


�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
�L��
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
posted by fanblog
2022�N12��20��
�����Ɩ����ւ���
Advent Calendar �u�|��ɖ𗧂��Ă��ꂻ���ȃc�[���v�̋L���ł��B����� Trados �ł��B���݂܂���B
�O��̉p�P��`�F�b�N�̋L���ŁA�����Ɩ����ւ��ă`�F�b�N������ƌ��ʓI�Ƃ����b�����܂����B����́A���ۂ� Trados �Ō����Ɩ����ւ�����@��������܂��B
�����Ɩ����ւ���Ƃ����Ă��A���̖ړI�͂��܂��܂��Ǝv���܂��B�܂��A����ւ�����@�����͂�������܂��B���̋L���ł́A�O��̋L���Ő��������p�P��`�F�b�N��ړI�Ƃ��ē���ւ�����@���Љ�܂��B�����ŏЉ����@�́A���ׂĂ̕��߂��܂܂�Ȃ��A�^�O��������A�Ȃǂ̖�������̂ŁA�����Ɩ����ւ���ړI�ɂ���Ă͎g���܂���B
�ȉ��� 2 �̕��@��������܂��B
�@�E�e�L�X�g�`���̃����� (TMX �t�@�C��) ���g��
�@�EExcel �t�@�C���ɃG�N�X�|�[�g����
���ׂĂ̕��߂��������ɓo�^�����킯�ł͂Ȃ�
�e�L�X�g�`���̃����� (TMX �t�@�C��) �́A�����Ɩ̓���ւ����s���ɂ͎�y�Ɏg���ĂƂĂ��֗��ł��BTMX �t�@�C���ɂ́A�����Ɩ̋�ʂ����łȂ��u�p��v��u���{��v�Ȃnj���̎�ނ��L�^����Ă��܂��B���̂��߁A�p�������� (.sdltm �t�@�C��) ����G�N�X�|�[�g���� .tmx �t�@�C���́A���̂܂ܔ��Ε����̓��p�������ɃC���|�[�g�ł��܂��B����œ���ւ����ł��܂��B�^�O���قڈێ�����܂��B�ύX�������t���Ă��Ă��������͗�����K�ɏ����ł��܂��B
�����A1 ��肪����܂��B����́A�Œ�v�f�������Ⴄ���߂̓������ɓo�^����Ȃ����Ƃł� (�Œ�v�f�̏ڍׂɂ��ẮA�ȑO�̋L���y�O�ҁz�^�C�s���O�����炻�����Q�Ƃ��Ă�������)�B�ȉ��̂悤�� 2 �̕��߂�����A������́uAC�v�ƁuDC�v���Œ�v�f�Ƃ��ĔF������Ă����Ƃ��܂��B

���̏ꍇ�A2 �̕��߂�Ă��A�������ɓo�^����镪�߂́uAC�d���P�[�u�����`�F�b�N���܂��B�v�� 1 �����ł��B�uDC�v�̕��߂́uAC�v�̕��߂ƌŒ�v�f�ȊO���܂����������Ȃ̂Ń������ɓo�^����܂���B�O��̉p�P��`�F�b�N�ł͂��������p�P�ꂱ���`�F�b�N�������̂ŁA1 �����������ɓo�^����Ȃ��d�l�͍���܂��B
�����������̌`�ɂȂ��Ă��āA������`�F�b�N�������Ƃ����Ƃ��� TMX �t�@�C�����g���Ė�肠��܂��Asdlxliff �t�@�C���̏�ԂŃ`�F�b�N���������ꍇ�̓���������Ȃ����@���K�v�ɂȂ�܂��B
Excel �ւ̃G�N�X�|�[�g�̓^�O�ƕύX����������
����������Ȃ����@�� 1 ���Asdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���Č����Ɩ����ւ�����@�ł��B����Ȃ�Asdlxliff �t�@�C�����ɂ��镪�߂����ׂă`�F�b�N�ł��܂��B�����A���̕��@�ɂ���肪����܂��BExcel �t�@�C���ɃG�N�X�|�[�g����ƃ^�O���قڏ����܂��B�܂��A�ύX�������F������Ȃ��̂ŁA�ύX�������c���Ă���ꍇ�͎g���܂��� (�폜�������������ׂĂ��̂܂܃G�N�X�|�[�g����܂�)�B
����̉p�P��`�F�b�N�Ƃ����ړI�ł́A�^�O�͏����Ă��\��Ȃ��̂ŁA���� Excel �t�@�C���ɃG�N�X�|�[�g������@���g���܂��B�ύX����������Ƃ��͔Y�܂����ł����A�ύX����t���̃t�@�C�����o�b�N�A�b�v������ŁA�ύX���������ׂēK�p���܂��B����Ńt�@�C�����G�N�X�|�[�g���A���̌�Ō��̕ύX����t���̃t�@�C����߂��܂� (���Ȃ�A�ʓ|�ł�)�B
TMX �t�@�C�����g�����@����������Ă����܂��B�ȉ��̐����ł́u�p���|������Ă���Ƃ��ɁA���p�ɓ���ւ��ă`�F�b�N���s���v�Ƃ�����z�肵�Ă��܂��B
���O�ɕK�v�Ȃ���: TMX �t�@�C���p�̃t�@�C�� �^�C�v��` (File type definition for TMX)
�菇�́A�ȉ��̂悤�ɂȂ�܂��B
�@1. ���ׂĂ̕��߂��������ɓo�^����
�@2. �o�^�����p���������� TMX �t�@�C���ɃG�N�X�|�[�g����
�@3. ���p�����������ATMX �t�@�C�����C���|�[�g���� (�����ŁA����ւ����s��)
�@4. ���p�������� TMX �t�@�C���ɃG�N�X�|�[�g����
�@5. ���p�v���W�F�N�g�� TMX �t�@�C����lj�����
�ł́A�n�߂Ă����܂��傤�B
���O����
���O�����Ƃ��āATMX �t�@�C���p�̃t�@�C�� �^�C�v��`�� Trados �ɃC���X�g�[�����܂��B���̃t�@�C�� �^�C�v���C���X�g�[�����Ă����� .tmx �t�@�C�������̂܂ܖ|��t�@�C���Ƃ��ăG�f�B�^�[�ŊJ�����Ƃ��ł��܂��B
�t�@�C�� �^�C�v�́A���̃A�v���Ɠ��l�� AppStore ����_�E�����[�h���ăC���X�g�[���ł��܂��B�o�[�W���� 2021 �ȍ~��������ATrados �� [�悤����] ��ʂ��猟���ł��܂��B�C���X�g�[������ƁA�v���W�F�N�g�̐ݒ�� [�t�@�C���̎��] ��ʂ� [�V���ȃC���X�g�[���ς݂̃t�@�C���̎�ނ����݂��܂��B] �Ƃ������b�Z�[�W���\�������̂ŁA�������N���b�N���� TMX �t�@�C���p�̃t�@�C�� �^�C�v��L���ɂ��܂��B
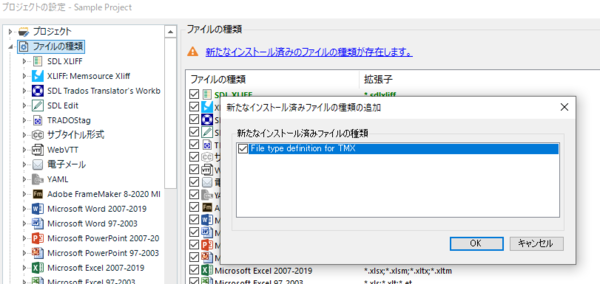
���O�����͂���Ŋ����ł��B�ł́A���ۂ̎菇�ɐi�݂܂��B
1. ���ׂĂ̕��߂��������ɓo�^����
�܂��A�O�̂��߁A���݃G�f�B�^�[�ɓ��͂��Ă�������ׂă������ɓo�^���܂��B�t�@�C�� ���X�g����A�Ώۂ̖|��t�@�C�����E�N���b�N���� [�ꊇ�^�X�N] > [���C���̖|�����̍X�V] ��I�����܂��B��ʂ̎w���ɏ]���ăE�B�U�[�h��i�߂܂��B�������ɓo�^���镪�߂̃X�e�[�^�X�Ȃǂ��K�v�ɉ����Đݒ�ł��܂��B�Ȃ��A���̑�����s���Ă��A�ŏ��ɐ��������u�Œ�v�f�ȊO���܂������������߁v�͓o�^����܂���B
2. �p���������� TMX �t�@�C���ɃG�N�X�|�[�g����
���������X�V������G�N�X�|�[�g���܂��B[�v���W�F�N�g�̐ݒ�] �̃������̐ݒ��ʂŁA�Ώۂ̃�������I������ [�G�N�X�|�[�g] ���N���b�N���܂��B����� TMX �t�@�C���ɃG�N�X�|�[�g�����Ǝv���܂����A�O�̂��߃t�@�C�������w�肷��Ƃ��Ƀt�@�C���̌`�����m�F���܂��B
3. ���p�����������ATMX �t�@�C�����C���|�[�g����
�����ŁA������������ւ������p��������V�����쐬���܂��B�����ɁA�G�N�X�|�[�g���� TMX �t�@�C�����C���|�[�g���܂��B�p������������G�N�X�|�[�g���� TMX �t�@�C�������̂܂ܓ��p�������ɃC���|�[�g�ł��܂��B����ŁA����ւ��͊����ł��B
4. ���p�������� TMX �t�@�C���ɃG�N�X�|�[�g����
���p�������ɃC���|�[�g�ł�����A���߂� TMX �t�@�C���ɃG�N�X�|�[�g���܂��B����ŁA���p�� TMX �t�@�C���̊����ł��B
5. ���p�v���W�F�N�g�� TMX �t�@�C����lj�����
�Ō�ɁA���p�v���W�F�N�g���쐬���āA���p�� TMX �t�@�C����|��t�@�C���Ƃ��Ēlj����܂��B����ŁA���p�� TMX �t�@�C���ɑ��� QA Checker �����s�ł��܂��B���p�v���W�F�N�g�́A�`�F�b�N�p�̂��̂� 1 ���A������ QA Checker �̐ݒ�Ȃǂ����Ă����ƕ֗��ł��B ����A���̃v���W�F�N�g�Ƀt�@�C����lj����ă`�F�b�N�ł��܂��B
TMX �t�@�C�����g���菇�͈ȏ�ł��B�����Ă݂�ƁA�ӊO�Ǝ菇�������Ȃ��Ă��܂��܂����B�p���� TMX �t�@�C�������̂܂ܓ��p�v���W�F�N�g�ɒlj��ł��Ȃ����Ǝv���Ď����Ă݂��̂ł����A����͂ł��܂���ł����B������ (.sdltm �t�@�C��) �ɃC���|�[�g���ē���ւ���Ƃ����������ǂ����Ă��K�v�Ȃ悤�ł��B���� Excel �t�@�C�����g�������菇�͏��Ȃ��ł��B
