


�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
�L��
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
posted by fanblog
2018�N07��06��
�J�E���g�\���悭�m�F���悤 �\ ���� �A
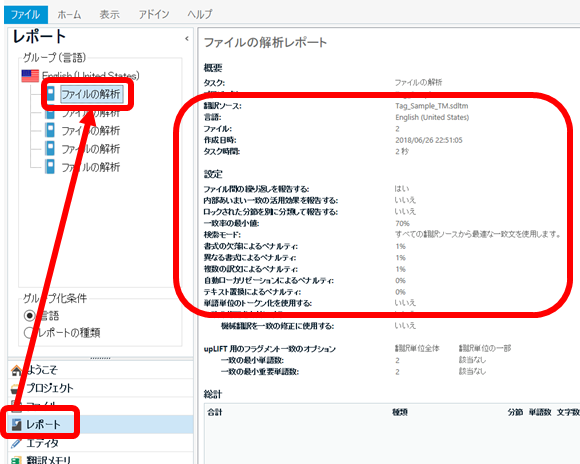
�O���Ɉ��������A�J�E���g�\�̊m�F�|�C���g�ł��B�܂��܂��A����Ƃ������s���Ƃ������A���낢��Ȑݒ肪����̂ŁA���ӂ��Ȃ��猩�Ă��������Ǝv���܂��B

4 �ڂ́u���b�N���ꂽ���߁v�ł��B���̂���܂ł̌o���ł́A���̐ݒ肪�Ԉ���Ă��邱�Ƃ���ԑ����悤�Ɏv���܂��B
�ʏ�A���̐ݒ�́u�͂��v�ŁA���b�N���ꂽ���߂�ʂɃJ�E���g���܂��B���ۂ̎d���ł́A�u���b�N����Ă��镪�߂͍�ƑΏۊO�ŁI�v�Ǝw������邱�Ƃ������A���b�N�Ƃ��ăJ�E���g���ꂽ������ 0 �~�ƂȂ�܂��B�܂��A���b�N����Ă���̂Ŗ��m�ł����A��ƑΏۊO�ƌ�������̎w���ɏ]����������܂���B
�����ATrados �̃f�t�H���g�ݒ�́u�������v�̂悤�Ȃ�ł��B�Ȃ̂ŁA�ԈႦ�ă��b�N�������J�E���g�Ɋ܂܂�Ă��邱�Ƃ����܂ɂ���܂��B�J�E���g����������̂ŁA�Ԉ���Ă����烉�b�L�[�I�Ȃ�čl���Ă͂����܂���B���̐ݒ肪�Ԉ���Ă����ꍇ�A�|���Ђ���͕K���������Ă��܂��B���Ƃ������������s���ꂽ��ł��A���邢�͍�Ƃ��J�n������ł��������Ă��܂���[�B(����������Ȃ��Ƃ�����܂����B)
���b�N����Ă���̂ō�Ƃ͂��Ȃ��ł����A�������x�����Ȃ��͓̂��R�ł����A��Ƃ̒��O���Ƃ̊J�n��̒����͖|��҂Ƃ��Ă͂ƂĂ�����܂��B���Ƃ��A�|���Ђ���u�����̑Őf�̎��_�ł� 10,000 ���[�h�Ƃ��`�����Ă��܂������A���ۂɃt�@�C�������ă��b�N���������O���Ă݂��� 5,000 ���[�h�ł����v�ƌ�����ƁA10,000 ���[�h���̎��Ԃ��m�ۂ��Ă����̂ɁI�I�]�������Ԃ͂ǂ�����H�H�Ƃ������ԂɂȂ�܂��B
���̐ݒ�ł́A���� 1 ���ӓ_������܂��B
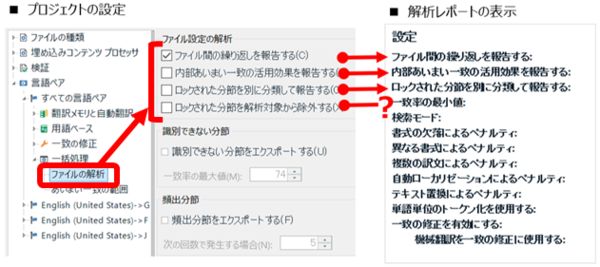
�O��̋L���ŏЉ���ݒ���܂߁A�t�@�C���̉�͂̃I�v�V������ [�v���W�F�N�g�̐ݒ�] -> [����y�A] -> [�ꊇ����] -> [�t�@�C���̉��] ����ݒ�ł��܂��B���̐ݒ��ʂɂ́A���b�N���ꂽ���߂Ɋւ���I�v�V������ 2 ����܂��B
�@�@�@ ���b�N���ꂽ���߂�ʂɕ��ނ��ĕ���
�@�@�A ���b�N���ꂽ���߂���͑Ώۂ��珜�O����
�@ �́u�ʂɕ��ނ��ĕ���v��I������ƁA��̓��|�[�g�Ɂu���b�N�ς݁v�Ƃ������������A�����ɃJ�E���g�����\������܂��B�����āA���|�[�g�㕔�̃I�v�V�����̈ꗗ�ɂ́u���b�N���ꂽ���߂�ʂɕ��ނ��ĕ���: �͂��v�ƕ\������܂��B
�A �́u��͑Ώۂ��珜�O����v��I������ƁA��̓��|�[�g�ł̓��b�N���ꂽ���߂̃J�E���g���͏��O����A�ǂ��ɂ��\������܂���B�����āA���|�[�g�㕔�̃I�v�V�����̈ꗗ�ɂ��A���̃I�v�V�����ɂ��Ă̕\���͂���܂���B�{���ɁA���ׂĂ��珜�O������ł��I �u���b�N���ꂽ���߂�ʂɕ��ނ��ĕ����v�̕\���́A�A �̐ݒ�ɊW�Ȃ��A�@ ���I������Ă��Ȃ�����u�������v�ɂȂ�܂��B
