


�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
�L��
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
posted by fanblog
2023�N08��28��
�����������Ă����肢�낢��
���̃u���O�̋L���������Ƃ��́A���������ł��𗧂����܂߂����ƍl���A�o�O��s������グ��Ƃ����A�Ȃ�ׂ��������@������i���ꏏ�ɏ����悤�ɂ��Ă��܂����B�����A���݂܂���A���̂Ƃ��뎄�p�ł��낢�날�肠�܂莞�Ԃ����Ȃ��̂ŁA����͎��������������Ƃ̂�������Ƃ肠�������Ă݂����Ǝv���܂��B
�{���Ȃ班�����������Ă���L���������Ƃ���ł����A����͂قƂ�lj������ׂ��肵�Ă��܂���B���̊����L�̂��̂��܂܂�Ă��邩�Ǝv���܂����A�����u�����悤�Ȗ�肪��������I�v�Ƃ��A�u����������璼�����I�v�Ȃǂ̏����܂����狤�L���Ă��炦��Ɗ������ł��B
���C�Z���X�̃A�N�e�B�x�[�V������ʂŁA�V���[�g�J�b�g �L�[���g���ă��C�Z���X �L�[��\��t�����Ȃ�
���C�Z���X �L�[��\��t����Ƃ��ɃL�[�{�[�h�� Ctrl+V �͋@�\�����A�\��t���̃A�C�R�����}�E�X�ŃN���b�N����K�v������܂��B�}�E�X��������Ȃ���Ȃ�Ȃ��̂́A���ɂƂ��Ă͔��ɖʓ|�ł��B
�X�y�� �`�F�b�J�[�� MS Word ��I���ł��Ȃ�
MS Word ��I������ƃG���[�ɂȂ�̂ŁA�d���Ȃ������ Hunspell ���g���Ă��܂��BMS Word �̕������x���ǂ������ȋC������̂� MS Word �ɐ�ւ������̂ł����A���ꂪ�ł��܂���B
Trados ������������āAWord ���J���Ă���t�@�C�������ׂĕ��āA���̌�ʼn��߂� Trados ���N������ƁAMS Word ��I���ł��邱�Ƃ� (���܂�) ����܂��B
�ύX�������I���ɂ��č�Ƃ��Ă���Ƃ��ɁA�G�f�B�^�[���悭�����I������
���b�Z�[�W�������Ȃ���ʂ������Ă��܂����Ƃ�����܂��B���ɁAShift+F3 �ő啶���������̕ϊ��������Ƃ��ɉ�ʂ������邱�Ƃ������C�����܂��B�����AShift+F3 ���������Ƃ��͗��Ɂu���߂�}���ł��܂���v�Ƃ������b�Z�[�W���\������Ă��邱�Ƃ�����܂��B
�ύX�������I���ɂ��č�Ƃ��Ă���Ƃ��ɁA�������I�����ăR�����g��lj��ł��Ȃ�
���ߑS�̂ɑ���R�����g�͒lj��ł��܂����A���ߓ��̕�����ɑ��ẴR�����g�͒lj��ł��Ȃ����Ƃ������ł��B
Quick Insert �ŁA�V���[�g�J�b�g �L�[�� Ctrl+Shift+0 �Ɋ��蓖�Ă���Ƌ@�\���Ȃ�
����͈ȑO�̋L���uQuickInsert ��ݒ肷��Ƃ��ɒ��ӂ����������v�ł��Љ�܂����B�������Ȃ蒷���Ԃ��̏�Ԃ������Ă���C�����܂��B1 ��o�^���āACtrl+Shift+0 �����蓖�Ă�ꂽ��A����͂��̂܂܂ɂ��Ă�����x�o�^���܂��B�ʓ|�ł��B
Word �t�@�C�����v���r���[������A�v���r���[�̃t�@�C�������Ƃ��ɁuNormal.dot �� �`�`�v�Ƃ������b�Z�[�W���\������ăE�B���h�E�������ɕ����Ȃ�
����� Word �̃}�N����ݒ肵�Ă���̂��������Ǝv���܂��B�����Őݒ肷��}�N���� Normal.dot �ȊO�ɓo�^��������̂ł͂Ȃ����A�Ǝv���Ă͂���̂ł����A���̂Ƃ�����u���Ă��܂��B
Trados �̉�ʂ��ő剻���Ă��A��ʉ����̕������Ȃǂ̐��������S�ɕ\������Ȃ�
Trados ���N����������͉�ʉE���̐������������炢�����\������܂���B���������ʂ̑傫�����蓮�ŕς��āA���߂čő剻����Ɗ��S�ɕ\�������悤�ɂȂ�܂��B
�e���L�[���琔���̓��͂��ł��Ȃ�
���݂̂Ƃ���A���ɂƂ��čő�̖��͂��ꂩ������Ȃ��ł��BTrados ��Ńe���L�[����̓��͂��ł��Ȃ��ꍇ�ł��A���̃A�v���ɉ�ʂ��ւ���Ɛ���ɓ��͂��ł���̂ŁANumLock �Ƃ��̖��ł͂Ȃ��Ǝv���̂ł����悭�킩��܂���B
���Ȃ݂ɁA���������͂ł��Ȃ������ŁA�e���L�[�� Enter �L�[�Ȃǂ͋@�\���܂��B���ꂪ�܂���������ŁA��������͂��� Enter �L�[�����������肪�AEnter �L�[�����������ꂽ��ԂɂȂ�܂��B
�v���W�F�N�g�̐ݒ��ʂŁA��ʂ̑J�ڂ����̂������x���Ȃ�Ƃ�������
�ǂ������Ƃ��ɒx���Ȃ�̂��Ȃǂ͂킩��Ȃ��̂ł����A�Ƃɂ����A���̂������x���đ҂�����Ȃ��Ƃ�������܂��B
�t�@�C�� ���X�g��ʂŁA�u�X�e�[�^�X���v�^�u�̐�����P�ꐔ�ƕ������Ő�ւ����Ȃ�
���p�|��̏ꍇ�͊���P�ꐔ�ł͂Ȃ��������ɂȂ�̂ŁA�X�e�[�^�X�Ȃǂ��������ŕ\�����Ăق����̂ł����A������ւ���h���b�v�_�E�� ���X�g���\������܂���B��������ʂ̃^�u��\�����Ă���߂��Ă���ƁA���̃h���b�v�_�E�� ���X�g���\������܂��B
���A���^�C�� �v���r���[���g���ƁATrados �̃G�f�B�^�[��̃J�[�\���������Ă��܂�
�o�[�W���� 2022 �Ńv���r���[�͉��P����Ă���炵���̂ł����A�{���ł��傤�� �B(��������������͉��P����Ă��Ȃ��悤�ł����B)
�J�[�\���������Ă��܂����ꍇ�́ACtrl+0 �������ƃJ�[�\�������ɕ������܂��B�����͂��܂����A���������ʓ|�������Ă���Ă��܂���B
�v���O�C���� MSWord Grammer Checker ���x�����Ďg���Ȃ�
�����Ђ���� MSWord Grammer Checker ���g���Č����s���悤�Ɏw�����ꂽ�̂ł����A���ɂ����鎞�Ԃ��ƂĂ������Ȃ�܂��B�傫�ȃt�@�C���ɂȂ�ƁA�܂��A�҂��Ă����܂���B
�v���O�C���� SDLXLIFF Compare ���g���ƁA�G�f�B�^�[��ʂɈڂ��Ă��A���̃v���O�C���̎c�����\�������
SDLXLIFF Compare ���g������A�G�f�B�^�[��ɂ��̃v���O�C���̑����ʂ��\������Ă��܂��A���܂��܂��̕������N���b�N�����肷��ƁA���̃N���b�N���v���O�C���ɑ��Č����Ă��܂��܂��B�����A���炭����Ƃ��̌��ۂ͂Ȃ��Ȃ�C�����܂��B
�ȏ�ł��B��������������ڍׂ��킩�����肵����A�܂����߂ċL�������������Ǝv���܂��B����Ȃɂ��낢�날���Ă� Trados ���g�������Ă����Ԃ͂ǂ��Ȃ낤�Ǝv��Ȃ����Ȃ��ł����A���Ԃ�A�܂����炭�͎g�������Ă��܂��C�����܂��B

�{���Ȃ班�����������Ă���L���������Ƃ���ł����A����͂قƂ�lj������ׂ��肵�Ă��܂���B���̊����L�̂��̂��܂܂�Ă��邩�Ǝv���܂����A�����u�����悤�Ȗ�肪��������I�v�Ƃ��A�u����������璼�����I�v�Ȃǂ̏����܂����狤�L���Ă��炦��Ɗ������ł��B
���C�Z���X�̃A�N�e�B�x�[�V������ʂŁA�V���[�g�J�b�g �L�[���g���ă��C�Z���X �L�[��\��t�����Ȃ�
���C�Z���X �L�[��\��t����Ƃ��ɃL�[�{�[�h�� Ctrl+V �͋@�\�����A�\��t���̃A�C�R�����}�E�X�ŃN���b�N����K�v������܂��B�}�E�X��������Ȃ���Ȃ�Ȃ��̂́A���ɂƂ��Ă͔��ɖʓ|�ł��B
�X�y�� �`�F�b�J�[�� MS Word ��I���ł��Ȃ�
MS Word ��I������ƃG���[�ɂȂ�̂ŁA�d���Ȃ������ Hunspell ���g���Ă��܂��BMS Word �̕������x���ǂ������ȋC������̂� MS Word �ɐ�ւ������̂ł����A���ꂪ�ł��܂���B
Trados ������������āAWord ���J���Ă���t�@�C�������ׂĕ��āA���̌�ʼn��߂� Trados ���N������ƁAMS Word ��I���ł��邱�Ƃ� (���܂�) ����܂��B
�ύX�������I���ɂ��č�Ƃ��Ă���Ƃ��ɁA�G�f�B�^�[���悭�����I������
���b�Z�[�W�������Ȃ���ʂ������Ă��܂����Ƃ�����܂��B���ɁAShift+F3 �ő啶���������̕ϊ��������Ƃ��ɉ�ʂ������邱�Ƃ������C�����܂��B�����AShift+F3 ���������Ƃ��͗��Ɂu���߂�}���ł��܂���v�Ƃ������b�Z�[�W���\������Ă��邱�Ƃ�����܂��B
�ύX�������I���ɂ��č�Ƃ��Ă���Ƃ��ɁA�������I�����ăR�����g��lj��ł��Ȃ�
���ߑS�̂ɑ���R�����g�͒lj��ł��܂����A���ߓ��̕�����ɑ��ẴR�����g�͒lj��ł��Ȃ����Ƃ������ł��B
Quick Insert �ŁA�V���[�g�J�b�g �L�[�� Ctrl+Shift+0 �Ɋ��蓖�Ă���Ƌ@�\���Ȃ�
����͈ȑO�̋L���uQuickInsert ��ݒ肷��Ƃ��ɒ��ӂ����������v�ł��Љ�܂����B�������Ȃ蒷���Ԃ��̏�Ԃ������Ă���C�����܂��B1 ��o�^���āACtrl+Shift+0 �����蓖�Ă�ꂽ��A����͂��̂܂܂ɂ��Ă�����x�o�^���܂��B�ʓ|�ł��B
Word �t�@�C�����v���r���[������A�v���r���[�̃t�@�C�������Ƃ��ɁuNormal.dot �� �`�`�v�Ƃ������b�Z�[�W���\������ăE�B���h�E�������ɕ����Ȃ�
����� Word �̃}�N����ݒ肵�Ă���̂��������Ǝv���܂��B�����Őݒ肷��}�N���� Normal.dot �ȊO�ɓo�^��������̂ł͂Ȃ����A�Ǝv���Ă͂���̂ł����A���̂Ƃ�����u���Ă��܂��B
Trados �̉�ʂ��ő剻���Ă��A��ʉ����̕������Ȃǂ̐��������S�ɕ\������Ȃ�
Trados ���N����������͉�ʉE���̐������������炢�����\������܂���B���������ʂ̑傫�����蓮�ŕς��āA���߂čő剻����Ɗ��S�ɕ\�������悤�ɂȂ�܂��B
�e���L�[���琔���̓��͂��ł��Ȃ�
���݂̂Ƃ���A���ɂƂ��čő�̖��͂��ꂩ������Ȃ��ł��BTrados ��Ńe���L�[����̓��͂��ł��Ȃ��ꍇ�ł��A���̃A�v���ɉ�ʂ��ւ���Ɛ���ɓ��͂��ł���̂ŁANumLock �Ƃ��̖��ł͂Ȃ��Ǝv���̂ł����悭�킩��܂���B
���Ȃ݂ɁA���������͂ł��Ȃ������ŁA�e���L�[�� Enter �L�[�Ȃǂ͋@�\���܂��B���ꂪ�܂���������ŁA��������͂��� Enter �L�[�����������肪�AEnter �L�[�����������ꂽ��ԂɂȂ�܂��B
�v���W�F�N�g�̐ݒ��ʂŁA��ʂ̑J�ڂ����̂������x���Ȃ�Ƃ�������
�ǂ������Ƃ��ɒx���Ȃ�̂��Ȃǂ͂킩��Ȃ��̂ł����A�Ƃɂ����A���̂������x���đ҂�����Ȃ��Ƃ�������܂��B
�t�@�C�� ���X�g��ʂŁA�u�X�e�[�^�X���v�^�u�̐�����P�ꐔ�ƕ������Ő�ւ����Ȃ�
���p�|��̏ꍇ�͊���P�ꐔ�ł͂Ȃ��������ɂȂ�̂ŁA�X�e�[�^�X�Ȃǂ��������ŕ\�����Ăق����̂ł����A������ւ���h���b�v�_�E�� ���X�g���\������܂���B��������ʂ̃^�u��\�����Ă���߂��Ă���ƁA���̃h���b�v�_�E�� ���X�g���\������܂��B
���A���^�C�� �v���r���[���g���ƁATrados �̃G�f�B�^�[��̃J�[�\���������Ă��܂�
�o�[�W���� 2022 �Ńv���r���[�͉��P����Ă���炵���̂ł����A�{���ł��傤�� �B(��������������͉��P����Ă��Ȃ��悤�ł����B)
�J�[�\���������Ă��܂����ꍇ�́ACtrl+0 �������ƃJ�[�\�������ɕ������܂��B�����͂��܂����A���������ʓ|�������Ă���Ă��܂���B
�v���O�C���� MSWord Grammer Checker ���x�����Ďg���Ȃ�
�����Ђ���� MSWord Grammer Checker ���g���Č����s���悤�Ɏw�����ꂽ�̂ł����A���ɂ����鎞�Ԃ��ƂĂ������Ȃ�܂��B�傫�ȃt�@�C���ɂȂ�ƁA�܂��A�҂��Ă����܂���B
�v���O�C���� SDLXLIFF Compare ���g���ƁA�G�f�B�^�[��ʂɈڂ��Ă��A���̃v���O�C���̎c�����\�������
SDLXLIFF Compare ���g������A�G�f�B�^�[��ɂ��̃v���O�C���̑����ʂ��\������Ă��܂��A���܂��܂��̕������N���b�N�����肷��ƁA���̃N���b�N���v���O�C���ɑ��Č����Ă��܂��܂��B�����A���炭����Ƃ��̌��ۂ͂Ȃ��Ȃ�C�����܂��B
�ȏ�ł��B��������������ڍׂ��킩�����肵����A�܂����߂ċL�������������Ǝv���܂��B����Ȃɂ��낢�날���Ă� Trados ���g�������Ă����Ԃ͂ǂ��Ȃ낤�Ǝv��Ȃ����Ȃ��ł����A���Ԃ�A�܂����炭�͎g�������Ă��܂��C�����܂��B
�^�O�FMSWord Grammer Checker SDLXLIFF Compare �v���r���[ ���A���^�C�� �v���r���[ �X�e�[�^�X��� Normal.dot �g���u���V���[�e�B���O �ύX���� �R�����g
Tweet
2023�N07��03��
Xbench �� TBX �t�@�C��
Trados �̃�������p��x�[�X�̌����@�\�͂��Ȃ�n��Ȃ̂ŁA���� Xbench ���悭�g�p���Ă��܂��BXbench �̎g�p���@�ɂ��Ă��ȑO�ɋL���������Ă��܂����A���́A�����Ő����������@�ł͂��܂������ł��Ȃ��p��x�[�X�����邱�Ƃɍ����ɂȂ��ċC�t�����̂ŁA����͂��̑Ώ��@�Ȃǂ��Љ�����Ǝv���܂��B
�O���Ƃ��āA���� Xbench �̖����� (�o�[�W���� 2.9) ���g�p���Ă��܂��B�L���ł�������A�����������獡��̖��͋N���Ȃ��̂�������Ȃ��ł����A�ǂ��ł��傤�B������Ǝ����ł͎����Ȃ��̂ŁA���������܂����為�Ђ����������B
���āAXbench �ł��܂������ł��Ȃ��̂́A����Ɩ��̑g�ݍ��킹�� 1 �� 1 �łȂ��p��x�[�X�ł��B���̂悤�ȗp��x�[�X (.sdltb) �� Glossary Converter ���g���� TBX �t�@�C���ɕϊ����AXbench �Ō������s���ƁA�����̖�ꂪ�����Ă� 1 �̖�ꂵ���q�b�g���Ă��܂���B
���Ƃ��A�p��x�[�X�ŁA�ȉ��̂悤�� interlock �ɑ��āu�C���^�[���b�N�v�Ɓu���S���u�v�Ƃ��� 2 �̒P�ꂪ�o�^����Ă����Ƃ��܂��B

�����P���� TBX �t�@�C���ɕϊ����� Xbench �Ɏ�荞�ނƁA�u���S���u�v�����q�b�g���Ă��܂���B
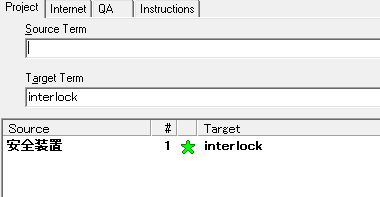
�������A���̏ꍇ�ł� TBX �t�@�C���ɂ́u�C���^�[���b�N�v�Ɓu���S���u�v�̗���������ɋL�q����Ă��܂��B�܂�AXbench �̌����@�\�� 1 �����������Ȃ��Ƃ������Ƃ̂悤�ł��B
�ŁA�ǂ��������̂��ƍl�������A����́ATBX �t�@�C���ł͂Ȃ��A�^�u���t�@�C�����g�����Ƃɂ��܂����B�菇�͂���Ȋ����ł��B
�@1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
�@2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�ł́A�菇�����Ԃɐ������Ă����܂��傤�B
Glossary Converter �ł̕ϊ����@�ɂ��ẮA�ȑO�̋L���u�y�O�ҁzXbench ��֗��Ɏg���v�Ɓu�y��ҁz�}�C�N���\�t�g�̗p��W���g�������v���Q�l�ɂ��Ă��������B
�܂��A[setting] > [General] �� �uExcel 2007 Workbook�v��I�����܂��B����ŁA�p��x�[�X (.sdltb �t�@�C��) �� Excel �t�@�C���ɕϊ������悤�ɂȂ�܂��B
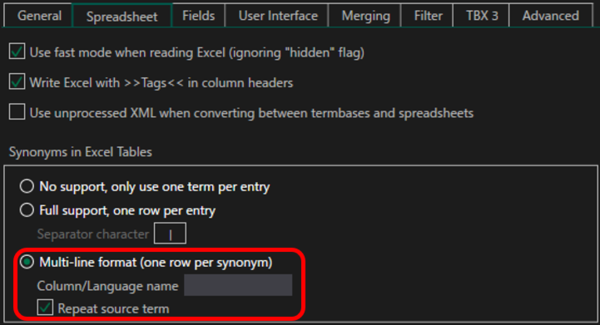