���ɁA������������Asdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���ē���ւ���������@��������܂��B
���O�ɕK�v�Ȃ���: Excel �ɃG�N�X�|�[�g����A�v�� (Export to Excel)
�菇�́A�ȉ��̂悤�ɂȂ�܂��B
�@1. Excel �t�@�C���ɃG�N�X�|�[�g����
�@2. ���p�v���W�F�N�g�� Excel �t�@�C���� Bilingual Excel �Ƃ��Ēlj����� (�����ŁA����ւ����s��)
���O����
���O�����Ƃ��āAsdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���Ă����A�v�� Export to Excel ���C���X�g�[�����܂��BExcel �t�@�C���ւ̃G�N�X�|�[�g���s�����@�͂��̃A�v�����g���ȊO�ɂ�����������܂����A���̃A�v���͂��낢��Ȑݒ���ł��ĕ֗��Ȃ̂Ŏ��͂�����g���Ă��܂��B
�ł́A�n�߂܂��傤�B
1. Excel �t�@�C���ɃG�N�X�|�[�g����
Export to Excel �A�v�����C���X�g�[������ƁA�t�@�C�� ���X�g�� [�ꊇ�^�X�N] �� [Export to Excel] �Ƃ����R�}���h���\�������悤�ɂȂ�܂��B���̃R�}���h���N���b�N���ăG�N�X�|�[�g���܂��B
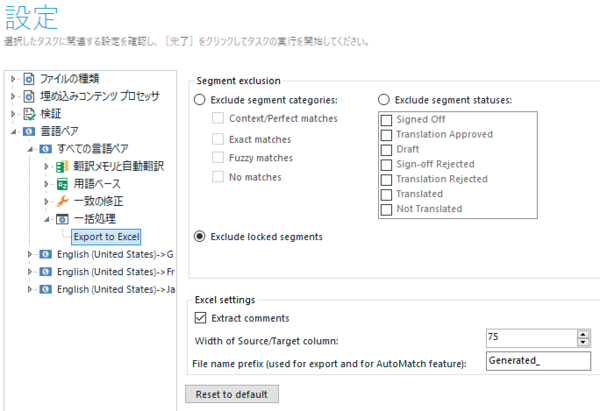
�G�N�X�|�[�g����ΏۂȂǂ�ݒ�ł��܂��B���b�N����Ă��镪�߂��`�F�b�N���Ȃ��ꍇ�́A[Exclude locked segments] ��I�����āA���b�N����Ă��镪�߂��G�N�X�|�[�g����Ȃ��悤�ɂ��܂��B
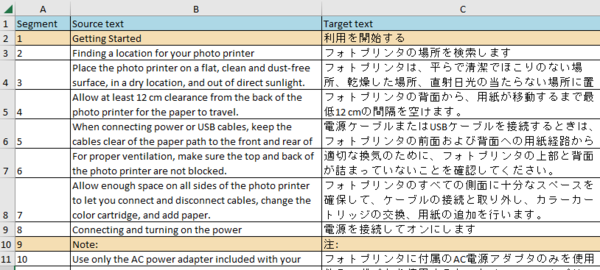
�ȉ��̂悤�� Excel �t�@�C�����G�N�X�|�[�g����܂��B���� Excel �t�@�C���̓G�N�X�|�[�g���� sdlxliff �t�@�C���Ɠ����ꏊ�ɐ�������܂��B�c�O�Ȃ���A���̎��_�Ń^�O�͂Ȃ��Ȃ��Ă��܂��B
2. ���p�v���W�F�N�g�� Excel �t�@�C���� Bilingual Excel �Ƃ��Ēlj�����
Excel �t�@�C���ւ̃G�N�X�|�[�g���ł�����A���x�͂������p�v���W�F�N�g�ɖ|��t�@�C���Ƃ��Ēlj����܂��B���̂Ƃ��AExcel �t�@�C����ʏ�� Excel �t�@�C���ł͂Ȃ��uBilingual Excel�v�Ƃ��Ēlj����܂��B
�t�@�C����lj�����O�ɁA�t�@�C���̎�ނƂ��� Bilingual Excel ���I���悤�ɐݒ�����܂��B���p�v���W�F�N�g�� [�v���W�F�N�g�̐ݒ�] ���� [�t�@�C���̎��] ��ʂ��J���A�g���q�u.xlsx�v�ɑ���Bilingual Excel �������L���ɂȂ�悤�ɑ��� Excel �֘A�̃`�F�b�N�{�b�N�X���I�t�ɂ��܂��B
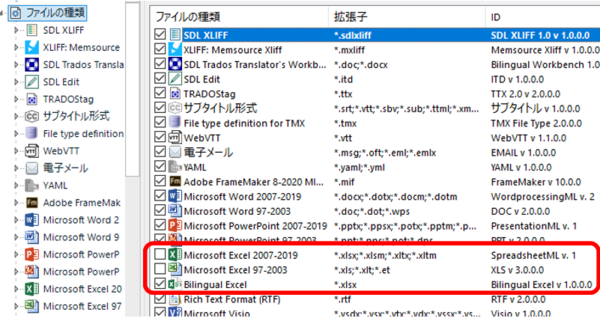
���̃��X�g�́A�ォ�珇�ԂɓK�p����Ă����̂ŁA�`�F�b�N�{�b�N�X���I�t�ɂ���̂ł͂Ȃ��ABilingual Excel ����ԏ�Ɉړ����邱�Ƃł� Bilingual Excel ���I���悤�ɐݒ�ł��܂��B
Bilingual Excel ���I���悤�ɐݒ肵����A���ɁABilingual Excel �̒��g��ݒ肵�܂��B �����̃��X�g���� [Bilingual Excel] > [�S�ʐݒ�] ��I������ƁA�ȉ��̉�ʂ��\������܂��B
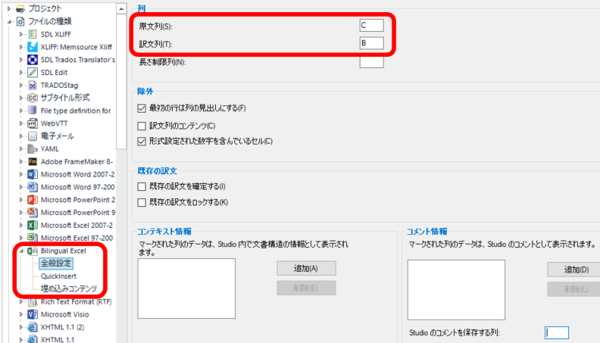
[������:] �ɂ́A��قǃG�N�X�|�[�g���� Excel �t�@�C���œ��{�ꂪ���͂���Ă���uC�v����w�肵�A[��:] �ɂ͉p�ꂪ���͂���Ă���uB�v����w�肵�܂��B�����ŁA�����Ɩ̓���ւ����s���܂��B
����ŏ����͊����ł��B��́A�G�N�X�|�[�g���� Excel �t�@�C�����v���W�F�N�g�ɒlj�����A���������{��A���p��̖|��t�@�C�����ł�������܂��B����� QA Checker �����s�ł��܂��B
����͈ȏ�ł��B�u�����Ɩ����ւ���v�Ƃ����^�C�g���ɂ��Ă��܂����A����ȊO�̐��������������Ȃ��Ă��܂��܂����B�����Ɩ����ւ�����@�͂��̖ړI�ɂ���Ă��낢�날��Ǝv���܂��̂ŁA�ړI�ɍ��������@��T���Ă݂Ă��������B
�O��̉p�P��`�F�b�N�̋L���ŁA�����Ɩ����ւ��ă`�F�b�N������ƌ��ʓI�Ƃ����b�����܂����B����́A���ۂ� Trados �Ō����Ɩ����ւ�����@��������܂��B
�����Ɩ����ւ���Ƃ����Ă��A���̖ړI�͂��܂��܂��Ǝv���܂��B�܂��A����ւ�����@�����͂�������܂��B���̋L���ł́A�O��̋L���Ő��������p�P��`�F�b�N��ړI�Ƃ��ē���ւ�����@���Љ�܂��B�����ŏЉ����@�́A���ׂĂ̕��߂��܂܂�Ȃ��A�^�O��������A�Ȃǂ̖�������̂ŁA�����Ɩ����ւ���ړI�ɂ���Ă͎g���܂���B
�ȉ��� 2 �̕��@��������܂��B
�@�E�e�L�X�g�`���̃����� (TMX �t�@�C��) ���g��
�@�EExcel �t�@�C���ɃG�N�X�|�[�g����
�ǂ���̕��@�ɂ���肪����
���ׂĂ̕��߂��������ɓo�^�����킯�ł͂Ȃ�
�e�L�X�g�`���̃����� (TMX �t�@�C��) �́A�����Ɩ̓���ւ����s���ɂ͎�y�Ɏg���ĂƂĂ��֗��ł��BTMX �t�@�C���ɂ́A�����Ɩ̋�ʂ����łȂ��u�p��v��u���{��v�Ȃnj���̎�ނ��L�^����Ă��܂��B���̂��߁A�p�������� (.sdltm �t�@�C��) ����G�N�X�|�[�g���� .tmx �t�@�C���́A���̂܂ܔ��Ε����̓��p�������ɃC���|�[�g�ł��܂��B����œ���ւ����ł��܂��B�^�O���قڈێ�����܂��B�ύX�������t���Ă��Ă��������͗�����K�ɏ����ł��܂��B
�����A1 ��肪����܂��B����́A�Œ�v�f�������Ⴄ���߂̓������ɓo�^����Ȃ����Ƃł� (�Œ�v�f�̏ڍׂɂ��ẮA�ȑO�̋L���y�O�ҁz�^�C�s���O�����炻�����Q�Ƃ��Ă�������)�B�ȉ��̂悤�� 2 �̕��߂�����A������́uAC�v�ƁuDC�v���Œ�v�f�Ƃ��ĔF������Ă����Ƃ��܂��B

���̏ꍇ�A2 �̕��߂�Ă��A�������ɓo�^����镪�߂́uAC�d���P�[�u�����`�F�b�N���܂��B�v�� 1 �����ł��B�uDC�v�̕��߂́uAC�v�̕��߂ƌŒ�v�f�ȊO���܂����������Ȃ̂Ń������ɓo�^����܂���B�O��̉p�P��`�F�b�N�ł͂��������p�P�ꂱ���`�F�b�N�������̂ŁA1 �����������ɓo�^����Ȃ��d�l�͍���܂��B
�����������̌`�ɂȂ��Ă��āA������`�F�b�N�������Ƃ����Ƃ��� TMX �t�@�C�����g���Ė�肠��܂��Asdlxliff �t�@�C���̏�ԂŃ`�F�b�N���������ꍇ�̓���������Ȃ����@���K�v�ɂȂ�܂��B
Excel �ւ̃G�N�X�|�[�g�̓^�O�ƕύX����������
����������Ȃ����@�� 1 ���Asdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���Č����Ɩ����ւ�����@�ł��B����Ȃ�Asdlxliff �t�@�C�����ɂ��镪�߂����ׂă`�F�b�N�ł��܂��B�����A���̕��@�ɂ���肪����܂��BExcel �t�@�C���ɃG�N�X�|�[�g����ƃ^�O���قڏ����܂��B�܂��A�ύX�������F������Ȃ��̂ŁA�ύX�������c���Ă���ꍇ�͎g���܂��� (�폜�������������ׂĂ��̂܂܃G�N�X�|�[�g����܂�)�B
����̉p�P��`�F�b�N�Ƃ����ړI�ł́A�^�O�͏����Ă��\��Ȃ��̂ŁA���� Excel �t�@�C���ɃG�N�X�|�[�g������@���g���܂��B�ύX����������Ƃ��͔Y�܂����ł����A�ύX����t���̃t�@�C�����o�b�N�A�b�v������ŁA�ύX���������ׂēK�p���܂��B����Ńt�@�C�����G�N�X�|�[�g���A���̌�Ō��̕ύX����t���̃t�@�C����߂��܂� (���Ȃ�A�ʓ|�ł�)�B
�e�L�X�g�`���̃����� (TMX �t�@�C��) ���g��
TMX �t�@�C�����g�����@����������Ă����܂��B�ȉ��̐����ł́u�p���|������Ă���Ƃ��ɁA���p�ɓ���ւ��ă`�F�b�N���s���v�Ƃ�����z�肵�Ă��܂��B
���O�ɕK�v�Ȃ���: TMX �t�@�C���p�̃t�@�C�� �^�C�v��` (File type definition for TMX)
�菇�́A�ȉ��̂悤�ɂȂ�܂��B
�@1. ���ׂĂ̕��߂��������ɓo�^����
�@2. �o�^�����p���������� TMX �t�@�C���ɃG�N�X�|�[�g����
