


�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
�L��
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
posted by fanblog
2022�N05��23��
�f���A�� �f�B�X�v���C�ł̍��
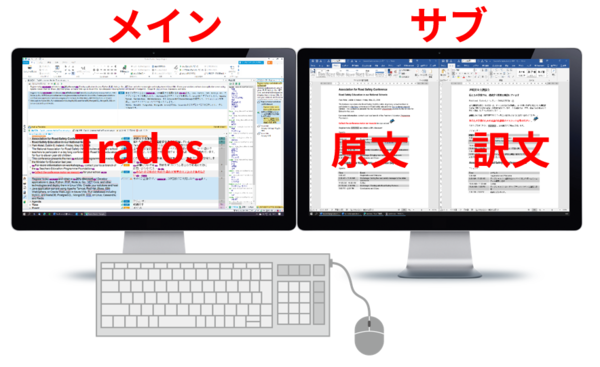
���͕��i����f���A�� �f�B�X�v���C�Ŗ|���Ƃ����Ă��܂��B3 ��ʁA4 ��ʂƑ��₵�������֗���������܂��A�����I�Ȑ�������A���� 2 ��ʂł��B����́A���� 2 ��ʂ� Trados ���ǂ̂悤�Ɏg���Ė|��ƃ`�F�b�N�̍�Ƃ����Ă���̂����Љ�܂��B

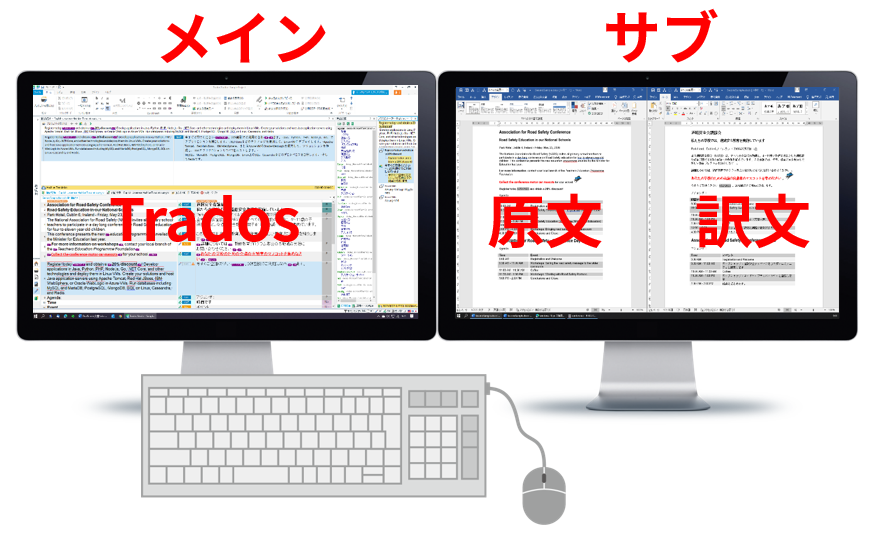
2 �̃f�B�X�v���C�� 1 �̊��̏�ɒu���Ă��܂��B�L�[�{�[�h�����C����ʊ��ɒu���A��𐳖ʂɌ������Ƃ��͂قڃ��C����ʁA�����E�������ƃT�u��ʂƂ����`�ɂȂ�悤�ɂ��Ă��܂��B
���́A�ŏ��ɖ|�������Ƃ��ƁA��������I����Ă���`�F�b�N������Ƃ��Ŋe��ʂɕ\��������e��ς��܂��B�ЂƎ�Ԃ�����܂����A���ꂼ��̍�Ƃɍ��킹�ĉ�ʕ\�������������֗��ł��B�܂��A�|�镶���̎�ނɂ���Ă��\�������܂��BWord �t�@�C���Ȃ�ʏ�͏c���ł����APowerPoint �͉����ł����AHTML �t�@�C���� XML �t�@�C���͊ȒP�ɂ͕\�����ł��Ȃ����Ƃ�����܂��BTrados �ɂ͂������v���r���[�@�\������܂����A�Ȃ��Ȃ����܂����삵�Ă���Ȃ��̂ő����̍H�v���K�v�ł��B
���C����ʂ� Trados
�ŏ��ɖ|�������Ƃ��́A���C����ʂ� Trados�A�T�u��ʂɌ����Ɩ�\�����܂��B�T�u��ʂɂ́A������u���E�U�[�Ȃǂ̎Q�l�������\�����܂��B2 ��ʂ̊��ł͎Q�l�����Ȃǂ��\�������ꂸ�A�ǂ����Ă��E�B���h�E�̐�ւ��������Ȃ�̂ŁA�f�B�X�v���C�̐��𑝂₹��Ȃ瑝�₵������������������܂���B
Trados ���̃��C�A�E�g
Trados ���̊e�y�C���Ȃǂ̃��C�A�E�g�͂��Ȃ莩�R�ɕύX�ł��܂��B�y�C���̃^�C�g���������h���b�O����ƁA�z�u�\�ȏꏊ�������K�C�h���\�������̂ŁA����ɍ��킹�Ĉړ����܂��B
�e�y�C���� Trados �{�̂̃E�B���h�E����O�ɏo���ĕʃE�B���h�E�Ƃ��ĕ\�����邱�Ƃ��ł��܂��B�傫���\���������v���r���[ �y�C���Ȃǂ́A�{�̂̃E�B���h�E����藣���ĕʃE�B���h�E�Ƃ��ĕ\�������������₷���Ȃ�܂��B�����A�E�B���h�E��藣���Ă� 1 �̃A�v���P�[�V�����ł��邱�Ƃɕς��͂Ȃ��̂ŁA1 �̃E�B���h�E���N���b�N����ƁATrados �̂��ׂẴE�B���h�E���A�N�e�B�u�ɂȂ�O�ʂɕ\������܂��B
�s�v�ȃy�C���͔�\���ɂł��܂��B�y�C���̉E��[�� × �A�C�R�����N���b�N����A���̃y�C���͔�\���ɂȂ�܂��B��\���ɂ��Ă��܂��Ă��A���{���� [�\��] �^�u����I������ēx�\���ł��܂��B�܂��A���� [�\��] �^�u�ɂ��� [�E�B���h�E�̃��C�A�E�g�����ɖ߂�] ���N���b�N����A�S�̂̕\���������ݒ�ɖ߂�܂��B�ςȕ��ɕύX���Ă����ɖ߂���̂ŁA���S���Ă��낢�남�������������B
���́A���}�̂悤�ɁA�������g��Ȃ��y�C����A�C�R���͏����A����͂��镔�����Ȃ�ׂ��L���Ȃ�悤�ɂ��Ă��܂��B�܂��A�p��F���ƃt���O�����g��v�͏�ɕ\�������ꏊ�Ɉړ����A�c���ɕ\�����܂��B�p��x�[�X���g��Ȃ��v���W�F�N�g�̂Ƃ��́A�p��F���y�C���͔�\���ɂ��܂��B
�p��F���ƃt���O�����g��v�̃y�C����藣���ăT�u��ʂɕ\�����Ă������Ƃ�����܂������A���͌��ɖ߂��܂����B���� 2 �̃y�C�����O�ɏo������������͂��镔���͍L���Ȃ�܂����A�p��������Ƃ����X�N���ǂ����Ă������Ȃ�C�����܂��B
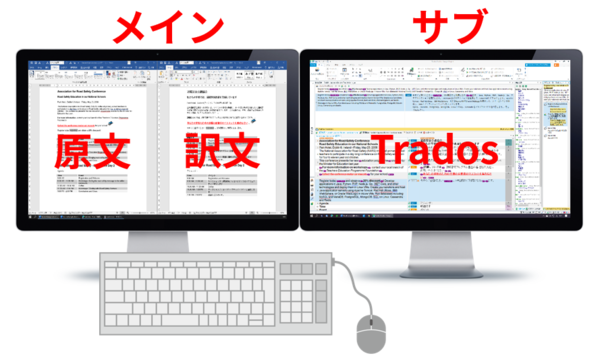
���C����ʂɌ����Ɩ�
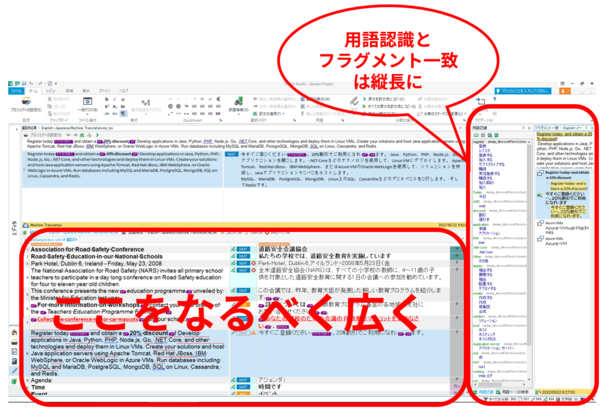
���āA�ꉞ�Ō�܂Ŗ|������ă`�F�b�N�����悤�Ƃ����Ƃ��́A���C����ʂɌ����Ɩ�\�����ATrados �̓T�u��ʂɈړ����܂��B���C����ʂ� Trados ��u���Ă����ƁA�`�F�b�N�����Ă���͂��Ȃ̂ɋC�Â��� Trados �̃E�B���h�E���茩�Ă����Ƃ�����ԂɂȂ肪���Ȃ̂ŁA�ł��ڂɓ���₷�����C����ʂɌ����Ɩ�u���܂��B
�܂��A�����łȂ��A�K���������ڂɓ���₷���Ƃ���ɒu���܂��B�`�F�b�N�����Ă���Ƃ��́A���R�Ȃ���ɒ��ӂ������̂ŁA�����������ڂ̓͂��Ƃ���ɂȂ��ƁA������A�C�Â��Ɩ����ǂ�ł��Ȃ������Ƃ�����ԂɂȂ肪���ł��BPowerPoint �Ȃǂ̉����y�[�W�Ō����Ɩ� 1 ��ʓ��ɕ\������̂�����ꍇ�́A���������C����ʂɁA���T�u��ʂɕ\�����܂��B�͌��ł�����̂ŁA��〈�ɂ������ɒu���Ă����Ă����v�ł��B
Trados ���̃��C�A�E�g
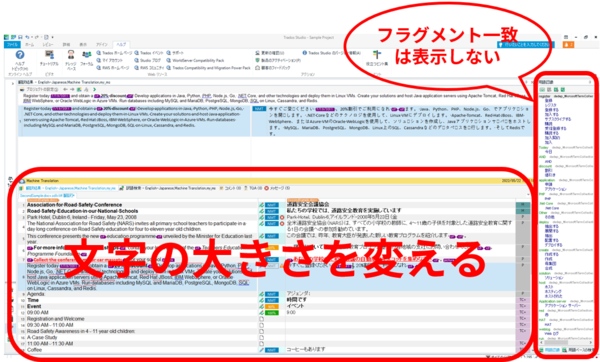
Trados ���̃��C�A�E�g���|�Ƃ͏����Ⴄ���̂ɂ��܂��B�t���O�����g��v�́A�|�ɂ͕֗��ł����A��x���m�肵�ă������ɓo�^������͌������s���Ȃ��Ȃ�܂��B���̏�ԂŃy�C����\�����Ă��Ă��X�y�[�X�̖��ʂȂ̂ŁA��\���ɂ��Ă��܂��܂��B
