����́A�̂��炠��\���t�B���^�ɂ��� Trados Studio 2021 �ł̌�����Љ�܂��B�\���t�B���^�́A2019 �ŕ֗��ɂȂ������̂́A���Ȃ蕡�G�Ȃ����ɂȂ��Ă��܂����B���ꂪ 2021 �ŏ����������肵���̂ŁA���߂ĕ\���t�B���^�̋@�\���܂Ƃ߂Ă݂����Ǝv���܂��B
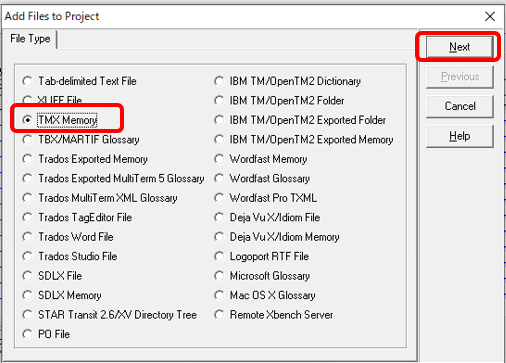
�\���t�B���^�� 2 ����
2021 �ɂ� 2 ��ނ̕\���t�B���^������܂��B(2019 �ł� 3 ��ނł������A���ꂪ 2 �ɂ܂Ƃ߂��܂����B)
�@�E[���r���[] �^�u > �\���t�B���^
�@�E[�\��] �^�u > ���x�ȕ\���t�B���^ 2.0
�u�\���t�B���^�v�́A���߂̃X�e�[�^�X�����̌��ȂǁA������ 1 �����w�肵�Ďg���ȈՓI�ȃt�B���^�ł��B����ɑ��āu���x�ȕ\���t�B���^ 2.0�v�́A���̖��O�̂Ƃ���A���x�ȋ@�\�����ڂ̂��Ȃ蕡�G�ȃt�B���^�ł��B��������̋@�\������̂ŁA���̋L���ł͎����悭�g�����̂����������Љ�����Ǝv���܂��B
�u�\���t�B���^�v�͐��K�\���Ŏw�肷��
���āA�܂��͍��x�ł͂Ȃ��u�\���t�B���^�v�ł��B��قNJȈՓI�ȃt�B���^�ƏЉ�܂������A���͌�����͂���Ƃ��ɐ��K�\�����g���K�v�̂���A�|��҂ɂƂ��Ă͂Ȃ��Ȃ��v���̌������t�B���^�ł��B
���Ƃ��A���p�ۊ��ʂň͂܂ꂽ
(�p��) ���������悤�Ƃ��� (�p��) �Ɠ��͂���ƁA���p�ۊ��ʂ͐��K�\���̎��ƌ��Ȃ���A�p�� ���q�b�g���Ă��܂��B
�����ǂ����
(�p��) ����������ɂ́A�ۊ��ʂ��G�X�P�[�v����K�v������̂ŁA�ۊ��ʂ̑O�ɉ~�}�[�N \ ��t���� \(�p��\) �Ɠ��͂��܂��B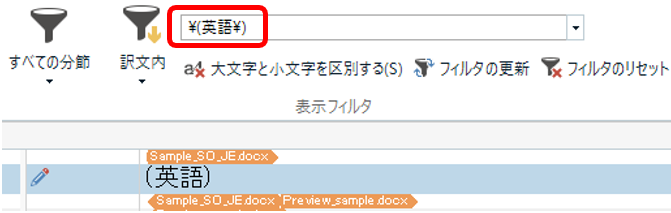
���͐��K�\���͂��܂蓾�ӂł͂���܂��A���́u�~�}�[�N
\ ��t����v�Ƃ������삾���͂悭�g���܂��B���ʂ�A�s���I�h�A�A�X�^���X�N�ȂǁA���K�\���̎����ۂ������̑O�ɂ� \ �}�[�N��t���܂��B(Trados �ł́A�Ȃ������K�\�����g��Ȃ���Ȃ�Ȃ����Ƃ�����AQA Checker �̒P�ꃊ�X�g�������ł��B)���K�\�����ʓ|�ȏꍇ�́u���x�ȕ\���t�B���^ 2.0�v���g���܂��B������ł́A���K�\���������łȂ������w��ł���̂ŁA�����ǂ���̌������ȒP�ɍs���܂��B
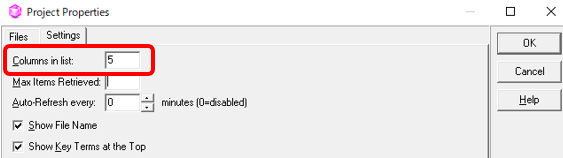