�@3. ���p�����������ATMX �t�@�C�����C���|�[�g���� (�����ŁA����ւ����s��)
�@4. ���p�������� TMX �t�@�C���ɃG�N�X�|�[�g����
�@5. ���p�v���W�F�N�g�� TMX �t�@�C����lj�����
�ł́A�n�߂Ă����܂��傤�B
���O����
���O�����Ƃ��āATMX �t�@�C���p�̃t�@�C�� �^�C�v��`�� Trados �ɃC���X�g�[�����܂��B���̃t�@�C�� �^�C�v���C���X�g�[�����Ă����� .tmx �t�@�C�������̂܂ܖ|��t�@�C���Ƃ��ăG�f�B�^�[�ŊJ�����Ƃ��ł��܂��B
�t�@�C�� �^�C�v�́A���̃A�v���Ɠ��l�� AppStore ����_�E�����[�h���ăC���X�g�[���ł��܂��B�o�[�W���� 2021 �ȍ~��������ATrados �� [�悤����] ��ʂ��猟���ł��܂��B�C���X�g�[������ƁA�v���W�F�N�g�̐ݒ�� [�t�@�C���̎��] ��ʂ� [�V���ȃC���X�g�[���ς݂̃t�@�C���̎�ނ����݂��܂��B] �Ƃ������b�Z�[�W���\�������̂ŁA�������N���b�N���� TMX �t�@�C���p�̃t�@�C�� �^�C�v��L���ɂ��܂��B

���O�����͂���Ŋ����ł��B�ł́A���ۂ̎菇�ɐi�݂܂��B
1. ���ׂĂ̕��߂��������ɓo�^����
�܂��A�O�̂��߁A���݃G�f�B�^�[�ɓ��͂��Ă�������ׂă������ɓo�^���܂��B�t�@�C�� ���X�g����A�Ώۂ̖|��t�@�C�����E�N���b�N���� [�ꊇ�^�X�N] > [���C���̖|�����̍X�V] ��I�����܂��B��ʂ̎w���ɏ]���ăE�B�U�[�h��i�߂܂��B�������ɓo�^���镪�߂̃X�e�[�^�X�Ȃǂ��K�v�ɉ����Đݒ�ł��܂��B�Ȃ��A���̑�����s���Ă��A�ŏ��ɐ��������u�Œ�v�f�ȊO���܂������������߁v�͓o�^����܂���B
2. �p���������� TMX �t�@�C���ɃG�N�X�|�[�g����
���������X�V������G�N�X�|�[�g���܂��B[�v���W�F�N�g�̐ݒ�] �̃������̐ݒ��ʂŁA�Ώۂ̃�������I������ [�G�N�X�|�[�g] ���N���b�N���܂��B����� TMX �t�@�C���ɃG�N�X�|�[�g�����Ǝv���܂����A�O�̂��߃t�@�C�������w�肷��Ƃ��Ƀt�@�C���̌`�����m�F���܂��B
3. ���p�����������ATMX �t�@�C�����C���|�[�g����
�����ŁA������������ւ������p��������V�����쐬���܂��B�����ɁA�G�N�X�|�[�g���� TMX �t�@�C�����C���|�[�g���܂��B�p������������G�N�X�|�[�g���� TMX �t�@�C�������̂܂ܓ��p�������ɃC���|�[�g�ł��܂��B����ŁA����ւ��͊����ł��B
4. ���p�������� TMX �t�@�C���ɃG�N�X�|�[�g����
���p�������ɃC���|�[�g�ł�����A���߂� TMX �t�@�C���ɃG�N�X�|�[�g���܂��B����ŁA���p�� TMX �t�@�C���̊����ł��B
5. ���p�v���W�F�N�g�� TMX �t�@�C����lj�����
�Ō�ɁA���p�v���W�F�N�g���쐬���āA���p�� TMX �t�@�C����|��t�@�C���Ƃ��Ēlj����܂��B����ŁA���p�� TMX �t�@�C���ɑ��� QA Checker �����s�ł��܂��B���p�v���W�F�N�g�́A�`�F�b�N�p�̂��̂� 1 ���A������ QA Checker �̐ݒ�Ȃǂ����Ă����ƕ֗��ł��B ����A���̃v���W�F�N�g�Ƀt�@�C����lj����ă`�F�b�N�ł��܂��B
TMX �t�@�C�����g���菇�͈ȏ�ł��B�����Ă݂�ƁA�ӊO�Ǝ菇�������Ȃ��Ă��܂��܂����B�p���� TMX �t�@�C�������̂܂ܓ��p�v���W�F�N�g�ɒlj��ł��Ȃ����Ǝv���Ď����Ă݂��̂ł����A����͂ł��܂���ł����B������ (.sdltm �t�@�C��) �ɃC���|�[�g���ē���ւ���Ƃ����������ǂ����Ă��K�v�Ȃ悤�ł��B���� Excel �t�@�C�����g�������菇�͏��Ȃ��ł��B
Excel �t�@�C���ɃG�N�X�|�[�g����
���ɁA������������Asdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���ē���ւ���������@��������܂��B
���O�ɕK�v�Ȃ���: Excel �ɃG�N�X�|�[�g����A�v�� (Export to Excel)
�菇�́A�ȉ��̂悤�ɂȂ�܂��B
�@1. Excel �t�@�C���ɃG�N�X�|�[�g����
�@2. ���p�v���W�F�N�g�� Excel �t�@�C���� Bilingual Excel �Ƃ��Ēlj����� (�����ŁA����ւ����s��)
���O����
���O�����Ƃ��āAsdlxliff �t�@�C���� Excel �t�@�C���ɃG�N�X�|�[�g���Ă����A�v�� Export to Excel ���C���X�g�[�����܂��BExcel �t�@�C���ւ̃G�N�X�|�[�g���s�����@�͂��̃A�v�����g���ȊO�ɂ�����������܂����A���̃A�v���͂��낢��Ȑݒ���ł��ĕ֗��Ȃ̂Ŏ��͂�����g���Ă��܂��B
�ł́A�n�߂܂��傤�B
1. Excel �t�@�C���ɃG�N�X�|�[�g����
Export to Excel �A�v�����C���X�g�[������ƁA�t�@�C�� ���X�g�� [�ꊇ�^�X�N] �� [Export to Excel] �Ƃ����R�}���h���\�������悤�ɂȂ�܂��B���̃R�}���h���N���b�N���ăG�N�X�|�[�g���܂��B

�G�N�X�|�[�g����ΏۂȂǂ�ݒ�ł��܂��B���b�N����Ă��镪�߂��`�F�b�N���Ȃ��ꍇ�́A[Exclude locked segments] ��I�����āA���b�N����Ă��镪�߂��G�N�X�|�[�g����Ȃ��悤�ɂ��܂��B
�ȉ��̂悤�� Excel �t�@�C�����G�N�X�|�[�g����܂��B���� Excel �t�@�C���̓G�N�X�|�[�g���� sdlxliff �t�@�C���Ɠ����ꏊ�ɐ�������܂��B�c�O�Ȃ���A���̎��_�Ń^�O�͂Ȃ��Ȃ��Ă��܂��B

2. ���p�v���W�F�N�g�� Excel �t�@�C���� Bilingual Excel �Ƃ��Ēlj�����
Excel �t�@�C���ւ̃G�N�X�|�[�g���ł�����A���x�͂������p�v���W�F�N�g�ɖ|��t�@�C���Ƃ��Ēlj����܂��B���̂Ƃ��AExcel �t�@�C����ʏ�� Excel �t�@�C���ł͂Ȃ��uBilingual Excel�v�Ƃ��Ēlj����܂��B
�t�@�C����lj�����O�ɁA�t�@�C���̎�ނƂ��� Bilingual Excel ���I���悤�ɐݒ�����܂��B���p�v���W�F�N�g�� [�v���W�F�N�g�̐ݒ�] ���� [�t�@�C���̎��] ��ʂ��J���A�g���q�u.xlsx�v�ɑ���Bilingual Excel �������L���ɂȂ�悤�ɑ��� Excel �֘A�̃`�F�b�N�{�b�N�X���I�t�ɂ��܂��B

���̃��X�g�́A�ォ�珇�ԂɓK�p����Ă����̂ŁA�`�F�b�N�{�b�N�X���I�t�ɂ���̂ł͂Ȃ��ABilingual Excel ����ԏ�Ɉړ����邱�Ƃł� Bilingual Excel ���I���悤�ɐݒ�ł��܂��B
Bilingual Excel ���I���悤�ɐݒ肵����A���ɁABilingual Excel �̒��g��ݒ肵�܂��B �����̃��X�g���� [Bilingual Excel] > [�S�ʐݒ�] ��I������ƁA�ȉ��̉�ʂ��\������܂��B
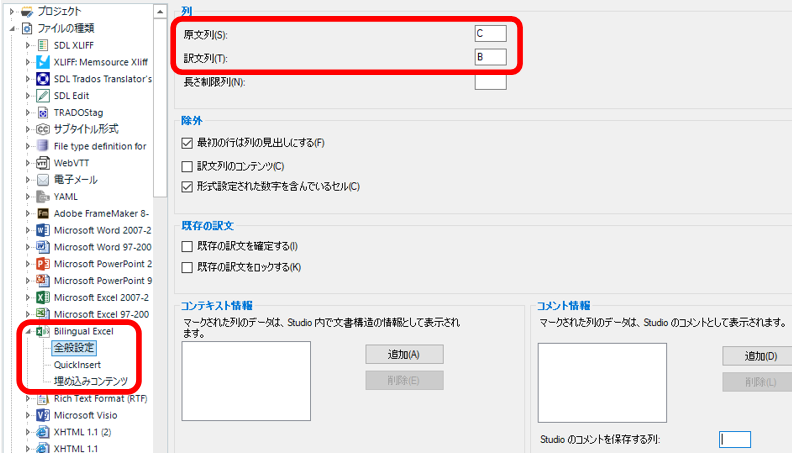
[������:] �ɂ́A��قǃG�N�X�|�[�g���� Excel �t�@�C���œ��{�ꂪ���͂���Ă���uC�v����w�肵�A[��:] �ɂ͉p�ꂪ���͂���Ă���uB�v����w�肵�܂��B�����ŁA�����Ɩ̓���ւ����s���܂��B
����ŏ����͊����ł��B��́A�G�N�X�|�[�g���� Excel �t�@�C�����v���W�F�N�g�ɒlj�����A���������{��A���p��̖|��t�@�C�����ł�������܂��B����� QA Checker �����s�ł��܂��B
����͈ȏ�ł��B�u�����Ɩ����ւ���v�Ƃ����^�C�g���ɂ��Ă��܂����A����ȊO�̐��������������Ȃ��Ă��܂��܂����B�����Ɩ����ւ�����@�͂��̖ړI�ɂ���Ă��낢�날��Ǝv���܂��̂ŁA�ړI�ɍ��������@��T���Ă݂Ă��������B
| �@�@ |
�^�O�F�����Ɩ̓���ւ� Export to Excel Bilingual Excel File type definition for TMX TMX �t�@�C���̎�� �t�@�C�� �^�C�v
Tweet
2022�N12��18��
CamelCase �� ALLUPPER CASE �����삷��
Advent Calendar �u�|��ɖ𗧂��Ă��ꂻ���ȃc�[���v�̋L���ł��B����́ATrados �Ɛ��K�\���ł��B