����ɁA[Spreadsheet] �^�u�� [Synonyms in Excel Tables] ��ݒ肵�܂��B[Multi-line format (one row per synonym)] �I�v�V������I�����A[Repeat source term] �`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA�����̗p�ꂪ����ꍇ�͕����̍s���쐬����A���ꂼ��̍s�Ɍ��ꂪ�L�q�����悤�ɂȂ�܂��B([Column/Language name] �͋̂܂܂ł����v�ł��B�ݒ肪�K�v�ȏꍇ�ɂ́A�ϊ��̎��s���Ƀv�����v�g���\������Ă��܂��B)
�����܂Őݒ��������AGlossary Converter �̃A�v����ɑΏۂ̗p��x�[�X �t�@�C�����h���b�O�A���h�h���b�v���܂��B����ŁA���̗p��x�[�X�Ɠ����t�H���_�[�� Excel �t�@�C�����쐬����܂��B
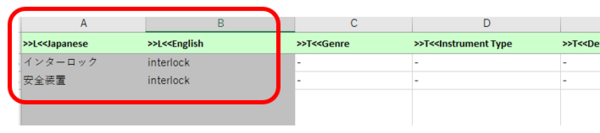
�쐬���ꂽ Excel �t�@�C�����J���āAXbench �������ł���`�Ƀf�[�^�𐮂��܂��B��̍���ł���p��x�[�X�̏ꍇ�́A�����Ă��A����Ɩ��ȊO�ɎQ�l���̃t�B�[���h���������ݒ肳��Ă��܂��B�����̃t�B�[���h�� Excel �t�@�C���̗�Ƃ��ďo�͂���܂����AXbench �͏�� A �������AB �����Ƃ��Č������s���̂ŁAExcel �t�@�C����ł��̂悤�ɗ����וς���K�v������܂��B�s�v�ȗ�͍폜���č\���܂��A�Q�l���� Xbench �ŕ\���������ꍇ�� C ��ȍ~�ɂ��̏����c���Ă����܂��B
��𐮂����� [���O��t���ĕۑ�] �����܂����A���̂Ƃ��� [�t�@�C���̎��] �Ƃ��āu�e�L�X�g (�^�u���) (*.txt)�v��I�����܂��B����ŁAXbench �ɓǂݍ��߂�^�u���t�@�C�����ł�������܂��B
�쐬�����^�u���t�@�C�� (.txt) �� Xbench �ɁuTab-delimited Text File�v�Ƃ��Ď�荞�ނƁA�ȉ��̂悤�ɕ����̗p�ꂪ�q�b�g���Ă��܂��B����Ŋ����ł��B
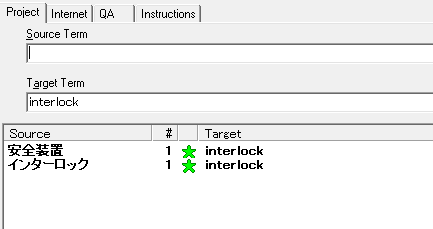
����͈ȏ�ł��B1 �� 1 �łȂ��p��x�[�X�� TBX �t�@�C�������܂������ł��Ȃ����ƂɂȂ����܂ŋC�t���Ȃ������̂��A������Ƌ��낵���Ȃ����̂Ŋm�F���Ă݂��Ƃ���A����Ȍ`���̗p��x�[�X�͎��͂قƂ�ǂ���܂���ł����B�����Ă��̏ꍇ�AExcel �t�@�C������ɂ���A���̎��_�� 1 �� 1 �ɂȂ��Ă��邩�A�Ȃ��Ă��Ȃ��ꍇ�� Excel �t�@�C����ŕҏW�����Ė������ 1 �� 1 �ɂ��Ă��܂����B�Ƃ͂����A����������h�����߁ATBX �t�@�C���� 1 �� 1 �ł��邱�Ƃ��m�F���Ă��� Xbench �Ɏ�荞�ޕK�v������܂��B
Tweet
�O���Ƃ��āA���� Xbench �̖����� (�o�[�W���� 2.9) ���g�p���Ă��܂��B�L���ł�������A�����������獡��̖��͋N���Ȃ��̂�������Ȃ��ł����A�ǂ��ł��傤�B������Ǝ����ł͎����Ȃ��̂ŁA���������܂����為�Ђ����������B
���āAXbench �ł��܂������ł��Ȃ��̂́A����Ɩ��̑g�ݍ��킹�� 1 �� 1 �łȂ��p��x�[�X�ł��B���̂悤�ȗp��x�[�X (.sdltb) �� Glossary Converter ���g���� TBX �t�@�C���ɕϊ����AXbench �Ō������s���ƁA�����̖�ꂪ�����Ă� 1 �̖�ꂵ���q�b�g���Ă��܂���B
���Ƃ��A�p��x�[�X�ŁA�ȉ��̂悤�� interlock �ɑ��āu�C���^�[���b�N�v�Ɓu���S���u�v�Ƃ��� 2 �̒P�ꂪ�o�^����Ă����Ƃ��܂��B

�����P���� TBX �t�@�C���ɕϊ����� Xbench �Ɏ�荞�ނƁA�u���S���u�v�����q�b�g���Ă��܂���B

�������A���̏ꍇ�ł� TBX �t�@�C���ɂ́u�C���^�[���b�N�v�Ɓu���S���u�v�̗���������ɋL�q����Ă��܂��B�܂�AXbench �̌����@�\�� 1 �����������Ȃ��Ƃ������Ƃ̂悤�ł��B
�ŁA�ǂ��������̂��ƍl�������A����́ATBX �t�@�C���ł͂Ȃ��A�^�u���t�@�C�����g�����Ƃɂ��܂����B�菇�͂���Ȋ����ł��B
�@1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
�@2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�ł́A�菇�����Ԃɐ������Ă����܂��傤�B
1. Glossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ�����
Glossary Converter �ł̕ϊ����@�ɂ��ẮA�ȑO�̋L���u�y�O�ҁzXbench ��֗��Ɏg���v�Ɓu�y��ҁz�}�C�N���\�t�g�̗p��W���g�������v���Q�l�ɂ��Ă��������B
�܂��A[setting] > [General] �� �uExcel 2007 Workbook�v��I�����܂��B����ŁA�p��x�[�X (.sdltb �t�@�C��) �� Excel �t�@�C���ɕϊ������悤�ɂȂ�܂��B
����ɁA[Spreadsheet] �^�u�� [Synonyms in Excel Tables] ��ݒ肵�܂��B[Multi-line format (one row per synonym)] �I�v�V������I�����A[Repeat source term] �`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA�����̗p�ꂪ����ꍇ�͕����̍s���쐬����A���ꂼ��̍s�Ɍ��ꂪ�L�q�����悤�ɂȂ�܂��B([Column/Language name] �͋̂܂܂ł����v�ł��B�ݒ肪�K�v�ȏꍇ�ɂ́A�ϊ��̎��s���Ƀv�����v�g���\������Ă��܂��B)

