


2022�N09��30��
�J��Ԃ������Ƀ������͕s�v
���炭�X�V�����Ă���܂����B����́A�J��Ԃ��̏������ڂ������Ă��������Ǝv���܂��B�J��Ԃ���镶�������I�ɏ������邱�Ƃ͖|�����̑�\�I�ȋ@�\�̂悤�Ɏv���܂����ATrados �Ɍ����Ă����A�J��Ԃ��̏����Ƀ������͕s�v�ł��B���������Ȃ��Ă��A�G�f�B�^�̋@�\�����ŌJ��Ԃ��͎��������ł��܂��B
���������͂ł���̂ł����A���́u�����v�Ƃ����̂���������ł��B���ۂɍ�Ƃ����Ă���ƁA�������z�肵�Ă���u�����v�ƈ���Ȣf�����Ƃ��悭����܂��B����́A���̎�������ɉe����^���Ă���ݒ���������Љ�܂��B
�܂��A�J��Ԃ������̊�{�I�Ȑݒ�� [�t�@�C��] > [�I�v�V����] > [�G�f�B�^] > [�������f] �ōs���܂��B����ɂ��ẮA�ȑO�̋L���uCAT �c�[����r�F�J��Ԃ��̎��������v���Q�Ƃ��Ă��������B����́A����ȊO�̐ݒ�Ŏ������f�̓���ɉe����^������̂���Ɏ��グ�܂��B
�ŏ��ɏ������悤�ɁA�J��Ԃ��̎������f�Ƀ������͕s�v�ł��B�v���W�F�N�g�Ƀ������� 1 ���ݒ肵�Ă��Ȃ��Ă��A�ȉ��̂悤�Ɏ������f�͍s���܂��B
�������A���������Ȃ��Ă��A�������̐ݒ�͎g���܂��B���̕ӂ肪 Trados �̂悭�킩��Ȃ��Ƃ���ł����A�������ɂ͂��낢��Əd�v�Ȑݒ肪�������A���ꂪ�g���܂��B
�g����ݒ�́A�������� [�ݒ�] ����ݒ肷��u���ꃊ�\�[�X�v�ƁA�v���W�F�N�g�ݒ�� [�|�����Ǝ����|��] ����ݒ肷��u�y�i���e�B�v�ł��B�ǂ�����A�{���̓������̂��߂̐ݒ�ł���A�J��Ԃ��̎������f�̂��߂̐ݒ�ł͂���܂��A�����̐ݒ肪�������f�̓���ɉe����^���܂��B
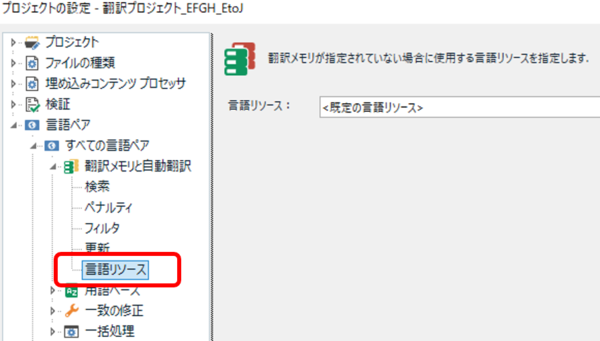
�ł́A���ꃊ�\�[�X�̐ݒ肩�猩�Ă����܂��B���̐ݒ�̓������ɕt��������̂ł����A���}�̂悤�ɁA�������� 1 ���w�肵�Ă��Ȃ��v���W�F�N�g�ł́u����̌��ꃊ�\�[�X�v���g�p����܂��B
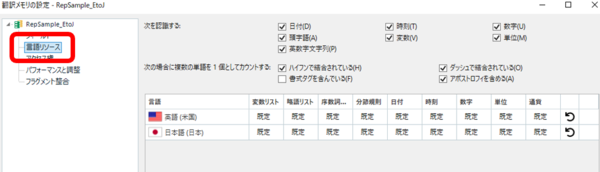
�v���W�F�N�g�Ƀ�������ݒ肵���ꍇ�́A���̃������� [�ݒ�] ��ʂ���ȉ��̂悤�Ȑݒ肪�\�ɂȂ�܂��B
����́A���ꃊ�\�[�X�̐ݒ�̂��߂Ƀ_�~�[�̃������� 1 �ݒ肵�܂����B�����炭�A���ꃊ�\�[�X�ڕҏW���邱�Ƃ��\�ł��傤���A���ꃊ�\�[�X���ǂ��ҏW����̂��Ƃ��A�v���W�F�N�g���������ɕҏW���Ă����̕ύX�͔��f�����̂��Ƃ��A�p�b�P�[�W��������ꍇ�͂ǂ��Ȃ�̂��Ƃ��A���낢��l���邱�Ƃ������Ȃ肻���Ȃ̂Ń_�~�[�̃��������g�����Ƃɂ��܂����B�������A�������Ƃ� 100% ��v����������ƌ����ʓ|�ɂȂ�̂ŁA����� [�X�V] �`�F�b�N�{�b�N�X���I�t�ɂ��ă��������o�^����Ȃ��悤�ɂ��Ă��܂��B