���͂����� Xbench �̖����� (V2.9) ���g���Ă��܂����A�����łň�Ԏc�O�Ȃ̂� QA �`�F�b�N�� CamelCase Mismatch �� ALLUPPER CASE Mismatch ��L���ɂł��Ȃ����Ƃł��B�L���ł� V3 �ȍ~�ł͗L���ɂł���炵���ł����AV2.9 �ł� DISABLED �ƕ\������邾���ŁA�����L���ɂ���I�v�V����������܂���B���̃`�F�b�N�́A�啶���̒P�� (WAF �� HTTP �Ȃ�) �ƃL�������P�[�X�̒P�� (GetStatus �� SetTranslationMemory �Ȃ�) �������Ɩň�v���Ă��邩���m�F���Ă������̂��Ǝv���܂��B�p�P��́u�K����������R�s�[����v�Ƃ������[����O�ꂵ�Ă���ΊԈႤ�͂��͂Ȃ��̂ł����A����ł������Ă��܂����肷�邱�Ƃ�����̂ŁA���������`�F�b�N�͂ǂ����Ă��K�v�ɂȂ�܂��B
�����ŁA����͂��̃`�F�b�N�� Trados �� QA Checker ���g���čČ����邱�Ƃɒ��킵�܂��B���p�|��Ɖp���|��̗������ɂ��čČ�������@���l���Ă݂܂����B�ŁA�l���Ă݂��̂ō���͂��̕��@���Љ�܂����A���͂��܂肤�܂��@�\���Ȃ��P�[�X������܂��B�ǂ����Ă��댟�o�������Ă��܂��܂��B�����A���P�ĂȂǂ���܂�����A�����Ē�����Ɗ������ł��B
QA Checker �̏ڍׂɂ��ẮA�ȑO�̋L���u���K�\���Ȃ��ŁA���؋@�\���g���v���Q�Ƃ��Ă��������B���̋L���ł������Ă���Ƃ���AQA Checker �̐ݒ�̓t�@�C���ɃG�N�X�|�[�g���ĕۑ����Ă������Ƃ��ł��܂��B�����悤�ɁA���K�\���ɂ� [�A�N�V����] �̒��� [�A�C�e���̃G�N�X�|�[�g] �� [�A�C�e���̃C���|�[�g] ���p�ӂ���Ă��܂��B���̉�ʂ̃G�N�X�|�[�g�͐��K�\���݂̂��G�N�X�|�[�g���܂��B�܂��֗��ȓ_�Ƃ��āA���̉�ʂ̃C���|�[�g�͍폜�������A�lj��ƍX�V���������Ă���܂��B�܂�A�����̃A�C�e���͂��̂܂c��A�V�����A�C�e���͒lj�����A�����čX�V���ꂽ�A�C�e���͍X�V����܂��BQA Checker �S�̂̃v���t�@�C������C���|�[�g������ƁA������ւ��ɂȂ�̂ŌÂ��A�C�e���͍폜����܂��B
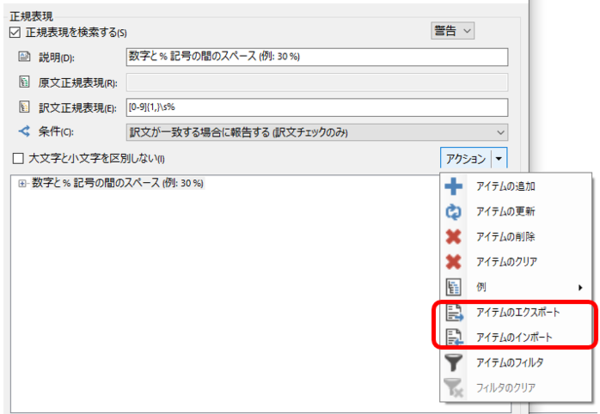
���p�|��̏ꍇ�́A�啶����L�������P�[�X�ȂNJW�Ȃ��P���Ɂu�p�P����o���v�ƍl����悢�̂ŊȒP�ł��B
�p�P��
����:
��:
���́A�����A�n�C�t���A�s���I�h���܂߂ď�L�̂悤�ɐݒ肵�Ă��܂��B����ŁA�p��̏������A�啶���A�����A�n�C�t���A�s���I�h�ō\�������P����������璊�o�ł��܂��B��
�S�p�̉p�P��
�����܂ł͊ȒP�ł����A���p�|��Ŗ��ɂȂ�̂͑S�p�ł��B���������{��̏ꍇ�A�p�������S�p�ŏ�����Ă��邱�Ƃ�����܂��B��L�̎��͑S�p�ɂ̓}�b�`���܂���B�����ŁA���͈ȉ��̎����lj����Ă��܂��B
����:
��:
����őS�p�̉p���������o�ł��܂��B���o�͂ł��܂����A��
�������p��̏ꍇ�́A���R�Ȃ��炷�ׂĂ��p�P��Ȃ̂ŏ�L�̂悤�ɒP���ɂ͂����܂���B�啶���ƃL�������P�[�X���w�肷��K�v������܂��B
�啶���ō\�������P��
�啶���͔�r�I�ȒP�ł��B���́A�n�C�t�����܂߂Ĉȉ��̂悤�Ɏw�肵�Ă��܂��B�u�啶�����n�C�t���� 2 ��ȏ�A������v�Ƃ����Ӗ��ł��B
����:
1 �����̉p����
��L�̏����́u2 ��ȏ�v�Ƃ����w��Ȃ̂� server A �Ȃǂɂ̓}�b�`���܂���B�����ŁA�p���� 1 ���������𒊏o���鎮���lj����܂��B
����:
�L�������P�[�X
���悢��L�������P�[�X�ł��B�������G�ɂȂ�܂��B���́A�l���Ă����畡�G�����Ă悭�킩��Ȃ��Ȃ����̂Łu�������n�܂�v�Ɓu�啶���n�܂�v�� 2 �ɕ����邱�Ƃɂ��܂����B
�E�������n�܂�L�������P�[�X (getTableStatus �Ȃ�)
����:
�E�啶���n�܂�L�������P�[�X (GetTableStatus �Ȃ�)
����:
������́u�啶���Ŏn�܂��āA���������o�ꂵ�āA�܂��啶�����o�ꂷ��v�Ƃ��������ł��B�u�啶���Ŏn�܂��āA���������o�ꂷ��v�����ł́A�擪��啶���ɂ���ʏ�̕����ׂĂɈ�v���Ă��܂��̂ŁA2 �x�ڂ̑啶�����K�v�ł��B
�����ȊO�̑啶���n�܂� (This is a Windows server �Ȃ�)
�啶���̘A����L�������P�[�X�ł͂Ȃ��A�P�ɕ��̒��ő啶���Ŏn�܂�P����`�F�b�N�������ꍇ������܂��B�����A�p��̕��͒ʏ�啶���Ŏn�܂�̂ł��ꂪ�Ȃ��Ȃ���ςł��B�����̑啶���͒��o���Ȃ��悤�ɂ���K�v������܂��B
����:
�擪��
���āA���낢��ȃ`�F�b�N�����Ă��A�R�}���h��v���p�e�B���Ȃǂ����ڂ� IT �n�����̂Ƃ��͉p�P��̋L�q�ɂǂ����Ă��s�����c��܂��B����ȂƂ��́A�����Ɩ����ւ��ă`�F�b�N�����Ă݂܂��B����͂��Ȃ�L���ł��B
Trados �̐��K�\���̈ꕔ�́u��������v�����̃`�F�b�N�����s���܂���B���K�\���̏������悭���Ă݂�Ɓu�O���[�v�����ꂽ�����\���v�͈ȉ��� 2 ��������������܂���B

��
�܂��A��L�̂Ƃ���A�p�� -> ���{��̃`�F�b�N�͂��Ȃ蕡�G�� False positive �� False negative �������Ȃ�܂��B������A���{�� -> �p��ɕς���ƃ`�F�b�N���P���ɂȂ�A�G���[��������₷���Ȃ�܂��B�p�� -> ���{��̏ꍇ�Aset �� get �Ȃǂ̏������n�܂�̃v���O���� �R�}���h�͕��ʂ̉p��Ƌ�ʂ����Ȃ��̂Ō��o�ł��܂��A��o��ɓ��{�� -> �p��ɕς��ĉp�P��̃`�F�b�N������Ό��o�ł��܂��B���̃`�F�b�N�́A���̌o����A���������L���ɋ@�\���܂��B
����͈ȏ�ł��BTrados �Ō����Ɩ����ւ�����@�ɂ��ẮA����Ƃ肠�������Ǝv���܂��B���K�\�������낢��l���Ă���ƁA�f���ɐV���� Xbench ���w����������������Ȃ����Ƃ����l���������悬��Ȃ����Ƃ��Ȃ��ł����A�Ƃ肠�����A���������撣���Ă݂܂��B���K�\���͂悭�킩��Ȃ����Ƃ������̂ŁA�A�h�o�C�X������ƂƂĂ��������ł��B
Tweet
���͂����� Xbench �̖����� (V2.9) ���g���Ă��܂����A�����łň�Ԏc�O�Ȃ̂� QA �`�F�b�N�� CamelCase Mismatch �� ALLUPPER CASE Mismatch ��L���ɂł��Ȃ����Ƃł��B�L���ł� V3 �ȍ~�ł͗L���ɂł���炵���ł����AV2.9 �ł� DISABLED �ƕ\������邾���ŁA�����L���ɂ���I�v�V����������܂���B���̃`�F�b�N�́A�啶���̒P�� (WAF �� HTTP �Ȃ�) �ƃL�������P�[�X�̒P�� (GetStatus �� SetTranslationMemory �Ȃ�) �������Ɩň�v���Ă��邩���m�F���Ă������̂��Ǝv���܂��B�p�P��́u�K����������R�s�[����v�Ƃ������[����O�ꂵ�Ă���ΊԈႤ�͂��͂Ȃ��̂ł����A����ł������Ă��܂����肷�邱�Ƃ�����̂ŁA���������`�F�b�N�͂ǂ����Ă��K�v�ɂȂ�܂��B
�����ŁA����͂��̃`�F�b�N�� Trados �� QA Checker ���g���čČ����邱�Ƃɒ��킵�܂��B���p�|��Ɖp���|��̗������ɂ��čČ�������@���l���Ă݂܂����B�ŁA�l���Ă݂��̂ō���͂��̕��@���Љ�܂����A���͂��܂肤�܂��@�\���Ȃ��P�[�X������܂��B�ǂ����Ă��댟�o�������Ă��܂��܂��B�����A���P�ĂȂǂ���܂�����A�����Ē�����Ɗ������ł��B
QA Checker �̐��K�\��
QA Checker �̏ڍׂɂ��ẮA�ȑO�̋L���u���K�\���Ȃ��ŁA���؋@�\���g���v���Q�Ƃ��Ă��������B���̋L���ł������Ă���Ƃ���AQA Checker �̐ݒ�̓t�@�C���ɃG�N�X�|�[�g���ĕۑ����Ă������Ƃ��ł��܂��B�����悤�ɁA���K�\���ɂ� [�A�N�V����] �̒��� [�A�C�e���̃G�N�X�|�[�g] �� [�A�C�e���̃C���|�[�g] ���p�ӂ���Ă��܂��B���̉�ʂ̃G�N�X�|�[�g�͐��K�\���݂̂��G�N�X�|�[�g���܂��B�܂��֗��ȓ_�Ƃ��āA���̉�ʂ̃C���|�[�g�͍폜�������A�lj��ƍX�V���������Ă���܂��B�܂�A�����̃A�C�e���͂��̂܂c��A�V�����A�C�e���͒lj�����A�����čX�V���ꂽ�A�C�e���͍X�V����܂��BQA Checker �S�̂̃v���t�@�C������C���|�[�g������ƁA������ւ��ɂȂ�̂ŌÂ��A�C�e���͍폜����܂��B

