


���͂����� Xbench �̖����� (V2.9) ���g���Ă��܂����A�����łň�Ԏc�O�Ȃ̂� QA �`�F�b�N�� CamelCase Mismatch �� ALLUPPER CASE Mismatch ��L���ɂł��Ȃ����Ƃł��B�L���ł� V3 �ȍ~�ł͗L���ɂł���炵���ł����AV2.9 �ł� DISABLED �ƕ\������邾���ŁA�����L���ɂ���I�v�V����������܂���B���̃`�F�b�N�́A�啶���̒P�� (WAF �� HTTP �Ȃ�) �ƃL�������P�[�X�̒P�� (GetStatus �� SetTranslationMemory �Ȃ�) �������Ɩň�v���Ă��邩���m�F���Ă������̂��Ǝv���܂��B�p�P��́u�K����������R�s�[����v�Ƃ������[����O�ꂵ�Ă���ΊԈႤ�͂��͂Ȃ��̂ł����A����ł������Ă��܂����肷�邱�Ƃ�����̂ŁA���������`�F�b�N�͂ǂ����Ă��K�v�ɂȂ�܂��B
�����ŁA����͂��̃`�F�b�N�� Trados �� QA Checker ���g���čČ����邱�Ƃɒ��킵�܂��B���p�|��Ɖp���|��̗������ɂ��čČ�������@���l���Ă݂܂����B�ŁA�l���Ă݂��̂ō���͂��̕��@���Љ�܂����A���͂��܂肤�܂��@�\���Ȃ��P�[�X������܂��B�ǂ����Ă��댟�o�������Ă��܂��܂��B�����A���P�ĂȂǂ���܂�����A�����Ē�����Ɗ������ł��B
QA Checker �̐��K�\��
QA Checker �̏ڍׂɂ��ẮA�ȑO�̋L���u���K�\���Ȃ��ŁA���؋@�\���g���v���Q�Ƃ��Ă��������B���̋L���ł������Ă���Ƃ���AQA Checker �̐ݒ�̓t�@�C���ɃG�N�X�|�[�g���ĕۑ����Ă������Ƃ��ł��܂��B�����悤�ɁA���K�\���ɂ� [�A�N�V����] �̒��� [�A�C�e���̃G�N�X�|�[�g] �� [�A�C�e���̃C���|�[�g] ���p�ӂ���Ă��܂��B���̉�ʂ̃G�N�X�|�[�g�͐��K�\���݂̂��G�N�X�|�[�g���܂��B�܂��֗��ȓ_�Ƃ��āA���̉�ʂ̃C���|�[�g�͍폜�������A�lj��ƍX�V���������Ă���܂��B�܂�A�����̃A�C�e���͂��̂܂c��A�V�����A�C�e���͒lj�����A�����čX�V���ꂽ�A�C�e���͍X�V����܂��BQA Checker �S�̂̃v���t�@�C������C���|�[�g������ƁA������ւ��ɂȂ�̂ŌÂ��A�C�e���͍폜����܂��B

���{�� -> �p��̏ꍇ
���p�|��̏ꍇ�́A�啶����L�������P�[�X�ȂNJW�Ȃ��P���Ɂu�p�P����o���v�ƍl����悢�̂ŊȒP�ł��B
�p�P��
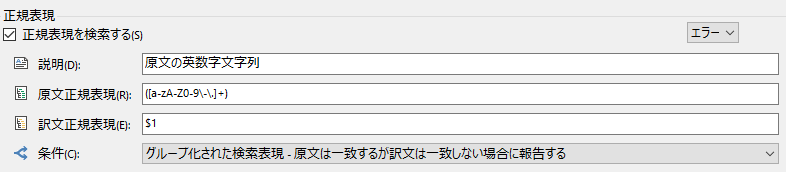
����:
([a-zA-Z0-9\-\.]+)��:
$1 ���́A�����A�n�C�t���A�s���I�h���܂߂ď�L�̂悤�ɐݒ肵�Ă��܂��B����ŁA�p��̏������A�啶���A�����A�n�C�t���A�s���I�h�ō\�������P����������璊�o�ł��܂��B��
$1 �́u������ ( ) ���Ƃ܂������������e�v�Ƃ������Ƃ��Ӗ����܂��B�������� CAT �����o���ꂽ��A�ł� CAT ��T���܂��B�S�p�̉p�P��
