Advent Calendar �u
�|��ɖ𗧂��Ă��ꂻ���ȃc�[���v�̋L���ł��B����� Trados �ł��B���݂܂���B
�O��̉p�P��`�F�b�N�̋L���ŁA�����Ɩ����ւ��ă`�F�b�N������ƌ��ʓI�Ƃ����b�����܂����B����́A���ۂ� Trados �Ō����Ɩ����ւ�����@��������܂��B
�����Ɩ����ւ���Ƃ����Ă��A���̖ړI�͂��܂��܂��Ǝv���܂��B�܂��A����ւ�����@�����͂�������܂��B���̋L���ł́A�O��̋L���Ő��������p�P��`�F�b�N��ړI�Ƃ��ē���ւ�����@���Љ�܂��B�����ŏЉ����@�́A���ׂĂ̕��߂��܂܂�Ȃ��A�^�O��������A�Ȃǂ̖�������̂ŁA�����Ɩ����ւ���ړI�ɂ���Ă͎g���܂���B
�ȉ��� 2 �̕��@��������܂��B
�@�E�e�L�X�g�`���̃����� (TMX �t�@�C��) ���g��
�@�EExcel �t�@�C���ɃG�N�X�|�[�g����
�ǂ���̕��@�ɂ���肪����
���ׂĂ̕��߂��������ɓo�^�����킯�ł͂Ȃ��e�L�X�g�`���̃����� (TMX �t�@�C��) �́A�����Ɩ̓���ւ����s���ɂ͎�y�Ɏg���ĂƂĂ��֗��ł��BTMX �t�@�C���ɂ́A�����Ɩ̋�ʂ����łȂ��u�p��v��u���{��v�Ȃnj���̎�ނ��L�^����Ă��܂��B���̂��߁A�p�������� (.sdltm �t�@�C��) ����G�N�X�|�[�g���� .tmx �t�@�C���́A���̂܂ܔ��Ε����̓��p�������ɃC���|�[�g�ł��܂��B����œ���ւ����ł��܂��B�^�O���قڈێ�����܂��B�ύX�������t���Ă��Ă��������͗�����K�ɏ����ł��܂��B
�����A1 ��肪����܂��B����́A
�Œ�v�f�������Ⴄ���߂̓������ɓo�^����Ȃ����Ƃł� (�Œ�v�f�̏ڍׂɂ��ẮA�ȑO�̋L��
�y�O�ҁz�^�C�s���O�����炻�����Q�Ƃ��Ă�������)�B�ȉ��̂悤�� 2 �̕��߂�����A������́uAC�v�ƁuDC�v���Œ�v�f�Ƃ��ĔF������Ă����Ƃ��܂��B

���̏ꍇ�A2 �̕��߂�Ă��A�������ɓo�^����镪�߂́uAC�d���P�[�u�����`�F�b�N���܂��B�v�� 1 �����ł��B�uDC�v�̕��߂́uAC�v�̕��߂ƌŒ�v�f�ȊO���܂����������Ȃ̂Ń������ɓo�^����܂���B�O��̉p�P��`�F�b�N�ł͂��������p�P�ꂱ���`�F�b�N�������̂ŁA1 �����������ɓo�^����Ȃ��d�l�͍���܂��B
�����������̌`�ɂȂ��Ă��āA������`�F�b�N�������Ƃ����Ƃ��� TMX �t�@�C�����g���Ė�肠��܂��Asdlxliff �t�@�C���̏�ԂŃ`�F�b�N���������ꍇ�̓���������Ȃ����@���K�v�ɂȂ�܂��B