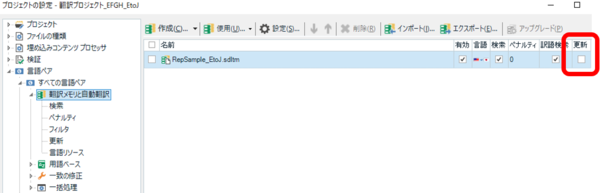
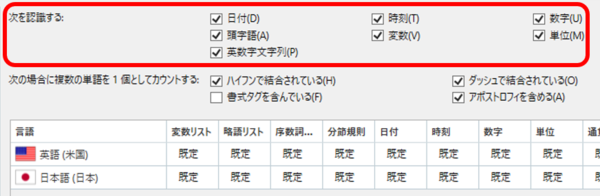
���āA���ꃊ�\�[�X�̐ݒ�Œ��ӂ���̂� [����F������] �ł��B�����Ń`�F�b�N�{�b�N�X���I���ɂȂ��Ă��Ȃ��ƌJ��Ԃ��̎������f�ł��F��������܂���B�����ɕ\������Ă���u���t�v�u������v�u�ϐ��v�u�p����������v�̏ڍׂɂ��ẮATrados �̃w���v�u�����u���̗��v���Q�Ƃ��Ă��������B�����A���̑��̍��ڂ��܂߁A�����u���̓���͂Ȃ��Ȃ����G�ł悭�킩��Ȃ����Ƃ���������܂��B�{���ɂ悭�킩��Ȃ��̂ŁA���݂܂���A����͐����Ɠ����ꂾ���ɒ��ڂ������Ǝv���܂��B������́A�ȒP�ɂ����Ɓu�啶���̉p���̂݁v�ō\�������P��ł��B
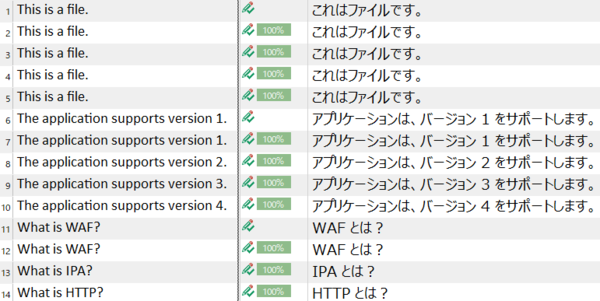
���Ƃ��A[����] �� [������] �̃`�F�b�N�{�b�N�X���I�t�ɂ���ƁA�������f�̌��ʂ͈ȉ��̂悤�ɂȂ�܂��B
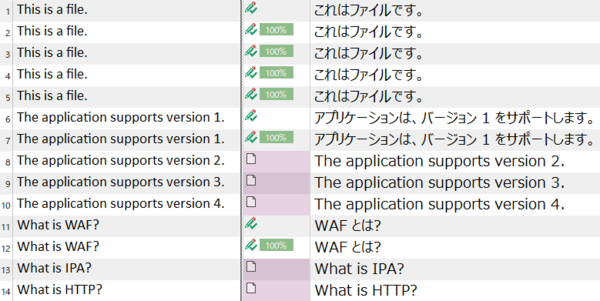
���� 6 �` 10 �͐����̗�ł��B������F�����Ȃ��ݒ�̏ꍇ�A���� 6 �� 7 �͂܂���������Ȃ̂ł���ł��J��Ԃ��ƌ��Ȃ���܂����A���� 8 �` 10 �͌J��Ԃ��ɂȂ�܂���B���� 11 �` 14 �͓�����̗�ł��B�������������F�����Ȃ��ݒ�ɂ��Ă���ƁA�܂���������łȂ�����J��Ԃ��ɂȂ�܂���B
�F�����Ȃ��ݒ�ɂ���ƁA�ނ�݂Ɏ������f����邱�Ƃ��Ȃ��̂ň��S�ɂ͂Ȃ�܂����A�����ɂ����ĕs�ւł��B���̐ݒ�́A�J��Ԃ��̎������f�����łȂ��A�������Ƃ̃}�b�`�� QuickPlace �@�\ (�V���[�g�J�b�g �L�[�� Ctrl+Alt+�����܂��� Ctrl+�J���}) �ɂ��e�����܂��B���[�h����}�b�`���ւ̉e���͗v�����ł����A���͎��̕��ׂ������l����A��������F�����Ă��ꂽ����������܂��B
�Ƃ����킯�ŁA���͂������ׂẴ`�F�b�N�{�b�N�X���I���ɂ��č�Ƃ��Ă��܂��B�������A�������Ă���ƌJ��Ԃ����������Ɏ������f����Ă��܂��̂ŁA�����h�����߂̎�i�͕K�v�ł��B