�����܂ł͊ȒP�ł����A���p�|��Ŗ��ɂȂ�̂͑S�p�ł��B���������{��̏ꍇ�A�p�������S�p�ŏ�����Ă��邱�Ƃ�����܂��B��L�̎��͑S�p�ɂ̓}�b�`���܂���B�����ŁA���͈ȉ��̎����lj����Ă��܂��B
����:
([��-���`-�y�O-�X]+)��:
$1����őS�p�̉p���������o�ł��܂��B���o�͂ł��܂����A��
$1 �͂��܂��@�\���܂���B�̉p��ł͉p�����͔��p�ɂ���̂ŁA�����̑S�p �b�`�s ��Ő��������p CAT �ɕϊ����Ă��Ă����ׂăG���[�Ƃ��Č��o����܂��B���S�̂��߂ɂ��̎����g���Ă͂��܂����A�댟�o�������Ȃ�܂��B�p�� -> ���{��̏ꍇ
�������p��̏ꍇ�́A���R�Ȃ��炷�ׂĂ��p�P��Ȃ̂ŏ�L�̂悤�ɒP���ɂ͂����܂���B�啶���ƃL�������P�[�X���w�肷��K�v������܂��B
�啶���ō\�������P��
�啶���͔�r�I�ȒP�ł��B���́A�n�C�t�����܂߂Ĉȉ��̂悤�Ɏw�肵�Ă��܂��B�u�啶�����n�C�t���� 2 ��ȏ�A������v�Ƃ����Ӗ��ł��B
����:
([A-Z\-]{2,})1 �����̉p����
��L�̏����́u2 ��ȏ�v�Ƃ����w��Ȃ̂� server A �Ȃǂɂ̓}�b�`���܂���B�����ŁA�p���� 1 ���������𒊏o���鎮���lj����܂��B
����:
(\b[\w\d]\b)\b �͒P��̎n�܂�܂��͏I���������܂��B\w �͉p�����A\d �͐����ł��B���̎��́u�P��̎n�܂肪�����āA�p������ 1 �����āA�P��̏I���ɂȂ�v�Ƃ��������ɂȂ�܂��B���͐������܂߂Ă��܂����A�����͐����`�F�b�N�̋@�\���ʂɂ���̂ł����Ɋ܂߂Ȃ��Ă� OK �ł��B�L�������P�[�X
���悢��L�������P�[�X�ł��B�������G�ɂȂ�܂��B���́A�l���Ă����畡�G�����Ă悭�킩��Ȃ��Ȃ����̂Łu�������n�܂�v�Ɓu�啶���n�܂�v�� 2 �ɕ����邱�Ƃɂ��܂����B
�E�������n�܂�L�������P�[�X (getTableStatus �Ȃ�)
����:
(\b[a-z]+\-*[A-Z]+[a-z\-]*)\b �͒P��̎n�܂�Ȃ̂Łu�������Ŏn�܂��āA�啶���� 1 ��ȏ�o�ꂵ�āA�܂�������������v�Ƃ��������ł��B�O�̂��߁A�n�C�t��������Ƃ������Ƃɂ��Ă��܂��B�E�啶���n�܂�L�������P�[�X (GetTableStatus �Ȃ�)
����:
(\b[A-Z]+\-*[a-z]+\-*[A-Z]+[\w\d\-]*)������́u�啶���Ŏn�܂��āA���������o�ꂵ�āA�܂��啶�����o�ꂷ��v�Ƃ��������ł��B�u�啶���Ŏn�܂��āA���������o�ꂷ��v�����ł́A�擪��啶���ɂ���ʏ�̕����ׂĂɈ�v���Ă��܂��̂ŁA2 �x�ڂ̑啶�����K�v�ł��B
�����ȊO�̑啶���n�܂� (This is a Windows server �Ȃ�)