Excel �ւ̃G�N�X�|�[�g�̓^�O�ƕύX��������������������Ȃ����@�� 1 ���Asdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���Č����Ɩ����ւ�����@�ł��B����Ȃ�Asdlxliff �t�@�C�����ɂ��镪�߂����ׂă`�F�b�N�ł��܂��B�����A���̕��@�ɂ���肪����܂��BExcel �t�@�C���ɃG�N�X�|�[�g����ƃ^�O���قڏ����܂��B�܂��A�ύX�������F������Ȃ��̂ŁA�ύX�������c���Ă���ꍇ�͎g���܂��� (�폜�������������ׂĂ��̂܂܃G�N�X�|�[�g����܂�)�B
����̉p�P��`�F�b�N�Ƃ����ړI�ł́A�^�O�͏����Ă��\��Ȃ��̂ŁA���� Excel �t�@�C���ɃG�N�X�|�[�g������@���g���܂��B�ύX����������Ƃ��͔Y�܂����ł����A�ύX����t���̃t�@�C�����o�b�N�A�b�v������ŁA�ύX���������ׂēK�p���܂��B����Ńt�@�C�����G�N�X�|�[�g���A���̌�Ō��̕ύX����t���̃t�@�C����߂��܂� (���Ȃ�A�ʓ|�ł�)�B
�e�L�X�g�`���̃����� (TMX �t�@�C��) ���g��
TMX �t�@�C�����g�����@����������Ă����܂��B�ȉ��̐����ł́u�p���|������Ă���Ƃ��ɁA���p�ɓ���ւ��ă`�F�b�N���s���v�Ƃ�����z�肵�Ă��܂��B
���O�ɕK�v�Ȃ���: TMX �t�@�C���p�̃t�@�C�� �^�C�v��` (
File type definition for TMX)
�菇�́A�ȉ��̂悤�ɂȂ�܂��B
�@1. ���ׂĂ̕��߂��������ɓo�^����
�@2. �o�^�����p���������� TMX �t�@�C���ɃG�N�X�|�[�g����
�@3. ���p�����������ATMX �t�@�C�����C���|�[�g���� (�����ŁA����ւ����s��)
�@4. ���p�������� TMX �t�@�C���ɃG�N�X�|�[�g����
�@5. ���p�v���W�F�N�g�� TMX �t�@�C����lj�����
�ł́A�n�߂Ă����܂��傤�B
���O�������O�����Ƃ��āATMX �t�@�C���p�̃t�@�C�� �^�C�v��`�� Trados �ɃC���X�g�[�����܂��B���̃t�@�C�� �^�C�v���C���X�g�[�����Ă����� .tmx �t�@�C�������̂܂ܖ|��t�@�C���Ƃ��ăG�f�B�^�[�ŊJ�����Ƃ��ł��܂��B
�t�@�C�� �^�C�v�́A���̃A�v���Ɠ��l��
AppStore ����_�E�����[�h���ăC���X�g�[���ł��܂��B�o�[�W���� 2021 �ȍ~��������ATrados ��
[�悤����] ��ʂ��猟���ł��܂��B�C���X�g�[������ƁA�v���W�F�N�g�̐ݒ��
[�t�@�C���̎��] ��ʂ�
[�V���ȃC���X�g�[���ς݂̃t�@�C���̎�ނ����݂��܂��B] �Ƃ������b�Z�[�W���\�������̂ŁA�������N���b�N���� TMX �t�@�C���p�̃t�@�C�� �^�C�v��L���ɂ��܂��B
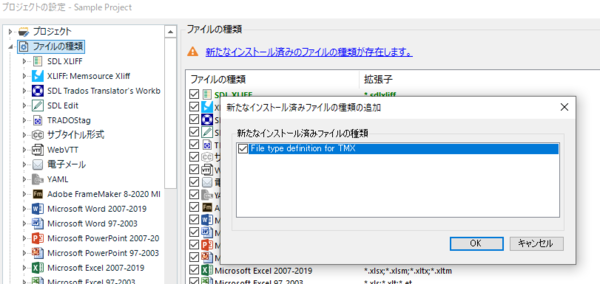
���O�����͂���Ŋ����ł��B�ł́A���ۂ̎菇�ɐi�݂܂��B
1. ���ׂĂ̕��߂��������ɓo�^�����܂��A�O�̂��߁A���݃G�f�B�^�[�ɓ��͂��Ă�������ׂă������ɓo�^���܂��B�t�@�C�� ���X�g����A�Ώۂ̖|��t�@�C�����E�N���b�N����
[�ꊇ�^�X�N] >
[���C���̖|�����̍X�V] ��I�����܂��B��ʂ̎w���ɏ]���ăE�B�U�[�h��i�߂܂��B�������ɓo�^���镪�߂̃X�e�[�^�X�Ȃǂ��K�v�ɉ����Đݒ�ł��܂��B�Ȃ��A���̑�����s���Ă��A�ŏ��ɐ��������u�Œ�v�f�ȊO���܂������������߁v�͓o�^����܂���B
2. �p���������� TMX �t�@�C���ɃG�N�X�|�[�g�������������X�V������G�N�X�|�[�g���܂��B
[�v���W�F�N�g�̐ݒ�] �̃������̐ݒ��ʂŁA�Ώۂ̃�������I������
[�G�N�X�|�[�g] ���N���b�N���܂��B����� TMX �t�@�C���ɃG�N�X�|�[�g�����Ǝv���܂����A�O�̂��߃t�@�C�������w�肷��Ƃ��Ƀt�@�C���̌`�����m�F���܂��B
3. ���p�����������ATMX �t�@�C�����C���|�[�g���������ŁA������������ւ������p��������V�����쐬���܂��B�����ɁA�G�N�X�|�[�g���� TMX �t�@�C�����C���|�[�g���܂��B�p������������G�N�X�|�[�g���� TMX �t�@�C�������̂܂ܓ��p�������ɃC���|�[�g�ł��܂��B����ŁA����ւ��͊����ł��B
4. ���p�������� TMX �t�@�C���ɃG�N�X�|�[�g�������p�������ɃC���|�[�g�ł�����A���߂� TMX �t�@�C���ɃG�N�X�|�[�g���܂��B����ŁA���p�� TMX �t�@�C���̊����ł��B
5. ���p�v���W�F�N�g�� TMX �t�@�C����lj������Ō�ɁA���p�v���W�F�N�g���쐬���āA���p�� TMX �t�@�C����|��t�@�C���Ƃ��Ēlj����܂��B����ŁA���p�� TMX �t�@�C���ɑ��� QA Checker �����s�ł��܂��B���p�v���W�F�N�g�́A�`�F�b�N�p�̂��̂� 1 ���A������ QA Checker �̐ݒ�Ȃǂ����Ă����ƕ֗��ł��B ����A���̃v���W�F�N�g�Ƀt�@�C����lj����ă`�F�b�N�ł��܂��B