�̕����T�C�Y���ύX���܂��B����́A���s�ʒu��ς��邽�߂ł��B���s������ƁA�X�y�[�X�̗L�����킩��ɂ����ł����A���ӎ��̂����ɂ��������Ɗ����Ă��܂��̂ŁA�Ǔ_�����邩�ǂ����̔��f�ɉe�����邱�Ƃ�����܂��B���́A�`�F�b�N���͕����T�C�Y�����������āA1 �s�ɂȂ�ׂ������̕������\�������悤�ɂ��܂��B
�ȑO�ɂ��b�������Ƃ̂���|��҂���́A�`�F�b�N���ɂ͕�����傫������Ƃ���������Ă��܂����B�����̍D�݂╶���̎�ނɂ���Ăǂ���ł������Ǝv���܂����A�Ƃɂ����u���s�ʒu���ς��v�悤�ɂ��܂��B�����T�C�Y��ς��ɂ����Ƃ��́A�y�C���̕���ς��邾���ł����s�ʒu���ς��܂� (�������A�t���O�����g��v���\���ɂ������_�ŁA�G�f�B�^�[�����̕��͕ς���Ă��܂�)�B
Trados �̃G�f�B�^�[���ł̕\�������Ƃ��āA���́A�����̕\��/��\���ƁA�^�O�\�����[�h�̐�ւ����V���[�g�J�b�g �L�[�ɐݒ肵�Ďg�p���Ă��܂��B�|��ł��A�`�F�b�N�ł��A�K�v�ɉ����Đ�����ւ��Ȃ����Ƃ��܂��B
�����̕\��/��\��
�V���[�g�J�b�g �L�[�̐ݒ�: [�t�@�C��] > [�I�v�V����] > [�V���[�g�J�b�g �L�[] > [�G�f�B�^] > [�����̕\��]
���{��: [�z�[��] > [����]
�ݒ���: [�t�@�C��] > [�I�v�V����] > [�G�f�B�^] > [�����̕\��]
�u�����̕\���v�Ƃ����ݒ��ŁA�X�y�[�X�͂������A���s�A�^�u�Ȃǂ̋L�����\������܂��B�����A�X�y�[�X�������|�`���Ƃ��������_�́A�p��̃s���I�h����{��̒����Ƃ̌��ԈႦ���N����₷���ł��B�܂��A���s���\������Ă����ԂƂ���Ă��Ȃ���Ԃł́A��ǂƂ��̈�ۂ������ς���Ă���悤�ȋC�����܂��B��ɕ\������A�܂��͏�ɔ�\���ɂ���Ƃ������Ƃł͂Ȃ��A��ւ��Ȃ����Ƃ���̂��悢���Ǝv���܂��B
�^�O�\�����[�h
�V���[�g�J�b�g �L�[�̐ݒ�: [�t�@�C��] > [�I�v�V����] > [�V���[�g�J�b�g �L�[] > [�G�f�B�^] > [�^�O�\�����[�h�̕ύX]
���{��: [�\��] > [�I�v�V����]
�ݒ���: �����炭�A�Ȃ�
�^�O�\�����[�h����ւ��Ȃ����Ƃ���̂��֗��ł��B�^�O�̒��g�܂Ŋm�F�������Ƃ��͂���܂����A���i�͎ז��Ȃ̂ł��܂�ڗ����Ȃ��\���ɂ��Ă��܂��B[�^�O ID] �Ƃ����\���ɂ���ƁA�^�O���ԍ��ŕ\������܂��BUI ��i���ȂǁA�����^�O�Œ��g���Ⴄ�ꍇ�́A�^�O ID �̕\�����֗��ł��B
�Ō�ɁA���������������グ�܂��B�����܂Łu��\������v�Ƃ�����Ə����Ă��܂������A���͖�\������̂͂Ȃ��Ȃ���ςł��BTrados �ɂ͖̃v���r���[�@�\������������܂����A�ǂ���꒷��Z����A���܂�֗��ł͂���܂���B�ڂ����́A�ȑO�̋L���A�u�̕\���v���g���Ă݂��A�u�݂̂ŕۑ��v���g���Ă݂��A�ӊO�Ǝg����u����v���r���[�v���Q�l�ɂ��Ă��������B
Office �����Ȃ�u�̕\���v
Word�APowerPoint�AExcel �Ȃǂ� Office �����Ȃ�A�u�̕\���v�@�\���g�����ƂŁATrados �Ƃ͕ʂ� Word�APowerPoint�AExcel �Ȃnj��X�̃A�v���P�[�V�����Ŗ�\���ł��܂��B�V���[�g�J�b�g �L�[�� Ctrl+Shift+P �ŊȒP�ɕ\���ł��܂��B
HTML �t�@�C���Ȃ�u�݂̂ŕۑ��v
HTML �t�@�C���Ȃ�A���t�@�C���Ƃ��ĕۑ����A�u���E�U�[�ŕ\������̂��֗��ł��B�X�^�C���V�[�g��摜���܂܂�Ă���ꍇ�͂ЂƎ�Ԃ�����܂����A����ł��u���E�U�[�ł̕\���͂ƂĂ���y�ł��B���t�@�C���Ƃ��ĕۑ�����ɂ́A[�t�@�C��] > [�ʖ� (�̂�) �ŕۑ�] �ƑI�����邩�A�V���[�g�J�b�g �L�[�� Shift+F12 ���g���܂��B
XML �t�@�C���Ȃ�u�v���r���[�v
XML �t�@�C���Ȃ�ATrados ���̃v���r���[ �y�C���ł̕\�����ȒP�ł��B���A���^�C�� �v���r���[�ɂ���A���ݕҏW���̕��߂��n�C���C�g���邱�Ƃ��ł��܂��B�v���r���[ �y�C���́AXML �t�@�C���ȊO�ɂ��������g�p�ł��܂����A���̌o����AXML �t�@�C���ȊO�ł͂��܂肤�܂��@�\���܂���B���̃p�\�R�����̖�肩������܂��ATrados �̃G�f�B�^�[�̓������x���Ȃ�����A�J�[�\�����������肵�܂��BXML �t�@�C���̂Ƃ������́A���������s���ȓ�����Ȃ��A����ɋ@�\���܂��B
�ŏI��i�́u����v���r���[�v
�ꍇ�ɂ���ẮA��L�̂���������܂��@�\���Ȃ����Ƃ�����܂��B����ȂƂ��́A�ŏI��i�Ƃ��āu����v���r���[�v���g���܂��B�G�f�B�^�[��ɕ\������Ă��錴���Ɩ��u���E�U�[�ŕ\�����邱�Ƃ��ł��܂��B�}�b�`���ɂ��F������A�^�O�̕\�����ł��܂��B�V���[�g�J�b�g �L�[�� Ctrl+P �ł��B
����͈ȏ�ł��B���́A���݂̃f���A�� �f�B�X�v���C�����ƂĂ��C�ɓ����Ă��܂����A3 ��ʁA4 ��ʂ���������܂��B�ł��A�����̍��̕����ł͓�����A���炭�͌���̂܂܂ɂȂ肻���ł��B
Tweet

2 �̃f�B�X�v���C�� 1 �̊��̏�ɒu���Ă��܂��B�L�[�{�[�h�����C����ʊ��ɒu���A��𐳖ʂɌ������Ƃ��͂قڃ��C����ʁA�����E�������ƃT�u��ʂƂ����`�ɂȂ�悤�ɂ��Ă��܂��B