�����]�k�ł����A�v���W�F�N�g�� [�|�����Ǝ����|��] �̐ݒ��A�������� [�ݒ�] ����s���ݒ�́A���f�����^�C�~���O�����͂悭�킩��܂���B[����F������] �̃`�F�b�N�{�b�N�X���I���ɂ��Ă��F������Ȃ�������A�t�ɁA�I�t�ɂ��Ă���̂ɔF�����ꂽ�肵�܂��B�����������Ă݂����ʂƂ��ẮA�ݒ��������A�G�f�B�^�ł�������t�@�C������A���߂ĊJ�������Ɛݒ肪���f�����悤�ȋC�����Ă��܂��B����̋L�����������߂ɂ��낢�뎎�����̂ł����A���Ȃ荬�����܂����B
������������ �NjL 2022/12/14 ��������������������������������������������������������
��L�ł́A[����F������] �̃`�F�b�N�{�b�N�X�ɂ��Ă����L�q���Ă��܂���ł������A���� [�����u��] �̃`�F�b�N�{�b�N�X�������ăI���ɂ���K�v������܂����B���݂܂���A[�����u��] �̑��݂ɂ܂������C�Â��Ă��܂���ł����B�ڍׂɂ��ẮA������̋L���u�^�C�s���O�����炻���v���Q�Ƃ��Ă��������B
������������������������������������������������������������������������������������
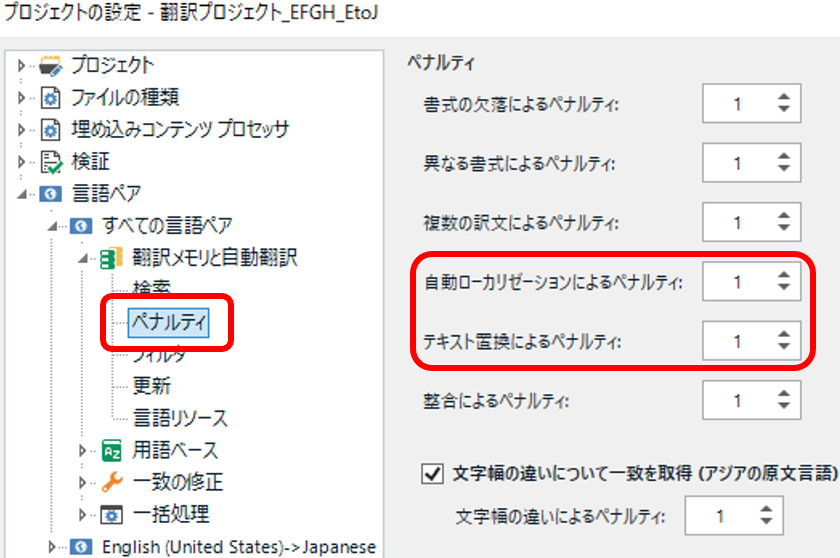
�ނ�݂Ȏ������f��h����i�� 1 �Ƃ��Ďg����̂��y�i���e�B�ł��B�ݒ肷��ꏊ�́A[�v���W�F�N�g�̐ݒ�] > [����y�A] > [���ׂĂ̌���y�A] > [�|�����Ǝ����|��] > [�y�i���e�B] �ł��B�y�i���e�B��ݒ肵�Ă����ƁA�}�b�`�����y�i���e�B�����������������܂��B�u1�v��ݒ肵�Ă����A100% �}�b�`�ł� 99% �ƌ��Ȃ����̂ł��܂��܂Ȏ��������̗\�h�ɂȂ�܂��B
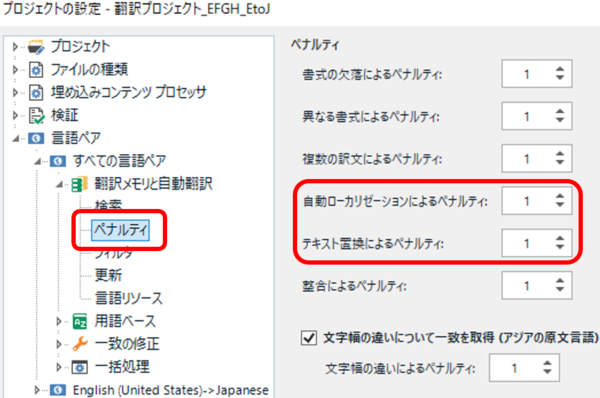
���ڂ���̂́A����Ń[���ɂȂ��Ă��� [�������[�J���[�[�V�����ɂ��y�i���e�B] �� [�e�L�X�g�u���ɂ��y�i���e�B] �� 2 �ł��B�ȒP�ɐ�������ƁA�u�������[�J���[�[�V�����v�͓��t�␔�l�̒u���A�u�e�L�X�g�u���v�͓������p����������̒u���ł��B�ڍׂɂ��ẮATrados �̃w���v�uTM �y�i���e�B�v���Q�Ƃ��Ă��������B
��ɐ����������ꃊ�\�[�X�Ő����Ɠ������F������ݒ�ɂ��Ă��Ă��A���� 2 �̃y�i���e�B���u1�v�ɐݒ肷��A�J��Ԃ��̎������f�͉��}�̂悤�ɐ�������܂��B�܂���������łȂ�����A�y�i���e�B�������̂� 100% �}�b�`�ɂȂ炸�������f�͂���܂���B