�����܂Őݒ��������AGlossary Converter �̃A�v����ɑΏۂ̗p��x�[�X �t�@�C�����h���b�O�A���h�h���b�v���܂��B����ŁA���̗p��x�[�X�Ɠ����t�H���_�[�� Excel �t�@�C�����쐬����܂��B
2. Excel �Ńf�[�^��ҏW���A�^�u���`���ŕۑ�����
�쐬���ꂽ Excel �t�@�C�����J���āAXbench �������ł���`�Ƀf�[�^�𐮂��܂��B��̍���ł���p��x�[�X�̏ꍇ�́A�����Ă��A����Ɩ��ȊO�ɎQ�l���̃t�B�[���h���������ݒ肳��Ă��܂��B�����̃t�B�[���h�� Excel �t�@�C���̗�Ƃ��ďo�͂���܂����AXbench �͏�� A �������AB �����Ƃ��Č������s���̂ŁAExcel �t�@�C����ł��̂悤�ɗ����וς���K�v������܂��B�s�v�ȗ�͍폜���č\���܂��A�Q�l���� Xbench �ŕ\���������ꍇ�� C ��ȍ~�ɂ��̏����c���Ă����܂��B

��𐮂����� [���O��t���ĕۑ�] �����܂����A���̂Ƃ��� [�t�@�C���̎��] �Ƃ��āu�e�L�X�g (�^�u���) (*.txt)�v��I�����܂��B����ŁAXbench �ɓǂݍ��߂�^�u���t�@�C�����ł�������܂��B
�쐬�����^�u���t�@�C�� (.txt) �� Xbench �ɁuTab-delimited Text File�v�Ƃ��Ď�荞�ނƁA�ȉ��̂悤�ɕ����̗p�ꂪ�q�b�g���Ă��܂��B����Ŋ����ł��B

����͈ȏ�ł��B1 �� 1 �łȂ��p��x�[�X�� TBX �t�@�C�������܂������ł��Ȃ����ƂɂȂ����܂ŋC�t���Ȃ������̂��A������Ƌ��낵���Ȃ����̂Ŋm�F���Ă݂��Ƃ���A����Ȍ`���̗p��x�[�X�͎��͂قƂ�ǂ���܂���ł����B�����Ă��̏ꍇ�AExcel �t�@�C������ɂ���A���̎��_�� 1 �� 1 �ɂȂ��Ă��邩�A�Ȃ��Ă��Ȃ��ꍇ�� Excel �t�@�C����ŕҏW�����Ė������ 1 �� 1 �ɂ��Ă��܂����B�Ƃ͂����A����������h�����߁ATBX �t�@�C���� 1 �� 1 �ł��邱�Ƃ��m�F���Ă��� Xbench �Ɏ�荞�ޕK�v������܂��B
| �@�@ |
Tweet
2023�N06��09��
Trados �����̕⑫
�v���Ԃ�� Trados �̎�������J�Â��ꂽ�̂ŎQ�����Ă݂܂����B����A�Ȃ�ƂȂ����ꂽ�����鎿���ł����A�Q�l�ɂȂ��Ȃ��킯�ł͂���܂���B
���̋L���ł́A���̊��z�ƕ⑫�������ȒP�ɂ܂Ƃ߂܂����B�ȉ��ɋ���������̃^�C�g������e�͂����܂Ŏ��̉��߂ł��B���̎��̉��߂��A���ۂɂ���������ꂽ���̐^�ӂ��炸��Ă��邩������܂��A���̕ӂ�͂��������������B
�|��A���r���[�A�����[�X�Ƃ������[�h���Ƃɉ�ʂ��J�X�^�}�C�Y�ł��邻���ł��B�������i�g���Ă����ʂ̃��C�A�E�g�͈ȑO�̋L���u�f���A�� �f�B�X�v���C�ł̍���v�ŏЉ�Ă���̂ł������������B
���̎���Ŏ����ł��C�ɂȂ����̂́A����̓��e���̂��̂ł͂Ȃ��ASDL �̕��́u���r���[�̂Ƃ��̓��������g���Ă��낢�낷�邱�Ƃ͂Ȃ��ł��傤����`�v�Ƃ����悤�Ȕ����ł��B���r���[�̂Ƃ��́A�����������܂�g��Ȃ����烁���� �y�C���͊���ʼn�ʉ����ɕ\������d�l�Ȃ̂������ł��B
���͈ȑO����A���r���[ ���[�h�̂Ƃ��ɂȂ������� �y�C������ʉ����ɕ\�������̂��^�₾�����̂ł����A���������J����Ђ̒��ł��������F���������̂ł��ˁB���������F����������A������r���[�������}�b�`���Ŋ���������肷�邱�Ƃ��Ȃ��ł���ˁH �����ł���ˁB�����āA���������g��Ȃ���ł�����B(���Ȃ݂ɁA�����Ȃ�����Ȃ��Ƃ������Ă���̂���������̋L�������ǂ݂��������B)
sdlxliff �t�@�C���������o�b�N�A�b�v���Ă��邪�A���ۂɕ�������Ƃ��͂ǂ�����悢�̂��Ƃ������₪����܂����B
�v���W�F�N�g�̊e�t�@�C�����ǂ��Ɋi�[����Ă��邩��m��ɂ́A�v���W�F�N�g �r���[�őΏۂ̃v���W�F�N�g���E�N���b�N���A�\������郁�j���[���� [�v���W�F�N�g �t�H���_���J��] ��I�����܂��B����ŁA�v���W�F�N�g���i�[����Ă���t�H���_�[���G�N�X�v���[���[�ŊJ����܂��B
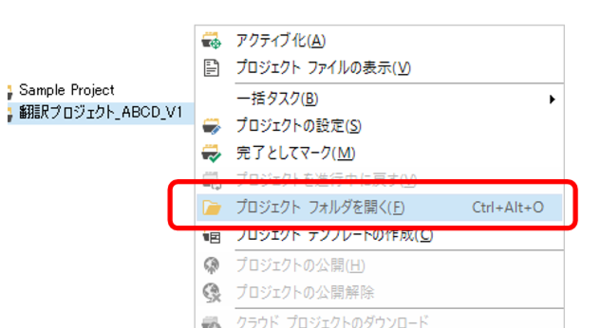
�J���ꂽ�t�H���_�[�̒��Ɂuen-US�v��uja-JP�v�ȂǁA���ꂲ�Ƃ̃t�H���_�[������Asdlxliff �t�@�C���͂��̌��ꂲ�Ƃ̃t�H���_�[�̒��Ɋi�[����Ă��܂��B
�����A�����̍�Ƃł� sdlxliff �t�@�C�����o�b�N�A�b�v�Ƃ��ĕۑ����Ă��܂��B�������≽���̐ݒ肪���Ă��܂������Ȃ��Ƃ��́A�|���Ђ�����ꂽ�p�b�P�[�W���J���Ȃ����A�o�b�N�A�b�v���Ă����� sdlxliff �t�@�C���������ɏ㏑�����܂��B����ŁA��������ݒ�͍ŏ��̏�Ԃɖ߂��A�͍��܂Ŗ����̂��ێ��ł��܂��B