���́A�ŏ��ɖ|�������Ƃ��ƁA��������I����Ă���`�F�b�N������Ƃ��Ŋe��ʂɕ\��������e��ς��܂��B�ЂƎ�Ԃ�����܂����A���ꂼ��̍�Ƃɍ��킹�ĉ�ʕ\�������������֗��ł��B�܂��A�|�镶���̎�ނɂ���Ă��\�������܂��BWord �t�@�C���Ȃ�ʏ�͏c���ł����APowerPoint �͉����ł����AHTML �t�@�C���� XML �t�@�C���͊ȒP�ɂ͕\�����ł��Ȃ����Ƃ�����܂��BTrados �ɂ͂������v���r���[�@�\������܂����A�Ȃ��Ȃ����܂����삵�Ă���Ȃ��̂ő����̍H�v���K�v�ł��B
�|�������Ƃ�
���C����ʂ� Trados
�ŏ��ɖ|�������Ƃ��́A���C����ʂ� Trados�A�T�u��ʂɌ����Ɩ�\�����܂��B�T�u��ʂɂ́A������u���E�U�[�Ȃǂ̎Q�l�������\�����܂��B2 ��ʂ̊��ł͎Q�l�����Ȃǂ��\�������ꂸ�A�ǂ����Ă��E�B���h�E�̐�ւ��������Ȃ�̂ŁA�f�B�X�v���C�̐��𑝂₹��Ȃ瑝�₵������������������܂���B
Trados ���̃��C�A�E�g
Trados ���̊e�y�C���Ȃǂ̃��C�A�E�g�͂��Ȃ莩�R�ɕύX�ł��܂��B�y�C���̃^�C�g���������h���b�O����ƁA�z�u�\�ȏꏊ�������K�C�h���\�������̂ŁA����ɍ��킹�Ĉړ����܂��B
�e�y�C���� Trados �{�̂̃E�B���h�E����O�ɏo���ĕʃE�B���h�E�Ƃ��ĕ\�����邱�Ƃ��ł��܂��B�傫���\���������v���r���[ �y�C���Ȃǂ́A�{�̂̃E�B���h�E����藣���ĕʃE�B���h�E�Ƃ��ĕ\�������������₷���Ȃ�܂��B�����A�E�B���h�E��藣���Ă� 1 �̃A�v���P�[�V�����ł��邱�Ƃɕς��͂Ȃ��̂ŁA1 �̃E�B���h�E���N���b�N����ƁATrados �̂��ׂẴE�B���h�E���A�N�e�B�u�ɂȂ�O�ʂɕ\������܂��B
�s�v�ȃy�C���͔�\���ɂł��܂��B�y�C���̉E��[�� × �A�C�R�����N���b�N����A���̃y�C���͔�\���ɂȂ�܂��B��\���ɂ��Ă��܂��Ă��A���{���� [�\��] �^�u����I������ēx�\���ł��܂��B�܂��A���� [�\��] �^�u�ɂ��� [�E�B���h�E�̃��C�A�E�g�����ɖ߂�] ���N���b�N����A�S�̂̕\���������ݒ�ɖ߂�܂��B�ςȕ��ɕύX���Ă����ɖ߂���̂ŁA���S���Ă��낢�남�������������B
���́A���}�̂悤�ɁA�������g��Ȃ��y�C����A�C�R���͏����A����͂��镔�����Ȃ�ׂ��L���Ȃ�悤�ɂ��Ă��܂��B�܂��A�p��F���ƃt���O�����g��v�͏�ɕ\�������ꏊ�Ɉړ����A�c���ɕ\�����܂��B�p��x�[�X���g��Ȃ��v���W�F�N�g�̂Ƃ��́A�p��F���y�C���͔�\���ɂ��܂��B
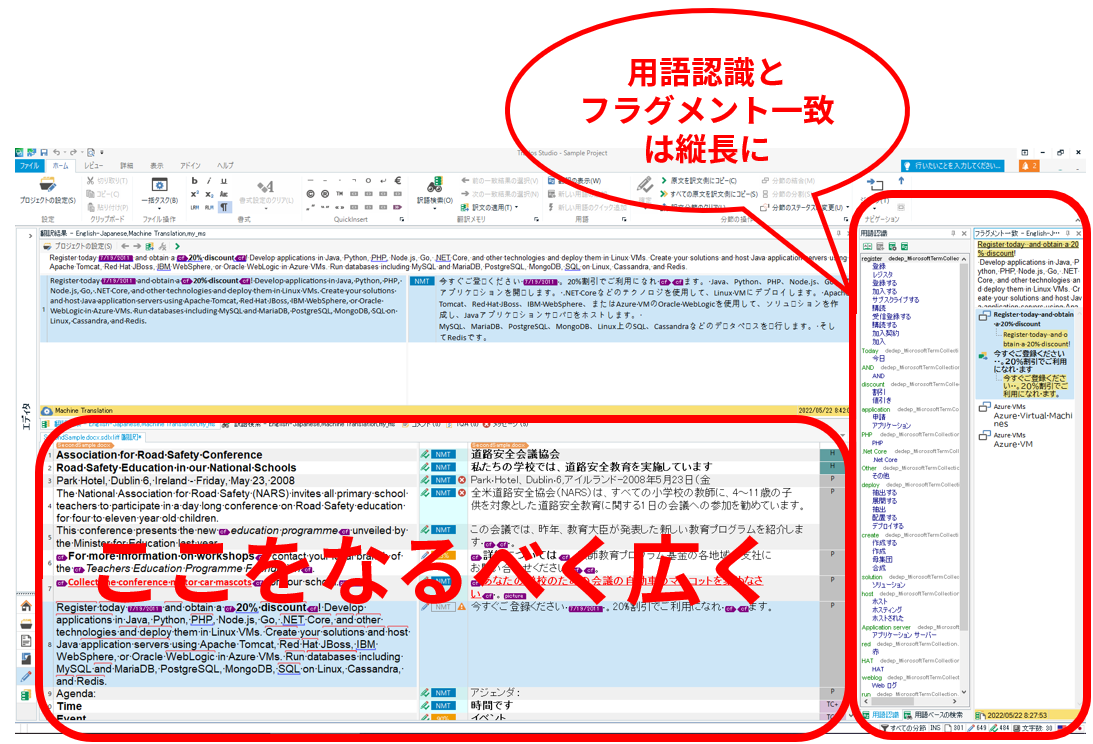
�p��F���ƃt���O�����g��v�̃y�C����藣���ăT�u��ʂɕ\�����Ă������Ƃ�����܂������A���͌��ɖ߂��܂����B���� 2 �̃y�C�����O�ɏo������������͂��镔���͍L���Ȃ�܂����A�p��������Ƃ����X�N���ǂ����Ă������Ȃ�C�����܂��B
�`�F�b�N������Ƃ�
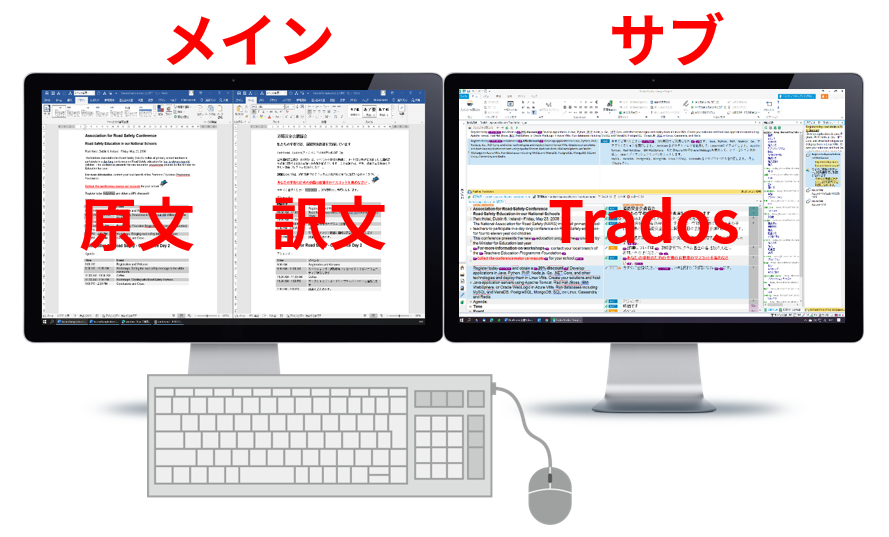
���C����ʂɌ����Ɩ�
���āA�ꉞ�Ō�܂Ŗ|������ă`�F�b�N�����悤�Ƃ����Ƃ��́A���C����ʂɌ����Ɩ�\�����ATrados �̓T�u��ʂɈړ����܂��B���C����ʂ� Trados ��u���Ă����ƁA�`�F�b�N�����Ă���͂��Ȃ̂ɋC�Â��� Trados �̃E�B���h�E���茩�Ă����Ƃ�����ԂɂȂ肪���Ȃ̂ŁA�ł��ڂɓ���₷�����C����ʂɌ����Ɩ�u���܂��B
�܂��A�����łȂ��A�K���������ڂɓ���₷���Ƃ���ɒu���܂��B�`�F�b�N�����Ă���Ƃ��́A���R�Ȃ���ɒ��ӂ������̂ŁA�����������ڂ̓͂��Ƃ���ɂȂ��ƁA������A�C�Â��Ɩ����ǂ�ł��Ȃ������Ƃ�����ԂɂȂ肪���ł��BPowerPoint �Ȃǂ̉����y�[�W�Ō����Ɩ� 1 ��ʓ��ɕ\������̂�����ꍇ�́A���������C����ʂɁA���T�u��ʂɕ\�����܂��B�͌��ł�����̂ŁA��〈�ɂ������ɒu���Ă����Ă����v�ł��B
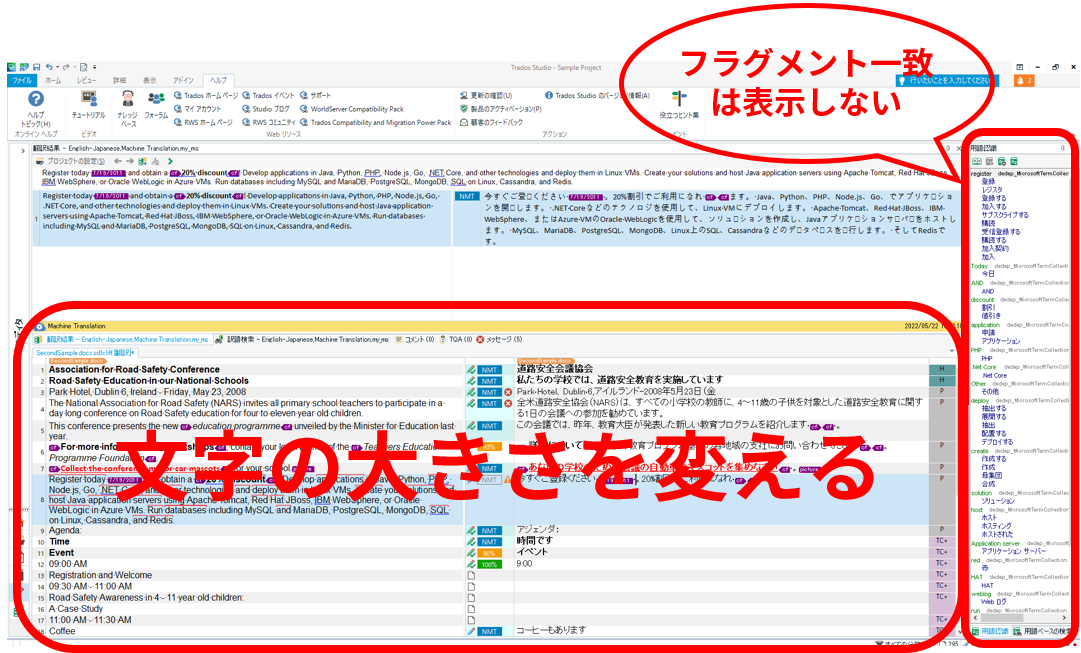
Trados ���̃��C�A�E�g
Trados ���̃��C�A�E�g���|�Ƃ͏����Ⴄ���̂ɂ��܂��B�t���O�����g��v�́A�|�ɂ͕֗��ł����A��x���m�肵�ă������ɓo�^������͌������s���Ȃ��Ȃ�܂��B���̏�ԂŃy�C����\�����Ă��Ă��X�y�[�X�̖��ʂȂ̂ŁA��\���ɂ��Ă��܂��܂��B
�̕����T�C�Y���ύX���܂��B����́A���s�ʒu��ς��邽�߂ł��B���s������ƁA�X�y�[�X�̗L�����킩��ɂ����ł����A���ӎ��̂����ɂ��������Ɗ����Ă��܂��̂ŁA�Ǔ_�����邩�ǂ����̔��f�ɉe�����邱�Ƃ�����܂��B���́A�`�F�b�N���͕����T�C�Y�����������āA1 �s�ɂȂ�ׂ������̕������\�������悤�ɂ��܂��B
�ȑO�ɂ��b�������Ƃ̂���|��҂���́A�`�F�b�N���ɂ͕�����傫������Ƃ���������Ă��܂����B�����̍D�݂╶���̎�ނɂ���Ăǂ���ł������Ǝv���܂����A�Ƃɂ����u���s�ʒu���ς��v�悤�ɂ��܂��B�����T�C�Y��ς��ɂ����Ƃ��́A�y�C���̕���ς��邾���ł����s�ʒu���ς��܂� (�������A�t���O�����g��v���\���ɂ������_�ŁA�G�f�B�^�[�����̕��͕ς���Ă��܂�)�B
�֗��ȃV���[�g�J�b�g �L�[