�܂�A�A �́u��͑Ώۂ��珜�O����v���I������Ă��Ă��A��̓��|�[�g��ł͂��̂��Ƃ��킩��܂���B���́u��͑Ώۂ��珜�O����v�̃I�v�V�����͍ŋߒlj����ꂽ�̂ł��傤���B�������̃I�v�V�����ɋC�Â����͍̂ŋ߂ł��B��̓��|�[�g�Łu���b�N���ꂽ���߂�ʂɕ��ނ��ĕ���: �������v�ƂȂ��Ă��Ă��A�|���Ђ���ɘA������O�ɁA�ꉞ�u��͑Ώۂ��珜�O����v�I�v�V�������m�F���Ă݂܂��傤�B

���āA�Ō�̃|�C���g�́u�P��P�ʂ̃g�[�N�����v�ł��B����́ASDL Trados 2017 SR1 �ȍ~�ŁA���������{�ꂩ������̂Ƃ��ɊW���Ă��܂��B�������p��̂Ƃ��͋C�ɂ���K�v���Ȃ��̂ŁA��͕\�ɂ��̃I�v�V�����͕\������Ă��܂���B
���̐ݒ�́A�P��x�[�X�ʼn�͂��邩�A�����x�[�X�ʼn�͂��邩�̑I���ł����A�ڍׂɂ��ẮASDL �̂�����̃u���O���Q�l�ɂȂ�܂��B���̃u���O�̍Ō�Ɂu�ȑO�̉�͕��@�i�����x�[�X�j�ƐV������͕��@�����[�U�[���I���ł���悤�Ȏd�g�݂��J�����ł��v�Ƃ���܂����A����ŊJ�����ꂽ�̂����̐ݒ肾�Ǝv���܂��B
�ʏ�A����́u�������v�ł��B���������{��̏ꍇ�A�����͈�ʓI�ɕ����P���Ōv�Z�����̂ŁA���R�Ȃ����͂������x�[�X�ł���ׂ��ł��B�P��x�[�X�ň�v�����v�Z���āA�����ɕ����P����K�p����Ƃ������Ȃ��ƂɂȂ�܂��B
�����A��L�̃u���O�ɂ�����悤�ɁA���̐ݒ�͏����� SR 1 �ɂ͂���܂���ł����B�|���Ђ���̎g���Ă��� Trados �̃o�[�W�����ɂ���Ă͂��̐ݒ肪�Ȃ��A�P��x�[�X�̉�͂��s���Ă���\��������܂��B(���A�Ȃ��Ȃ��A�|��҂Ƃ��Ă͂����܂Ŋm�F���ɂ����ł��ˁ`)
�����ŃJ�E���g����ꍇ�A���̐ݒ�́u�v���W�F�N�g�̐ݒ�v����s���܂��B[�v���W�F�N�g�̐ݒ�] �̍ŏ��̉�� [�v���W�F�N�g] �ŁA�m�������A�W�A����̏ꍇ�ɒP��P�ʂ̃g�[�N�������g�p����] �`�F�b�N�{�b�N�X���I�t�ɂ��܂��B(�f�t�H���g�ŃI�t�̂悤�ł��B)
���̐ݒ肪�A��͌��ʂ����łȂ��v���W�F�N�g�S�̂ɉ����e������̂��͂�����ƕs���ł��B������I�t�ɂ���ƁA��̓��|�[�g�́u�P��P�ʂ̃g�[�N�������g�p����v�́u�������v�ɂȂ�܂��B���̏�Ԃł��AupLift �̋@�\�ł���t���O�����g��v�Ȃǂ͗L���ɋ@�\����C�����܂��B
�Ȃ��A�v���W�F�N�g�̐ݒ��t�@�C���̑傫���ɂ�邩������܂��A�u�P��P�ʂ̃g�[�N�������g�p����v���I���ɂȂ��Ă���ƃt�@�C���̉�͂ɂ����鎞�Ԃ��ُ�ɒ����Ȃ邱�Ƃ�����܂��B�t�@�C���̉�͂́A���Ƃ��Ə������Ԃ̂�����^�X�N�ł����A���̎��Ԃ�����ɒ����Ȃ�܂��B(���́A20 ���ȏォ���������Ƃ�����A���s�������Ǝv���܂����B)
������ �NjL 2018/11/21 ������
���̐ݒ���I���ɂ���Ə������Ԃ������Ȃ�̂��Ǝv���Ă����̂ł����A������I���ɂ��Ȃ��Ă��������Ԃ͒����Ȃ邱�Ƃ�����܂��B�t���O�����g��v�̃J�E���g���͗����ɊW���Ȃ��̂ŁA���̋@�\�Ȃ��ŃJ�E���g�ł�������̂ł����A�A�A
������������������������������

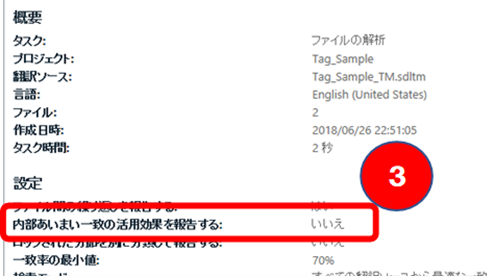
�Ō�ɁA���������Ă��܂�C�ɂ��Ȃ��悤�ɂ��Ă���|�C���g�������Ă����܂��B����́A��L�̐}�ɐԘg�Ŏ������e��̃y�i���e�B�ł��B