���x�ȕ\���t�B���^ 2.0 �̃V���[�g�J�b�g �L�[��ݒ肷��
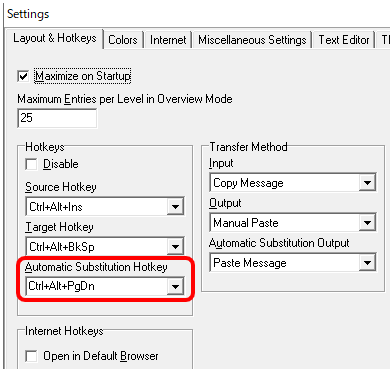
�ł́A���Ɂu���x�ȕ\���t�B���^ 2.0�v�ł��B���x�ȕ\���t�B���^�̓V���[�g�J�b�g �L�[��ݒ肵�Ďg���ƕ֗��ł��B�E�N���b�N�̃��j���[�Ƃ��� 4 �̃R�}���h���p�ӂ���Ă��܂����A����ɃV���[�g�J�b�g �L�[�����蓖�Ă��܂��B
�ݒ�̏ꏊ: [�t�@�C��] > [�I�v�V����] > [�V���[�g�J�b�g �L�[] > [���x�ȕ\���t�B���^ 2.0]

�u�����t�B���^�v�Ɓu�t�B���^�v�́A���ߑS�̂��������̂������ł��܂��B�����܂��͖́u�J��Ԃ��v�𒊏o����悤�ȃC���[�W�ł��B�u�I���t�B���^�v�́A�J�[�\���őI������������Ō��������܂��B������̑I���͌������ł����ł��s�����Ƃ��ł��A�����őI������A�����Ɩ̗����������Ɍ���������܂��B���́A�u�I���t�B���^�v�̃V���[�g�J�b�g �L�[�Ƃ��� Ctrl+Shift+F �����蓖�ĂĂ��܂��B����ŁAMemsource �Ƃقړ������슴���܂��B�ƂĂ��֗��ł��I
���x�ȕ\���t�B���^ 2.0 �\ �R���e���c
��������́A���x�ȕ\���t�B���^�̋@�\���^�u���ƂɌ��Ă��������Ǝv���܂��B�܂��A������Ńt�B���^�����������ꍇ�� [�R���e���c] �^�u���g���܂��B�V���[�g�J�b�g �L�[�ɐݒ肵���u�I���t�B���^�v�́A�I����������������̃^�u�ɐݒ肵�Ă��邾���ł��B

������ [���K�\��] �̃I�v�V����������܂��B���x�ȕ\���t�B���^�ł́A���̃I�v�V������I�����Ȃ�����A�ݒ肵���������K�\���Ƃ��Ĉ����邱�Ƃ͂Ȃ��̂ŁA���p�ۊ��ʂȂǂ����S���Č����ł��܂��B
����� [�^�O �R���e���c������] �I�v�V�������g���ƁA�^�O�̒��̕����������ł��܂��B���Ƃ��A<bold> �^�O�̒��́ubold�v�Ƃ��������Ńt�B���^���������܂��B�ȑO�̍��x�ȕ\���t�B���^�ɂ͂��̃I�v�V�������Ȃ��A�^�O�̒��̕������܂߂Ă��ׂĈꏏ�Ɍ������邱�Ƃ����ł��܂���ł����B���̃I�v�V�������ł��Ă���A�^�O��������A�^�O�̒����������������肷�邱�Ƃ��\�ɂȂ�܂����B
���x�ȕ\���t�B���^ 2.0 �\ �����̃t�B���^