���{�� -> �p��̏ꍇ
���p�|��̏ꍇ�́A�啶����L�������P�[�X�ȂNJW�Ȃ��P���Ɂu�p�P����o���v�ƍl����悢�̂ŊȒP�ł��B
�p�P��
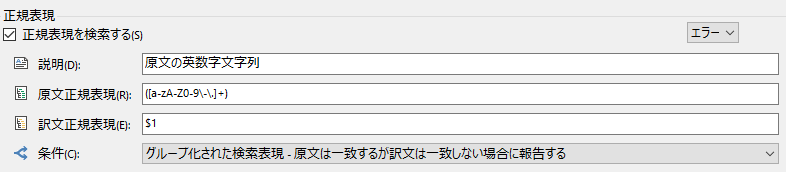
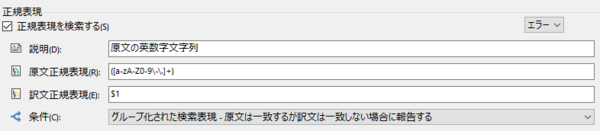
����:
([a-zA-Z0-9\-\.]+)��:
$1 ���́A�����A�n�C�t���A�s���I�h���܂߂ď�L�̂悤�ɐݒ肵�Ă��܂��B����ŁA�p��̏������A�啶���A�����A�n�C�t���A�s���I�h�ō\�������P����������璊�o�ł��܂��B��
$1 �́u������ ( ) ���Ƃ܂������������e�v�Ƃ������Ƃ��Ӗ����܂��B�������� CAT �����o���ꂽ��A�ł� CAT ��T���܂��B�S�p�̉p�P��
�����܂ł͊ȒP�ł����A���p�|��Ŗ��ɂȂ�̂͑S�p�ł��B���������{��̏ꍇ�A�p�������S�p�ŏ�����Ă��邱�Ƃ�����܂��B��L�̎��͑S�p�ɂ̓}�b�`���܂���B�����ŁA���͈ȉ��̎����lj����Ă��܂��B
����:
([��-���`-�y�O-�X]+)��:
$1����őS�p�̉p���������o�ł��܂��B���o�͂ł��܂����A��
$1 �͂��܂��@�\���܂���B�̉p��ł͉p�����͔��p�ɂ���̂ŁA�����̑S�p �b�`�s ��Ő��������p CAT �ɕϊ����Ă��Ă����ׂăG���[�Ƃ��Č��o����܂��B���S�̂��߂ɂ��̎����g���Ă͂��܂����A�댟�o�������Ȃ�܂��B�p�� -> ���{��̏ꍇ
�������p��̏ꍇ�́A���R�Ȃ��炷�ׂĂ��p�P��Ȃ̂ŏ�L�̂悤�ɒP���ɂ͂����܂���B�啶���ƃL�������P�[�X���w�肷��K�v������܂��B
�啶���ō\�������P��
�啶���͔�r�I�ȒP�ł��B���́A�n�C�t�����܂߂Ĉȉ��̂悤�Ɏw�肵�Ă��܂��B�u�啶�����n�C�t���� 2 ��ȏ�A������v�Ƃ����Ӗ��ł��B
����:
([A-Z\-]{2,})1 �����̉p����
��L�̏����́u2 ��ȏ�v�Ƃ����w��Ȃ̂� server A �Ȃǂɂ̓}�b�`���܂���B�����ŁA�p���� 1 ���������𒊏o���鎮���lj����܂��B
����:
(\b[\w\d]\b)\b �͒P��̎n�܂�܂��͏I���������܂��B\w �͉p�����A\d �͐����ł��B���̎��́u�P��̎n�܂肪�����āA�p������ 1 �����āA�P��̏I���ɂȂ�v�Ƃ��������ɂȂ�܂��B���͐������܂߂Ă��܂����A�����͐����`�F�b�N�̋@�\���ʂɂ���̂ł����Ɋ܂߂Ȃ��Ă� OK �ł��B�L�������P�[�X
���悢��L�������P�[�X�ł��B�������G�ɂȂ�܂��B���́A�l���Ă����畡�G�����Ă悭�킩��Ȃ��Ȃ����̂Łu�������n�܂�v�Ɓu�啶���n�܂�v�� 2 �ɕ����邱�Ƃɂ��܂����B
�E�������n�܂�L�������P�[�X (getTableStatus �Ȃ�)
����:
(\b[a-z]+\-*[A-Z]+[a-z\-]*)\b �͒P��̎n�܂�Ȃ̂Łu�������Ŏn�܂��āA�啶���� 1 ��ȏ�o�ꂵ�āA�܂�������������v�Ƃ��������ł��B�O�̂��߁A�n�C�t��������Ƃ������Ƃɂ��Ă��܂��B�E�啶���n�܂�L�������P�[�X (GetTableStatus �Ȃ�)
����:
(\b[A-Z]+\-*[a-z]+\-*[A-Z]+[\w\d\-]*)������́u�啶���Ŏn�܂��āA���������o�ꂵ�āA�܂��啶�����o�ꂷ��v�Ƃ��������ł��B�u�啶���Ŏn�܂��āA���������o�ꂷ��v�����ł́A�擪��啶���ɂ���ʏ�̕����ׂĂɈ�v���Ă��܂��̂ŁA2 �x�ڂ̑啶�����K�v�ł��B
�����ȊO�̑啶���n�܂� (This is a Windows server �Ȃ�)
�啶���̘A����L�������P�[�X�ł͂Ȃ��A�P�ɕ��̒��ő啶���Ŏn�܂�P����`�F�b�N�������ꍇ������܂��B�����A�p��̕��͒ʏ�啶���Ŏn�܂�̂ł��ꂪ�Ȃ��Ȃ���ςł��B�����̑啶���͒��o���Ȃ��悤�ɂ���K�v������܂��B
����:
^.+([A-Z]+\-*[a-z0-9]+\-*\b)�擪��
^ �͐��K�\���Łu�����v���Ӗ����܂��B���̎��́u�������牽����������������ɑ啶�����o�ꂷ��v�Ƃ��������ɂȂ�܂��B���݂܂���A������l���Ă݂͂����̂́A���Ȃ�댟�o�������Ȃ�܂��B�����ȊO�ɑ啶�����o�ꂷ�镶�͎��͂��Ȃ肠��܂��B���Ƃ��A���o���Ńw�b�h���C�� �X�^�C�����g���Ă���A���S�̂��ۊ��ʂň͂܂�Ă���ANote: �̂悤�ȃR�����̌�ɕ���������Ă���A�Ȃǂł��B���������P�[�X�����O���悤�Ƃ���ƂȂ��Ȃ��ʓ|�ł��B�����Ɩ����ւ��ă`�F�b�N����
���āA���낢��ȃ`�F�b�N�����Ă��A�R�}���h��v���p�e�B���Ȃǂ����ڂ� IT �n�����̂Ƃ��͉p�P��̋L�q�ɂǂ����Ă��s�����c��܂��B����ȂƂ��́A�����Ɩ����ւ��ă`�F�b�N�����Ă݂܂��B����͂��Ȃ�L���ł��B
Trados �̐��K�\���̈ꕔ�́u��������v�����̃`�F�b�N�����s���܂���B���K�\���̏������悭���Ă݂�Ɓu�O���[�v�����ꂽ�����\���v�͈ȉ��� 2 ��������������܂���B

��
$1 �ȂǂƋL�q����P�[�X���u�O���[�v�����ꂽ�����\���v�ɂ�����܂����A���̏ꍇ�͕K���������Ɍ�������K�v������܂��B����ȊO�̏ꍇ�́u�͈�v���邪�`�v��u�`�F�b�N�̂݁v���\�ł����A$1 �Ȃǂ��g���ꍇ�͂��ꂪ�ł��܂��� (���̉�ʏ�ł͂ǂ̏������I���ł��܂����A���҂ǂ���̓���ɂȂ�܂���)�B���̂��߁A�ʏ�́u�ɗ]�v�ȉp�P�ꂪ�����Ă���v�Ƃ����P�[�X�͌��o�ł��܂��A�����Ɩ����ւ��ă`�F�b�N������Ό��o�ł��܂��B�܂��A��L�̂Ƃ���A�p�� -> ���{��̃`�F�b�N�͂��Ȃ蕡�G�� False positive �� False negative �������Ȃ�܂��B������A���{�� -> �p��ɕς���ƃ`�F�b�N���P���ɂȂ�A�G���[��������₷���Ȃ�܂��B�p�� -> ���{��̏ꍇ�Aset �� get �Ȃǂ̏������n�܂�̃v���O���� �R�}���h�͕��ʂ̉p��Ƌ�ʂ����Ȃ��̂Ō��o�ł��܂��A��o��ɓ��{�� -> �p��ɕς��ĉp�P��̃`�F�b�N������Ό��o�ł��܂��B���̃`�F�b�N�́A���̌o����A���������L���ɋ@�\���܂��B
����͈ȏ�ł��BTrados �Ō����Ɩ����ւ�����@�ɂ��ẮA����Ƃ肠�������Ǝv���܂��B���K�\�������낢��l���Ă���ƁA�f���ɐV���� Xbench ���w����������������Ȃ����Ƃ����l���������悬��Ȃ����Ƃ��Ȃ��ł����A�Ƃ肠�����A���������撣���Ă݂܂��B���K�\���͂悭�킩��Ȃ����Ƃ������̂ŁA�A�h�o�C�X������ƂƂĂ��������ł��B
| �@�@ |
Tweet
2022�N12��14��
�y�O�ҁz�^�C�s���O�����炻��
Advent Calendar �u�|��ɖ𗧂��Ă��ꂻ���ȃc�[���v�̋L���ł��B����́A������ Trados �ł��B
�|���Ƃ����������悤�ƍl�����Ƃ��A�����^����Ɏv�����̂́u�^�C�s���O�̗ʂ����炷�v���Ƃł��B���Ȃ��^�C�s���O�Ő��m�ɓ��͂ł����ƃX�s�[�h�͊m���ɏオ��ł��傤�B�������A�����͎v�����A�^�C�s���O�� 1 �� 1 ��͂킸���Ȏ��ԂȂ̂ő��������ɂ������ł��B
����Ȏ����AIME �̒P��o�^�� AutoHotkey �͎g���Ă��܂��B�����AIME �͊�{�I�ɓ��{�����͂��邽�߂̂��̂Ȃ̂ʼnp������Ă���Ƃ��͂��܂�𗧂��܂���B�܂��AAutoHotkey �͂ƂĂ��֗��ł����X�N���v�g�̋L�q�͂ǂ����Ă��ʓ|�ł��B�Ƃ����킯�ŁA����� Trados �̒��Ń^�C�s���O�����炷���߂Ɏg�p�ł���@�\���܂Ƃ߂Ă݂܂����BTrados �̊O�Ń^�C�s���O�����炷���@�͐���������Ǝv���܂����A�܂��� Trados �ɕt���Ă���@�\�����ł��\���Ɋ��p���Ă����܂��傤�B�����ɋ������ȊO�ɂ��ǂ��A�C�f�A������A���Ђ��Ђ����������������B
�ݒ�̎��: [�v���W�F�N�g�̐ݒ�] �� [�t�@�C��] > [�I�v�V����]