Trados �̃G�f�B�^�[���ł̕\�������Ƃ��āA���́A�����̕\��/��\���ƁA�^�O�\�����[�h�̐�ւ����V���[�g�J�b�g �L�[�ɐݒ肵�Ďg�p���Ă��܂��B�|��ł��A�`�F�b�N�ł��A�K�v�ɉ����Đ�����ւ��Ȃ����Ƃ��܂��B
�����̕\��/��\��
�V���[�g�J�b�g �L�[�̐ݒ�: [�t�@�C��] > [�I�v�V����] > [�V���[�g�J�b�g �L�[] > [�G�f�B�^] > [�����̕\��]
���{��: [�z�[��] > [����]
�ݒ���: [�t�@�C��] > [�I�v�V����] > [�G�f�B�^] > [�����̕\��]
�u�����̕\���v�Ƃ����ݒ��ŁA�X�y�[�X�͂������A���s�A�^�u�Ȃǂ̋L�����\������܂��B�����A�X�y�[�X�������|�`���Ƃ��������_�́A�p��̃s���I�h����{��̒����Ƃ̌��ԈႦ���N����₷���ł��B�܂��A���s���\������Ă����ԂƂ���Ă��Ȃ���Ԃł́A��ǂƂ��̈�ۂ������ς���Ă���悤�ȋC�����܂��B��ɕ\������A�܂��͏�ɔ�\���ɂ���Ƃ������Ƃł͂Ȃ��A��ւ��Ȃ����Ƃ���̂��悢���Ǝv���܂��B
�^�O�\�����[�h
�V���[�g�J�b�g �L�[�̐ݒ�: [�t�@�C��] > [�I�v�V����] > [�V���[�g�J�b�g �L�[] > [�G�f�B�^] > [�^�O�\�����[�h�̕ύX]
���{��: [�\��] > [�I�v�V����]
�ݒ���: �����炭�A�Ȃ�
�^�O�\�����[�h����ւ��Ȃ����Ƃ���̂��֗��ł��B�^�O�̒��g�܂Ŋm�F�������Ƃ��͂���܂����A���i�͎ז��Ȃ̂ł��܂�ڗ����Ȃ��\���ɂ��Ă��܂��B[�^�O ID] �Ƃ����\���ɂ���ƁA�^�O���ԍ��ŕ\������܂��BUI ��i���ȂǁA�����^�O�Œ��g���Ⴄ�ꍇ�́A�^�O ID �̕\�����֗��ł��B
�̃v���r���[
�Ō�ɁA���������������グ�܂��B�����܂Łu��\������v�Ƃ�����Ə����Ă��܂������A���͖�\������̂͂Ȃ��Ȃ���ςł��BTrados �ɂ͖̃v���r���[�@�\������������܂����A�ǂ���꒷��Z����A���܂�֗��ł͂���܂���B�ڂ����́A�ȑO�̋L���A�u�̕\���v���g���Ă݂��A�u�݂̂ŕۑ��v���g���Ă݂��A�ӊO�Ǝg����u����v���r���[�v���Q�l�ɂ��Ă��������B
Office �����Ȃ�u�̕\���v
Word�APowerPoint�AExcel �Ȃǂ� Office �����Ȃ�A�u�̕\���v�@�\���g�����ƂŁATrados �Ƃ͕ʂ� Word�APowerPoint�AExcel �Ȃnj��X�̃A�v���P�[�V�����Ŗ�\���ł��܂��B�V���[�g�J�b�g �L�[�� Ctrl+Shift+P �ŊȒP�ɕ\���ł��܂��B
HTML �t�@�C���Ȃ�u�݂̂ŕۑ��v
HTML �t�@�C���Ȃ�A���t�@�C���Ƃ��ĕۑ����A�u���E�U�[�ŕ\������̂��֗��ł��B�X�^�C���V�[�g��摜���܂܂�Ă���ꍇ�͂ЂƎ�Ԃ�����܂����A����ł��u���E�U�[�ł̕\���͂ƂĂ���y�ł��B���t�@�C���Ƃ��ĕۑ�����ɂ́A[�t�@�C��] > [�ʖ� (�̂�) �ŕۑ�] �ƑI�����邩�A�V���[�g�J�b�g �L�[�� Shift+F12 ���g���܂��B
XML �t�@�C���Ȃ�u�v���r���[�v
XML �t�@�C���Ȃ�ATrados ���̃v���r���[ �y�C���ł̕\�����ȒP�ł��B���A���^�C�� �v���r���[�ɂ���A���ݕҏW���̕��߂��n�C���C�g���邱�Ƃ��ł��܂��B�v���r���[ �y�C���́AXML �t�@�C���ȊO�ɂ��������g�p�ł��܂����A���̌o����AXML �t�@�C���ȊO�ł͂��܂肤�܂��@�\���܂���B���̃p�\�R�����̖�肩������܂��ATrados �̃G�f�B�^�[�̓������x���Ȃ�����A�J�[�\�����������肵�܂��BXML �t�@�C���̂Ƃ������́A���������s���ȓ�����Ȃ��A����ɋ@�\���܂��B
�ŏI��i�́u����v���r���[�v
�ꍇ�ɂ���ẮA��L�̂���������܂��@�\���Ȃ����Ƃ�����܂��B����ȂƂ��́A�ŏI��i�Ƃ��āu����v���r���[�v���g���܂��B�G�f�B�^�[��ɕ\������Ă��錴���Ɩ��u���E�U�[�ŕ\�����邱�Ƃ��ł��܂��B�}�b�`���ɂ��F������A�^�O�̕\�����ł��܂��B�V���[�g�J�b�g �L�[�� Ctrl+P �ł��B
����͈ȏ�ł��B���́A���݂̃f���A�� �f�B�X�v���C�����ƂĂ��C�ɓ����Ă��܂����A3 ��ʁA4 ��ʂ���������܂��B�ł��A�����̍��̕����ł͓�����A���炭�͌���̂܂܂ɂȂ肻���ł��B
| �@�@ |
Tweet
2022�N05��05��
�t�@�C�� �r���[���J�X�^�}�C�Y����
����ATrados ����ς��G���[���\��������悤�ɂȂ��Ă��܂����̂ŁATrados �̃C���X�g�[�������N���[���ȏ�Ԃɖ߂��Ă����A�v�� Trados Freshstart ���g���܂����B����ŃG���[�͉������܂������A���낢��Ȑݒ肪����������A�Đݒ�ɂ����Ԏ�Ԃ�����܂����B�Y��Ă���ݒ�����������̂ŁA����͎����̔��Y�^�����˂ăt�@�C�� �r���[�̐ݒ���܂Ƃ߂Ă��������Ǝv���܂��B
�܂��́A�����̃��j���[�� [�T�u�t�H���_���܂߂�] �`�F�b�N�{�b�N�X���I���ɂ��܂��B������I���ɂ��Ȃ��ƁA�t�H���_���Ƃɂ����t�@�C����\���ł��Ȃ��̂ŕs�ւł��B�v���W�F�N�g�͂������̃t�H���_�ŊK�w�\���ɂȂ��Ă��邱�Ƃ�����̂ŁA�S�t�@�C������C�Ɉꗗ�������Ƃ��͂��̃`�F�b�N�{�b�N�X���I���ɂ��܂��B