TMX �t�@�C�����g���菇�͈ȏ�ł��B�����Ă݂�ƁA�ӊO�Ǝ菇�������Ȃ��Ă��܂��܂����B�p���� TMX �t�@�C�������̂܂ܓ��p�v���W�F�N�g�ɒlj��ł��Ȃ����Ǝv���Ď����Ă݂��̂ł����A����͂ł��܂���ł����B������ (.sdltm �t�@�C��) �ɃC���|�[�g���ē���ւ���Ƃ����������ǂ����Ă��K�v�Ȃ悤�ł��B���� Excel �t�@�C�����g�������菇�͏��Ȃ��ł��B
Excel �t�@�C���ɃG�N�X�|�[�g����
���ɁA������������Asdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���ē���ւ���������@��������܂��B
���O�ɕK�v�Ȃ���: Excel �ɃG�N�X�|�[�g����A�v�� (
Export to Excel)
�菇�́A�ȉ��̂悤�ɂȂ�܂��B
�@1. Excel �t�@�C���ɃG�N�X�|�[�g����
�@2. ���p�v���W�F�N�g�� Excel �t�@�C���� Bilingual Excel �Ƃ��Ēlj����� (�����ŁA����ւ����s��)
���O�������O�����Ƃ��āAsdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���Ă����A�v��
Export to Excel ���C���X�g�[�����܂��BExcel �t�@�C���ւ̃G�N�X�|�[�g���s�����@�͂��̃A�v�����g���ȊO�ɂ�����������܂����A���̃A�v���͂��낢��Ȑݒ���ł��ĕ֗��Ȃ̂Ŏ��͂�����g���Ă��܂��B
�ł́A�n�߂܂��傤�B
1. Excel �t�@�C���ɃG�N�X�|�[�g����Export to Excel �A�v�����C���X�g�[������ƁA�t�@�C�� ���X�g��
[�ꊇ�^�X�N] ��
[Export to Excel] �Ƃ����R�}���h���\�������悤�ɂȂ�܂��B���̃R�}���h���N���b�N���ăG�N�X�|�[�g���܂��B
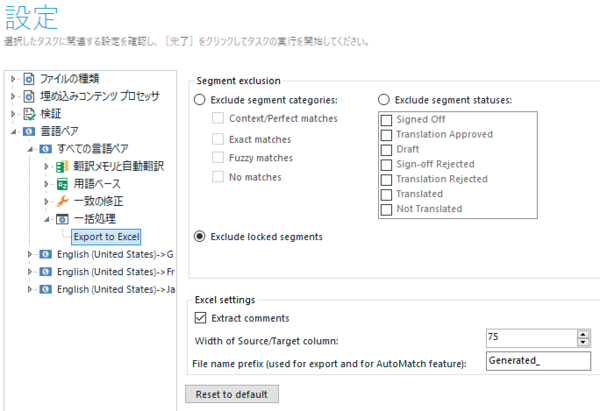
�G�N�X�|�[�g����ΏۂȂǂ�ݒ�ł��܂��B���b�N����Ă��镪�߂��`�F�b�N���Ȃ��ꍇ�́A
[Exclude locked segments] ��I�����āA���b�N����Ă��镪�߂��G�N�X�|�[�g����Ȃ��悤�ɂ��܂��B
�ȉ��̂悤�� Excel �t�@�C�����G�N�X�|�[�g����܂��B���� Excel �t�@�C���̓G�N�X�|�[�g���� sdlxliff �t�@�C���Ɠ����ꏊ�ɐ�������܂��B�c�O�Ȃ���A���̎��_�Ń^�O�͂Ȃ��Ȃ��Ă��܂��B
