パッケージは、各種のファイルをひとまとめにできるのでデータの受け渡しにはとても便利です。ただ、中に格納されているファイルに直接アクセスできないという点に少し不便さを感じることがあります。たとえば、翻訳作業の途中では、変な一括置換をしてしまったので一部のファイルだけ元に戻したいとか、プロジェクトの設定を変えてはみたけれども最初の設定をもう一度見たいとかいうように、元の状態のファイルにアクセスしたくなることがたまにあります。また、翻訳作業の完了後は、返却パッケージに正しいファイルを格納したかどうか不安になってパッケージの中を確認したくなることがしばしばです。
今回は、このような場合の手だてとして、パッケージの中のファイルや設定を確認する方法を 3 つ紹介したいと思います。1 つ目は、強制的に解凍する方法、2 つ目は、SDL AppStore で提供されているツールを使用する方法、そして最後はパッケージを別プロジェクトとして開き直す方法です。
パッケージを強制的に解凍する
パッケージ ファイルは、実は、単なる zip ファイルのようです。ですので、一般的な zip ツールで解凍できます。私は自分ではこの事実にまったく気付かなかったのですが、つい最近になって、あるコーディネーターさんに「普通に解凍できますよ」と教えられ、かなり、かなり、驚きました!
パッケージ ファイルの拡張子を「.zip」に変更すれば、エクスプローラー付属の解凍ツールでそのまま解凍できます。翻訳会社さんから送られてきたままのオリジナルな状態のバイリンガル ファイルやメモリを見たいというケースでは、この方法が手早くて便利です。
ただ、日本語の文字を含むファイル名は文字化けしてしまう場合があります。ファイルの中身そのものに影響はないようですが、ファイル名が文字化けして各ファイルを識別できなくなるので、名前に日本語を含むファイルが複数存在する場合は厳しいかもしれません。ファイル名が半角英数字のみで構成されている場合は問題なく解凍できると思います。
SDL AppStore で提供されている PackageReader を使う
SDL AppStore に PackageReader というツールが無料で提供されています。これは、パッケージの中身を参照するためのツールで、簡単に使用できてとても便利です。
このツールは、Trados の中に組み込まれるプラグインではなく、Trados の外側で独立して動くアプリケーションです。AppStore のページで [ダウンロード] ボタンをクリックすると zip ファイルがダウンロードされてきます。その中の exe ファイルを実行してインストールを開始します。インストール時にファイルの関連付けが自動的に行われるので、インストール後はエクスプローラー上で右クリックするだけで簡単に使用できます。

パッケージ ファイルを右クリックして [プログラムから開く] > [PackageReader] と選択すると、以下のような画面が表示され、パッケージ内のバイリンガル ファイル、メモリ、用語集を一覧表示できます。さらに、バイリンガル ファイルについては、虫眼鏡アイコンをクリックしてファイルの中身を参照することもできます。
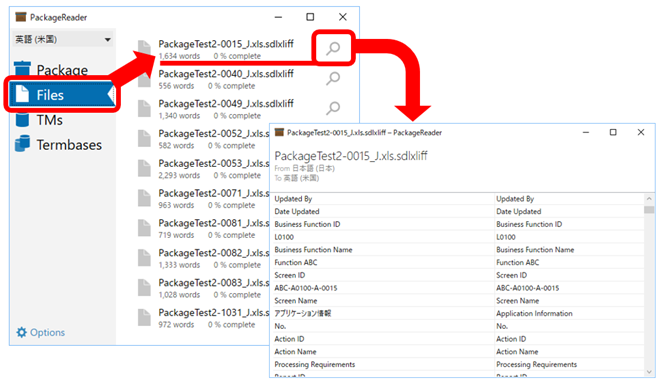
私は、返却パッケージの中身を確認したいときにこの PackageReader をよく使います。返却パッケージを作成した後、PackageReader でパッケージを開き、格納したファイルに過不足がないかを確認します。
ただ、このツールは、パッケージに含まれているファイルを一覧表示してくれるだけで、特定のファイルを取り出したり、プロジェクトの設定内容を確認したりすることはできません。特定のファイルを取り出したいときは、最初に説明した強制的に解凍する方法を採る必要があります。また、ファイル名に日本語が含まれる場合や、プロジェクトの設定内容を見たい場合は、さらに別の方法が必要になります。
パッケージを別プロジェクトとして開き直す
さて、「さらに別の方法」とは「別プロジェクトとして開き直す」です。パッケージは、いったん開いてプロジェクトを作成してしまうと、その後で単純にもう一度開いても、プロジェクトの保存先を指定できず、別プロジェクトとして開き直すことはできません。別プロジェクトとして開き直すには、既存のプロジェクトをいったん「削除」する必要があります。

上の図のように、プロジェクトを右クリックして [リストから削除] を選択します。[リストから削除] を実行してもプロジェクト自体は削除されないのでご安心ください。(この UI の文言は信用して大丈夫です。文字どおり、リストから削除されるだけで、実際のファイルは削除されません。)
プロジェクトが一覧に表示されていないことを確認したら、パッケージを改めて開きます。今度は、プロジェクトの保存先を指定できるので、既存のプロジェクトとは別のフォルダーを指定してプロジェクトを作成します。これで、別プロジェクトとして開くことができます。
元のプロジェクトに戻したいときは、[リストから削除] を再度実行して、後から作ったプロジェクトをリストから削除します。その後で、元のプロジェクトの保存先にあるプロジェクト ファイル (.sdlproj) からプロジェクトを開きます。これで、元のプロジェクトに戻ることができます。
残念ながら、元のプロジェクトと後から作ったプロジェクトを同時にリストに表示することはできなそうです。(私が試してみた限りでは、できませんでした。) ファイル自体は保存先に残しておけるので、リストに表示するプロジェクトを必要に応じて切り替える操作が必要になります。
今回は、以上です。いろいろ書きましたが、まとめると、まずは zip ツールで解凍してみる、だめなら [リストから削除] をしてからパッケージを開き直す、中身を一覧表示したいだけなら PackageReader が便利、という感じでしょうか。私は、「パッケージ」というものが登場して以降、自分なりにここまで理解するのに相当な時間がかかりました (
Tweet