���Ƃ��A���}�̃v���W�F�N�g�ɂ́uChapter1�v�ƁuChapter2�v�Ƃ����T�u�t�H���_������܂��B[�T�u�t�H���_���܂߂�] �`�F�b�N�{�b�N�X���I�t�̂܂܂̏ꍇ�A�����̃T�u�t�H���_���̃t�@�C���͂��̃t�H���_��I�����Ȃ�����ꗗ�ɕ\������Ă��܂���B
�� [�T�u�t�H���_���܂߂�] ���I�t�ɂ����܂�
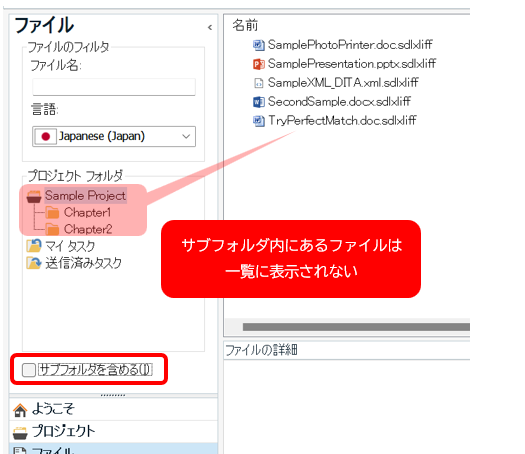
�� [�T�u�t�H���_���܂߂�] ���I���ɂ���
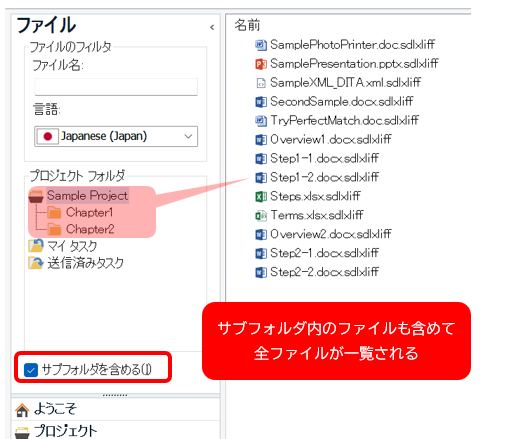
�������A[�T�u�t�H���_���܂߂�] ���I���ɂ��ăt�@�C����\������ƁA�S�t�@�C�����������x���ňꗗ�����̂Ńt�H���_�̊K�w�\�����킩��ɂ����Ȃ�܂��B����ɂ��Ă̑Ώ����@�́A��Ő������܂��B
�t�@�C���̈ꗗ�ɕ\������鍀�ڂȂǂ̓��{���� [���C�A�E�g] �^�u����ύX�ł��܂��B�ɉ����Ċ���̃��C�A�E�g�������őI������܂����A�����̖ړI�ɍ��킹�ĕύX���邱�Ƃ��\�ł��B�������i�悭�g���̂́u�t�@�C���̏ڍׂ̃��C�A�E�g�v�ł��B
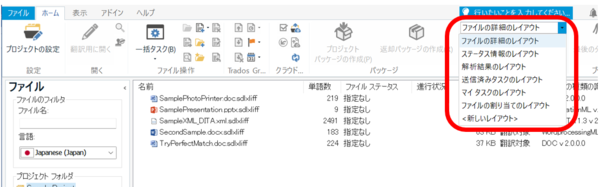
���낢��ȃ��C�A�E�g������ŗp�ӂ���Ă��܂����A���́A�ǂ����������܂�g�����肪�悭����܂���B�ł��A���v�ł��B���̊���̃��C�A�E�g�̓J�X�^�}�C�Y�ł��܂��B�܂��A�����ł܂������V�������C�A�E�g���쐬���邱�Ƃ��ł��܂��B
�J�X�^�}�C�Y����ꍇ�́A���ږ� (���o���s) �̂ǂ������E�N���b�N���ă��j���[��\�����܂��B���̃��j���[����A�\�����������ڂ�I�����邩�A[�J�X�^�}�C�Y] ��I�����čׂ����ݒ���s���܂��B�܂��A���ږ��Ƀh���b�O �A���h �h���b�v���ĕ\������ړ����邱�Ƃ��ł��܂��B
�V�������C�A�E�g���쐬����ꍇ�́A��}�Ɏ��������C�A�E�g�I��p�̃h���b�v�_�E���ŁA��ԉ��ɂ��� <�V�������C�A�E�g> ��I�����܂��B���}�̂悤�Ȑݒ��ʂ��\�������̂ŁA[�r���[��] �ɐV�������C�A�E�g�̖��O����͂��A��́A�\�����������ڂ�I�����Ă����܂��B
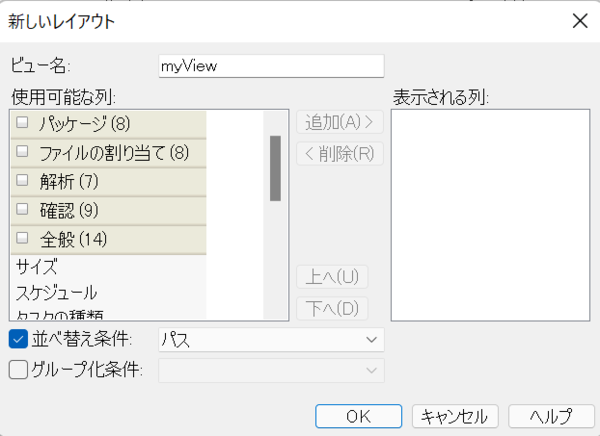
�ȉ��ɁA�����悭�g�p���鍀�ڂ��Љ�܂��B
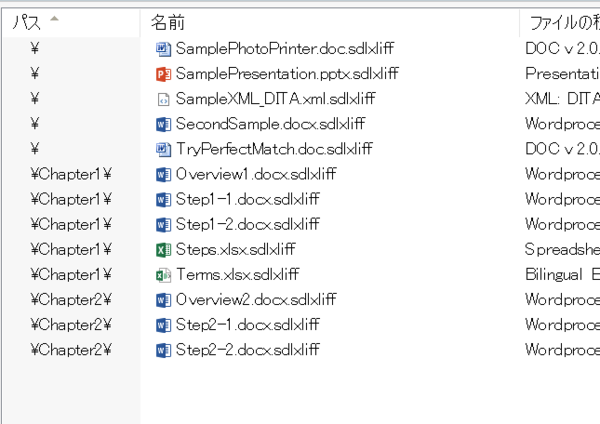
[�S��] > [�p�X]
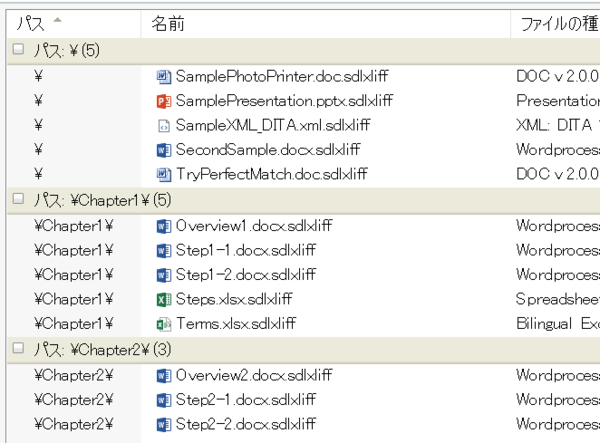
�܂��A�t�@�C���ꗗ�̐擪 (���[) �Ƀp�X��\�����܂��B[�T�u�t�H���_���܂߂�] �I�v�V������L���ɂ��Ă���ƑS�t�@�C�����������x���ňꗗ����Ă��܂��܂����A�擪�Ƀp�X��\�����āA�p�X�̒l�ŕ��ёւ������Ă����A�t�H���_�̊K�w�\�����킩��₷���Ȃ�܂��B ����ɁA[�O���[�v������] �Ɂu�p�X�v��I������ƁA�t�@�C�����t�H���_���ƂɃO���[�v������܂��B�t�H���_���d�v�ȈӖ������v���W�F�N�g�ł́A�O���[�v���̕\���ɂ��Ă����Ǝ��o�I�ɂ킩��₷���Ȃ�֗��ł��B
�� ���[�Ƀp�X��\�����A�p�X�̒l�ŕ��ёւ������Ă���
�� ����ɁA�p�X�ŃO���[�v�����邱�Ƃ��ł���
�@
[�S��] > [�t�@�C���̎�ނ̎��ʎq] �� [�g�p�ړI]
�����Ńv���W�F�N�g���쐬����̂ł͂Ȃ��A�|���Ђ���p�b�P�[�W�Ƃ��ăt�@�C�������ꍇ�ł��A�����́u�t�@�C���̎�ށv��m���Ă������Ƃ͑�ł��BQuickInsert �̐ݒ���A���������t�@�C���ɃR�����g���܂߂邩�̐ݒ��ȂǁA�u�t�@�C���̎�ށv�ɂ͂悭�g���ݒ肪�������܂܂�Ă��܂��B�܂��ATrados �̓t�@�C���̎�ނɂ���Ă��Ȃ蓮�삪�قȂ�̂ŁA�����𑼂̐l�ɑ��k�������Ƃ��Ȃǂ́A�܂��t�@�C���̎�ނ�`����Ƙb���X���[�Y�ɐi�މ\���������Ȃ�܂��B
�t�@�C���̎�ނ̓A�C�R���ő�̂킩��܂����A�킩��ɂ����P�[�X������܂��B���Ƃ��AOffice �����̓o�[�W�����ɂ���ăt�@�C���̎�ނ��قȂ�܂����AExcel �ɂ́A�L����X�^�C���p�ɐ�p�̎�ނ��p�ӂ���Ă��܂��B���m�ȁu�t�@�C���̎�ށv����肷��ɂ́A�t�@�C���̎�ނ̎��ʎq���m�F����K�v������܂��B���̎��ʎq�������ɁA[�v���W�F�N�g�̐ݒ�] > [�t�@�C���̎��] �ŊY������t�@�C���̎�ނ������܂��B
�t�@�C���̎�ނƂ��킹�āu�g�p�ړI�v���O�̂��ߕ\�����Ă����܂��B�����܂�ɂł����A�p�b�P�[�W�ɂ͎g�p�ړI���u�|��Ώہv�ł͂Ȃ��u���t�@�����X�v�ƂȂ��Ă���t�@�C�����܂܂�Ă��邱�Ƃ�����܂��B����́A�Q�l�����Ƃ��Ďg���Ă��������A�Ƃ����Ӗ��Ȃ̂ŁA���̃t�@�C���̖|��͕s�v�ł��B
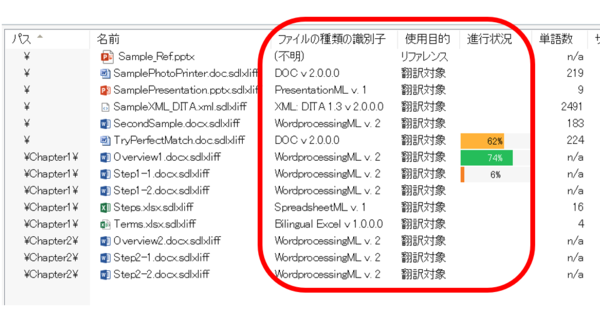
[�m�F] > [�i�s��]
����́A�X�e�[�^�X���m��ς݂ɂȂ��Ă��镪�߂̕����� (�P�ꐔ) �̊����ł��B�ǂꂭ�炢��Ƃ��i��ł��邩�̖ڈ��ɂȂ�܂��B
[�m�F] �Ƃ������ނ̒��ɂ͑��ɂ����������ڂ�����܂����A���̕��ނ̍��ڂ̒l�̓G�f�B�^�[�ō�Ƃ�i�߂�ɂ�Ăǂ�ǂ�ƍX�V����Ă����܂��B����A[���] �Ƃ������ނ̒��ɂ���u100%�v�Ȃǂ̍��ڂ́A�ꊇ�^�X�N�́u�t�@�C���̉�́v�����s���Ȃ��ƍX�V����܂���B�G�f�B�^�[�ō�Ƃ�i�߂Ă��A100% �̒l�͑����Ȃ��̂Œ��ӂ��Ă��������B
