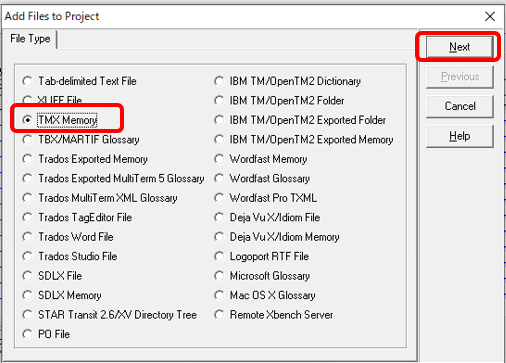
����́A�����|���Ђ���Ǝ��ۂɂǂ̂悤�Ȏd�������Ă���̂������������Љ�����Ǝv���܂��B���́A��� IT ����̓��p�Ɖp���̖|������Ă���A���������̎�ނ������đ�������܂��A����ł��|���Ђɂ���Ă��낢��Ȃ��Ƃ��傫���Ⴂ�܂��B
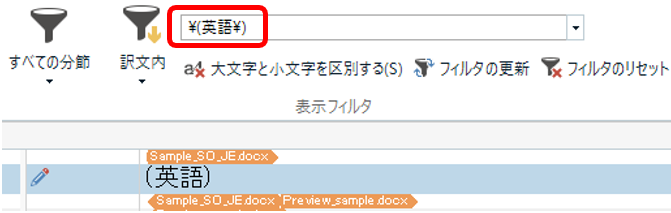
A ��: ���K�͂Ȃ�ł͂� �g�K�����h
�@�������: �p -> ��
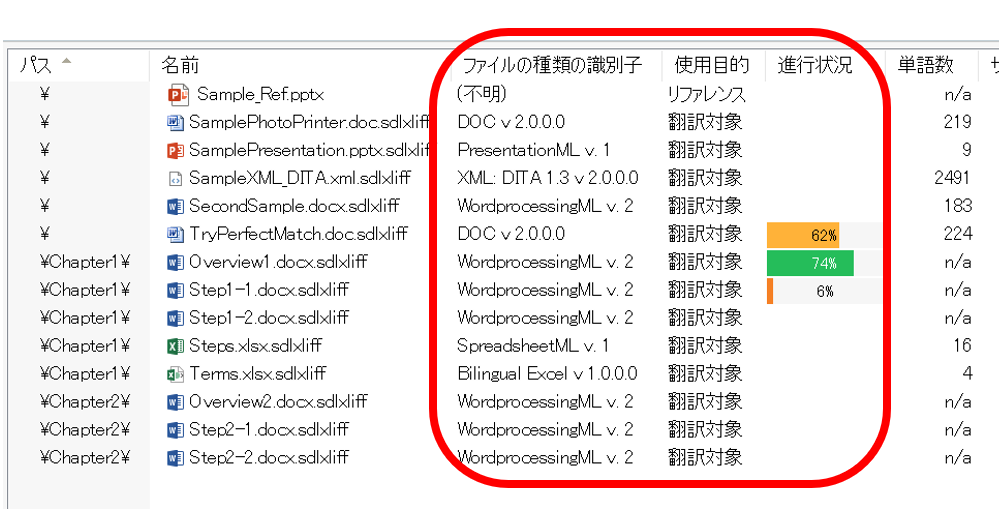
�@�t�@�C���̎��: Word �� PowerPoint ���قƂ��
�@�\�[�X �N���C�A���g: �ق� 1 ��
�܂��A���K�͂ł����Ȃ��Ȃ��撣���Ă��� A �Ђ��Љ�܂��B���� A �Ђ���قڌ��܂����\�[�X �N���C�A���g 1 �Ђ̎d�����Ă��܂� (�����炭�AA �БS�̂ł��A���̃\�[�X �N���C�A���g�̎d�����傫�Ȋ������߂Ă���Ǝv���܂�)�B�\�[�X �N���C�A���g�����܂��Ă���̂ŁA�|��t�@�C���������悤�Ȃ��̂������AWord �� PowerPoint ���قƂ�ǂŁATrados �̃v���W�F�N�g�ݒ���قږ����ł��B
����ȃ������������
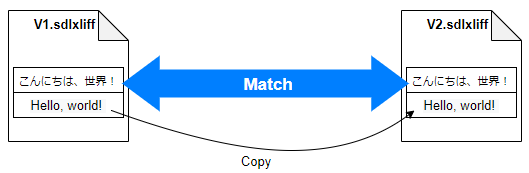
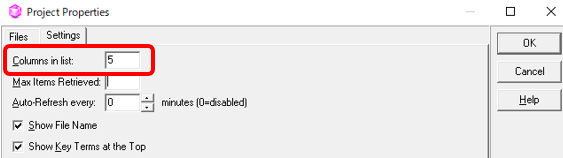
A �Ђ́A���̌��܂����\�[�X �N���C�A���g�̖��W�߂�����ȃ������� 1 �����Ă��āA�����Ă��̃v���W�F�N�g�ɂ��̃�������ݒ肵�Ă��܂��B�����A�V�K�|��̈Č��������̂ŁA����ȃ������ł����Ă��قƂ�ǃ}�b�`�͂��܂���B�}�b�`����̂́A���쌠��Ɛӎ����̒�^�����炢�ł��B
�قƂ�ǃ}�b�`���Ȃ��̂ŁA�O����������Ă��܂���B�|��t�@�C�����J���ƁA�܂�����ȏ�ԂŁA100% �}�b�`��R���e�L�X�g �}�b�`�������Ă����O�ɖ��}������Ă��邱�Ƃ͂���܂���BA �Ђ́A100% �}�b�`�Ȃǂɂ��������Ă���� (��������͂���܂���) �̂ŁA�O����������Ă��Ȃ��Ă����ɖ��͂���܂���B�Ƃ������A�V�K�|��Ȃ�A����ɖ��}������Ă�����A��������Ă��Ȃ��ق������₷�������܂��B
�K���ɂ�������
����ȃ��������炽�܂Ɍ����Ⴂ�Ȗ��q�b�g���Ă���Ƃ��A�������̔��s���x���Ƃ��A�p��x�[�X���g��Ȃ��Ƃ��A�Ȃ�ƂȂ����͂���܂����A�[���͂����Ȃ����A�P�������߂����A�ςɖʓ|�Ȏw���͂Ȃ��̂ŁA�S�̂Ƃ��Ă� �g�K���Ɂh ���������ł��B
B ��: �N���C�A���g�̎w��� Trados ���g��
�@�������: �p -> ��
�@�t�@�C���̎��: XML �t�@�C��
�@�\�[�X �N���C�A���g: �ق� 1 ��
���ɁAA �Ђ�肩�Ȃ��Ђ̋K�͂��傫�� B �Ђ��Љ�܂��B B �Ђ�������͂قڌ��܂����\�[�X �N���C�A���g 1 �Ђ̈Č������܂��AA �ЂƂ͏������ԈႢ�܂��BB �Ђ́A��ЂƂ��Ă� Memsource �����C���� CAT �c�[���Ƃ��Ďg���A����̃\�[�X �N���C�A���g�̂Ƃ��̂� Trados ���g���Ă���悤�ł��B
������Č��̃\�[�X �N���C�A���g�͂������� IT ��ƂŁA������̖|����s���Ă��܂��BTrados �����Ă���̂́A���̃\�[�X �N���C�A���g���̂��AB �Ђ�肳��ɏ㗬�� MLV (Multiple-Language Vendor) �炵���A�v���W�F�N�g������̎d�l�͊�{�I�ɂ͂��̏㗬�Ō��߂��Ă���悤�ł��B
�@
�v���W�F�N�g�p�|������������Ȃ�
B �Ђ����� Trados �̃v���W�F�N�g�ɂ́A�v���W�F�N�g�p�|�����̂݊܂܂�Ă��āA���C�� �������͊܂܂�Ă��܂���B�u�v���W�F�N�g�p�|�����v�Ƃ́A���̃}�b�`�� (�����炭�A70%) �ȏ�̕��߂����𒊏o�����������ł� (�ڂ����́A�����u���O�u�v���W�F�N�g�p�|�����ɂ����v���Q�Ƃ��Ă�������)�B ���C�� ������������ł��e�v���W�F�N�g�Ɋ܂߂�f�[�^�̗ʂ����点��̂Ŗ|���Ђɂ͕֗��ȃ������ł��B
�����A�|��҂Ƃ��ẮA���C�� �����������ė~�����Ǝv���Ă��܂��B�}�b�`���Ă��Ȃ��Ă���ꌟ���͂ł��܂����A�ŋ߂́u�t���O�����g��v�v�Ƃ����@�\�ŁA���ߑS�̂Ƃ��Ă̓}�b�`���Ȃ��Ă��A�ꕔ�̗p�ꂾ�����q�b�g���Ă��邱�Ƃ�����܂��BB �Ђ́A75% �}�b�`���痿������������Ă��܂����A75% �}�b�`�ŗ�������������قǓK�Ŋ֘A���̂��郁�����Ȃ� 69% �}�b�`�̖��Q�Ƃ̕K�v������ł��傤���A69% �}�b�`���Q�ƕs�v�ƂȂ���x�̎G���ȃ������Ȃ� 75% �}�b�`�̖��������������قǓK�Ŋ֘A���̂�����̂ł͂Ȃ��\���������̂ł͂Ǝv���܂��B