���������܂��ϊ�����Ȃ��Ƃ��A������������當�̃X�^�C��������Ă���Ƃ��A�^�O���}������Ă��Ȃ��Ƃ��A�����̑I�������������獢��Ƃ��A�|��҂Ƃ��Ă͂��낢��咣�������Ƃ���ł͂���܂����A�����Ɍ����āA���͍ŋ߂�����߂��݂ł��B���ꂼ��ɂ��čׂ������ׂė��H���R�Ɩ|���Ђ���Ɉًc��\�����Ă�̂͊ȒP�ł͂���܂���B
�����A�|���Ђ�����[���������������ł��̃y�i���e�B�����肵�Ă���Ƃ͌���Ȃ��Ǝv���܂��BTrados �̃f�t�H���g�ݒ�́A��L�̂Ƃ���A��� 3 �� 1% �ŁA���� 2 �� 0% �ł��B�f�t�H���g�ݒ�̂܂܂̏ꍇ������܂����A�ݒ肪�ς����Ă���ꍇ�����Ȃ�̕p�x�ł���܂��B�ǂ���ɂ��Ă��A���́A����܂ŁA���ꂱ�ꂱ���������R�ł��̃y�i���e�B��ݒ肵�Ă��܂��A�Ƃ����悤�Ȑ�����|���Ђ�������Ƃ͂���܂���B�����R�[�f�B�l�[�^�[����ł��A�f�t�H���g�ݒ�̂܂܂�������A�ݒ肪�ύX����Ă�����Ƃ��낢��ł��B(�������A���ꂼ��̃t�@�C�����������������ōœK�Ȑݒ�ɂ��Ă���A�Ƃ����\�����Ȃ��͂Ȃ��ł����B)
���ǁA���́A�R���e�L�X�g �}�b�`�� 100% �}�b�`����ƑΏۂł���ꍇ�́A�y�i���e�B��[���l���Ȃ��悤�ɂ��Ă��܂��B100% �ł� 99% �ł���Ƃ��邱�Ƃɕς��͂Ȃ��̂ŁA�����̃��[�g�̍��͂�����߂܂��B
�����A�R���e�L�X�g �}�b�`�� 100% �}�b�`����ƑΏۂɊ܂܂�Ȃ��ꍇ�́A�����̃y�i���e�B���ǂ���������̂ł͂Ȃ��A�Ƃɂ�����ƑΏۊO�̕��������O�Ƀ��b�N���Ă����悤�ɖ|���Ђ���ɂ��肢���܂��B���b�N����Ă���Ζ��m�Ȃ̂ŁA�����M���č�Ƃ��܂��B
�ȏ�ł��B�O��̋L��������������J�E���g�\�ɂ��Đ������Ă��܂����B�J�E���g�͖���̂��ƂȂ̂ŁA�d�v�Ƃ͂킩���Ă��Ă��A�����m�F��ӂ��Ă��܂����Ƃ�����܂��B�|���Ђ���ւ̘A���́A�x���Ȃ�Ȃ�قǍs���ɂ����Ȃ���̂ł��B��ƃt�@�C�����������A�Ȃ�ׂ������Ɋm�F���邱�Ƃ������߂��܂��B(�����A�����������Ə�X�v���Ă͂��܂��B)


�m�F�|�C���g 4 �\ ���b�N���ꂽ���߂�ʂɕ��ނ��ĕ���

4 �ڂ́u���b�N���ꂽ���߁v�ł��B���̂���܂ł̌o���ł́A���̐ݒ肪�Ԉ���Ă��邱�Ƃ���ԑ����悤�Ɏv���܂��B
�ʏ�A���̐ݒ�́u�͂��v�ŁA���b�N���ꂽ���߂�ʂɃJ�E���g���܂��B���ۂ̎d���ł́A�u���b�N����Ă��镪�߂͍�ƑΏۊO�ŁI�v�Ǝw������邱�Ƃ������A���b�N�Ƃ��ăJ�E���g���ꂽ������ 0 �~�ƂȂ�܂��B�܂��A���b�N����Ă���̂Ŗ��m�ł����A��ƑΏۊO�ƌ�������̎w���ɏ]����������܂���B
�����ATrados �̃f�t�H���g�ݒ�́u�������v�̂悤�Ȃ�ł��B�Ȃ̂ŁA�ԈႦ�ă��b�N�������J�E���g�Ɋ܂܂�Ă��邱�Ƃ����܂ɂ���܂��B�J�E���g����������̂ŁA�Ԉ���Ă����烉�b�L�[�I�Ȃ�čl���Ă͂����܂���B���̐ݒ肪�Ԉ���Ă����ꍇ�A�|���Ђ���͕K���������Ă��܂��B���Ƃ������������s���ꂽ��ł��A���邢�͍�Ƃ��J�n������ł��������Ă��܂���[�B(����������Ȃ��Ƃ�����܂����B)
