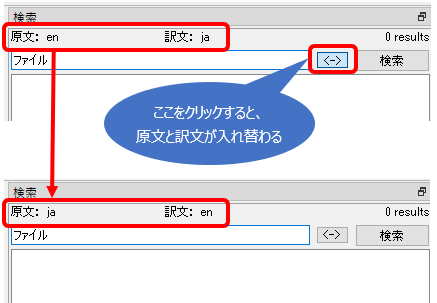
Visual Studio Code (VS Code) �̓}�C�N���\�t�g�������Œ��Ă���e�L�X�g �G�f�B�^�[�ŁA��Ƀv���O�����̃\�[�X�R�[�h��ҏW���邱�Ƃ�ړI�Ƃ������̂ł��B��ʓI�ɂ̓v���O���~���O�Ɏg�p������̂Ȃ̂ŕ��G�ȋ@�\�����ڂ���Ă͂��܂����A���́u�����Ŏg����e�L�X�g �G�f�B�^�[�v�ƍl���Ă��������ȒP�ȗp�r�Ɏg���Ă��܂��B
�T�v�A�_�E�����[�h�A�C���X�g�[���Ȃǂɂ��ẮA�ȉ��̂悤�ȃT�C�g���Q�l�ɂȂ�܂��B
�@�EVisual Studio Code – �R�[�h �G�f�B�^�[ | Microsoft Azure
�@�@�����T�C�g�ł��B��������_�E�����[�h�ł��܂��B
�@�E�yVSCode�z�C���X�g�[���^���{�ꉻ�^��{�I�Ȏg���� (senseshare.jp)
�@�E�J���̒�ԁuVSCode�v�Ƃ́H �C���X�g�[������g�����܂ł���� (1/3)|CodeZine�i�R�[�h�W���j
�@�@�܂��A�A�ڂ̑�1������܂��A����lj������悤�ł��B
�@�EVSCode | Visual Studio Code�̃_�E�����[�h�ƃC���X�g�[�� (javadrive.jp)
�C���X�g�[���Ɠ��{�ꉻ
VS Code �́A��L�ɂ������������T�C�g����_�E�����[�h�ł��܂��B�C���X�g�[���[���p�ӂ���Ă���̂ŁA������_�E�����[�h���āA��ʂ̎w���ɏ]���ĂȂ�ƂȂ��i�߂Ă����� OK �ł��B���ɓ���菇�͂���܂���B��L�� 2 �Ԗڂɋ����Ă���T�C�g�̐������킩��₷���Ǝv���܂� (���A���ɎQ�Ƃ��Ȃ��Ă����ʂɃC���X�g�[���ł��܂�)�B
�����A�P�ɃC���X�g�[�����������ł� UI ���p��ł��B���{��\���ɂ������ꍇ�͓��{��p�̊g���@�\��ʓr�C���X�g�[������K�v������܂��B����̎菇����L�̃T�C�g�ɐ�������Ă��܂����A�����炭�ǂ܂Ȃ��Ă����v�ł��B�p��̂܂g���Ă���� VS Code ���炵�������炢�u���{��ɂ��܂����v�Ƃ����v�����v�g���\������Ă��܂��B�v�����v�g���\�����ꂽ��A����ɏ]���đ��삷��Γ��{��\���ɂł��܂��B
�g���@�\
VS Code �ʼn����������Ƃ��́A�����Ă��u�g���@�\�v���C���X�g�[�����܂��BTrados �́u�A�v���v�̂悤�Ȃ��̂ł����ATrados �Ƃ͔�r�ɂȂ�Ȃ����炢��ނ���������܂��B�����A�������C���X�g�[�����ȒP�Ȃ̂ŐS�z�͖��p�ł��B