���߂̃X�e�[�^�X�ȂǂŃt�B���^�����������Ƃ��� [�����̃t�B���^] �^�u���g���܂��B���x�ł͂Ȃ��u�\���t�B���^�v�ɂ����l�̍��ڂ�����܂����A�u���x�ȕ\���t�B���^�v�̕������Ȃ荂�x�ł��B���x�߂���̂ŁA�����ȂƂ���ׂ������Ƃ͂悭�킩��܂��A���́uInteractive�v�Ɓu�ŗL�̏o���v���֗����Ǝv���Ă��܂��B
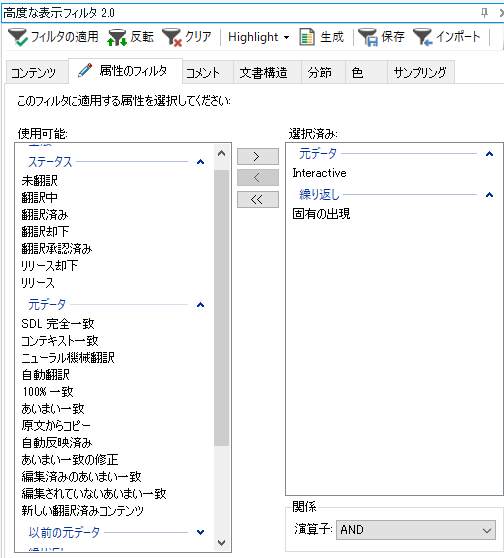
Interactive �\ �����ŕҏW�������߂�����\������
�uInteractive�v�́A�����őΘb�^�ɕҏW�������߂Ƃ����Ӗ����Ǝv���܂� (���̏��������p��̂܂܂ŁA�悭�킩��Ȃ��̂ł����A���͂������߂��Ă��܂�)�B�܂�A�V�K�Ɏ����Ŗ���͂������߂ƁA����������̖ɉ��炩�̕ύX�����������߂ł��B�����炭�A�G�f�B�^�[�̒����̃X�e�[�^�X���ŃA�C�R���������Ȃ��Ă��镪�߂ł��B�u���f�[�^�v�Ɓu�ȑO�̌��f�[�^�v�̗����ɂ��̏���������܂����A���ʂ́u���f�[�^�v�̏������g���đ��v�ł��B(��������̉��߂ł����A�u���f�[�^�v���P���ɍl���Č��݂̃X�e�[�^�X��\���Ă��āA�u�ȑO�̌��f�[�^�v�́A���݂̕ҏW���s���O�̉ߋ��̃X�e�[�^�X��\���Ă���悤�ł��B)

�����A�����̏����ł́A�ǂ̃���������̈�v���͍l������܂���B�܂��A����������m�肵�ă������ɓo�^���āA�����ҏW���āA�܂��m�肵�āA�ȂǂƌJ��Ԃ��Ă���ƃX�e�[�^�X�͂悭�킩��Ȃ���ԂɂȂ�܂��B�ł��̂ŁA�������ҏW�������߂��������������悤�Ƃ����Ƃ��� �uInteractive�v���g���͕̂֗��ł����A����Ɋ��S�ɗ���̂͏����댯�ł��B
�ŗL�̏o�� �\ �d�����Ă��镪�߂��\���ɂ���
�u�ŗL�̏o���v�́A�J��Ԃ��̏���̕��߂ƁA�J��Ԃ��ł͂Ȃ��ʏ�̕��߂�\�����Ă���܂��B(�ȑO�̋L���u���v���O�C���� �t�B���^�ŌJ��Ԃ������O�����v�ł��Љ�Ă���̂ŁA�Q�l�ɂ��Ă��������B) �J��Ԃ��̕��߂��\���ɂł���̂ŁA��������������s���Ƃ��Ȃǂɕ֗��ł��B�u�ŗL�̏o���v�Ńt�B���^�������Ă���S�̂��R�s�[���āA����� Word �ɓ\��t���ĕ��͍Z�����s���A�J��Ԃ��̕��߂ɑ��ăG���[��������o�Ă���悤�Ȃ��Ƃ�������܂��B�����A��L�̋L���ł��������Ă��܂����A���������Ă��邩�ǂ����͂��̃t�B���^�ł͍l������Ȃ��̂ŁA��͂�t�B���^�� 100% �M����̂͊댯�ł��B