��L�̃y�i���e�B�́A���R�Ȃ���A�J��Ԃ��̎������f�����łȂ��A�������������͂���Ƃ��̓���ɉe�����܂��B���̂��߁A���͕K���S���ڂɁu1�v��ݒ肵�č�Ƃ��Ă��܂��B�����������������肷��Ǝ����u���̓���͐M�p�ł��Ȃ��̂ŁA�K���m�F����K�v������܂��B
�K���m�F����K�v�͂���̂ł����A�����������Ⴄ���߂����炸��ƕ��ԏꍇ�ȂǁA����ς莩�����f���Ăق����Ƃ��͂���܂��B���̏ꍇ�́A�ŏ��ɋ������G�f�B�^�̐ݒ��ς��܂��B
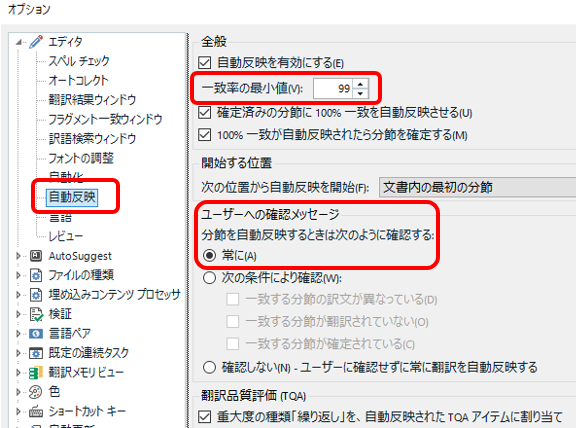
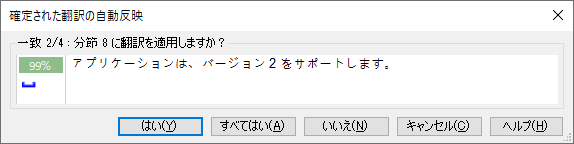
[��v���̍ŏ��l] ���u99�v�ɐݒ肵�A[���[�U�[�ւ̊m�F���b�Z�[�W] ���u��Ɂv�\�������悤�ɂ��܂��B����ŁA�y�i���e�B�������� 99% �}�b�`�ɂȂ��Ă��������f���s���A�m�F���b�Z�[�W������\�������悤�ɂȂ�܂��B
���ӓ_�Ƃ��āA��v���̍ŏ��l������������Ƃ��Ȃ�댯�ȓ���ɂȂ邱�Ƃ�S���Ă����Ă��������B�y�i���e�B�ł͂Ȃ��A�ʏ�̕����̈Ⴂ�� 99% �}�b�`�ɂȂ��Ă�����̂��������f�����̂ŁA����͂����܂ňꎞ�I�Ȑݒ�Ƃ��������ɂ��A�K�v�łȂ��Ȃ����炷���Ɍ��ɖ߂��܂��B
�m�F���b�Z�[�W�͉��}�̂悤�ɕ\������܂��B�u99%�v�̉��ɕ\������Ă���F�̃}�[�N�͎������[�J���[�[�V�����Œu�����s��ꂽ���Ƃ������Ă��܂��B(�������A�ǂ����u�����ꂽ�̂��͂킩��܂���B�����͎����Ŋm�F���邵������܂���B)
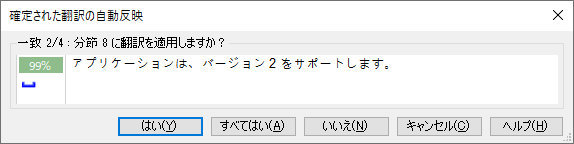
���̃��b�Z�[�W�͂��ׂĂ̌J��Ԃ��ɂ��Ė���\������܂����A�{���Ɋm�F���s�v�ȏꍇ�́A[���ׂĂ͂�] ���N���b�N���邱�Ƃň�C�Ɏ������f��K�p�ł��܂��B
�J��Ԃ��̎������f�Ɋւ���ݒ�̐����͈ȏ�ł��B�J��Ԃ��̏����Ƀ������͕s�v�ł����A�������̐ݒ�͎g����̂ł��낢��Ȓ��ӂ��K�v�ł��B
���́A�����Ă��ȉ��̂悤�ɐݒ肵�č�Ƃ��Ă��܂��B
�@�@���ꃊ�\�[�X
�@�@�@�@�E ���ׂĂ̍��ڂ�F������ (���ׂẴ`�F�b�N�{�b�N�X���I��)
�@�@�y�i���e�B
�@�@�@�@�E ���ׂĂ̍��ڂɁu1�v��ݒ肷��
�@�@�G�f�B�^
�@�@�@�@�E ��v���̍ŏ��l�́u100�v
�@�@�@�@�E �m�F���b�Z�[�W�́u��Ɂv�\������
��L�̂悤�ɐݒ肵���ꍇ�A�܂���������łȂ�����J��Ԃ��̎������f�͍s���܂���B�����A����͌��̂��߂Ƀ������̍X�V���I�t�ɂ��Ă��܂������A�ʏ�̓������ɖ�o�^���Ă���̂ŁA�J��Ԃ��Ƃ��Ď������f������Ȃ��Ă��A�������������͂ł��܂��B�ǂ����Ă��s�ւȏꍇ�́u��v���̍ŏ��l�v�����������܂����A����͊댯�Ȃ̂łނ�݂ɂ͍s���܂���B