�啶���̘A����L�������P�[�X�ł͂Ȃ��A�P�ɕ��̒��ő啶���Ŏn�܂�P����`�F�b�N�������ꍇ������܂��B�����A�p��̕��͒ʏ�啶���Ŏn�܂�̂ł��ꂪ�Ȃ��Ȃ���ςł��B�����̑啶���͒��o���Ȃ��悤�ɂ���K�v������܂��B
����:
^.+([A-Z]+\-*[a-z0-9]+\-*\b)�擪��
^ �͐��K�\���Łu�����v���Ӗ����܂��B���̎��́u�������牽����������������ɑ啶�����o�ꂷ��v�Ƃ��������ɂȂ�܂��B���݂܂���A������l���Ă݂͂����̂́A���Ȃ�댟�o�������Ȃ�܂��B�����ȊO�ɑ啶�����o�ꂷ�镶�͎��͂��Ȃ肠��܂��B���Ƃ��A���o���Ńw�b�h���C�� �X�^�C�����g���Ă���A���S�̂��ۊ��ʂň͂܂�Ă���ANote: �̂悤�ȃR�����̌�ɕ���������Ă���A�Ȃǂł��B���������P�[�X�����O���悤�Ƃ���ƂȂ��Ȃ��ʓ|�ł��B�����Ɩ����ւ��ă`�F�b�N����
���āA���낢��ȃ`�F�b�N�����Ă��A�R�}���h��v���p�e�B���Ȃǂ����ڂ� IT �n�����̂Ƃ��͉p�P��̋L�q�ɂǂ����Ă��s�����c��܂��B����ȂƂ��́A�����Ɩ����ւ��ă`�F�b�N�����Ă݂܂��B����͂��Ȃ�L���ł��B
Trados �̐��K�\���̈ꕔ�́u��������v�����̃`�F�b�N�����s���܂���B���K�\���̏������悭���Ă݂�Ɓu�O���[�v�����ꂽ�����\���v�͈ȉ��� 2 ��������������܂���B

��
$1 �ȂǂƋL�q����P�[�X���u�O���[�v�����ꂽ�����\���v�ɂ�����܂����A���̏ꍇ�͕K���������Ɍ�������K�v������܂��B����ȊO�̏ꍇ�́u�͈�v���邪�`�v��u�`�F�b�N�̂݁v���\�ł����A$1 �Ȃǂ��g���ꍇ�͂��ꂪ�ł��܂��� (���̉�ʏ�ł͂ǂ̏������I���ł��܂����A���҂ǂ���̓���ɂȂ�܂���)�B���̂��߁A�ʏ�́u�ɗ]�v�ȉp�P�ꂪ�����Ă���v�Ƃ����P�[�X�͌��o�ł��܂��A�����Ɩ����ւ��ă`�F�b�N������Ό��o�ł��܂��B�܂��A��L�̂Ƃ���A�p�� -> ���{��̃`�F�b�N�͂��Ȃ蕡�G�� False positive �� False negative �������Ȃ�܂��B������A���{�� -> �p��ɕς���ƃ`�F�b�N���P���ɂȂ�A�G���[��������₷���Ȃ�܂��B�p�� -> ���{��̏ꍇ�Aset �� get �Ȃǂ̏������n�܂�̃v���O���� �R�}���h�͕��ʂ̉p��Ƌ�ʂ����Ȃ��̂Ō��o�ł��܂��A��o��ɓ��{�� -> �p��ɕς��ĉp�P��̃`�F�b�N������Ό��o�ł��܂��B���̃`�F�b�N�́A���̌o����A���������L���ɋ@�\���܂��B
����͈ȏ�ł��BTrados �Ō����Ɩ����ւ�����@�ɂ��ẮA����Ƃ肠�������Ǝv���܂��B���K�\�������낢��l���Ă���ƁA�f���ɐV���� Xbench ���w����������������Ȃ����Ƃ����l���������悬��Ȃ����Ƃ��Ȃ��ł����A�Ƃ肠�����A���������撣���Ă݂܂��B���K�\���͂悭�킩��Ȃ����Ƃ������̂ŁA�A�h�o�C�X������ƂƂĂ��������ł��B
| �@�@ |
Tweet