���x�ȕ\���t�B���^ 2.0 �\ �����\��
���x�ȋ@�\�͂܂��܂������܂��B[�����\��] �^�u�ł́A�G�f�B�^�[�̉E�[�ɕ\������Ă��镶���\���Ńt�B���^���������܂��B�n�C�o�[�����N�̃A�h���X�����AExcel �̃��[�N�V�[�g�������A������ƍ\��������Ă��镶���������猩�o���̓���̃��x�������ȂǁA���������֗��Ȏg�������ł��܂��B

�����A�����̍\���͂��܂��܂ł����A�ꍇ�ɂ���Ă͂��Ȃ蕡�G�Ȑݒ�ɂȂ��Ă��܂��B���Ƃ��A�����ŋߋ�킵���̂� PowerPoint �̃Z�N�V�����ł��B�Z�N�V�������̓v���r���[���Ă������Ƃ��₷���̂ŁA�t�B���^�������Ĉꊇ�Ń`�F�b�N�������Ǝv���Ă��܂����B
�傫�� PowerPoint �t�@�C���ł́A�X���C�h���������̃Z�N�V�����ɕ�����Ă��邱�Ƃ�����A�����Ă��́A���̃Z�N�V���������|��K�v������܂��B

Trados �̃G�f�B�^�[�ʼnE�[�̕����\�������N���b�N����ƁA�����\���̏ڍׂ��\������܂��B�G�f�B�^�[��ɂ́uS�v��uTB+�v�Ȃ� 1 �̍\�������\������Ă��܂��A�N���b�N���ďڍׂ�\�����Ă݂�ƕ����̍\�����K�w�I�ɐݒ肳��Ă��邱�Ƃ��킩��܂��B ���� 24 �� 25 �̗����Ɂu�Z�N�V�������v������̂ŁA�P���Ɂu�Z�N�V�������v�Ńt�B���^�������Ă��Z�N�V�������̕��߂����𒊏o���邱�Ƃ͂ł��܂���B
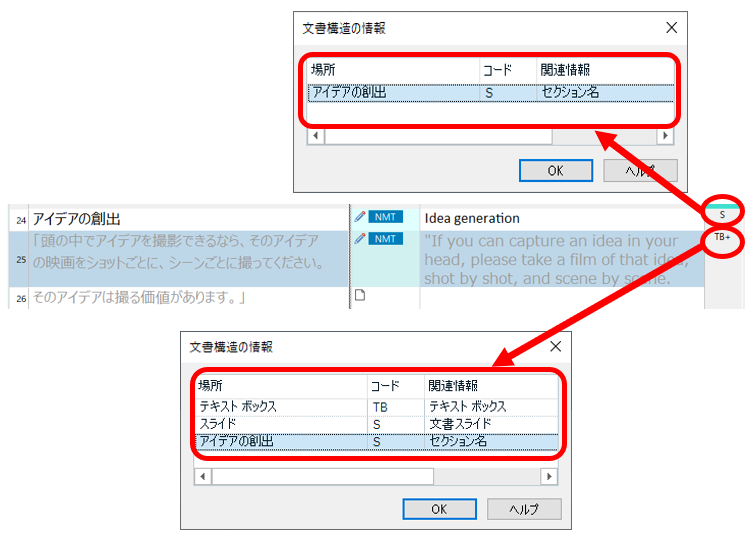
�u�Z�N�V�������v��I������ [�t�B���^�̓K�p] �����Ă��A�Z�N�V�����������𒊏o���邱�Ƃ͂ł��Ȃ�
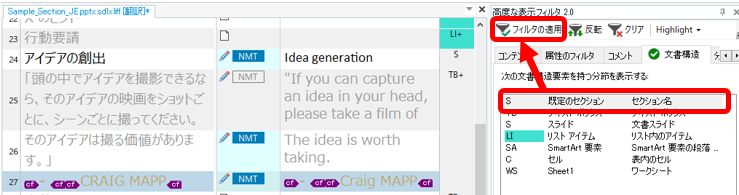
�u�����X���C�h�v��I������ [���]] ������ƁA�����X���C�h�����O����A���ʓI�ɃZ�N�V�����������o�����

�����X���C�h�ƃZ�N�V�������̓R�[�h������ �uS�v�ł��邱�Ƃ������������������ł����B�ŏ��̓R�[�h������������t�B���^�����܂��@�\���Ȃ��̂ł͂Ȃ����Ǝv���Ă��܂������A����͖��ł͂Ȃ��悤�ł����B���ǁA������ے肷�� [���]] ���g���܂������A�ǂ����������藝���͂ł��܂���B
�����ɋ������ȊO�ɂ��܂��^�u�͂���܂��B�܂��A�����̃^�u�ŏ������w�肵�ăt�B���^�������邱�Ƃ��ł��܂��B�����̏������w�肵�� [���]] ����ȂǁA�l����l����قǕ��G�ɂȂ��Ă����̂ŁA���͓K���ȂƂ���ł�����߂Ă��܂��B