����͈ȏ�ł��B�J��Ԃ������̐ݒ�͂��Ȃ蕡�G�ŁA���͍������s���낷�邱�Ƃ�����܂��B�J��Ԃ����قƂ�ǔ������Ȃ������������̂ŁA�ݒ肵�Ă͖Y��A�܂����낢�뎎���A�Ƃ������Ƃ��J��Ԃ��Ă��܂��B
Tweet
���������͂ł���̂ł����A���́u�����v�Ƃ����̂���������ł��B���ۂɍ�Ƃ����Ă���ƁA�������z�肵�Ă���u�����v�ƈ���Ȣf�����Ƃ��悭����܂��B����́A���̎�������ɉe����^���Ă���ݒ���������Љ�܂��B
�܂��A�J��Ԃ������̊�{�I�Ȑݒ�� [�t�@�C��] > [�I�v�V����] > [�G�f�B�^] > [�������f] �ōs���܂��B����ɂ��ẮA�ȑO�̋L���uCAT �c�[����r�F�J��Ԃ��̎��������v���Q�Ƃ��Ă��������B����́A����ȊO�̐ݒ�Ŏ������f�̓���ɉe����^������̂���Ɏ��グ�܂��B
�������͎g��Ȃ����A�������̐ݒ�͎g��
�ŏ��ɏ������悤�ɁA�J��Ԃ��̎������f�Ƀ������͕s�v�ł��B�v���W�F�N�g�Ƀ������� 1 ���ݒ肵�Ă��Ȃ��Ă��A�ȉ��̂悤�Ɏ������f�͍s���܂��B

�������A���������Ȃ��Ă��A�������̐ݒ�͎g���܂��B���̕ӂ肪 Trados �̂悭�킩��Ȃ��Ƃ���ł����A�������ɂ͂��낢��Əd�v�Ȑݒ肪�������A���ꂪ�g���܂��B
�g����ݒ�́A�������� [�ݒ�] ����ݒ肷��u���ꃊ�\�[�X�v�ƁA�v���W�F�N�g�ݒ�� [�|�����Ǝ����|��] ����ݒ肷��u�y�i���e�B�v�ł��B�ǂ�����A�{���̓������̂��߂̐ݒ�ł���A�J��Ԃ��̎������f�̂��߂̐ݒ�ł͂���܂��A�����̐ݒ肪�������f�̓���ɉe����^���܂��B
���ꃊ�\�[�X
�ł́A���ꃊ�\�[�X�̐ݒ肩�猩�Ă����܂��B���̐ݒ�̓������ɕt��������̂ł����A���}�̂悤�ɁA�������� 1 ���w�肵�Ă��Ȃ��v���W�F�N�g�ł́u����̌��ꃊ�\�[�X�v���g�p����܂��B

�v���W�F�N�g�Ƀ�������ݒ肵���ꍇ�́A���̃������� [�ݒ�] ��ʂ���ȉ��̂悤�Ȑݒ肪�\�ɂȂ�܂��B

����́A���ꃊ�\�[�X�̐ݒ�̂��߂Ƀ_�~�[�̃������� 1 �ݒ肵�܂����B�����炭�A���ꃊ�\�[�X�ڕҏW���邱�Ƃ��\�ł��傤���A���ꃊ�\�[�X���ǂ��ҏW����̂��Ƃ��A�v���W�F�N�g���������ɕҏW���Ă����̕ύX�͔��f�����̂��Ƃ��A�p�b�P�[�W��������ꍇ�͂ǂ��Ȃ�̂��Ƃ��A���낢��l���邱�Ƃ������Ȃ肻���Ȃ̂Ń_�~�[�̃��������g�����Ƃɂ��܂����B�������A�������Ƃ� 100% ��v����������ƌ����ʓ|�ɂȂ�̂ŁA����� [�X�V] �`�F�b�N�{�b�N�X���I�t�ɂ��ă��������o�^����Ȃ��悤�ɂ��Ă��܂��B