�ȑO�ɁA���C�� �������̒����肢�������Ƃ�����܂����A�ł��Ȃ��Ƃ̕Ԏ��ł����B�����炭�A�u����ȃ������v�ƏЉ�� A �Ђ̃������Ƃ͔�ɂȂ�Ȃ����傳�Ȃ̂��Ǝv���܂��B���̂����A������Ȃ̂ŁA�\�[�X �N���C�A���g���ɂ͂��̋���ȃ�����������̐��������݂��Ă���͂��ł���A�܂��Ǘ�����ς����ł��邱�Ƃ͑z�������܂��B
������v���W�F�N�g�̒��ӓ_
�����ꂪ�ւ��Č��ł́A�����̒S�����P�ꌾ�ꂾ�Ƃ��Ă� Trados �̃v���W�F�N�g�ݒ�ŏ������ӂ��K�v�ɂȂ�܂��B
����y�A
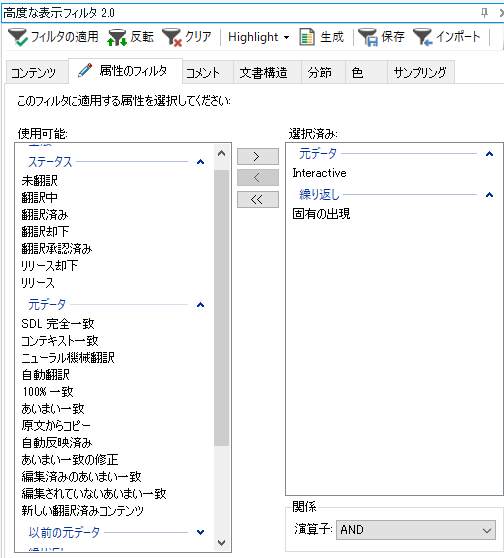
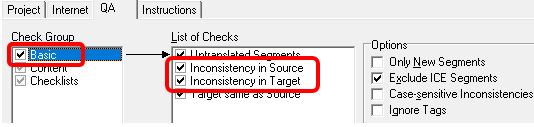
�ȑO�� Trados �̃��i�Ƃ��ďЉ�܂������A�v���W�F�N�g�̐ݒ�ɂ́u���ׂĂ̌���y�A�v�Ɓu����̌���y�A�v�̗���������܂��B
�@�@

�����Őݒ肪����Ă���ꍇ�A�D�悳���̂́u����̌���y�A�v�̕��ł��B�������̐ݒ�Ȃǂ�ς���ꍇ�́A�u���ׂĂ̌���y�A�v�ł͂Ȃ��A�uJapanese�v�ƕ\������Ă������̌���y�A�̕��ŕς���K�v������܂��B
�p��x�[�X
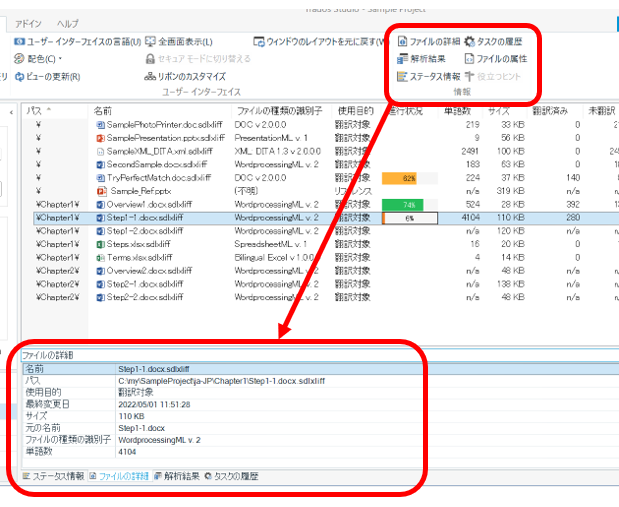
���̃\�[�X �N���C�A���g�̈Č��ł́AUI �̕����� Excel �t�@�C���� Trados �̗p��x�[�X�̗����Œ���܂��B�p��x�[�X�̒͑�ϊ������̂ł����A�ȑO�ɗp�ꂪ���܂��F������Ȃ����Ƃ�����A�m�F���Ă݂��猾��̐ݒ肪�Ԉ���Ă��܂����B
������̏ꍇ�́A���������̃\�[�X���ꂪ English ��������ASource ��������Aen-US ��������A�܂��͂܂������Ⴄ���ꂾ�����肵�܂��B���̃\�[�X �N���C�A���g�������� Excel �t�@�C��������ƁA�\������̗��ɂ�����ƕ���ł��āA���̒��� Source ��� English ����AEnglish ��͋�ɂȂ��Ă��邱�Ƃ�����܂��B���������t�@�C������p��x�[�X���쐬����Ƃ��́A�ǂ̗��p��x�[�X�́u�p��v�Ƃ���̂��ɒ��ӂ��K�v�ł��B
�S�̂Ƃ��ẮA������Ɛ����Ă���
B �Ђ��\�[�X �N���C�A���g����肾�������āA��ƃf�[�^�̓��e��菇�͂��Ȃ肫����Ɛ������Ă��܂��B�|��t�@�C���� XML �t�@�C���ł����A�����`�ɋ߂��v���r���[���ł���悤�ɐݒ肪����Ă��܂��B������ UI �̃f�[�^���ŏ��ɕK������܂����A����������ƑO�ɔ��s����܂��B���C�� ����������Ă���Ȃ��_�ȊO�́A�ƂĂ������I�ɍ�Ƃ��i�߂��ĉ��K�ł��B
C ��: �ו��܂ł̔z��������Ă���
�@�������: �� -> �p
�@�t�@�C���̎��: Word�APowerPoint�AHTML �t�@�C��
�@�\�[�X �N���C�A���g: 3�A4 ��
���ɁA��Ђ̋K�͂Ƃ��Ă� A �Ђ��傫���AB �Ђ��͏����������x�� C �Ђ��Љ�܂��BC �Ђ́A���Ȃ�ȑO���� Trados �����C���Ɏg���Ă���悤�ŁA�Z�p�I�Ȓm�����L�x�Ȋ����̉�Ђł��B��ƃf�[�^�̓��e�Ȃǂ�����ƁA�ו��܂ł��낢��Ȕz��������Ă��邱�Ƃ��킩��܂��B
�Q�Ɨp�������ƍX�V�p���������ݒ肳��Ă���
C �Ђ́ATrados �̃v���W�F�N�g�ɎQ�Ɨp�������ƍX�V�p���������ŏ�����ݒ肵�Ă��Ă���܂��B�Q�Ɨp�������͍X�V���ꂸ�A���������������͍X�V�p�������ɓo�^����Ă����܂��B�X�V���郁�����̐ݒ�ɂ��ẮA�ȑO�̋L���u���ꂽ�Ǝ����̖���ʂ��� �[ �@ �����������v���Q�Ƃ��Ă��������B
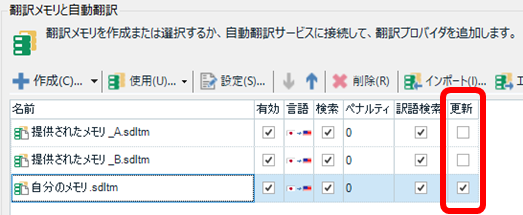
�|���Ђ�����ꂽ�������������̖ōX�V���Ă��܂��ƁA�ォ��m�F�������Ȃ����Ƃ��ɍ���̂ŁA���ꂽ�������͍X�V���Ȃ��ݒ�ɂ��Ă����ق������S�ł��B�����ATrados �̊���ݒ�ł͍X�V����Ă��܂����߁A���͂����Ă������Őݒ��ς��Ă��܂��BC �Ђ͂��̐ݒ�܂ł��Ă��Ă����̂ŁA�����Őݒ肷��K�v���Ȃ��A�ݒ��Y��čX�V���Ă��܂����Ƃ�����܂���B�ƂĂ�������܂��B
�p�����݂̂̕��߂����b�N���Ă���
�ו��܂ł̔z���͂��炵�����Ƃł����A�|��҂ɂƂ��Ă͏����V�r�A�ȓ_������܂��BC �Ђ́A���{�ꂩ��p��ɖČ��̏ꍇ�A���{����̉p�����݂̂̕��߂����b�N���āA��ƑΏۊO�Ƃ��Ă��܂��B�u��ƑΏۊO�v�Ƃ������Ƃ́A���R�Ȃ���A���� 0 �~�ł��B