���b�N����Ă���̂ō�Ƃ͂��Ȃ��ł����A�������x�����Ȃ��͓̂��R�ł����A��Ƃ̒��O���Ƃ̊J�n��̒����͖|��҂Ƃ��Ă͂ƂĂ�����܂��B���Ƃ��A�|���Ђ���u�����̑Őf�̎��_�ł� 10,000 ���[�h�Ƃ��`�����Ă��܂������A���ۂɃt�@�C�������ă��b�N���������O���Ă݂��� 5,000 ���[�h�ł����v�ƌ�����ƁA10,000 ���[�h���̎��Ԃ��m�ۂ��Ă����̂ɁI�I�]�������Ԃ͂ǂ�����H�H�Ƃ������ԂɂȂ�܂��B
���̐ݒ�ł́A���� 1 ���ӓ_������܂��B
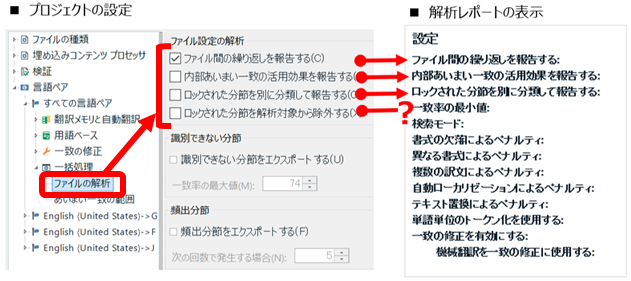
�O��̋L���ŏЉ���ݒ���܂߁A�t�@�C���̉�͂̃I�v�V������ [�v���W�F�N�g�̐ݒ�] -> [����y�A] -> [�ꊇ����] -> [�t�@�C���̉��] ����ݒ�ł��܂��B���̐ݒ��ʂɂ́A���b�N���ꂽ���߂Ɋւ���I�v�V������ 2 ����܂��B
�@�@�@ ���b�N���ꂽ���߂�ʂɕ��ނ��ĕ���
�@�@�A ���b�N���ꂽ���߂���͑Ώۂ��珜�O����
�@ �́u�ʂɕ��ނ��ĕ���v��I������ƁA��̓��|�[�g�Ɂu���b�N�ς݁v�Ƃ������������A�����ɃJ�E���g�����\������܂��B�����āA���|�[�g�㕔�̃I�v�V�����̈ꗗ�ɂ́u���b�N���ꂽ���߂�ʂɕ��ނ��ĕ���: �͂��v�ƕ\������܂��B
�A �́u��͑Ώۂ��珜�O����v��I������ƁA��̓��|�[�g�ł̓��b�N���ꂽ���߂̃J�E���g���͏��O����A�ǂ��ɂ��\������܂���B�����āA���|�[�g�㕔�̃I�v�V�����̈ꗗ�ɂ��A���̃I�v�V�����ɂ��Ă̕\���͂���܂���B�{���ɁA���ׂĂ��珜�O������ł��I �u���b�N���ꂽ���߂�ʂɕ��ނ��ĕ����v�̕\���́A�A �̐ݒ�ɊW�Ȃ��A�@ ���I������Ă��Ȃ�����u�������v�ɂȂ�܂��B
�܂�A�A �́u��͑Ώۂ��珜�O����v���I������Ă��Ă��A��̓��|�[�g��ł͂��̂��Ƃ��킩��܂���B���́u��͑Ώۂ��珜�O����v�̃I�v�V�����͍ŋߒlj����ꂽ�̂ł��傤���B�������̃I�v�V�����ɋC�Â����͍̂ŋ߂ł��B��̓��|�[�g�Łu���b�N���ꂽ���߂�ʂɕ��ނ��ĕ���: �������v�ƂȂ��Ă��Ă��A�|���Ђ���ɘA������O�ɁA�ꉞ�u��͑Ώۂ��珜�O����v�I�v�V�������m�F���Ă݂܂��傤�B
�m�F�|�C���g 5 �\ �P��P�ʂ̃g�[�N�������g�p����

���āA�Ō�̃|�C���g�́u�P��P�ʂ̃g�[�N�����v�ł��B����́ASDL Trados 2017 SR1 �ȍ~�ŁA���������{�ꂩ������̂Ƃ��ɊW���Ă��܂��B�������p��̂Ƃ��͋C�ɂ���K�v���Ȃ��̂ŁA��͕\�ɂ��̃I�v�V�����͕\������Ă��܂���B
���̐ݒ�́A�P��x�[�X�ʼn�͂��邩�A�����x�[�X�ʼn�͂��邩�̑I���ł����A�ڍׂɂ��ẮASDL �̂�����̃u���O���Q�l�ɂȂ�܂��B���̃u���O�̍Ō�Ɂu�ȑO�̉�͕��@�i�����x�[�X�j�ƐV������͕��@�����[�U�[���I���ł���悤�Ȏd�g�݂��J�����ł��v�Ƃ���܂����A����ŊJ�����ꂽ�̂����̐ݒ肾�Ǝv���܂��B
�ʏ�A����́u�������v�ł��B���������{��̏ꍇ�A�����͈�ʓI�ɕ����P���Ōv�Z�����̂ŁA���R�Ȃ����͂������x�[�X�ł���ׂ��ł��B�P��x�[�X�ň�v�����v�Z���āA�����ɕ����P����K�p����Ƃ������Ȃ��ƂɂȂ�܂��B
�����A��L�̃u���O�ɂ�����悤�ɁA���̐ݒ�͏����� SR 1 �ɂ͂���܂���ł����B�|���Ђ���̎g���Ă��� Trados �̃o�[�W�����ɂ���Ă͂��̐ݒ肪�Ȃ��A�P��x�[�X�̉�͂��s���Ă���\��������܂��B(���A�Ȃ��Ȃ��A�|��҂Ƃ��Ă͂����܂Ŋm�F���ɂ����ł��ˁ`)