�Ō�ɁA�t�@�C���ꗗ�̉��ɕ\�������^�u�ɂ��Ă����������������Ă����܂��B�����ɂ́A���{���� [���] �^�u�őI��������\������܂��B�\�������e�y�C���̃��C�A�E�g�́ATrados �̑��̉�ʂƓ��l�A�h���b�O �A���h �h���b�v�Ŏ��R�ɕύX�ł��܂��B
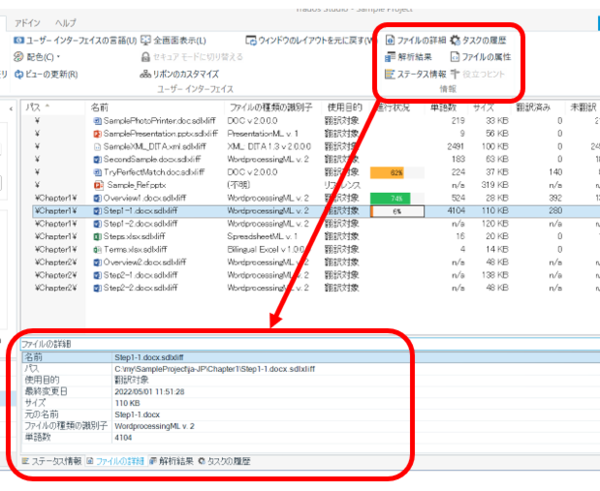
[�t�@�C���̏ڍ�] �^�u
�ꗗ��őI�������t�@�C���̏ڍ�\������܂��B�����Œ��ڂ���̂́u�ŏI�ύX���v�ł��B�e�t�@�C���̍ŏI�ύX���͂����ɂ����\������܂���B�㕔�̈ꗗ�̍��ڂƂ��Ă͕\���ł��Ȃ��̂ŁA�ŏI�ύX�����ɕ��בւ���A�Ƃ���������͂ł��܂���B
�ŏI�ύX���ŕ��בւ��邱�Ƃ��ł��Ȃ��̂́A��ʂ̃t�@�C��������Ƃ��Ȃǂ͂ƂĂ��s�ւł��B�ꉞ�AIdeas �Ƀ��N�G�X�g�͏o�Ă���̂ŁA�����悯��Γ��[�����肢���܂��B
[�X�e�[�^�X���] �^�u�� [��͌���] �^�u
[�X�e�[�^�X���] �^�u�͈ꗗ�ɕ\�����鍀�ڂ̕��ނł����� [�m�F] �ɁA[��͌���] �^�u�� [���] �ɑ������܂��B�ł��̂ŁA[�X�e�[�^�X���] �̓G�f�B�^�[�ō�Ƃ�i�߂�ɂ�čX�V����܂����A[��͌���] �͉�͂��s��Ȃ�����X�V����܂���B�������Ƃ̈�v���܂߂č�Ƃ̐i����m�肽���Ƃ��́A�ꊇ�^�X�N�ʼn�͂����s���Ă��� [��͌���] �^�u���m�F���܂��B
����͈ȏ�ł��B�t�@�C�� �r���[�͕p�ɂɎg����ʂȂ̂ŁA�ʓ|���炸�Ɏ����̎g�����ɍ��킹�ăJ�X�^�}�C�Y���邱�Ƃ������߂��܂��B
�T�u�t�H���_���܂߂�
�܂��́A�����̃��j���[�� [�T�u�t�H���_���܂߂�] �`�F�b�N�{�b�N�X���I���ɂ��܂��B������I���ɂ��Ȃ��ƁA�t�H���_���Ƃɂ����t�@�C����\���ł��Ȃ��̂ŕs�ւł��B�v���W�F�N�g�͂������̃t�H���_�ŊK�w�\���ɂȂ��Ă��邱�Ƃ�����̂ŁA�S�t�@�C������C�Ɉꗗ�������Ƃ��͂��̃`�F�b�N�{�b�N�X���I���ɂ��܂��B
���Ƃ��A���}�̃v���W�F�N�g�ɂ́uChapter1�v�ƁuChapter2�v�Ƃ����T�u�t�H���_������܂��B[�T�u�t�H���_���܂߂�] �`�F�b�N�{�b�N�X���I�t�̂܂܂̏ꍇ�A�����̃T�u�t�H���_���̃t�@�C���͂��̃t�H���_��I�����Ȃ�����ꗗ�ɕ\������Ă��܂���B
�� [�T�u�t�H���_���܂߂�] ���I�t�ɂ����܂�

�� [�T�u�t�H���_���܂߂�] ���I���ɂ���
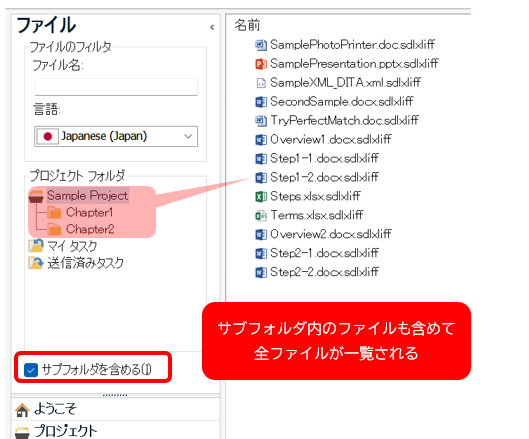
�������A[�T�u�t�H���_���܂߂�] ���I���ɂ��ăt�@�C����\������ƁA�S�t�@�C�����������x���ňꗗ�����̂Ńt�H���_�̊K�w�\�����킩��ɂ����Ȃ�܂��B����ɂ��Ă̑Ώ����@�́A��Ő������܂��B
�t�@�C���ꗗ�̃��C�A�E�g��I������
�t�@�C���̈ꗗ�ɕ\������鍀�ڂȂǂ̓��{���� [���C�A�E�g] �^�u����ύX�ł��܂��B�ɉ����Ċ���̃��C�A�E�g�������őI������܂����A�����̖ړI�ɍ��킹�ĕύX���邱�Ƃ��\�ł��B�������i�悭�g���̂́u�t�@�C���̏ڍׂ̃��C�A�E�g�v�ł��B
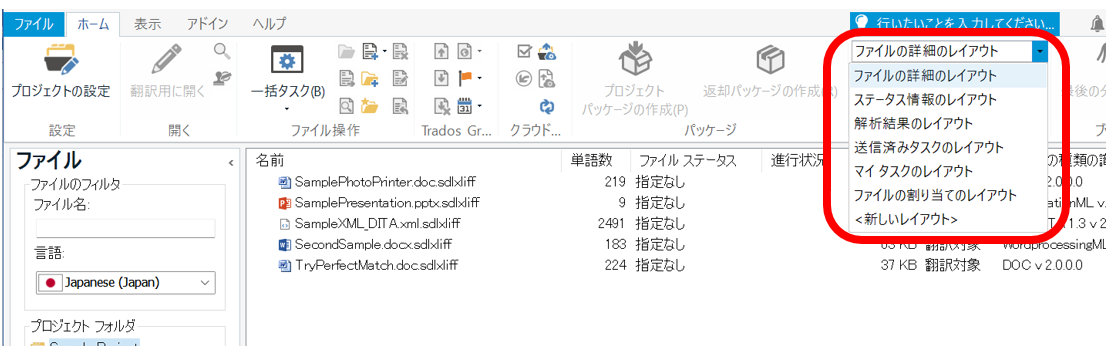
���C�A�E�g�������p�ɕύX����
���낢��ȃ��C�A�E�g������ŗp�ӂ���Ă��܂����A���́A�ǂ����������܂�g�����肪�悭����܂���B�ł��A���v�ł��B���̊���̃��C�A�E�g�̓J�X�^�}�C�Y�ł��܂��B�܂��A�����ł܂������V�������C�A�E�g���쐬���邱�Ƃ��ł��܂��B
�J�X�^�}�C�Y����ꍇ�́A���ږ� (���o���s) �̂ǂ������E�N���b�N���ă��j���[��\�����܂��B���̃��j���[����A�\�����������ڂ�I�����邩�A[�J�X�^�}�C�Y] ��I�����čׂ����ݒ���s���܂��B�܂��A���ږ��Ƀh���b�O �A���h �h���b�v���ĕ\������ړ����邱�Ƃ��ł��܂��B
�V�������C�A�E�g���쐬����ꍇ�́A��}�Ɏ��������C�A�E�g�I��p�̃h���b�v�_�E���ŁA��ԉ��ɂ��� <�V�������C�A�E�g> ��I�����܂��B���}�̂悤�Ȑݒ��ʂ��\�������̂ŁA[�r���[��] �ɐV�������C�A�E�g�̖��O����͂��A��́A�\�����������ڂ�I�����Ă����܂��B
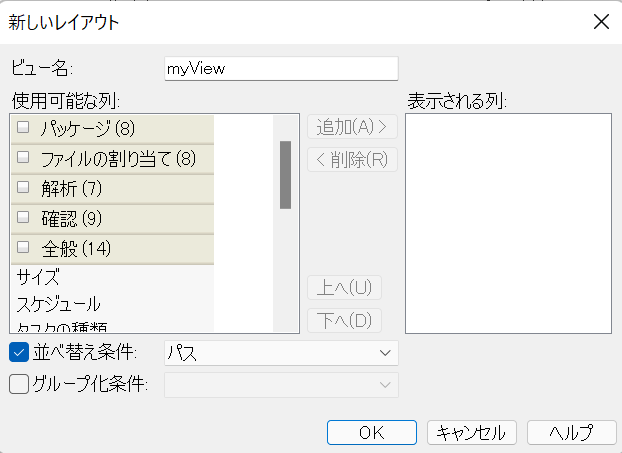
�ȉ��ɁA�����悭�g�p���鍀�ڂ��Љ�܂��B
[�S��] > [�p�X]
�܂��A�t�@�C���ꗗ�̐擪 (���[) �Ƀp�X��\�����܂��B[�T�u�t�H���_���܂߂�] �I�v�V������L���ɂ��Ă���ƑS�t�@�C�����������x���ňꗗ����Ă��܂��܂����A�擪�Ƀp�X��\�����āA�p�X�̒l�ŕ��ёւ������Ă����A�t�H���_�̊K�w�\�����킩��₷���Ȃ�܂��B ����ɁA[�O���[�v������] �Ɂu�p�X�v��I������ƁA�t�@�C�����t�H���_���ƂɃO���[�v������܂��B�t�H���_���d�v�ȈӖ������v���W�F�N�g�ł́A�O���[�v���̕\���ɂ��Ă����Ǝ��o�I�ɂ킩��₷���Ȃ�֗��ł��B
�� ���[�Ƀp�X��\�����A�p�X�̒l�ŕ��ёւ������Ă���

�� ����ɁA�p�X�ŃO���[�v�����邱�Ƃ��ł���
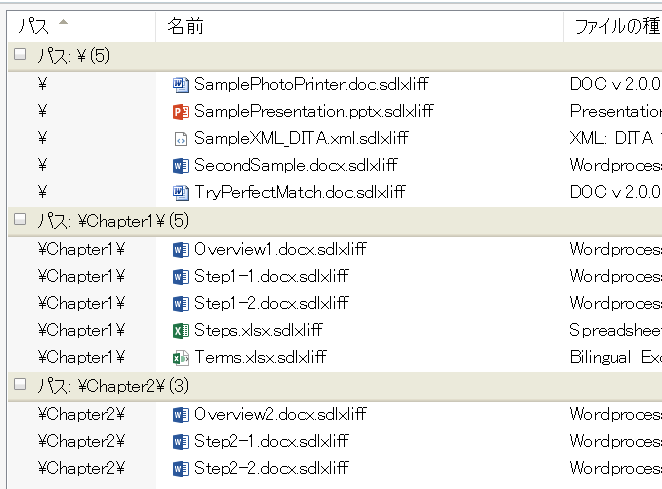
�@
[�S��] > [�t�@�C���̎�ނ̎��ʎq] �� [�g�p�ړI]