���āATrados �������Ƃ͂����Ă��A�^�C�s���O�����炷���ʂ����҂ł���@�\�͂���������������܂��B����� Trados �̐ݒ�� 2 �ɕ����A������O�҂ƌ�҂� 2 �̋L���Ő����������Ǝv���܂��BTrados �̐ݒ�͑傫��������ƁA�v���W�F�N�g���Ƃ̐ݒ�ł��� [�v���W�F�N�g�̐ݒ�] �ƁATrados ���S�̂̐ݒ�ł��� [�t�@�C��] > [�I�v�V����] �� 2 �ɂȂ�܂��B���� 2 �̏ڍׂɂ��ẮA�ȑO�̋L���uTrados �̐ݒ��ς���ɂ� �| [�t�@�C��] �� [�v���W�F�N�g�̐ݒ�]�v���Q�Ƃ��Ă��������B
[�t�@�C��] > [�I�v�V����] �̐ݒ�͈�x�ݒ肷����̌ジ���ƗL���ł����A[�v���W�F�N�g�̐ݒ�] �̓v���W�F�N�g���Ƃɐݒ���s���K�v������܂��B�܂�A�v���W�F�N�g�̐ݒ�͐V�����p�b�P�[�W���J�����тɐݒ�����܂��B�t�@�C�����lj��ɂȂ�܂����Ȃǂƌ����čX�V�p�b�P�[�W��������Ƃ����A�c�O�Ȃ���A�ݒ����蒼���Ȃ���Ȃ�܂���B
�ł́A����̑O�҂ł͂��̃v���W�F�N�g�̐ݒ�����Ă����܂��B
�ݒ�̏ꏊ: [����y�A] > [���ׂĂ̌���y�A] > [�|�����Ǝ����|��] > [����] > [upLIFT �p�̃t���O�����g��v�̃I�v�V����]
�t���O�����g��v�̋@�\�͊���ŗL���ł����A�ꕔ�����ɂȂ��Ă���I�v�V����������܂��B�t���O�����g��v�� upLIFT �̏ڍׂɂ��ẮA�ȑO�̋L���u�t���O�����g��v�Ɋւ���ݒ��v��ATrados �̌����u���O���Q�Ƃ��Ă��������B
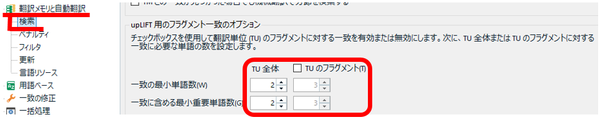
��}�� [TU �̃t���O�����g] ���I���ɂ��܂��B������I���ɂ���ƁA���ߑS�̂ł͂Ȃ��A���̒P�ʂŃ}�b�`�����o�����̂ŁA[�t���O�����g��v] �E�B���h�E�ɕ\�������}�b�`�������Ȃ�܂��B[�t���O�����g��v] �E�B���h�E�ɕ\�����ꂽ���́A�V���[�g�J�b�g �L�[ Ctrl+Alt+M �Ŗɑ}���ł��܂��B
�P�ꐔ�̃t�B�[���h�́A��L�̌����u���O�̐����ɏ]���Ăǂ�����u2�v�ɐݒ肵�܂��B���܂�Ƀ}�b�`�������\�������悤�Ȃ�u3�v�ɕύX���܂��B������傫������ƃ}�b�`������܂��B
�ݒ�̏ꏊ: [����y�A] > [���ׂĂ̌���y�A] > [�|�����Ǝ����|��]�A��������I������ [�ݒ�] > [���ꃊ�\�[�X] > [����F������]
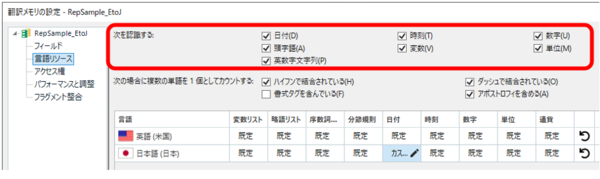
�u�Œ�v�f�v�Ƃ́A�����A���t�A�啶���̉p�P��Ȃǂ̂��Ƃł��B�u�F���ς݃g�[�N���v�ƌĂ�邱�Ƃ�����܂��B���ɂƂ��ẮATrados �̒��ł悭�킩��Ȃ��@�\�̃g�b�v�ɂ�������̂ł����A�����F���Ƃ��A�����u���Ƃ��A QuickPlace (�V���[�g�J�b�g �L�[�� Ctrl+Alt+�����܂��� Ctrl+�J���}) �Ƃ��A�J��Ԃ������Ƃ��A���낢��ȂƂ���ɉe������̂Œ��ӂ��K�v�ł��B�ڍׂɂ��ẮA�����w���v�́u�Œ�v�f�v���Q�Ƃ��Ă��������B(�����A�Q�Ƃ��Ă��悭�킩��܂���B)
�Œ�v�f�̐ݒ�� 2 �i�K�ōs���܂��B�ŏ��Ɂu�F���v��L���ɂ��A���̌�Łu�u���v��L���ɂ��܂��B�ł́A�܂��u�F���v��L���ɂ�����@�ł��B
�G�f�B�^�[�̌����ŁA��������t�ȂǂɐF�̉�����������Ă��邱�Ƃ�����Ǝv���܂��B���ꂪ�A�Œ�v�f���u�F������Ă���v��Ԃł��B�F�����ꂽ�v�f�́AQuickPlace �@�\ (�V���[�g�J�b�g �L�[�� Ctrl+Alt+�����܂��� Ctrl+�J���}) �ŖɃR�s�[�ł��܂��B
�F����L���ɂ���ݒ�́A�������ɕt������u���ꃊ�\�[�X�v�ōs���܂��B�������̐ݒ��ʂ� [���ꃊ�\�[�X] �� [����F������] �̊e�`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA���ꂼ��̗v�f���F�������悤�ɂȂ�܂��B
�ݒ�̏ꏊ: [����y�A] > [����̌���y�A] > [�|�����Ǝ����|��] > [�����u��]
�ł͎��ɁA�F�����ꂽ�Œ�v�f�́u�u���v��L���ɂ���ݒ���s���܂��B����́A���t��ʉ݂Ȃǂ̌`���������I�ɕϊ����Ă����@�\�ł��B�ڍׂɂ��ẮA�����w���v�� [�|�����Ǝ����|��] > [�����u��] ���Q�Ƃ��Ă��������B
�u���̐ݒ�́A[���ׂĂ̌���y�A] �ł͂Ȃ��AJapanese->English �ȂǁA����̌���y�A�ōs���܂��B���t��ʉ݂̌`���͌���Ɉˑ�����̂ŁA���ꂲ�Ƃɐݒ肷��K�v������܂��B�ȉ��� [�����u��] �y�[�W�ɕ\������鍀�ڂ̃`�F�b�N�{�b�N�X���I���ɂ���ƁA���ꂼ��̗v�f�̒u�����L���ɂȂ�܂��B
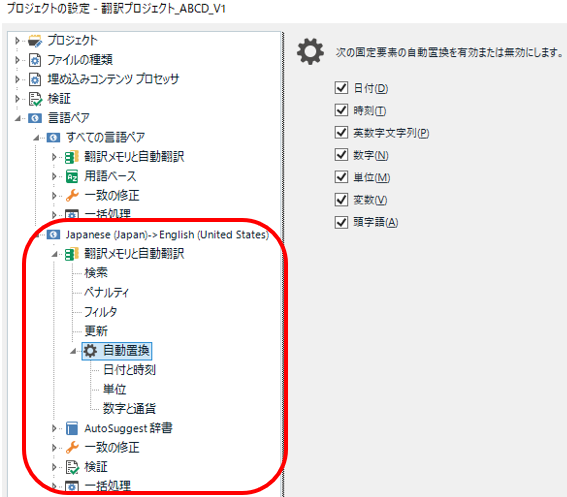
�����A�����u���̓���͂��܂�M�p�ł��Ȃ��̂ŁA�����S�ȕ��@���Ƃ�Ȃ�u�F���͗L���A�u���͖����v�Ɛݒ肷��̂��悢�Ǝv���܂��B�F����L���ɂ��ĐF�̉�����������Ă���A�u���͖����ł� QuickPlace �@�\�̃V���[�g�J�b�g �L�[�œ��͂��\�ł��B
���́A���͍���̋L���������Ă��ď��߂Ă��̒u���ݒ�y�[�W�̑��݂ɋC�Â��܂����B�ȑO���J��Ԃ������̋L���ł��Œ�v�f�ɂ��Ă͐������Ă��܂����A���̎����u���̗L��/�����͂������蔲�������Ă��܂��� (���݂܂���)�B�J��Ԃ������̓���ɂ����́u�F���v�Ɓu�u���v�� 2 �i�K�̐ݒ肪�e�����܂��B
���Ȃ݂ɁA���͖���u�F���v�Ɓu�u���v�̑S�`�F�b�N�{�b�N�X���I���ɂ��Ă��܂����A����͂����܂Ń^�C�s���O�����炷���߂ł��B�����āA�����Ŗ�����Ă��炨���Ƃ��Ă���킯�ł͂���܂���B�uWindows�v�� OS �ł͂Ȃ��ĕ����̃E�B���h�E��������Ȃ����A�uSW�v�̓X�C�b�`��������Ȃ����ǃ\�t�g�E�F�A��������Ȃ����A�u�o�[�W���� 100 �� 100 ���̃t�@�C���� 100 ���� 1 �̎��Ԃŏ�������v�݂����ȕ������邩������܂���B�����I�ȕϊ��͐M���ł��Ȃ��̂ł��ׂĊm�F���K�v�ł��B���̂��߁A�y�i���e�B�Ƃ̕��p�͕K�{�ł��B�����u����L���ɂ���ƃ}�b�`�����オ�����肵�܂����A����ŗ�������������ł���ƍl����̂͊ԈႢ�ł� (�Ǝ��͎v���Ă��܂�)�B�|���Б��ʼn�͂�����Ƃ��́u�����u���Ȃ��A�����u������Ȃ�y�i���e�B��t����v�������ł� (�Ǝ��͎v���Ă��܂�)�B
�ݒ�̏ꏊ: [����y�A] > [����̌���y�A] > [�|�����Ǝ����|��] > [�����u��]
(�K�v�ɉ����āA[����y�A] > [���ׂĂ̌���y�A] > [�|�����Ǝ����|��]�A��������I������ [�ݒ�] > [���ꃊ�\�[�X])
�����u���̐ݒ��ʂɂ́A[���t�Ǝ���]�A[�P��]�A[�����ƒʉ�] �� 3 ���p�ӂ���Ă��܂��B�����ł́A[���t�Ǝ���] �ɂ��Ă��������������Ǝv���܂��B[�P��] �ɂ��ẮA�ȑO�̋L���u�P�ʋL���̑O�ɃX�y�[�X�������v���Q�Ƃ��Ă��������B[�����ƒʉ�] �ɂ��ẮA���݂܂���A�悭�킩��Ȃ����Ƃ��炯�Ȃ̂ō���͏ȗ����܂��B
���t�Ǝ����́A�ȉ��̉�ʂŌ`����ݒ�ł��܂��B�X�^�C���K�C�h�Ȃǂ��m�F���āA�K�Ȍ`����I�т܂��B�����A�����u���͌������������`���œ��͂�����Ă��Ȃ��ƓK�ɋ@�\���܂���B���Ɠ������A�܂��͓������A�Ƃ����悤�ȏꍇ�͔F�����ꂸ�A�u��������܂���B
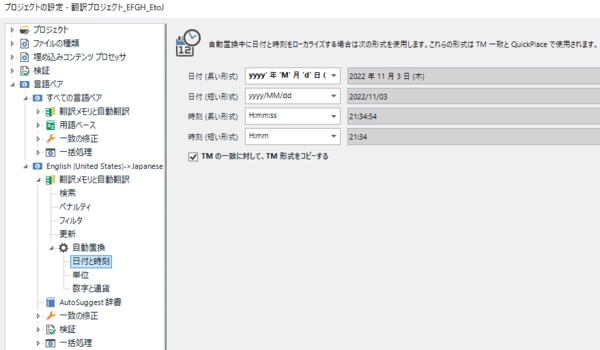
���̐ݒ��ʂ̃h���b�v�_�E���ɕ\�������I�v�V�����͎����Őݒ肪�\�ł��B���Ƃ��A[���t (�����`��)] �ɂ͂��Ȃ肽������̃I�v�V����������܂����A�X�^�C���K�C�h���u�S�p�Ɣ��p�̊ԂɃX�y�[�X������v�Ƃ������[���̏ꍇ�A����ɍ������I�v�V�����͂���܂���B
���̃��[���ɂ������I�v�V�������쐬����ɂ́A�������̌��ꃊ�\�[�X�̐ݒ�ɖ߂�܂��B
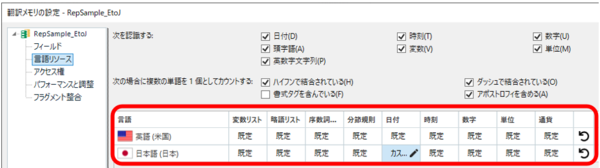
���̕\���� [���t] �� [���{��] ���N���b�N���ĕҏW��ʂ��J���܂��B�����ŁA�K�v�Ȍ`����lj����܂��Byyyy �Ȃǂ̗v�f���e�Ƀv�����v�g����Ă���̂ŁA�����g�ݍ��킹�Ă����ΐݒ�ł��܂��B
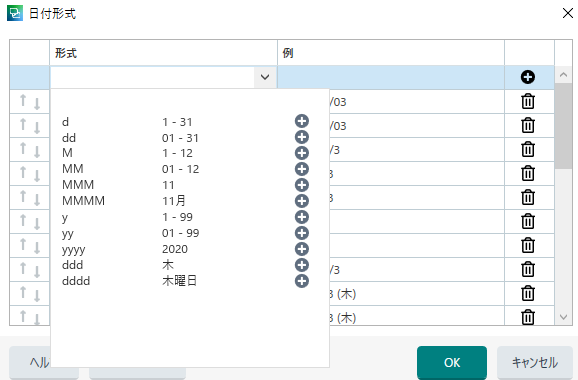
�u�S�p�Ɣ��p�̊ԂɃX�y�[�X������v�Ƃ������[���̏ꍇ�́A�ȉ���ݒ肵�܂� (�R�s�y�ł��܂�)�B
����ŁA��قǂ̎����u���̐ݒ��ʂɖ߂�ƁA�lj������`�����h���b�v�_�E���ɕ\�������悤�ɂȂ�܂��B