���āA���ꃊ�\�[�X�̐ݒ�Œ��ӂ���̂� [����F������] �ł��B�����Ń`�F�b�N�{�b�N�X���I���ɂȂ��Ă��Ȃ��ƌJ��Ԃ��̎������f�ł��F��������܂���B�����ɕ\������Ă���u���t�v�u������v�u�ϐ��v�u�p����������v�̏ڍׂɂ��ẮATrados �̃w���v�u�����u���̗��v���Q�Ƃ��Ă��������B�����A���̑��̍��ڂ��܂߁A�����u���̓���͂Ȃ��Ȃ����G�ł悭�킩��Ȃ����Ƃ���������܂��B�{���ɂ悭�킩��Ȃ��̂ŁA���݂܂���A����͐����Ɠ����ꂾ���ɒ��ڂ������Ǝv���܂��B������́A�ȒP�ɂ����Ɓu�啶���̉p���̂݁v�ō\�������P��ł��B

���Ƃ��A[����] �� [������] �̃`�F�b�N�{�b�N�X���I�t�ɂ���ƁA�������f�̌��ʂ͈ȉ��̂悤�ɂȂ�܂��B
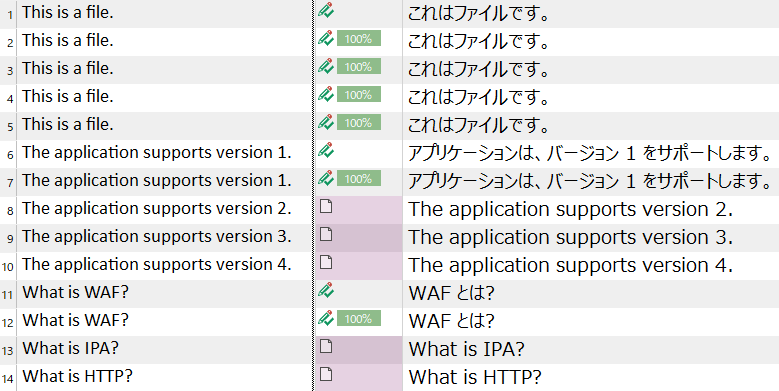
���� 6 �` 10 �͐����̗�ł��B������F�����Ȃ��ݒ�̏ꍇ�A���� 6 �� 7 �͂܂���������Ȃ̂ł���ł��J��Ԃ��ƌ��Ȃ���܂����A���� 8 �` 10 �͌J��Ԃ��ɂȂ�܂���B���� 11 �` 14 �͓�����̗�ł��B�������������F�����Ȃ��ݒ�ɂ��Ă���ƁA�܂���������łȂ�����J��Ԃ��ɂȂ�܂���B
�F�����Ȃ��ݒ�ɂ���ƁA�ނ�݂Ɏ������f����邱�Ƃ��Ȃ��̂ň��S�ɂ͂Ȃ�܂����A�����ɂ����ĕs�ւł��B���̐ݒ�́A�J��Ԃ��̎������f�����łȂ��A�������Ƃ̃}�b�`�� QuickPlace �@�\ (�V���[�g�J�b�g �L�[�� Ctrl+Alt+�����܂��� Ctrl+�J���}) �ɂ��e�����܂��B���[�h����}�b�`���ւ̉e���͗v�����ł����A���͎��̕��ׂ������l����A��������F�����Ă��ꂽ����������܂��B
�Ƃ����킯�ŁA���͂������ׂẴ`�F�b�N�{�b�N�X���I���ɂ��č�Ƃ��Ă��܂��B�������A�������Ă���ƌJ��Ԃ����������Ɏ������f����Ă��܂��̂ŁA�����h�����߂̎�i�͕K�v�ł��B
�����]�k�ł����A�v���W�F�N�g�� [�|�����Ǝ����|��] �̐ݒ��A�������� [�ݒ�] ����s���ݒ�́A���f�����^�C�~���O�����͂悭�킩��܂���B[����F������] �̃`�F�b�N�{�b�N�X���I���ɂ��Ă��F������Ȃ�������A�t�ɁA�I�t�ɂ��Ă���̂ɔF�����ꂽ�肵�܂��B�����������Ă݂����ʂƂ��ẮA�ݒ��������A�G�f�B�^�ł�������t�@�C������A���߂ĊJ�������Ɛݒ肪���f�����悤�ȋC�����Ă��܂��B����̋L�����������߂ɂ��낢�뎎�����̂ł����A���Ȃ荬�����܂����B