Trados �ɂ́A������v���r���[�̕��@����������܂��B�v���r���[�Ɩ����̈Ⴂ�͎����������������̂ł����A����̉͂����܂ŏڂ������̂ł͂���܂���ł����B
��\��������@�ɂ��ẮA�ȑO�̋L�� �u�݂̂ŕۑ��v���g���Ă݂� �� �u�̕\���v���g���Ă݂� ���Q�Ƃ��Ă��������B
���������Љ��Ă����u�G�N�X�|�[�g�v�@�\�͏o�͐�Ȃǂ�ݒ�ł���̂łƂĂ��֗��ł��B�ȑO�̋L���u�����ɕ����̉�ʂ��J���v�ŊȒP�ɏЉ�Ă��܂��B
�u�R�����ŕ�����Ȃ��悤�ɂ������v�u���ʓ��̋�_�ł͕�����Ăق����Ȃ��v�ȂǁA���ߋK���̐ݒ�͂Ȃ��Ȃ��ʓ|�ł��B�ݒ肷��ꏊ�́A�Ő�������Ă����Ƃ���A�|������ [���ꃊ�\�[�X] > [���ߋK��] �ł��B(�ڍׂȐݒ���@�́A���݂܂���A�Z�~�i�[�ł̉̂Ƃ��茟�����Ă��������B)
���̕��ߋK���ɂ��āA���͂��� SDL ����ɋ������Đ������Ăق����Ȃ��Ǝv���Ă��邱�Ƃ�����܂��B����́u���ߋK���͌�������荞�ޑO�ɐݒ肷��K�v������v���Ƃł��B�܂�A�p�b�P�[�W��n���ꂽ�|��҂͐ݒ��ς��邱�Ƃ��ł��܂���B�|���Ђ��p�b�P�[�W�����i�K�Őݒ������K�v������܂��B
�܂��A�ŋ߂́A�@�B�|���O�ɑ}������Ă��邱�Ƃ�����܂����A���ʓ��̋�_�ŕ������Ȃ��Ƃ����ݒ肪����Ă��Ȃ����߂ɁA�����r���Ő�A�@�B�|���܂��@�\���Ă��Ȃ����Ƃ��悭����܂��B���̐ݒ�������ɋ@�B�|���K�p���āA�����͊�������܂��˂��Č����Ă����Ђ��������܂��B�������̂��ƁA���ʓ��̋�_�ŕ������Ȃ��ݒ������ɂ������������C�����܂����A���߂ł����ˁB
���╶���ȒP�Ȃ��̂ł������A���u�w���v�����Ă��������v�Ƃ����ȒP�Ȃ��̂ł����B�����������₵�Ă���̂�����A�������������Ă����Ă�������Ȃ����Ɗ������̂Ŗ|��҂̗��ꂩ�班���⑫���܂��B
���b�N�������Ԃ̖ړI�́A�����炭�u��ƑΏۊO�ł��邱�Ƃ������v���Ƃł��B�|���Ђ���Ƃ̎d���̏ꍇ�A���b�N����Ă��镪�߂͊�{�I�ɍ�Ƃ����Ȃ��̂ŗ������������܂���B�܂�A���b�N�̗L���͗����ɒ��ڂ������܂��B���̂��߁A�|��ґ��Ń��b�N����������A���������肷�邱�Ƃ͌����֎~�ł��B
����ɁA���b�N�������Ă���̂��A�|���Ђł͂Ȃ��A���̐�̃\�[�X �N���C�A���g�ł���ꍇ������܂��B���̏ꍇ�A�|���Ђ����b�N�����ɂ��Ă͗�����������Ă��Ȃ��\��������̂ŁA�����|��҂�����ɕς��Ă��܂������ςȂ��ƂɂȂ�܂��B��낤�ƁA�Ȃ낤�ƁA���b�N����Ă��镔���ɏ���ɐG���̂͌��ւł��B
�܂��A�t�ɁA���b�N����Ă��Ȃ��̂ɍ�ƑΏۊO�Ƃ������Ƃ���������܂���B100% �}�b�`����ƑΏۊO�Ƃ���Ȃ�A���̕��߂̓��b�N���ꂽ��ԂŃt�@�C����n�����̂��ʏ�ł��B���́A��ƑΏۊO�ɂ�������炸���b�N����Ă��Ȃ��ꍇ�́A�K����ƑO�ɃR�[�f�B�l�[�^�[����Ɋm�F����悤�ɂ��Ă��܂��B
����́u���x�ȕ\���t�B���^�v�̉E�N���b�N �R�}���h�ł��B�ڂ����́u2021 �ŐV�����Ȃ����\���t�B���^�v���Q�Ƃ��Ă��������B
��L�̋L���ł��������Ă��܂����A���̉E�N���b�N �R�}���h�ɂ̓V���[�g�J�b�g �L�[�����蓖�Ă��܂��B���� Phrase �Ɠ�������ɂȂ�悤�Ɂu�I���t�B���^�v�� Ctrl+Shift+F �����蓖�ĂĂ��܂��B�܂��A�t�B���^�[�̉����� Ctrl+Alt+F6 �ʼn\�ł��B(���Ȃ�֗��ł��B)
����̉ł̓G�f�B�^�[��� 1 �F�Ȃ�n�C���C�g��t������Ƃ̂��Ƃł����B����ȋ@�\�����������ǂ������̋L���ł͂悭�킩��܂��A�ЂƂ܂��A�Љ��Ă����v���O�C�� Wordlight ���C���X�g�[�����Ă݂܂����B������A�V���[�g�J�b�g �L�[��ݒ肷��ƂĂ��֗������ł��B
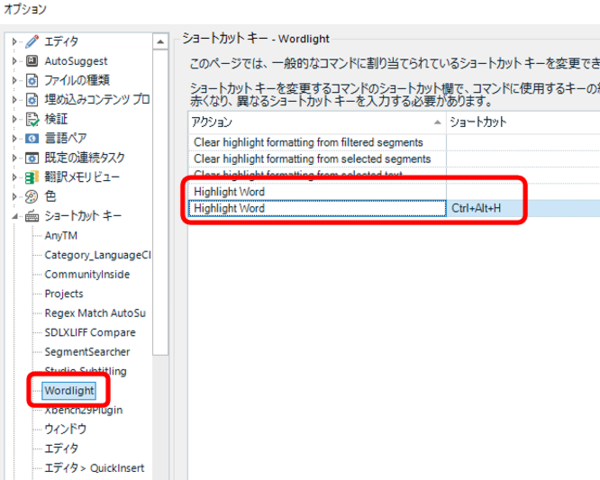
�V���[�g�J�b�g �L�[�̐ݒ��ʂɂ́uHighlight Word�v�Ƃ����������O�̃A�N�V������ 2 �\������Ă��܂��B���ۂɐݒ肵�Ă݂��Ƃ���A��̃A�N�V�����ł͐F�̑I����ʂ��\������܂����B���̃A�N�V�����ł́A�F�̑I����ʂ͕\�����ꂸ�A���̂܂܃n�C���C�g��t���邱�Ƃ��ł��܂����B
�u�p��x�[�X�̒P�ꐔ�ɐ����͂���܂����v�Ƃ�������ɑ��āu�o�^���ɐ����͂���܂���v�Ƃ���������Ă��܂������A���́A���̎���͗p��x�[�X���̗p�� 1 �� 1 �̒����ɐ����͂���̂��A�Ƃ����Ӗ��������̂ł͂Ȃ����Ǝv���܂����B
�ȑO�A�|���Ђ�����ꂽ�p�b�P�[�W�� UI �������������ɓo�^����Ă������Ƃ�����A���́u�������ł͒Z���p�ꂪ�q�b�g���Ȃ��̂ŗp��x�[�X�ɓo�^���Ă��炦�܂��v�Ƃ��肢�������Ƃ�����܂��B���̂Ƃ��ɖ|���Ђ���Ԃ��Ă����������u�G���[ ���b�Z�[�W�Ȃǂ̒������������Ă���̂ŁA�p��x�[�X�ł͂��܂��q�b�g���Ȃ��\��������܂��v�Ƃ������̂ł����B���ǁA�|���Ђ��u�������܂��v�ƌ����Ă���Ԃɂ��̃v���W�F�N�g�͏I�����A���������ł����B