�����ŃJ�E���g����ꍇ�A���̐ݒ�́u�v���W�F�N�g�̐ݒ�v����s���܂��B[�v���W�F�N�g�̐ݒ�] �̍ŏ��̉�� [�v���W�F�N�g] �ŁA�m�������A�W�A����̏ꍇ�ɒP��P�ʂ̃g�[�N�������g�p����] �`�F�b�N�{�b�N�X���I�t�ɂ��܂��B(�f�t�H���g�ŃI�t�̂悤�ł��B)
���̐ݒ肪�A��͌��ʂ����łȂ��v���W�F�N�g�S�̂ɉ����e������̂��͂�����ƕs���ł��B������I�t�ɂ���ƁA��̓��|�[�g�́u�P��P�ʂ̃g�[�N�������g�p����v�́u�������v�ɂȂ�܂��B���̏�Ԃł��AupLift �̋@�\�ł���t���O�����g��v�Ȃǂ͗L���ɋ@�\����C�����܂��B
�Ȃ��A�v���W�F�N�g�̐ݒ��t�@�C���̑傫���ɂ�邩������܂��A�u�P��P�ʂ̃g�[�N�������g�p����v���I���ɂȂ��Ă���ƃt�@�C���̉�͂ɂ����鎞�Ԃ��ُ�ɒ����Ȃ邱�Ƃ�����܂��B�t�@�C���̉�͂́A���Ƃ��Ə������Ԃ̂�����^�X�N�ł����A���̎��Ԃ�����ɒ����Ȃ�܂��B(���́A20 ���ȏォ���������Ƃ�����A���s�������Ǝv���܂����B)
������ �NjL 2018/11/21 ������
���̐ݒ���I���ɂ���Ə������Ԃ������Ȃ�̂��Ǝv���Ă����̂ł����A������I���ɂ��Ȃ��Ă��������Ԃ͒����Ȃ邱�Ƃ�����܂��B�t���O�����g��v�̃J�E���g���͗����ɊW���Ȃ��̂ŁA���̋@�\�Ȃ��ŃJ�E���g�ł�������̂ł����A�A�A
������������������������������
���܂�m�F���Ȃ��|�C���g �\ �e��y�i���e�B

�Ō�ɁA���������Ă��܂�C�ɂ��Ȃ��悤�ɂ��Ă���|�C���g�������Ă����܂��B����́A��L�̐}�ɐԘg�Ŏ������e��̃y�i���e�B�ł��B
���������܂��ϊ�����Ȃ��Ƃ��A������������當�̃X�^�C��������Ă���Ƃ��A�^�O���}������Ă��Ȃ��Ƃ��A�����̑I�������������獢��Ƃ��A�|��҂Ƃ��Ă͂��낢��咣�������Ƃ���ł͂���܂����A�����Ɍ����āA���͍ŋ߂�����߂��݂ł��B���ꂼ��ɂ��čׂ������ׂė��H���R�Ɩ|���Ђ���Ɉًc��\�����Ă�̂͊ȒP�ł͂���܂���B
�����A�|���Ђ�����[���������������ł��̃y�i���e�B�����肵�Ă���Ƃ͌���Ȃ��Ǝv���܂��BTrados �̃f�t�H���g�ݒ�́A��L�̂Ƃ���A��� 3 �� 1% �ŁA���� 2 �� 0% �ł��B�f�t�H���g�ݒ�̂܂܂̏ꍇ������܂����A�ݒ肪�ς����Ă���ꍇ�����Ȃ�̕p�x�ł���܂��B�ǂ���ɂ��Ă��A���́A����܂ŁA���ꂱ�ꂱ���������R�ł��̃y�i���e�B��ݒ肵�Ă��܂��A�Ƃ����悤�Ȑ�����|���Ђ�������Ƃ͂���܂���B�����R�[�f�B�l�[�^�[����ł��A�f�t�H���g�ݒ�̂܂܂�������A�ݒ肪�ύX����Ă�����Ƃ��낢��ł��B(�������A���ꂼ��̃t�@�C�����������������ōœK�Ȑݒ�ɂ��Ă���A�Ƃ����\�����Ȃ��͂Ȃ��ł����B)
���ǁA���́A�R���e�L�X�g �}�b�`�� 100% �}�b�`����ƑΏۂł���ꍇ�́A�y�i���e�B��[���l���Ȃ��悤�ɂ��Ă��܂��B100% �ł� 99% �ł���Ƃ��邱�Ƃɕς��͂Ȃ��̂ŁA�����̃��[�g�̍��͂�����߂܂��B
�����A�R���e�L�X�g �}�b�`�� 100% �}�b�`����ƑΏۂɊ܂܂�Ȃ��ꍇ�́A�����̃y�i���e�B���ǂ���������̂ł͂Ȃ��A�Ƃɂ�����ƑΏۊO�̕��������O�Ƀ��b�N���Ă����悤�ɖ|���Ђ���ɂ��肢���܂��B���b�N����Ă���Ζ��m�Ȃ̂ŁA�����M���č�Ƃ��܂��B