�����Ńv���W�F�N�g���쐬����̂ł͂Ȃ��A�|���Ђ���p�b�P�[�W�Ƃ��ăt�@�C�������ꍇ�ł��A�����́u�t�@�C���̎�ށv��m���Ă������Ƃ͑�ł��BQuickInsert �̐ݒ���A���������t�@�C���ɃR�����g���܂߂邩�̐ݒ��ȂǁA�u�t�@�C���̎�ށv�ɂ͂悭�g���ݒ肪�������܂܂�Ă��܂��B�܂��ATrados �̓t�@�C���̎�ނɂ���Ă��Ȃ蓮�삪�قȂ�̂ŁA�����𑼂̐l�ɑ��k�������Ƃ��Ȃǂ́A�܂��t�@�C���̎�ނ�`����Ƙb���X���[�Y�ɐi�މ\���������Ȃ�܂��B
�t�@�C���̎�ނ̓A�C�R���ő�̂킩��܂����A�킩��ɂ����P�[�X������܂��B���Ƃ��AOffice �����̓o�[�W�����ɂ���ăt�@�C���̎�ނ��قȂ�܂����AExcel �ɂ́A�L����X�^�C���p�ɐ�p�̎�ނ��p�ӂ���Ă��܂��B���m�ȁu�t�@�C���̎�ށv����肷��ɂ́A�t�@�C���̎�ނ̎��ʎq���m�F����K�v������܂��B���̎��ʎq�������ɁA[�v���W�F�N�g�̐ݒ�] > [�t�@�C���̎��] �ŊY������t�@�C���̎�ނ������܂��B
�t�@�C���̎�ނƂ��킹�āu�g�p�ړI�v���O�̂��ߕ\�����Ă����܂��B�����܂�ɂł����A�p�b�P�[�W�ɂ͎g�p�ړI���u�|��Ώہv�ł͂Ȃ��u���t�@�����X�v�ƂȂ��Ă���t�@�C�����܂܂�Ă��邱�Ƃ�����܂��B����́A�Q�l�����Ƃ��Ďg���Ă��������A�Ƃ����Ӗ��Ȃ̂ŁA���̃t�@�C���̖|��͕s�v�ł��B
[�m�F] > [�i�s��]
����́A�X�e�[�^�X���m��ς݂ɂȂ��Ă��镪�߂̕����� (�P�ꐔ) �̊����ł��B�ǂꂭ�炢��Ƃ��i��ł��邩�̖ڈ��ɂȂ�܂��B
[�m�F] �Ƃ������ނ̒��ɂ͑��ɂ����������ڂ�����܂����A���̕��ނ̍��ڂ̒l�̓G�f�B�^�[�ō�Ƃ�i�߂�ɂ�Ăǂ�ǂ�ƍX�V����Ă����܂��B����A[���] �Ƃ������ނ̒��ɂ���u100%�v�Ȃǂ̍��ڂ́A�ꊇ�^�X�N�́u�t�@�C���̉�́v�����s���Ȃ��ƍX�V����܂���B�G�f�B�^�[�ō�Ƃ�i�߂Ă��A100% �̒l�͑����Ȃ��̂Œ��ӂ��Ă��������B
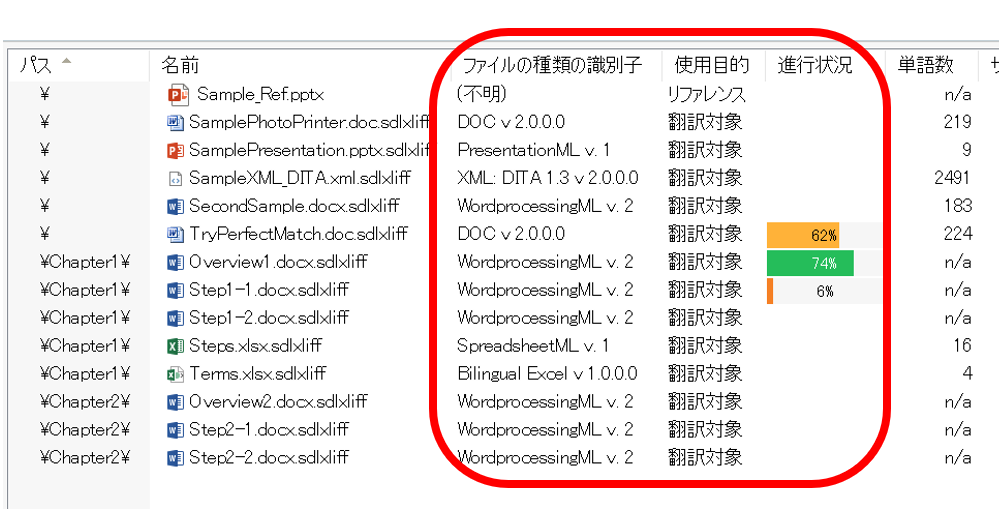
�E�B���h�E�����̃^�u
�Ō�ɁA�t�@�C���ꗗ�̉��ɕ\�������^�u�ɂ��Ă����������������Ă����܂��B�����ɂ́A���{���� [���] �^�u�őI��������\������܂��B�\�������e�y�C���̃��C�A�E�g�́ATrados �̑��̉�ʂƓ��l�A�h���b�O �A���h �h���b�v�Ŏ��R�ɕύX�ł��܂��B
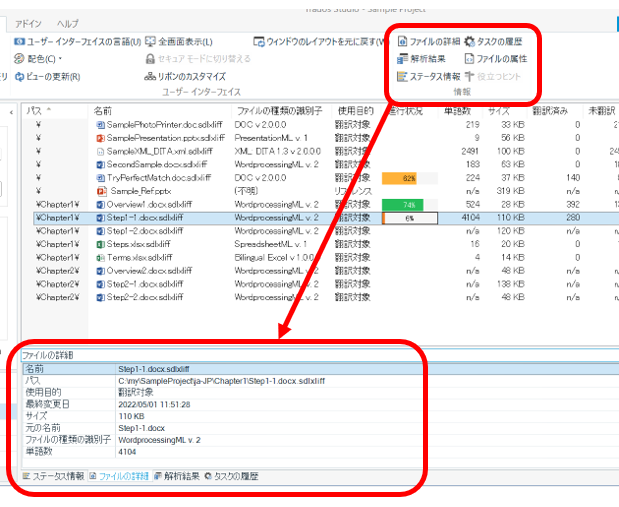
[�t�@�C���̏ڍ�] �^�u
�ꗗ��őI�������t�@�C���̏ڍ�\������܂��B�����Œ��ڂ���̂́u�ŏI�ύX���v�ł��B�e�t�@�C���̍ŏI�ύX���͂����ɂ����\������܂���B�㕔�̈ꗗ�̍��ڂƂ��Ă͕\���ł��Ȃ��̂ŁA�ŏI�ύX�����ɕ��בւ���A�Ƃ���������͂ł��܂���B
�ŏI�ύX���ŕ��בւ��邱�Ƃ��ł��Ȃ��̂́A��ʂ̃t�@�C��������Ƃ��Ȃǂ͂ƂĂ��s�ւł��B�ꉞ�AIdeas �Ƀ��N�G�X�g�͏o�Ă���̂ŁA�����悯��Γ��[�����肢���܂��B
[�X�e�[�^�X���] �^�u�� [��͌���] �^�u
[�X�e�[�^�X���] �^�u�͈ꗗ�ɕ\�����鍀�ڂ̕��ނł����� [�m�F] �ɁA[��͌���] �^�u�� [���] �ɑ������܂��B�ł��̂ŁA[�X�e�[�^�X���] �̓G�f�B�^�[�ō�Ƃ�i�߂�ɂ�čX�V����܂����A[��͌���] �͉�͂��s��Ȃ�����X�V����܂���B�������Ƃ̈�v���܂߂č�Ƃ̐i����m�肽���Ƃ��́A�ꊇ�^�X�N�ʼn�͂����s���Ă��� [��͌���] �^�u���m�F���܂��B
����͈ȏ�ł��B�t�@�C�� �r���[�͕p�ɂɎg����ʂȂ̂ŁA�ʓ|���炸�Ɏ����̎g�����ɍ��킹�ăJ�X�^�}�C�Y���邱�Ƃ������߂��܂��B
| �@�@ |
�^�O�F���C�A�E�g FreshStart �T�u�t�H���_���܂߂� �t�@�C���̎�ނ̎��ʎq ��͌��� �X�e�[�^�X��� �t�@�C���̎�� �t�@�C�� �r���[ QuickInsert
Tweet
2022�N03��28��
�ǂ����Ă������ł��Ȃ��Ƃ�
�����ŋ߁A100MB �߂����� Word �t�@�C���������܂܂��v���W�F�N�g����Ƃ��Ă��Ă����ԍ��������ƂɂȂ��Ă��܂����B�ˑR�A�������ł��Ȃ��Ȃ�A�v���r���[���ł��Ȃ��Ȃ�܂����B��Ɠ������烁�����s���̃G���[���p�����s����ł͂������̂ł����A������v���r���[���ł��Ȃ��̂͒v���I�ł��B
�����ł��Ȃ��Ƃ����Ă��A�����̃v���Z�X���̂̓G���[���Ȃ��������܂��B�����A�������ꂽ�t�@�C���� Word �ŊJ���ƁA�t�@�C�������Ă���Ƃ����G���[���\������A�C������I�v�V������I��ł��̃t�@�C�����\������邾���ł����B
�^�O�̃G���[�͂Ȃ����A�R�����g������Ă��Ȃ����A�\���t�B���^�[�̃n�C���C�g���g���Ă��܂����B���낢��l���Ă��邤���ɁA�O�ɂ������ PowerPoint �t�@�C���Ŗ����ł��Ȃ����Ƃ��������̂��v���o���A�����Ŏ����Ă݂����@���A
�@�v���W�F�N�g��V�����쐬���āA�V�����t�@�C���ō�Ƃ�����
�ł��B����ŁA��������͖����ł���悤�ɂȂ�܂����B��Ƃ������Ƃ����Ă��A���ׂē��͂������킯�ł͂���܂���B������������ɕۑ����A�V�����t�@�C���ɂ��̃������Ē����܂��B�����̎�Ԃ͂�����܂����A�����ł��Ȃ��̂ł���Ύd������܂���B