�m���ɁA�p��x�[�X�ɒ�����������Ƃǂ��Ȃ�̂�������ƕs���ł��B�����ƃq�b�g���Ă���ł��傤���B���ہA�G���[ ���b�Z�[�W�ȂǁA������x�̒������������q�b�g���Ă��邱�Ƃ͂���̂ŁA�����炭���v���낤�ƌl�I�ɂ͍l���Ă��܂��B���̕ӂ�̂��Ƃ����̎���̓����ł͊��҂��Ă��܂����B
�Ȃ��A�p��F���̐ݒ�Ȃǂɂ��Ắu�p��x�[�X�̐ݒ��v���ǂ����Q�l�ɂ��Ă��������B
�܂��܂�����͂�������܂������A����͂����܂łƂ��܂��B���̎����Řb��ɏ�������Ŏ����~�����Ǝv�����@�\�́A�G�f�B�^�[��Ńt�H���g���w�肷��@�\�ƁA�J��Ԃ��̓K�p���ɖ��C���ł���@�\�ł��B�uIdeas �ɓ��e���Ă��������v�Ɖ������Ă��܂������A���������܂ł̓��̂�͒������ł��B
���̋L���ł́A���̊��z�ƕ⑫�������ȒP�ɂ܂Ƃ߂܂����B�ȉ��ɋ���������̃^�C�g������e�͂����܂Ŏ��̉��߂ł��B���̎��̉��߂��A���ۂɂ���������ꂽ���̐^�ӂ��炸��Ă��邩������܂��A���̕ӂ�͂��������������B
��ʂ̃J�X�^�}�C�Y
�|��A���r���[�A�����[�X�Ƃ������[�h���Ƃɉ�ʂ��J�X�^�}�C�Y�ł��邻���ł��B�������i�g���Ă����ʂ̃��C�A�E�g�͈ȑO�̋L���u�f���A�� �f�B�X�v���C�ł̍���v�ŏЉ�Ă���̂ł������������B
���̎���Ŏ����ł��C�ɂȂ����̂́A����̓��e���̂��̂ł͂Ȃ��ASDL �̕��́u���r���[�̂Ƃ��̓��������g���Ă��낢�낷�邱�Ƃ͂Ȃ��ł��傤����`�v�Ƃ����悤�Ȕ����ł��B���r���[�̂Ƃ��́A�����������܂�g��Ȃ����烁���� �y�C���͊���ʼn�ʉ����ɕ\������d�l�Ȃ̂������ł��B
���͈ȑO����A���r���[ ���[�h�̂Ƃ��ɂȂ������� �y�C������ʉ����ɕ\�������̂��^�₾�����̂ł����A���������J����Ђ̒��ł��������F���������̂ł��ˁB���������F����������A������r���[�������}�b�`���Ŋ���������肷�邱�Ƃ��Ȃ��ł���ˁH �����ł���ˁB�����āA���������g��Ȃ���ł�����B(���Ȃ݂ɁA�����Ȃ�����Ȃ��Ƃ������Ă���̂���������̋L�������ǂ݂��������B)
�v���W�F�N�g�̍\���ƃo�b�N�A�b�v����̕������@
sdlxliff �t�@�C���������o�b�N�A�b�v���Ă��邪�A���ۂɕ�������Ƃ��͂ǂ�����悢�̂��Ƃ������₪����܂����B
�v���W�F�N�g�̊e�t�@�C�����ǂ��Ɋi�[����Ă��邩��m��ɂ́A�v���W�F�N�g �r���[�őΏۂ̃v���W�F�N�g���E�N���b�N���A�\������郁�j���[���� [�v���W�F�N�g �t�H���_���J��] ��I�����܂��B����ŁA�v���W�F�N�g���i�[����Ă���t�H���_�[���G�N�X�v���[���[�ŊJ����܂��B
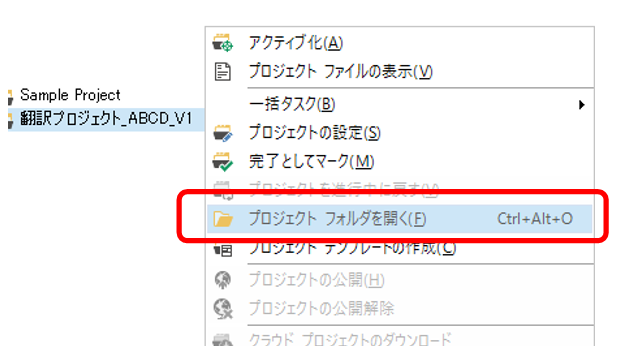
�J���ꂽ�t�H���_�[�̒��Ɂuen-US�v��uja-JP�v�ȂǁA���ꂲ�Ƃ̃t�H���_�[������Asdlxliff �t�@�C���͂��̌��ꂲ�Ƃ̃t�H���_�[�̒��Ɋi�[����Ă��܂��B
�����A�����̍�Ƃł� sdlxliff �t�@�C�����o�b�N�A�b�v�Ƃ��ĕۑ����Ă��܂��B�������≽���̐ݒ肪���Ă��܂������Ȃ��Ƃ��́A�|���Ђ�����ꂽ�p�b�P�[�W���J���Ȃ����A�o�b�N�A�b�v���Ă����� sdlxliff �t�@�C���������ɏ㏑�����܂��B����ŁA��������ݒ�͍ŏ��̏�Ԃɖ߂��A�͍��܂Ŗ����̂��ێ��ł��܂��B
�����̕��@�A�v���r���[�Ɩ����̈Ⴂ
Trados �ɂ́A������v���r���[�̕��@����������܂��B�v���r���[�Ɩ����̈Ⴂ�͎����������������̂ł����A����̉͂����܂ŏڂ������̂ł͂���܂���ł����B
��\��������@�ɂ��ẮA�ȑO�̋L�� �u�݂̂ŕۑ��v���g���Ă݂� �� �u�̕\���v���g���Ă݂� ���Q�Ƃ��Ă��������B
���������Љ��Ă����u�G�N�X�|�[�g�v�@�\�͏o�͐�Ȃǂ�ݒ�ł���̂łƂĂ��֗��ł��B�ȑO�̋L���u�����ɕ����̉�ʂ��J���v�ŊȒP�ɏЉ�Ă��܂��B
�Z�O�����e�[�V���� (���ߋK��)
�u�R�����ŕ�����Ȃ��悤�ɂ������v�u���ʓ��̋�_�ł͕�����Ăق����Ȃ��v�ȂǁA���ߋK���̐ݒ�͂Ȃ��Ȃ��ʓ|�ł��B�ݒ肷��ꏊ�́A�Ő�������Ă����Ƃ���A�|������ [���ꃊ�\�[�X] > [���ߋK��] �ł��B(�ڍׂȐݒ���@�́A���݂܂���A�Z�~�i�[�ł̉̂Ƃ��茟�����Ă��������B)
���̕��ߋK���ɂ��āA���͂��� SDL ����ɋ������Đ������Ăق����Ȃ��Ǝv���Ă��邱�Ƃ�����܂��B����́u���ߋK���͌�������荞�ޑO�ɐݒ肷��K�v������v���Ƃł��B�܂�A�p�b�P�[�W��n���ꂽ�|��҂͐ݒ��ς��邱�Ƃ��ł��܂���B�|���Ђ��p�b�P�[�W�����i�K�Őݒ������K�v������܂��B