�ȏ�ł��B�O��̋L��������������J�E���g�\�ɂ��Đ������Ă��܂����B�J�E���g�͖���̂��ƂȂ̂ŁA�d�v�Ƃ͂킩���Ă��Ă��A�����m�F��ӂ��Ă��܂����Ƃ�����܂��B�|���Ђ���ւ̘A���́A�x���Ȃ�Ȃ�قǍs���ɂ����Ȃ���̂ł��B��ƃt�@�C�����������A�Ȃ�ׂ������Ɋm�F���邱�Ƃ������߂��܂��B(�����A�����������Ə�X�v���Ă͂��܂��B)
�^�O�FupLIFT �e�N�m���W�[ ������ ���[�h�J�E���g ���[�h�� �t�@�C���̉�� SDL Trados Studio �J�E���g ���b�N���ꂽ���� ���b�N �P��P�ʂ̃g�[�N���� �v���W�F�N�g�̐ݒ� Trados Studio 2017 SR1 �y�i���e�B
Tweet
2018�N06��27��
�J�E���g�\���悭�m�F���悤 �\ ���� �@
�O��̕������̘b�Ɉ��������A�J�E���g�̘b������グ�����Ǝv���܂��B����́A�O��̋L����菭���傫�Ȏ��_�ōl���܂��B
��������[�h���̃J�E���g���@�́A�ׂ������Ă����Ƃ��肪����܂���B�O��̃^�O�͂������ł����A�����A�p�P��AURL�A�n�C�t����A�|�X�g���t�B�A����L���Ȃǂ��ׂ������ׂĂ����ƁA�|���Ђ�����ꂽ�����ɑ��Ă��낢��^�₪������ł��邩������܂���B�����A�ݒ�ŕς����Ȃ�������A��ʓI�Ƃ���Ă��郋�[������������ŁA�|��҂̎咣���Ƃ����̂͂Ȃ��Ȃ�����̂������ł��B
�����A�����Ă��͖|���Ђ������Ă���J�E���g�������̂܂ܐM���Ă��܂��܂����A����ł��A�ꉞ�m�F���ׂ��|�C���g�͂���܂��B����̋L���ł́A�u�܂��ׂ����ݒ�͖|���Ђ����M���邯�ǁA����ł��m�F���Ă����������Ɓv�������̔��Y�^�����˂ďЉ�����Ǝv���܂��B
�܂��́A�ȉ��̂悤�� Trados �����̉�̓��|�[�g����肵�܂��B
��̓��|�[�g�͖|���Ђ������邱�Ƃ������ł����A��Ђ���ɂ���ẮA�Ǝ��̌`���̃J�E���g�\���g���Ă��āATrados �����̉�̓��|�[�g�͒��Ă���Ȃ����Ƃ�����܂��B��L�̐}�̐Ԑ��ň͂�ł��镔�����m�F�������̂ŁA�J�E���g�l�����𒊏o�����Ǝ��쐬�̕\�Ȃǂł͂Ȃ��ATrados �Ő������ꂽ��̓��|�[�g����肵�܂��B
�|���Ђ������Ȃ��ꍇ�́A�����ŃJ�E���g���܂��B�v���W�F�N�g���E�N���b�N���� [�ꊇ�^�X�N] -> [�t�@�C���̉��] �ƑI�����A�^�X�N�����s���ă��|�[�g���쐬���܂��B�v���W�F�N�g������̐ݒ��ς��Ă��܂��ƃJ�E���g�l�ɉe�����邱�Ƃ�����̂ŁA�p�b�P�[�W���J������A�܂����̂܂܂̐ݒ�� [�t�@�C���̉��] �����s���܂��B

�ŏ��̃|�C���g�́u�|��\�[�X�v�ł��B��������Ȃ����t�ɂȂ��Ă��܂����A���̂��Ƃ͂Ȃ��|�����̂��Ƃł��B��v���̊�ƂȂ���̂Ȃ̂ŕK���m�F���܂��B��Ǝw�����ȂǂɋL�ڂ���Ă��郁�����ƁA���ۂ� Trados �ɐݒ肳��Ă��郁�����ƁA�����ăJ�E���g�\�̃����������ׂĈ�v���Ă��邱�Ƃ��m�F���܂��B
�����̃�����������ꍇ�Ȃǂ́A�|���Ђ�������܂ɊԈႦ�Ă��邱�Ƃ�����܂��B���ۂɍ�ƂŎg���������ŃJ�E���g����Ă��邱�Ƃ��m�F���܂��B