���b�N�܂ł��Ă���̂� 0 �~�ł��\��Ȃ��ł����A�u�p�����̂݁v�̒��o�͐��K�\���������ŋ@�B�I�ɍs���Ă��܂��B���̂��߁A�a���p�����{��Ɠ��̗���Ȃ� (���Ƃ��AOK/NG �́uNG�v�ANumber �𗪂����s���I�h�Ȃ��́uNo�v) �̓��b�N����Ă��܂��B�܂��A�����ƒP�ʂ����̕��߂����b�N����Ă��܂��B�X�^�C���K�C�h�Ɂu�����ƒP�ʂ̊Ԃɂ͋�����v�Ə����Ă����Ă��A�����́u10cm�v�͂��̂܂܃��b�N����Ă��܂��B�����炭�A���r���A�[�����b�N���������đΉ����Ă���̂ł͂Ȃ����Ǝv���܂��B
D ��: ���낢��Ȏ�@��I�Ɏ������
�@�������: �� -> �p
�@�t�@�C���̎��: Word�APowerPoint�AHTML �t�@�C���A���̑����낢��
�@�\�[�X �N���C�A���g: �s����
���ɁAC �ЂƓ����x���A�����K�͂̑傫�� D �Ђ��Љ�܂��BD �Ђ� Trados �̎g�p���т͖L�x�Ǝv���܂����AC �Ђ��l�̍ٗʂ��傫���Е��̂悤�ŁA�R�[�f�B�l�[�^�[����ɂ���č�ƃf�[�^�̓��e��菇�����܂��܂ɕς��܂��B�܂��A�\�[�X �N���C�A���g��|��t�@�C���̎�ނ��������߂��A���낢��Ȏ�@��I�Ɏ�����Ă��銴�������܂��B
�R���e�L�X�g �}�b�`����ƑΏۊO�̂��Ƃ�����
D �Ђ́A�������t���������Ă���|���Ђ̒��ŗB��A�R���e�L�X�g �}�b�` (CM) ����ƑΏۊO�Ƃ��Ă��� �g���Ƃ�����h ��Ђł��BCM �� 100% �}�b�`�ɂ��Ă͌����u���O���u100%��v�v�Ɓu���S��v�v�̈Ⴂ�ł���������Ă��܂����A�ȒP�ɂ����ƁACM �� 100% �}�b�`���M���x�������}�b�`�ł��B���̂��߁ATrados �̐ݒ�ł́u100% �}�b�`�̓��b�N���Ȃ����ACM �̓��b�N����v���Ƃ��\�ł��BTrados �Łu���b�N����v�Ƃ������Ƃ́A��ƑΏۊO�Ƃ��� 0 �~�ɂ���Ƃ����Ӗ��ł��B
�Ƃ͂����A�|���Ђ�����ݒ�ʼn\������Ƃ����Ăނ�݂� CM ����ƑΏۊO�ɂ���킯�ł͂���܂���B�i���A�\�Z�A�[���Ȃǂ��낢��ƌ���������łǂ�����ƑΏۂƂ��邩�����肵�Ă���͂��ł��BD �Ђ̏ꍇ���A���ׂĂ̈Č��� CM ����ƑΏۊO�ƂȂ�킯�ł͂Ȃ��̂Ŗ���m�F���K�v�ł��B
��ƑΏۂ̊m�F�́A�w�����A�|��t�@�C���A�������� 3 �ŊԈႢ���Ȃ����m�F���܂��B��ԑ����ԈႢ�́A�w�����ɁuCM ����Ƃ��Ă��������v�Ƃ���̂ɁA�������� CM �� 0 �~�ɂȂ��Ă���P�[�X�ł��B