�܂��A�ŋ߂́A�@�B�|���O�ɑ}������Ă��邱�Ƃ�����܂����A���ʓ��̋�_�ŕ������Ȃ��Ƃ����ݒ肪����Ă��Ȃ����߂ɁA�����r���Ő�A�@�B�|���܂��@�\���Ă��Ȃ����Ƃ��悭����܂��B���̐ݒ�������ɋ@�B�|���K�p���āA�����͊�������܂��˂��Č����Ă����Ђ��������܂��B�������̂��ƁA���ʓ��̋�_�ŕ������Ȃ��ݒ������ɂ������������C�����܂����A���߂ł����ˁB
�u���߂̃��b�N�v�̗p�r
���╶���ȒP�Ȃ��̂ł������A���u�w���v�����Ă��������v�Ƃ����ȒP�Ȃ��̂ł����B�����������₵�Ă���̂�����A�������������Ă����Ă�������Ȃ����Ɗ������̂Ŗ|��҂̗��ꂩ�班���⑫���܂��B
���b�N�������Ԃ̖ړI�́A�����炭�u��ƑΏۊO�ł��邱�Ƃ������v���Ƃł��B�|���Ђ���Ƃ̎d���̏ꍇ�A���b�N����Ă��镪�߂͊�{�I�ɍ�Ƃ����Ȃ��̂ŗ������������܂���B�܂�A���b�N�̗L���͗����ɒ��ڂ������܂��B���̂��߁A�|��ґ��Ń��b�N����������A���������肷�邱�Ƃ͌����֎~�ł��B
����ɁA���b�N�������Ă���̂��A�|���Ђł͂Ȃ��A���̐�̃\�[�X �N���C�A���g�ł���ꍇ������܂��B���̏ꍇ�A�|���Ђ����b�N�����ɂ��Ă͗�����������Ă��Ȃ��\��������̂ŁA�����|��҂�����ɕς��Ă��܂������ςȂ��ƂɂȂ�܂��B��낤�ƁA�Ȃ낤�ƁA���b�N����Ă��镔���ɏ���ɐG���̂͌��ւł��B
�܂��A�t�ɁA���b�N����Ă��Ȃ��̂ɍ�ƑΏۊO�Ƃ������Ƃ���������܂���B100% �}�b�`����ƑΏۊO�Ƃ���Ȃ�A���̕��߂̓��b�N���ꂽ��ԂŃt�@�C����n�����̂��ʏ�ł��B���́A��ƑΏۊO�ɂ�������炸���b�N����Ă��Ȃ��ꍇ�́A�K����ƑO�ɃR�[�f�B�l�[�^�[����Ɋm�F����悤�ɂ��Ă��܂��B
�E�N���b�N�́u�I���t�B���^�v�u�����t�B���^�v�u�t�B���^�v
����́u���x�ȕ\���t�B���^�v�̉E�N���b�N �R�}���h�ł��B�ڂ����́u2021 �ŐV�����Ȃ����\���t�B���^�v���Q�Ƃ��Ă��������B
��L�̋L���ł��������Ă��܂����A���̉E�N���b�N �R�}���h�ɂ̓V���[�g�J�b�g �L�[�����蓖�Ă��܂��B���� Phrase �Ɠ�������ɂȂ�悤�Ɂu�I���t�B���^�v�� Ctrl+Shift+F �����蓖�ĂĂ��܂��B�܂��A�t�B���^�[�̉����� Ctrl+Alt+F6 �ʼn\�ł��B(���Ȃ�֗��ł��B)
�n�C���C�g
����̉ł̓G�f�B�^�[��� 1 �F�Ȃ�n�C���C�g��t������Ƃ̂��Ƃł����B����ȋ@�\�����������ǂ������̋L���ł͂悭�킩��܂��A�ЂƂ܂��A�Љ��Ă����v���O�C�� Wordlight ���C���X�g�[�����Ă݂܂����B������A�V���[�g�J�b�g �L�[��ݒ肷��ƂĂ��֗������ł��B
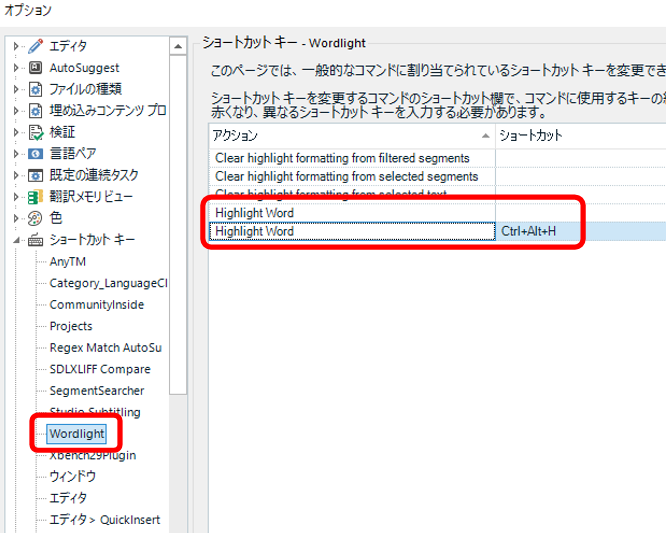
�V���[�g�J�b�g �L�[�̐ݒ��ʂɂ́uHighlight Word�v�Ƃ����������O�̃A�N�V������ 2 �\������Ă��܂��B���ۂɐݒ肵�Ă݂��Ƃ���A��̃A�N�V�����ł͐F�̑I����ʂ��\������܂����B���̃A�N�V�����ł́A�F�̑I����ʂ͕\�����ꂸ�A���̂܂܃n�C���C�g��t���邱�Ƃ��ł��܂����B
�p��x�[�X�̒P�ꐔ
�u�p��x�[�X�̒P�ꐔ�ɐ����͂���܂����v�Ƃ�������ɑ��āu�o�^���ɐ����͂���܂���v�Ƃ���������Ă��܂������A���́A���̎���͗p��x�[�X���̗p�� 1 �� 1 �̒����ɐ����͂���̂��A�Ƃ����Ӗ��������̂ł͂Ȃ����Ǝv���܂����B
�ȑO�A�|���Ђ�����ꂽ�p�b�P�[�W�� UI �������������ɓo�^����Ă������Ƃ�����A���́u�������ł͒Z���p�ꂪ�q�b�g���Ȃ��̂ŗp��x�[�X�ɓo�^���Ă��炦�܂��v�Ƃ��肢�������Ƃ�����܂��B���̂Ƃ��ɖ|���Ђ���Ԃ��Ă����������u�G���[ ���b�Z�[�W�Ȃǂ̒������������Ă���̂ŁA�p��x�[�X�ł͂��܂��q�b�g���Ȃ��\��������܂��v�Ƃ������̂ł����B���ǁA�|���Ђ��u�������܂��v�ƌ����Ă���Ԃɂ��̃v���W�F�N�g�͏I�����A���������ł����B
�m���ɁA�p��x�[�X�ɒ�����������Ƃǂ��Ȃ�̂�������ƕs���ł��B�����ƃq�b�g���Ă���ł��傤���B���ہA�G���[ ���b�Z�[�W�ȂǁA������x�̒������������q�b�g���Ă��邱�Ƃ͂���̂ŁA�����炭���v���낤�ƌl�I�ɂ͍l���Ă��܂��B���̕ӂ�̂��Ƃ����̎���̓����ł͊��҂��Ă��܂����B
�Ȃ��A�p��F���̐ݒ�Ȃǂɂ��Ắu�p��x�[�X�̐ݒ��v���ǂ����Q�l�ɂ��Ă��������B
�܂��܂�����͂�������܂������A����͂����܂łƂ��܂��B���̎����Řb��ɏ�������Ŏ����~�����Ǝv�����@�\�́A�G�f�B�^�[��Ńt�H���g���w�肷��@�\�ƁA�J��Ԃ��̓K�p���ɖ��C���ł���@�\�ł��B�uIdeas �ɓ��e���Ă��������v�Ɖ������Ă��܂������A���������܂ł̓��̂�͒������ł��B
| �@�@ |
�^�O�F����� �\���t�B���^ �v���O�C�� ���x�ȕ\���t�B���^ �p��x�[�X �n�C���C�g Wordlight ���ߋK�� �t�@�C���̃G�N�X�|�[�g
Tweet