���x�ȕ\���t�B���^�͕ύX�������T�|�[�g���Ȃ�
���x�ȕ\���t�B���^�͂��낢�덂�x�ł����A�ύX�����ɂ͑Ή����Ă��܂���B�ύX�������c���č�Ƃ��Ă���Ƃ��ɁA�ύX��̖ɑ��ăt�B���^�������邱�Ƃ��ł��܂���B���x�ł͂Ȃ����́u�\���t�B���^�v�́A�ύX�������c���Ă��Ă��A�ύX��̖ɑ��ăt�B���^�������邱�Ƃ��ł��܂��B
���x�ȕ\���t�B���^�̏ꍇ�A�ύX�����̓^�O���̕����Ƃ��ĔF�������炵���A[�^�O �R���e���c������] �I�v�V�������g���ΕύX������������������邱�Ƃ͂ł��܂��B�����A�lj�������������폜������������S���܂Ƃ߂Č��������̂ŁA���܂�Ӗ�������܂���B
����ɂ��ẮARWS Community �� Ideas �ɗv�]�𓊍e���Ă��܂��B���r���[��Ƃł����x�ȕ\���t�B���^���g�������Ƃ������A���Ў^���̓��[�����肢�v���܂��B
���x�ȃW�����v�@�\���~����
�O��̕\���t�B���^�Љ�L���ł������܂������A�\���t�B���^�͂ǂ�Ȃɋ@�\�����x�ɂ��Ă��A�|��҂ɂƂ��Ă͂��������g���ɂ����@�\�ł��B�t�B���^�������ĕ��߂��\���ɂ��Ă��܂��ƁA��ƑΏۂ̕��߂̑O�オ�����Ȃ��̂ŁA���ǁA�t�B���^���������đO���\�����Ă����Ƃ��邱�Ƃ������Ȃ�܂��B
�t�B���^�������Ĕ�\���ɂ��Ă��܂����Ƃ����l�����́A����̏����ňꊇ�������s�������R�[�f�B�l�[�^�[����̍l�����̂悤�Ɏv���܂��B1 �� 1 �̕��߂���Ƃ��Ă����|��҂ɂ́A�W�����v�@�\ (Ctrl+G) �̕����֗��ł��B�S�̂�\�������܂܁A��]�̕��߂ɃW�����v�ł�������A�O��̕��߂����Ȃ����Ƃł���̂Ō����I�ł��B�W�����v�@�\�̍��x�����Ɋ���Ă��܂��B
���Ȃ蒷���Ȃ�܂����B�u���x�ȕ\���t�B���^ 2.0�v�ɂ́A�����ŏЉ���ȊO�ɂ��܂��܂��@�\����������܂��B�܂��A�����֗��Ȏg��������������A�Љ�����Ǝv���܂��B
| �@�@ |
�^�O�F�ύX���� �V���[�g�J�b�g �L�[ �����\�� ���x�ȕ\���t�B���^ ���x�ȕ\���t�B���^ 2.0 �\���t�B���^ Interactive �I���t�B���^ �W�����v �Z�N�V������ �ŗL�̏o��
Tweet