�u�v���W�F�N�g�̐ݒ�v�Ń^�C�s���O�����炷���߂̋@�\�̐����͈ȏ�ł��B�Ō�ɁA�܂Ƃ߂Ƃ��Ă��������ӓ_�������Ă����܂��B�Œ�v�f�̔F����u���́A���̌o����A�Ȃ����ݒ肪���܂������Ȃ����Ƃ������ł��B�K����������Ƃ͌���܂��A�����̂Ƃ��̎Q�l�ɂ��Ă��������B
���ꃊ�\�[�X�� 1 �ԏ�ɂ��郁�����Őݒ肷��
���ꃊ�\�[�X�̐ݒ�̓������ɕt�����܂����A�v���W�F�N�g�ɂ͕����̃��������ݒ肳��Ă��邱�Ƃ�����܂��B���̏ꍇ�́A�������̃��X�g�� 1 �ԏ�ɕ\������Ă��郁�����Őݒ���s���Ă��������B���Ԃ�A1 �ԏ�̃������̐ݒ肪�D��I�Ɏg���Ă���Ǝv���܂��B(���݂܂���A�����܂ŁA���̌o�����ł��B)
�������A�|���Ђ�������T�[�o�[ TM �̌��ꃊ�\�[�X�͖|��ґ��ł͐ݒ��ύX�ł��܂���B���̂��߁A������p�b�P�[�W�ŃT�[�o�[ TM �� 1 �ԏ�ɐݒ肳��Ă���ꍇ�͏����Ή��ɍ���܂��B�����悭�s����́u����̃������� 1 �ԏ�ɒlj�����v�ł����A����ɂ�����|��t�@�C�����J���Ȃ��Ȃ������Ƃ�����܂��B�������̏��Ԃ�ς���ƁA�}�b�`�̗D��x���ς��̂ŁA���̕ӂ�����ӂ��K�v�ł��B
����̌���y�A�̐ݒ肪�D�悳���
��L�̐����ł́A�u���ׂĂ̌���y�A�v�Ɓu����̌���y�A�v�̐ݒ���g�p���Ă��܂����A������v���W�F�N�g�̏ꍇ�Łu����̌���y�A�v�Ɋ��ɉ��炩�̐ݒ肪����Ă���ꍇ�́u���ׂĂ̌���y�A�v���u����̌���y�A�v�̐ݒ肪�D�悳��܂��B���̂��߁A�����Őݒ��ύX����Ƃ����A�u����̌���y�A�v�Őݒ��ύX����K�v������܂��B�ڍׂɂ��ẮA�ȑO�̋L���u�ŋ߂� Trados �̃��i: ���������q�b�g���Ă��Ȃ��v���Q�Ƃ��Ă��������B
�ݒ��ς�����A�G�f�B�^�[������������āA�J������
�Œ�v�f�Ȃǂ̃������̐ݒ�́A�ݒ��ʂŕύX�����Ă��A�����ɓ��삪�ς��Ȃ����Ƃ�����܂��B���́A�ݒ肪���܂��ł��Ă��Ȃ��̂ł͂Ȃ����Ǝv���āA������m�F��ύX�����Ă������Ƃ�����܂��B����ȂƂ��͂�������G�f�B�^�[��ʂ���āA���߂Ė|��t�@�C�����J�������Ɠ��삪�ς�邱�Ƃ�����܂��B
���������A�b�v�O���[�h����H�H
���ꃊ�\�[�X�̐ݒ��ύX����ƁA�������ɃA�b�v�O���[�h�𑣂��x���}�[�N���\������܂��B�A�b�v�O���[�h���Ȃ��Ă�����ɋ@�\���Ă���悤�Ɍ����܂����A�Ƃɂ��������ł��ݒ��ύX����ƌx���}�[�N���t���܂��B�A�b�v�O���[�h�̏����̓��������傫���Ƃ��Ȃ莞�Ԃ�������̂ŁA���͂��낢��ݒ肵�Ă���A�Ō�ɔO�̂��߃A�b�v�O���[�h����悤�ɂ��Ă��܂��B
�ȏ�ł��B�ƂĂ��Ȃ������Ȃ��Ă��܂��܂����B�u�^�C�s���O�����炷���߂ɂǂꂾ���ݒ肪�K�v�Ȃ�I�v�Ƃ��������ł����A������p�b�P�[�W����邽�тɍs���K�v������܂��B�͂����肢���Ėʓ|�ł��B�ƂĂ��ʓ|�ł��B�ł����AAutoHotkey �ȂǑ��̎�i�ł��ׂĎ������悤�Ƃ���ƁA���������̂ŁA�Ƃ肠������ Trados ����̐ݒ�ɗ����Ă��܂��B����́A�v���W�F�N�g�̐ݒ�ł͂Ȃ��A�G�f�B�^�[�̐ݒ�����グ�܂��B������́A�v���W�F�N�g���Ƃɐݒ肷��K�v���Ȃ��A��ł����y��������܂���B
Tweet
�|���Ƃ����������悤�ƍl�����Ƃ��A�����^����Ɏv�����̂́u�^�C�s���O�̗ʂ����炷�v���Ƃł��B���Ȃ��^�C�s���O�Ő��m�ɓ��͂ł����ƃX�s�[�h�͊m���ɏオ��ł��傤�B�������A�����͎v�����A�^�C�s���O�� 1 �� 1 ��͂킸���Ȏ��ԂȂ̂ő��������ɂ������ł��B
����Ȏ����AIME �̒P��o�^�� AutoHotkey �͎g���Ă��܂��B�����AIME �͊�{�I�ɓ��{�����͂��邽�߂̂��̂Ȃ̂ʼnp������Ă���Ƃ��͂��܂�𗧂��܂���B�܂��AAutoHotkey �͂ƂĂ��֗��ł����X�N���v�g�̋L�q�͂ǂ����Ă��ʓ|�ł��B�Ƃ����킯�ŁA����� Trados �̒��Ń^�C�s���O�����炷���߂Ɏg�p�ł���@�\���܂Ƃ߂Ă݂܂����BTrados �̊O�Ń^�C�s���O�����炷���@�͐���������Ǝv���܂����A�܂��� Trados �ɕt���Ă���@�\�����ł��\���Ɋ��p���Ă����܂��傤�B�����ɋ������ȊO�ɂ��ǂ��A�C�f�A������A���Ђ��Ђ����������������B
�ݒ�̎��: [�v���W�F�N�g�̐ݒ�] �� [�t�@�C��] > [�I�v�V����]
���āATrados �������Ƃ͂����Ă��A�^�C�s���O�����炷���ʂ����҂ł���@�\�͂���������������܂��B����� Trados �̐ݒ�� 2 �ɕ����A������O�҂ƌ�҂� 2 �̋L���Ő����������Ǝv���܂��BTrados �̐ݒ�͑傫��������ƁA�v���W�F�N�g���Ƃ̐ݒ�ł��� [�v���W�F�N�g�̐ݒ�] �ƁATrados ���S�̂̐ݒ�ł��� [�t�@�C��] > [�I�v�V����] �� 2 �ɂȂ�܂��B���� 2 �̏ڍׂɂ��ẮA�ȑO�̋L���uTrados �̐ݒ��ς���ɂ� �| [�t�@�C��] �� [�v���W�F�N�g�̐ݒ�]�v���Q�Ƃ��Ă��������B
[�t�@�C��] > [�I�v�V����] �̐ݒ�͈�x�ݒ肷����̌ジ���ƗL���ł����A[�v���W�F�N�g�̐ݒ�] �̓v���W�F�N�g���Ƃɐݒ���s���K�v������܂��B�܂�A�v���W�F�N�g�̐ݒ�͐V�����p�b�P�[�W���J�����тɐݒ�����܂��B�t�@�C�����lj��ɂȂ�܂����Ȃǂƌ����čX�V�p�b�P�[�W��������Ƃ����A�c�O�Ȃ���A�ݒ����蒼���Ȃ���Ȃ�܂���B
�ł́A����̑O�҂ł͂��̃v���W�F�N�g�̐ݒ�����Ă����܂��B
�t���O�����g��v
�ݒ�̏ꏊ: [����y�A] > [���ׂĂ̌���y�A] > [�|�����Ǝ����|��] > [����] > [upLIFT �p�̃t���O�����g��v�̃I�v�V����]
�t���O�����g��v�̋@�\�͊���ŗL���ł����A�ꕔ�����ɂȂ��Ă���I�v�V����������܂��B�t���O�����g��v�� upLIFT �̏ڍׂɂ��ẮA�ȑO�̋L���u�t���O�����g��v�Ɋւ���ݒ��v��ATrados �̌����u���O���Q�Ƃ��Ă��������B
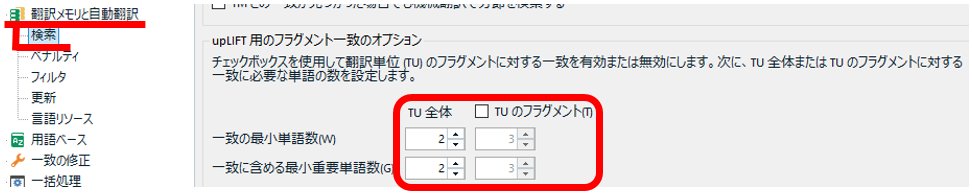
��}�� [TU �̃t���O�����g] ���I���ɂ��܂��B������I���ɂ���ƁA���ߑS�̂ł͂Ȃ��A���̒P�ʂŃ}�b�`�����o�����̂ŁA[�t���O�����g��v] �E�B���h�E�ɕ\�������}�b�`�������Ȃ�܂��B[�t���O�����g��v] �E�B���h�E�ɕ\�����ꂽ���́A�V���[�g�J�b�g �L�[ Ctrl+Alt+M �Ŗɑ}���ł��܂��B
�P�ꐔ�̃t�B�[���h�́A��L�̌����u���O�̐����ɏ]���Ăǂ�����u2�v�ɐݒ肵�܂��B���܂�Ƀ}�b�`�������\�������悤�Ȃ�u3�v�ɕύX���܂��B������傫������ƃ}�b�`������܂��B
�Œ�v�f���u�F���v����
�ݒ�̏ꏊ: [����y�A] > [���ׂĂ̌���y�A] > [�|�����Ǝ����|��]�A��������I������ [�ݒ�] > [���ꃊ�\�[�X] > [����F������]
�u�Œ�v�f�v�Ƃ́A�����A���t�A�啶���̉p�P��Ȃǂ̂��Ƃł��B�u�F���ς݃g�[�N���v�ƌĂ�邱�Ƃ�����܂��B���ɂƂ��ẮATrados �̒��ł悭�킩��Ȃ��@�\�̃g�b�v�ɂ�������̂ł����A�����F���Ƃ��A�����u���Ƃ��A QuickPlace (�V���[�g�J�b�g �L�[�� Ctrl+Alt+�����܂��� Ctrl+�J���}) �Ƃ��A�J��Ԃ������Ƃ��A���낢��ȂƂ���ɉe������̂Œ��ӂ��K�v�ł��B�ڍׂɂ��ẮA�����w���v�́u�Œ�v�f�v���Q�Ƃ��Ă��������B(�����A�Q�Ƃ��Ă��悭�킩��܂���B)
�Œ�v�f�̐ݒ�� 2 �i�K�ōs���܂��B�ŏ��Ɂu�F���v��L���ɂ��A���̌�Łu�u���v��L���ɂ��܂��B�ł́A�܂��u�F���v��L���ɂ�����@�ł��B
�G�f�B�^�[�̌����ŁA��������t�ȂǂɐF�̉�����������Ă��邱�Ƃ�����Ǝv���܂��B���ꂪ�A�Œ�v�f���u�F������Ă���v��Ԃł��B�F�����ꂽ�v�f�́AQuickPlace �@�\ (�V���[�g�J�b�g �L�[�� Ctrl+Alt+�����܂��� Ctrl+�J���}) �ŖɃR�s�[�ł��܂��B