�����̃��j���[����A�l�p���p�Y���̂悤�ȃA�C�R�����N���b�N����Ɗg���@�\�̃p�l�����\������܂��B���̃p�l������A�����A�C���X�g�[���ƃA���C���X�g�[���A�ݒ�ȂǁA���낢��ȑ��삪�s���܂��B
�ł́A��������͎��� VS Code ���ǂ̂悤�Ɏg���Ă���̂����Љ�Ă����܂��B�ŏ��ɏЉ�� AutoHotkey �̃X�N���v�g�ȊO�́A���Ƀv���O���~���O�Ƃ͊W�̂Ȃ��p�r�ł��B
AutoHotkey �̃X�N���v�g������
AutoHotkey �̃X�N���v�g�͕��ʂ̃e�L�X�g �G�f�B�^�[�ŏ����܂����AVS Code ���g���������R�[�h�̐F������I�[�g�R���v���[�g�@�\�Ȃǂ��g����̂ŕ֗��ł��B
���͏�L�̊g���@�\���C���X�g�[�����Ă��܂����A�g���@�\�͂���ȊO�ɂ�����������܂��B�g���q�� �u.ahk�v�̃t�@�C���� VS Code �ŊJ���ƁuAutoHotkey �p�̊g���@�\�����܂����v�Ƃ����悤�ȃv�����v�g���\������Ă��܂��B����ɏ]���ēK���Ȋg���@�\���C���X�g�[�����܂��B
Windows �̉��z�f�X�N�g�b�v���g��
AutoHotkey �̃X�N���v�g���������������Ȃ邱�Ƃ͂悭����܂����A�X�N���v�g�������̂͂ǂ����Ă��ʓ|�Ȃ̂ł�����ɂ������ł��B���̑�Ƃ��āA���͂悭�g���X�N���v�g �t�@�C������� VS Code �ŊJ�����ςȂ��ɂ��Ă��܂��B���������J����Ԃ��Ȃ��Ȃ��y�ɍX�V�ł���̂ŁA��ɂ������܂߂ɍX�V����悤�ɂȂ�܂��B
�Ƃ͂����A�|���Ƃ����Ă���Ƃ��̓E�B���h�E����������J���Ă��ăf�X�N�g�b�v�͏�Ɉ�t�̏�Ԃł��B������ VS Code �܂ŊJ���Ɛ�ւ��̑���Ȃǂ��ʓ|�ɂȂ�܂��B�����Ŏg���̂� Windows �̉��z�f�X�N�g�b�v�@�\�ł��B����́A���z�I�Ƀf�X�N�g�b�v��ʂ�lj����āA�����̃f�X�N�g�b�v���g����悤�ɂ���@�\�ł� (�ڍׂɂ��ẮA������̃T�C�g���Q�l�ɂȂ�܂�)�B���́A�ʏ�̖|���ƂɎg���Ă���f�X�N�g�b�v�̑��ɁA���z�f�X�N�g�b�v�� 1 �lj����A������ VS Code ���J���Ă��܂��B
�f�X�N�g�b�v�̒lj��́A�V���[�g�J�b�g�L�[ Windows+Ctrl+D �ōs���܂��B�lj�������̐�ւ��́AWindows+Ctrl+�E���/����� �ł��B����ŁA�X�N���v�g�̕ύX���K�v�ɂȂ�����A�����Ɖ�ʂ��ւ��ĕҏW�ł��܂��B(�Ƃ����Ă��A�X�N���v�g�������̂͂���ς肿����Ɩʓ|�ł��B)
Markdown �t�@�C�����v���r���[����
�ŋ߁AMarkdown �̖|����˗�����邱�Ƃ����܂ɂ���܂��BMarkdown �t�@�C���� VS Code �ŊJ���ΊȒP�Ƀv���r���[�ł��܂��B�g���@�\������������܂����A��������Ȃ��Ă�����Ńv���r���[�ł��܂��B(�ڂ������@�ɂ��ẮA��IT �� VS Code��Markdown���v���r���[����ɂ́H�FVisual Studio Code TIPS ���Q�l�ɂȂ�܂��B)
�g���q���u.md�v�̃t�@�C�����J���ƁA�G�f�B�^�[�̉E��Ɉȉ��̂悤�ȃA�C�R�����\������܂��B������N���b�N����ƃv���r���[���\������܂��B

���{��̃`�F�b�N������
�`�F�b�N�@�\�� CAT �c�[���ɂ��t�����Ă��܂����A���낢��ȃc�[��������̂ł킴�킴 VS Code ���g���K�v�͂Ȃ��̂ł����A���܂ɈႤ�c�[�����g���Ǝv��ʎw�E���������肵�܂��B�������܂Ɏg���Ă���̂́u�e�L�X�g�Z������v�Ƃ����g���@�\�ł��B
����́A�e�L�X�g �t�@�C���̓��{����`�F�b�N���Ă����g���@�\�ł��BWord �t�@�C���Ȃǂ����̂܂܃`�F�b�N���邱�Ƃ͂ł��܂��AWord �t�@�C���̃e�L�X�g���R�s�[���ăe�L�X�g �t�@�C�� (.txt �t�@�C��) �ɓ\��t����`�F�b�N�ł��܂��BTrados �Ȃ�G�f�B�^�[���炷�ׂẴe�L�X�g���R�s�[���ē\��t����� OK �ł��B
�e�L�X�g �t�@�C�����J���ƁA�����Ń`�F�b�N�����s����A�G�f�B�^�[�̍����ɃG���[�����\������܂��B������N���b�N����� [���] �p�l�����J���A�����ɃG���[�̏ڍׂ��\������܂��B

�{�i�I�ȍZ���͊��҂ł��܂��A�u���邱�Ƃ��ł��܂��v�Ȃǂ̏璷�\���̃`�F�b�N�͕֗��ł��B���܂Ɏg���ƁA�т����肷��قǎw�E����邱�Ƃ�����A�����̕��͂̃N�Z���킩��܂��B
�Z���c�[���Ƃ��ẮA����ȊO�ɂ� Vale (�p��p)�Atextlint (���{��p) �Ȃǂ�����܂��B���A���݂܂���A�L���ɂ���قǗ����ł��Ă��Ȃ��̂ŁA�����ɂ��Ă͂܂����x�ɂ������Ǝv���܂��B�����u�g���Ă����v�Ƃ����������炵����A���Џ��̂����L�����肢�v���܂��B
����͈ȏ�ł��BVS Code �̂��������ȒP�Ȋ��p����Љ�܂����BVS Code �̓v���O���~���O���܂������������Ƃ̂Ȃ��l�ɂƂ��Ă͂Ƃ����ɂ�����������܂��A�P�Ȃ�u�e�L�X�g �G�f�B�^�[�v�ƍl����Γ������܂���BAutoHotkey �̃X�N���v�g���AVS Code �ŏ����ƁA�Ȃ�ƂȂ����炵���X�N���v�g�����������ȋC�����Ă��܂��B���͋C�����ł��C�������߂Ă����܂��傤�I
| �@�@ |