2 �ڂ́u�t�@�C���Ԃ̌J��Ԃ��v�ł��B����́A�����̃t�@�C�����܂ރv���W�F�N�g�ŁA���������ʂ̃t�@�C���ɂ���ꍇ�ł��J��Ԃ��Ƃ݂Ȃ����ǂ����̐ݒ�ł��B�ʏ�́u�͂��v�ŁA�ʂ̃t�@�C���ł��J��Ԃ��Ƃ��ăJ�E���g���܂��B
���̂Ƃ����ӂ������̂��t�@�C�����ł��B�傫�ȃv���W�F�N�g�̏ꍇ�A�|���Ђ���� 1 �̃v���W�F�N�g���畡���̃p�b�P�[�W������ĉ��l���̖|��҂���ɔz�z���邱�Ƃ�����܂��B�����Ɋ��蓖�Ă�ꂽ�t�@�C���̒��ł̌J��Ԃ��́u�J��Ԃ��v�Ƃ��ăJ�E���g����Ė�肠��܂��A�ق��̖|��҂���Ɋ��蓖�Ă�ꂽ�t�@�C���Ƃ̌J��Ԃ��͂����͂����܂���B�Ȃ̂ŁA�t�@�C�����������Ɋ��蓖�Ă��Ă���t�@�C�����ƈ�v���Ă��邩���m�F���܂��B
�|���Ђ���쐬�̃J�E���g�\��������Ȃ��ꍇ�́A�u�J��Ԃ��v�̃J�E���g�����ATrados �����̃��|�[�g��̒l�ƈ�v���Ă��邩���m�F���܂��B�v���W�F�N�g�S�̂ŃJ�E���g����Ă���ƁA�ق��̖|��҂���̃t�@�C���Ƃ̌J��Ԃ����܂܂�邱�ƂɂȂ��Ă��܂��̂ŁA�O�̂��ߊm�F���܂��傤�B
3 �ڂ́u���������܂���v�v�ł��B����́A�V�K�|�邯��ǂ������悤�ȕ����J��Ԃ��o�ꂷ��悤�ȕ����ŁA���́u�����悤�ȕ��v���������Ƃ̈�v�Ɠ����悤�Ɂu�����܂���v�v�Ƃ��ăJ�E���g����Ƃ������̂ł��B
���Ƃ��A�V�K�|�镔���ɁuClick the Save button.�v�ƁuClick the OK button.�v�Ƃ�����������ƁA�ォ��o�ꂵ�������u���������܂���v�v�ƂȂ�A�������Ƃ̈�v�Ɠ����悤�Ɉ�v�����v�Z����܂��B
�ʏ�A���̐ݒ�́u�������v�ł��B���R�ł��B���ꂩ�玩���Ŗ̂ł�����A�V�K�|��Ƃ��Ă̗��������炢�܂��B����Ƃ��Ē���郁�����Ƃ̈�v�ŗ���������������͎̂d���Ȃ��Ƃ��Ă��A����ł��Ȃ��̂ɗ���������������̂͂�����Ɣ[���ł��܂���B
���́A����܂ł̎d���ł��̐ݒ肪�u�͂��v�ɂȂ��Ă������Ƃ�����܂����B�قƂ�ǂ̏ꍇ���P�Ȃ�ݒ�~�X�ŁA�|���Ђ���Ɋm�F�����炷���ɒ������Ă��炦�܂����B�܂��A���������܂���v���ǂꂭ�炢����̂��͂�����ƋC�ɂȂ�̂ŁA�u�͂��v�ɂ��ăJ�E���g���Ă݂����Ȃ�C�����͂킩��܂��B
�����A�Ӑ}�I�ɂ��̐ݒ肪�u�͂��v�ɂ���Ă��邱�Ƃ�����܂����B�����O�ɁA���������܂���v���K�p���ꂽ�J�E���g�\�������Ă����̂Ŋm�F�����Ƃ���A�u����͂��̐ݒ�ł��肢���܂��v�Ƃ̕ԓ��ł����B�������ɁA�u���O�ɉ��̒f����Ȃ������Ȃ肱�̐ݒ��K�p���Ă���̂͂���܂肶�Ⴀ��܂��H�v�� (�����) �R�c�����Ă��������܂����B���ʂƂ��āA�J�E���g�������Ă��炦�܂������A���܂肢���C���ł͂Ȃ��ł��ˁ`�B
�u���������܂���v�v��K�p����ƁA�J�E���g���͏��Ȃ��Ȃ�\���������̂ŁA��������u�͂��v�ɐݒ肳��Ă��Ȃ����A�O�̂��ߊm�F���邱�Ƃ������߂��܂��B
���āA����͂����܂łł��B�L���������Ă݂���\�z�ȏ�ɒ����Ȃ��Ă��܂����̂ŁA�㔼�͎����ɂ����Ă��������܂��B�ŋ߁A�u���O�̍X�V�p�x���Ⴍ�Ȃ��Ă��Ă��܂��Ă��܂����A�撣��܂��I ���y���݂ɁI�I