�F����L���ɂ���ݒ�́A�������ɕt������u���ꃊ�\�[�X�v�ōs���܂��B�������̐ݒ��ʂ� [���ꃊ�\�[�X] �� [����F������] �̊e�`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA���ꂼ��̗v�f���F�������悤�ɂȂ�܂��B

�Œ�v�f���u�u���v����
�ݒ�̏ꏊ: [����y�A] > [����̌���y�A] > [�|�����Ǝ����|��] > [�����u��]
�ł͎��ɁA�F�����ꂽ�Œ�v�f�́u�u���v��L���ɂ���ݒ���s���܂��B����́A���t��ʉ݂Ȃǂ̌`���������I�ɕϊ����Ă����@�\�ł��B�ڍׂɂ��ẮA�����w���v�� [�|�����Ǝ����|��] > [�����u��] ���Q�Ƃ��Ă��������B
�u���̐ݒ�́A[���ׂĂ̌���y�A] �ł͂Ȃ��AJapanese->English �ȂǁA����̌���y�A�ōs���܂��B���t��ʉ݂̌`���͌���Ɉˑ�����̂ŁA���ꂲ�Ƃɐݒ肷��K�v������܂��B�ȉ��� [�����u��] �y�[�W�ɕ\������鍀�ڂ̃`�F�b�N�{�b�N�X���I���ɂ���ƁA���ꂼ��̗v�f�̒u�����L���ɂȂ�܂��B
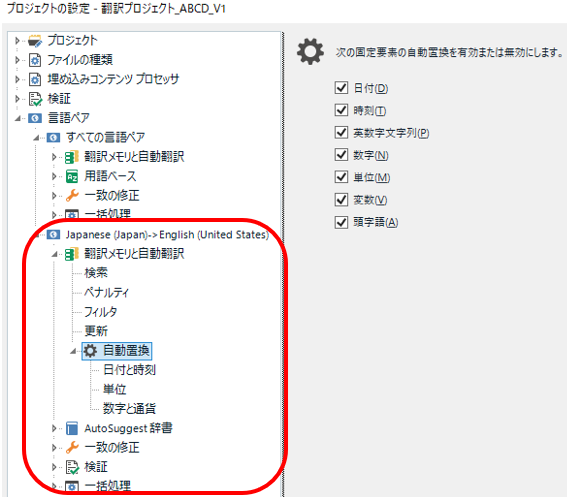
�����A�����u���̓���͂��܂�M�p�ł��Ȃ��̂ŁA�����S�ȕ��@���Ƃ�Ȃ�u�F���͗L���A�u���͖����v�Ɛݒ肷��̂��悢�Ǝv���܂��B�F����L���ɂ��ĐF�̉�����������Ă���A�u���͖����ł� QuickPlace �@�\�̃V���[�g�J�b�g �L�[�œ��͂��\�ł��B
���́A���͍���̋L���������Ă��ď��߂Ă��̒u���ݒ�y�[�W�̑��݂ɋC�Â��܂����B�ȑO���J��Ԃ������̋L���ł��Œ�v�f�ɂ��Ă͐������Ă��܂����A���̎����u���̗L��/�����͂������蔲�������Ă��܂��� (���݂܂���)�B�J��Ԃ������̓���ɂ����́u�F���v�Ɓu�u���v�� 2 �i�K�̐ݒ肪�e�����܂��B
���Ȃ݂ɁA���͖���u�F���v�Ɓu�u���v�̑S�`�F�b�N�{�b�N�X���I���ɂ��Ă��܂����A����͂����܂Ń^�C�s���O�����炷���߂ł��B�����āA�����Ŗ�����Ă��炨���Ƃ��Ă���킯�ł͂���܂���B�uWindows�v�� OS �ł͂Ȃ��ĕ����̃E�B���h�E��������Ȃ����A�uSW�v�̓X�C�b�`��������Ȃ����ǃ\�t�g�E�F�A��������Ȃ����A�u�o�[�W���� 100 �� 100 ���̃t�@�C���� 100 ���� 1 �̎��Ԃŏ�������v�݂����ȕ������邩������܂���B�����I�ȕϊ��͐M���ł��Ȃ��̂ł��ׂĊm�F���K�v�ł��B���̂��߁A�y�i���e�B�Ƃ̕��p�͕K�{�ł��B�����u����L���ɂ���ƃ}�b�`�����オ�����肵�܂����A����ŗ�������������ł���ƍl����̂͊ԈႢ�ł� (�Ǝ��͎v���Ă��܂�)�B�|���Б��ʼn�͂�����Ƃ��́u�����u���Ȃ��A�����u������Ȃ�y�i���e�B��t����v�������ł� (�Ǝ��͎v���Ă��܂�)�B
�u���̏ڍׂ�ݒ肷��
�ݒ�̏ꏊ: [����y�A] > [����̌���y�A] > [�|�����Ǝ����|��] > [�����u��]
(�K�v�ɉ����āA[����y�A] > [���ׂĂ̌���y�A] > [�|�����Ǝ����|��]�A��������I������ [�ݒ�] > [���ꃊ�\�[�X])
�����u���̐ݒ��ʂɂ́A[���t�Ǝ���]�A[�P��]�A[�����ƒʉ�] �� 3 ���p�ӂ���Ă��܂��B�����ł́A[���t�Ǝ���] �ɂ��Ă��������������Ǝv���܂��B[�P��] �ɂ��ẮA�ȑO�̋L���u�P�ʋL���̑O�ɃX�y�[�X�������v���Q�Ƃ��Ă��������B[�����ƒʉ�] �ɂ��ẮA���݂܂���A�悭�킩��Ȃ����Ƃ��炯�Ȃ̂ō���͏ȗ����܂��B
���t�Ǝ����́A�ȉ��̉�ʂŌ`����ݒ�ł��܂��B�X�^�C���K�C�h�Ȃǂ��m�F���āA�K�Ȍ`����I�т܂��B�����A�����u���͌������������`���œ��͂�����Ă��Ȃ��ƓK�ɋ@�\���܂���B���Ɠ������A�܂��͓������A�Ƃ����悤�ȏꍇ�͔F�����ꂸ�A�u��������܂���B
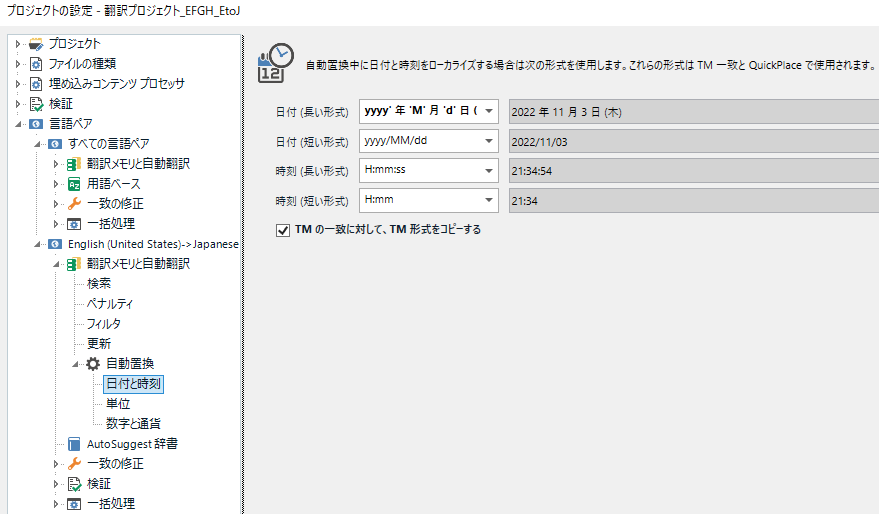
���̐ݒ��ʂ̃h���b�v�_�E���ɕ\�������I�v�V�����͎����Őݒ肪�\�ł��B���Ƃ��A[���t (�����`��)] �ɂ͂��Ȃ肽������̃I�v�V����������܂����A�X�^�C���K�C�h���u�S�p�Ɣ��p�̊ԂɃX�y�[�X������v�Ƃ������[���̏ꍇ�A����ɍ������I�v�V�����͂���܂���B
���̃��[���ɂ������I�v�V�������쐬����ɂ́A�������̌��ꃊ�\�[�X�̐ݒ�ɖ߂�܂��B

���̕\���� [���t] �� [���{��] ���N���b�N���ĕҏW��ʂ��J���܂��B�����ŁA�K�v�Ȍ`����lj����܂��Byyyy �Ȃǂ̗v�f���e�Ƀv�����v�g����Ă���̂ŁA�����g�ݍ��킹�Ă����ΐݒ�ł��܂��B
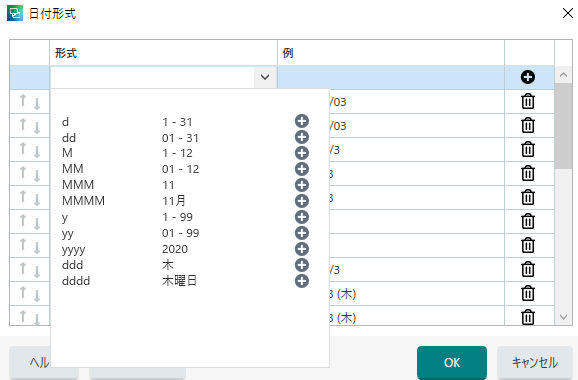
�u�S�p�Ɣ��p�̊ԂɃX�y�[�X������v�Ƃ������[���̏ꍇ�́A�ȉ���ݒ肵�܂� (�R�s�y�ł��܂�)�B
yyyy' �N 'M' �� 'd' �� ('ddd')'
����ŁA��قǂ̎����u���̐ݒ��ʂɖ߂�ƁA�lj������`�����h���b�v�_�E���ɕ\�������悤�ɂȂ�܂��B
�܂Ƃ�
�u�v���W�F�N�g�̐ݒ�v�Ń^�C�s���O�����炷���߂̋@�\�̐����͈ȏ�ł��B�Ō�ɁA�܂Ƃ߂Ƃ��Ă��������ӓ_�������Ă����܂��B�Œ�v�f�̔F����u���́A���̌o����A�Ȃ����ݒ肪���܂������Ȃ����Ƃ������ł��B�K����������Ƃ͌���܂��A�����̂Ƃ��̎Q�l�ɂ��Ă��������B
���ꃊ�\�[�X�� 1 �ԏ�ɂ��郁�����Őݒ肷��
���ꃊ�\�[�X�̐ݒ�̓������ɕt�����܂����A�v���W�F�N�g�ɂ͕����̃��������ݒ肳��Ă��邱�Ƃ�����܂��B���̏ꍇ�́A�������̃��X�g�� 1 �ԏ�ɕ\������Ă��郁�����Őݒ���s���Ă��������B���Ԃ�A1 �ԏ�̃������̐ݒ肪�D��I�Ɏg���Ă���Ǝv���܂��B(���݂܂���A�����܂ŁA���̌o�����ł��B)
�������A�|���Ђ�������T�[�o�[ TM �̌��ꃊ�\�[�X�͖|��ґ��ł͐ݒ��ύX�ł��܂���B���̂��߁A������p�b�P�[�W�ŃT�[�o�[ TM �� 1 �ԏ�ɐݒ肳��Ă���ꍇ�͏����Ή��ɍ���܂��B�����悭�s����́u����̃������� 1 �ԏ�ɒlj�����v�ł����A����ɂ�����|��t�@�C�����J���Ȃ��Ȃ������Ƃ�����܂��B�������̏��Ԃ�ς���ƁA�}�b�`�̗D��x���ς��̂ŁA���̕ӂ�����ӂ��K�v�ł��B
����̌���y�A�̐ݒ肪�D�悳���
��L�̐����ł́A�u���ׂĂ̌���y�A�v�Ɓu����̌���y�A�v�̐ݒ���g�p���Ă��܂����A������v���W�F�N�g�̏ꍇ�Łu����̌���y�A�v�Ɋ��ɉ��炩�̐ݒ肪����Ă���ꍇ�́u���ׂĂ̌���y�A�v���u����̌���y�A�v�̐ݒ肪�D�悳��܂��B���̂��߁A�����Őݒ��ύX����Ƃ����A�u����̌���y�A�v�Őݒ��ύX����K�v������܂��B�ڍׂɂ��ẮA�ȑO�̋L���u�ŋ߂� Trados �̃��i: ���������q�b�g���Ă��Ȃ��v���Q�Ƃ��Ă��������B
�ݒ��ς�����A�G�f�B�^�[������������āA�J������
�Œ�v�f�Ȃǂ̃������̐ݒ�́A�ݒ��ʂŕύX�����Ă��A�����ɓ��삪�ς��Ȃ����Ƃ�����܂��B���́A�ݒ肪���܂��ł��Ă��Ȃ��̂ł͂Ȃ����Ǝv���āA������m�F��ύX�����Ă������Ƃ�����܂��B����ȂƂ��͂�������G�f�B�^�[��ʂ���āA���߂Ė|��t�@�C�����J�������Ɠ��삪�ς�邱�Ƃ�����܂��B
���������A�b�v�O���[�h����H�H
���ꃊ�\�[�X�̐ݒ��ύX����ƁA�������ɃA�b�v�O���[�h�𑣂��x���}�[�N���\������܂��B�A�b�v�O���[�h���Ȃ��Ă�����ɋ@�\���Ă���悤�Ɍ����܂����A�Ƃɂ��������ł��ݒ��ύX����ƌx���}�[�N���t���܂��B�A�b�v�O���[�h�̏����̓��������傫���Ƃ��Ȃ莞�Ԃ�������̂ŁA���͂��낢��ݒ肵�Ă���A�Ō�ɔO�̂��߃A�b�v�O���[�h����悤�ɂ��Ă��܂��B
�ȏ�ł��B�ƂĂ��Ȃ������Ȃ��Ă��܂��܂����B�u�^�C�s���O�����炷���߂ɂǂꂾ���ݒ肪�K�v�Ȃ�I�v�Ƃ��������ł����A������p�b�P�[�W����邽�тɍs���K�v������܂��B�͂����肢���Ėʓ|�ł��B�ƂĂ��ʓ|�ł��B�ł����AAutoHotkey �ȂǑ��̎�i�ł��ׂĎ������悤�Ƃ���ƁA���������̂ŁA�Ƃ肠������ Trados ����̐ݒ�ɗ����Ă��܂��B����́A�v���W�F�N�g�̐ݒ�ł͂Ȃ��A�G�f�B�^�[�̐ݒ�����グ�܂��B������́A�v���W�F�N�g���Ƃɐݒ肷��K�v���Ȃ��A��ł����y��������܂���B
| �@�@ |