�������A����ł��u��������v�������������ŁA���炭��Ƃ𑱂��Ă���Ƃ܂��������ł��Ȃ��Ȃ�܂����B���̌�A����Ƀv���W�F�N�g����蒼���Ă݂���A����ɖ����ł��Ă����Ƃ��̃o�C�����K�� �t�@�C�����o�b�N�A�b�v����߂��Ă݂���A�����̃o�C�����K�� �t�@�C�����ꏏ�ɖ߂��Ă݂���A�Ƃ��낢�뎎���Ă��邤���ɁA1 �̖@���ɋC�Â��܂����B
�@������ 1 �s����ƁA������x�Ɛ���Ȑ����͂ł��Ȃ�
�ł��B�V�����v���W�F�N�g���쐬������A1 ��ł����������s����ƁA���̌�̓o�b�N�A�b�v����t�@�C����߂��Ă��A�������Ē����Ă��A�������Ă��A������x�Ɩ����͂ł��܂���B�v���r���[���ł��Ȃ��Ȃ�܂��B�������A����͗���Ԃ��A
�@�u�����v�������Ȃ���A�v���r���[�͂ł���
�Ƃ������Ƃł����B�v���W�F�N�g���쐬������A�ꊇ�^�X�N�́u�����v�͎g�킸�A�u�̕\���v�i[�t�@�C��] > [��� & �\��] > [�\�����@]�ACtrl+Shift+P�j�݂̂��g���悤�ɂ��܂��B�u�̕\���v�ł� Word �Ŗt�@�C�����\�������̂ŁA������ [���O��t���ĕۑ�] ������Ζ����ƌ��ʓI�ɂ͓����ɂȂ�܂��B
�u�̕\���v�@�\�́ATrados ��ʓ��̃v���r���[��ʂ���\������v���r���[�Ƃ͕ʂ̋@�\�ł��B�ڂ����́A������̋L���u�̕\�����g���Ă݂��v���Q�l�ɂ��Ă��������B�u�̕\���v�Ɓu�����v�͕ʋ@�\�Ȃ̂ŁA�ׂ����Ƃ���܂Ō���ƍ쐬�����t�@�C���ɂ͈Ⴂ�����邩������܂���B���A����͎��P��Ƃ��Ďg���܂����B
����͈ȏ�ł��B�Ȃ������ł��Ȃ��̂����{�I�Ȍ����͂킩��Ȃ��܂܂ł����A�����̔[�i�t�@�C�����쐬�ł����Ƃ���ł�����߂܂����B�����ł��Ȃ����͖{���ɍ���܂��B�����A�����ɏ������u������ 1 �s����ƁA���̌�͓�x�Ɛ������Ȃ��v�Ƃ������ۂ́A����̃v���W�F�N�g�Ɍ��������ۂł��B���̌o�����炷��ƁA����� Office �����ɓ��L�̌��ۂ��Ǝv���܂����A���ۂ̂Ƃ���͂悭�킩��܂���B���ʂ́A���������s���Ă��A�G���[���������čĒ��킷��A����ɏ����ł���͂��ł��B�i���Ԃ�ˁB�j
Tweet
�����ł��Ȃ��Ƃ����Ă��A�����̃v���Z�X���̂̓G���[���Ȃ��������܂��B�����A�������ꂽ�t�@�C���� Word �ŊJ���ƁA�t�@�C�������Ă���Ƃ����G���[���\������A�C������I�v�V������I��ł��̃t�@�C�����\������邾���ł����B
�^�O�̃G���[�͂Ȃ����A�R�����g������Ă��Ȃ����A�\���t�B���^�[�̃n�C���C�g���g���Ă��܂����B���낢��l���Ă��邤���ɁA�O�ɂ������ PowerPoint �t�@�C���Ŗ����ł��Ȃ����Ƃ��������̂��v���o���A�����Ŏ����Ă݂����@���A
�@�v���W�F�N�g��V�����쐬���āA�V�����t�@�C���ō�Ƃ�����
�ł��B����ŁA��������͖����ł���悤�ɂȂ�܂����B��Ƃ������Ƃ����Ă��A���ׂē��͂������킯�ł͂���܂���B������������ɕۑ����A�V�����t�@�C���ɂ��̃������Ē����܂��B�����̎�Ԃ͂�����܂����A�����ł��Ȃ��̂ł���Ύd������܂���B
�������A����ł��u��������v�������������ŁA���炭��Ƃ𑱂��Ă���Ƃ܂��������ł��Ȃ��Ȃ�܂����B���̌�A����Ƀv���W�F�N�g����蒼���Ă݂���A����ɖ����ł��Ă����Ƃ��̃o�C�����K�� �t�@�C�����o�b�N�A�b�v����߂��Ă݂���A�����̃o�C�����K�� �t�@�C�����ꏏ�ɖ߂��Ă݂���A�Ƃ��낢�뎎���Ă��邤���ɁA1 �̖@���ɋC�Â��܂����B
�@������ 1 �s����ƁA������x�Ɛ���Ȑ����͂ł��Ȃ�
�ł��B�V�����v���W�F�N�g���쐬������A1 ��ł����������s����ƁA���̌�̓o�b�N�A�b�v����t�@�C����߂��Ă��A�������Ē����Ă��A�������Ă��A������x�Ɩ����͂ł��܂���B�v���r���[���ł��Ȃ��Ȃ�܂��B�������A����͗���Ԃ��A
�@�u�����v�������Ȃ���A�v���r���[�͂ł���
�Ƃ������Ƃł����B�v���W�F�N�g���쐬������A�ꊇ�^�X�N�́u�����v�͎g�킸�A�u�̕\���v�i[�t�@�C��] > [��� & �\��] > [�\�����@]�ACtrl+Shift+P�j�݂̂��g���悤�ɂ��܂��B�u�̕\���v�ł� Word �Ŗt�@�C�����\�������̂ŁA������ [���O��t���ĕۑ�] ������Ζ����ƌ��ʓI�ɂ͓����ɂȂ�܂��B
�u�̕\���v�@�\�́ATrados ��ʓ��̃v���r���[��ʂ���\������v���r���[�Ƃ͕ʂ̋@�\�ł��B�ڂ����́A������̋L���u�̕\�����g���Ă݂��v���Q�l�ɂ��Ă��������B�u�̕\���v�Ɓu�����v�͕ʋ@�\�Ȃ̂ŁA�ׂ����Ƃ���܂Ō���ƍ쐬�����t�@�C���ɂ͈Ⴂ�����邩������܂���B���A����͎��P��Ƃ��Ďg���܂����B
����͈ȏ�ł��B�Ȃ������ł��Ȃ��̂����{�I�Ȍ����͂킩��Ȃ��܂܂ł����A�����̔[�i�t�@�C�����쐬�ł����Ƃ���ł�����߂܂����B�����ł��Ȃ����͖{���ɍ���܂��B�����A�����ɏ������u������ 1 �s����ƁA���̌�͓�x�Ɛ������Ȃ��v�Ƃ������ۂ́A����̃v���W�F�N�g�Ɍ��������ۂł��B���̌o�����炷��ƁA����� Office �����ɓ��L�̌��ۂ��Ǝv���܂����A���ۂ̂Ƃ���͂悭�킩��܂���B���ʂ́A���������s���Ă��A�G���[���������čĒ��킷��A����ɏ����ł���͂��ł��B�i���Ԃ�ˁB�j
| �@�@ |
Tweet