������������ �NjL 2022/12/14 ��������������������������������������������������������
��L�ł́A[����F������] �̃`�F�b�N�{�b�N�X�ɂ��Ă����L�q���Ă��܂���ł������A���� [�����u��] �̃`�F�b�N�{�b�N�X�������ăI���ɂ���K�v������܂����B���݂܂���A[�����u��] �̑��݂ɂ܂������C�Â��Ă��܂���ł����B�ڍׂɂ��ẮA������̋L���u�^�C�s���O�����炻���v���Q�Ƃ��Ă��������B
������������������������������������������������������������������������������������
�y�i���e�B
�ނ�݂Ȏ������f��h����i�� 1 �Ƃ��Ďg����̂��y�i���e�B�ł��B�ݒ肷��ꏊ�́A[�v���W�F�N�g�̐ݒ�] > [����y�A] > [���ׂĂ̌���y�A] > [�|�����Ǝ����|��] > [�y�i���e�B] �ł��B�y�i���e�B��ݒ肵�Ă����ƁA�}�b�`�����y�i���e�B�����������������܂��B�u1�v��ݒ肵�Ă����A100% �}�b�`�ł� 99% �ƌ��Ȃ����̂ł��܂��܂Ȏ��������̗\�h�ɂȂ�܂��B
���ڂ���̂́A����Ń[���ɂȂ��Ă��� [�������[�J���[�[�V�����ɂ��y�i���e�B] �� [�e�L�X�g�u���ɂ��y�i���e�B] �� 2 �ł��B�ȒP�ɐ�������ƁA�u�������[�J���[�[�V�����v�͓��t�␔�l�̒u���A�u�e�L�X�g�u���v�͓������p����������̒u���ł��B�ڍׂɂ��ẮATrados �̃w���v�uTM �y�i���e�B�v���Q�Ƃ��Ă��������B
��ɐ����������ꃊ�\�[�X�Ő����Ɠ������F������ݒ�ɂ��Ă��Ă��A���� 2 �̃y�i���e�B���u1�v�ɐݒ肷��A�J��Ԃ��̎������f�͉��}�̂悤�ɐ�������܂��B�܂���������łȂ�����A�y�i���e�B�������̂� 100% �}�b�`�ɂȂ炸�������f�͂���܂���B
�ł��A����ς莩�����f������
��L�̃y�i���e�B�́A���R�Ȃ���A�J��Ԃ��̎������f�����łȂ��A�������������͂���Ƃ��̓���ɉe�����܂��B���̂��߁A���͕K���S���ڂɁu1�v��ݒ肵�č�Ƃ��Ă��܂��B�����������������肷��Ǝ����u���̓���͐M�p�ł��Ȃ��̂ŁA�K���m�F����K�v������܂��B
�K���m�F����K�v�͂���̂ł����A�����������Ⴄ���߂����炸��ƕ��ԏꍇ�ȂǁA����ς莩�����f���Ăق����Ƃ��͂���܂��B���̏ꍇ�́A�ŏ��ɋ������G�f�B�^�̐ݒ��ς��܂��B