�܂��A���� 1 ����P�[�X�Ƃ��āACM ���ΏۊO�Ȃ̂ɁA�|��t�@�C���Ń��b�N����Ă��Ȃ��ꍇ������܂��B���b�N����Ă��Ȃ��ƁA���������Ƃ��Ă��܂��\��������A�g���u���ɂȂ肩�˂Ȃ��̂ŁA���͕K���|���Ђ���ɑΏۊO�̕��������b�N���Ă��Ă����悤�ɂ��肢���Ă��܂��B
�X�V�p�������͂Ȃ����Ƃ�����
CM �ɉ����āA���� 1 �� D �Ђ̓����I�ȓ_�́ATrados �̃v���W�F�N�g�ɍX�V�p��������ݒ肵�Ă��Ȃ����Ƃł��B������A�R�[�f�B�l�[�^�[����ɂ���Ă���͂���܂����A�V�K�|��̏ꍇ�Ƀ������� 1 ���ݒ肳��Ă��Ȃ�������A�Q�Ɨp���������ݒ肳��Ă���ꍇ�Ɂu�X�V�v�̃`�F�b�N���I�t�ɂ���Ă����肷�邱�Ƃ����X����܂��B
�u�X�V�v�̃`�F�b�N���I�t�ɂ���Ă���A�Q�Ɨp���������Ԉ���čX�V���Ă��܂����Ƃ͂Ȃ��̂ň��S�ł��B�X�V�p�����������炩���ߐݒ肵�Ă��� C �Ђ̏ꍇ�ƈقȂ�A�����ōX�V�p���������쐬���ăv���W�F�N�g�ɒlj�����K�v�͂���܂����A�����Ŏ��R�ɐݒ肵�������Ƃ�����̂ŁA���Ƃ��Ắu�X�V�v�̃`�F�b�N���I�t�ɂ���Ă��邾���ŏ\���ł��B
�|��t�@�C���ɂ��낢��ȉ��H������Ă���
D �Ђ́AC �ЂƓ��l�ATrados �ȂǂɊւ���m���͖L�x�Ȃ悤�ŁA�|��t�@�C���Ɏ�̍����H������Ă��邱�Ƃ�����܂��B�p�����݂̂̕��߂̓��b�N���Ă��܂����A�����ʂ̊�Ń��b�N������Ă��邱�Ƃ�����܂��B�܂��A�����ł̖|��ʼn������������������o����Ă��邱�Ƃ�����܂����B���H���ꂽ�t�@�C�����|��҂ɂƂ��č�Ƃ��₷�����̂��Ƃ����ΕK�����������ł͂Ȃ����Ƃ�����̂ł����A���낢��ƍH�v������Ă��邱�Ƃ͊m���ł��B
E ��: IT �|������C���ɂ��Ă��Ȃ����
�@�������: �p -> ��
�@�t�@�C���̎��: Word�A���̑����낢��
�@�\�[�X �N���C�A���g: �s����
��ŏЉ�� C �Ђ� D �Ђ� Trados ��ϋɓI�Ɋ��p���悤�Ƃ��镵�͋C���������܂����A�������A���̒�����ȉ�Ђ���ł͂���܂���B���ɂ��܂Ɉ˗������Ă��� E �Ђ� IT �|������C���ɂ����Ђł͂Ȃ��ATrados �N�g���Ă͂��܂����A�ϋɓI�Ɋ��p���悤�Ƃ���ӎ��͂Ȃ������Ȋ����ł��B
�p�b�P�[�W���g��Ȃ�
Trados �����܂�g��Ȃ����߂��AE �Ђ̓f�[�^�̎n���Ƀp�b�P�[�W���g�p���܂���B�v���W�F�N�g�̃t�H���_�[ (sdlproj �t�@�C���Ɗ֘A�̊e�t�H���_�[) �����̂܂ܑ����Ă��܂��B��ƌ�ɂ����炩��[�i����̂́Asdlxliff �t�@�C���ł��B
�u�p�b�P�[�W���g��Ȃ�����A�Ƃ�ł��Ȃ��s�ցv�Ƃ������Ƃ͂���܂��AE �ЈȊO�͂ǂ̉�Ђ��p�b�P�[�W���g���܂��B�p�b�P�[�W�́ATrados �̒������j���猩��Δ�r�I�V�����@�\�Ƃ����Ȃ����Ƃ��Ȃ��̂ŁA�̂��� Trados ���ق��ڂ��Ǝg���Ă�����ЂȂ�A�p�b�P�[�W���g��Ȃ��Ƃ����I�������R��������܂���B
F ��: Trados ���g��Ȃ����
�@�������: �� -> �p
�@�t�@�C���̎��: Word�APowerPoint�AExcel
�@�\�[�X �N���C�A���g: �s����
���āA�悤�₭�Ō�ł��BF �Ђ� Trados ���܂������g��Ȃ���Ђł��B�قƂ�ǂ̈Č��� Office �����ŁA�����̃t�@�C�������̂܂ܑ����Ă��܂��B���́A�����Ă����t�@�C���� Trados �Ɏ�荞�݁A�|������āA���������āA���C�A�E�g�𐮂��Ĕ[�i���܂��B���C�A�E�g�̗����͒lj��Ŏx�����܂����A����܂ł��܂蕡�G�Ȃ��̂͂Ȃ��ATrados �̖�����ɂ���قǎ�Ԃ������������Ƃ͂���܂���B
�����̍ٗʂ� Trados ���g��
�����̍ٗʂ� Trados ���g�p����̂ŁA������肪���������Ƃ��͎����őΏ�����K�v������܂��B�����A�ǂ����Ă���肪�����ł��Ȃ���A������� Trados ���g��Ȃ��Ƃ����I����������̂ŁA�ŏ����� Trados ���w�肳����肢����������܂���B
Trados �Ŗ�肪�������Ȃ����𑁂߂Ɋm�F���邽�߁A���́A��������������炷���� Trados �Ɏ�荞�݁A�������������͂��Ė��������Ă݂܂��B�����ŁA���C�A�E�g���ێ�����邩�A�t�H���g�����܂��ϊ�����邩�Ȃǂ��m�F���āA���v�����Ȃ� Trados �ō�Ƃ��܂��B
����͈ȏ�ł��B���낢��ȉ�Ђ�����Ƃ������Ƃ����`���������āA���낢��Ȃ��Ƃ������Ă�����A���̂����������Ȃ��Ă��܂��܂����B�v���W�F�N�g�p�|�����Ƃ��ACM �Ƃ��A���b�N�Ƃ��A����͂����Ƃ����������܂���ł������A�܂��@���������ڂ����L�������������Ǝv���܂��B
| �@�@ |
Tweet