��������[�h���̃J�E���g���@�́A�ׂ������Ă����Ƃ��肪����܂���B�O��̃^�O�͂������ł����A�����A�p�P��AURL�A�n�C�t����A�|�X�g���t�B�A����L���Ȃǂ��ׂ������ׂĂ����ƁA�|���Ђ�����ꂽ�����ɑ��Ă��낢��^�₪������ł��邩������܂���B�����A�ݒ�ŕς����Ȃ�������A��ʓI�Ƃ���Ă��郋�[������������ŁA�|��҂̎咣���Ƃ����̂͂Ȃ��Ȃ�����̂������ł��B
�����A�����Ă��͖|���Ђ������Ă���J�E���g�������̂܂ܐM���Ă��܂��܂����A����ł��A�ꉞ�m�F���ׂ��|�C���g�͂���܂��B����̋L���ł́A�u�܂��ׂ����ݒ�͖|���Ђ����M���邯�ǁA����ł��m�F���Ă����������Ɓv�������̔��Y�^�����˂ďЉ�����Ǝv���܂��B
Trados �����̉�̓��|�[�g����肷��
�܂��́A�ȉ��̂悤�� Trados �����̉�̓��|�[�g����肵�܂��B

��̓��|�[�g�͖|���Ђ������邱�Ƃ������ł����A��Ђ���ɂ���ẮA�Ǝ��̌`���̃J�E���g�\���g���Ă��āATrados �����̉�̓��|�[�g�͒��Ă���Ȃ����Ƃ�����܂��B��L�̐}�̐Ԑ��ň͂�ł��镔�����m�F�������̂ŁA�J�E���g�l�����𒊏o�����Ǝ��쐬�̕\�Ȃǂł͂Ȃ��ATrados �Ő������ꂽ��̓��|�[�g����肵�܂��B
�|���Ђ������Ȃ��ꍇ�́A�����ŃJ�E���g���܂��B�v���W�F�N�g���E�N���b�N���� [�ꊇ�^�X�N] -> [�t�@�C���̉��] �ƑI�����A�^�X�N�����s���ă��|�[�g���쐬���܂��B�v���W�F�N�g������̐ݒ��ς��Ă��܂��ƃJ�E���g�l�ɉe�����邱�Ƃ�����̂ŁA�p�b�P�[�W���J������A�܂����̂܂܂̐ݒ�� [�t�@�C���̉��] �����s���܂��B
�m�F�|�C���g 1 �\ �|��\�[�X

�ŏ��̃|�C���g�́u�|��\�[�X�v�ł��B��������Ȃ����t�ɂȂ��Ă��܂����A���̂��Ƃ͂Ȃ��|�����̂��Ƃł��B��v���̊�ƂȂ���̂Ȃ̂ŕK���m�F���܂��B��Ǝw�����ȂǂɋL�ڂ���Ă��郁�����ƁA���ۂ� Trados �ɐݒ肳��Ă��郁�����ƁA�����ăJ�E���g�\�̃����������ׂĈ�v���Ă��邱�Ƃ��m�F���܂��B
�����̃�����������ꍇ�Ȃǂ́A�|���Ђ�������܂ɊԈႦ�Ă��邱�Ƃ�����܂��B���ۂɍ�ƂŎg���������ŃJ�E���g����Ă��邱�Ƃ��m�F���܂��B
�m�F�|�C���g 2 �\ �t�@�C���Ԃ̌J��Ԃ������

2 �ڂ́u�t�@�C���Ԃ̌J��Ԃ��v�ł��B����́A�����̃t�@�C�����܂ރv���W�F�N�g�ŁA���������ʂ̃t�@�C���ɂ���ꍇ�ł��J��Ԃ��Ƃ݂Ȃ����ǂ����̐ݒ�ł��B�ʏ�́u�͂��v�ŁA�ʂ̃t�@�C���ł��J��Ԃ��Ƃ��ăJ�E���g���܂��B
���̂Ƃ����ӂ������̂��t�@�C�����ł��B�傫�ȃv���W�F�N�g�̏ꍇ�A�|���Ђ���� 1 �̃v���W�F�N�g���畡���̃p�b�P�[�W������ĉ��l���̖|��҂���ɔz�z���邱�Ƃ�����܂��B�����Ɋ��蓖�Ă�ꂽ�t�@�C���̒��ł̌J��Ԃ��́u�J��Ԃ��v�Ƃ��ăJ�E���g����Ė�肠��܂��A�ق��̖|��҂���Ɋ��蓖�Ă�ꂽ�t�@�C���Ƃ̌J��Ԃ��͂����͂����܂���B�Ȃ̂ŁA�t�@�C�����������Ɋ��蓖�Ă��Ă���t�@�C�����ƈ�v���Ă��邩���m�F���܂��B
�|���Ђ���쐬�̃J�E���g�\��������Ȃ��ꍇ�́A�u�J��Ԃ��v�̃J�E���g�����ATrados �����̃��|�[�g��̒l�ƈ�v���Ă��邩���m�F���܂��B�v���W�F�N�g�S�̂ŃJ�E���g����Ă���ƁA�ق��̖|��҂���̃t�@�C���Ƃ̌J��Ԃ����܂܂�邱�ƂɂȂ��Ă��܂��̂ŁA�O�̂��