[��v���̍ŏ��l] ���u99�v�ɐݒ肵�A[���[�U�[�ւ̊m�F���b�Z�[�W] ���u��Ɂv�\�������悤�ɂ��܂��B����ŁA�y�i���e�B�������� 99% �}�b�`�ɂȂ��Ă��������f���s���A�m�F���b�Z�[�W������\�������悤�ɂȂ�܂��B
���ӓ_�Ƃ��āA��v���̍ŏ��l������������Ƃ��Ȃ�댯�ȓ���ɂȂ邱�Ƃ�S���Ă����Ă��������B�y�i���e�B�ł͂Ȃ��A�ʏ�̕����̈Ⴂ�� 99% �}�b�`�ɂȂ��Ă�����̂��������f�����̂ŁA����͂����܂ňꎞ�I�Ȑݒ�Ƃ��������ɂ��A�K�v�łȂ��Ȃ����炷���Ɍ��ɖ߂��܂��B
�m�F���b�Z�[�W�͉��}�̂悤�ɕ\������܂��B�u99%�v�̉��ɕ\������Ă���F�̃}�[�N�͎������[�J���[�[�V�����Œu�����s��ꂽ���Ƃ������Ă��܂��B(�������A�ǂ����u�����ꂽ�̂��͂킩��܂���B�����͎����Ŋm�F���邵������܂���B)
���̃��b�Z�[�W�͂��ׂĂ̌J��Ԃ��ɂ��Ė���\������܂����A�{���Ɋm�F���s�v�ȏꍇ�́A[���ׂĂ͂�] ���N���b�N���邱�Ƃň�C�Ɏ������f��K�p�ł��܂��B
�ŁA���ǂǂ��ݒ肷������́H
�J��Ԃ��̎������f�Ɋւ���ݒ�̐����͈ȏ�ł��B�J��Ԃ��̏����Ƀ������͕s�v�ł����A�������̐ݒ�͎g����̂ł��낢��Ȓ��ӂ��K�v�ł��B
���́A�����Ă��ȉ��̂悤�ɐݒ肵�č�Ƃ��Ă��܂��B
�@�@���ꃊ�\�[�X
�@�@�@�@�E ���ׂĂ̍��ڂ�F������ (���ׂẴ`�F�b�N�{�b�N�X���I��)
�@�@�y�i���e�B
�@�@�@�@�E ���ׂĂ̍��ڂɁu1�v��ݒ肷��
�@�@�G�f�B�^
�@�@�@�@�E ��v���̍ŏ��l�́u100�v
�@�@�@�@�E �m�F���b�Z�[�W�́u��Ɂv�\������
��L�̂悤�ɐݒ肵���ꍇ�A�܂���������łȂ�����J��Ԃ��̎������f�͍s���܂���B�����A����͌��̂��߂Ƀ������̍X�V���I�t�ɂ��Ă��܂������A�ʏ�̓������ɖ�o�^���Ă���̂ŁA�J��Ԃ��Ƃ��Ď������f������Ȃ��Ă��A�������������͂ł��܂��B�ǂ����Ă��s�ւȏꍇ�́u��v���̍ŏ��l�v�����������܂����A����͊댯�Ȃ̂łނ�݂ɂ͍s���܂���B
����͈ȏ�ł��B�J��Ԃ������̐ݒ�͂��Ȃ蕡�G�ŁA���͍������s���낷�邱�Ƃ�����܂��B�J��Ԃ����قƂ�ǔ������Ȃ������������̂ŁA�ݒ肵�Ă͖Y��A�܂����낢�뎎���A�Ƃ������Ƃ��J��Ԃ��Ă��܂��B
| �@�@ |
���̋L���ւ̃R�����g
�R�����g������
���̋L���ւ̃g���b�N�o�b�NURL
https://fanblogs.jp/tb/11611694
���u���O�I�[�i�[�����F�����g���b�N�o�b�N�̂ݕ\������܂��B
���̋L���ւ̃g���b�N�o�b�N