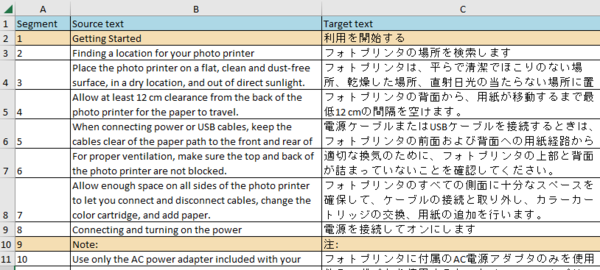 2. ���p�v���W�F�N�g�� Excel �t�@�C���� Bilingual Excel �Ƃ��Ēlj�����
2. ���p�v���W�F�N�g�� Excel �t�@�C���� Bilingual Excel �Ƃ��Ēlj�����Excel �t�@�C���ւ̃G�N�X�|�[�g���ł�����A���x�͂������p�v���W�F�N�g�ɖ|��t�@�C���Ƃ��Ēlj����܂��B���̂Ƃ��AExcel �t�@�C����ʏ�� Excel �t�@�C���ł͂Ȃ��uBilingual Excel�v�Ƃ��Ēlj����܂��B
�t�@�C����lj�����O�ɁA�t�@�C���̎�ނƂ��� Bilingual Excel ���I���悤�ɐݒ�����܂��B���p�v���W�F�N�g��
[�v���W�F�N�g�̐ݒ�] ����
[�t�@�C���̎��] ��ʂ��J���A�g���q�u.xlsx�v�ɑ���Bilingual Excel �������L���ɂȂ�悤�ɑ��� Excel �֘A�̃`�F�b�N�{�b�N�X���I�t�ɂ��܂��B
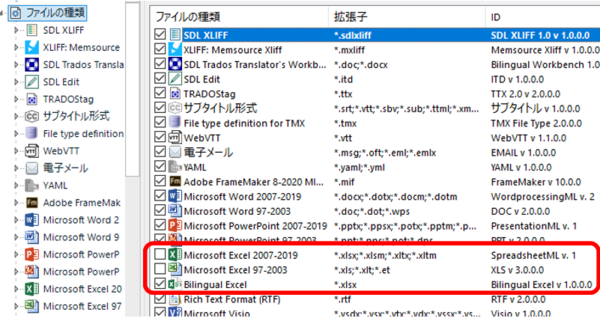
���̃��X�g�́A�ォ�珇�ԂɓK�p����Ă����̂ŁA�`�F�b�N�{�b�N�X���I�t�ɂ���̂ł͂Ȃ��ABilingual Excel ����ԏ�Ɉړ����邱�Ƃł� Bilingual Excel ���I���悤�ɐݒ�ł��܂��B
Bilingual Excel ���I���悤�ɐݒ肵����A���ɁABilingual Excel �̒��g��ݒ肵�܂��B �����̃��X�g����
[Bilingual Excel] >
[�S�ʐݒ�] ��I������ƁA�ȉ��̉�ʂ��\������܂��B
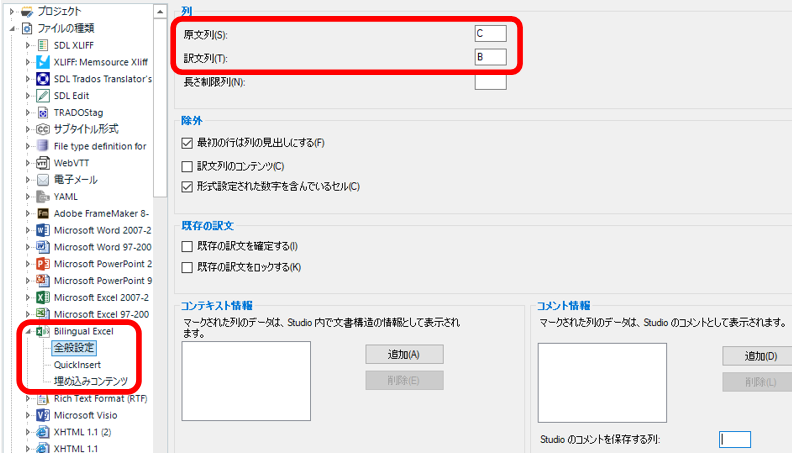
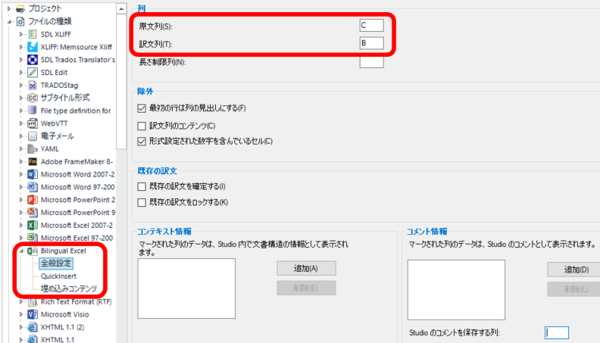 [������:]
[������:] �ɂ́A��قǃG�N�X�|�[�g���� Excel �t�@�C���œ��{�ꂪ���͂���Ă���uC�v����w�肵�A
[��:] �ɂ͉p�ꂪ���͂���Ă���uB�v����w�肵�܂��B�����ŁA�����Ɩ̓���ւ����s���܂��B
����ŏ����͊����ł��B��́A�G�N�X�|�[�g���� Excel �t�@�C�����v���W�F�N�g�ɒlj�����A���������{��A���p��̖|��t�@�C�����ł�������܂��B����� QA Checker �����s�ł��܂��B
����͈ȏ�ł��B�u�����Ɩ����ւ���v�Ƃ����^�C�g���ɂ��Ă��܂����A����ȊO�̐��������������Ȃ��Ă��܂��܂����B�����Ɩ����ւ�����@�͂��̖ړI�ɂ���Ă��낢�날��Ǝv���܂��̂ŁA�ړI�ɍ��������@��T���Ă݂Ă��������B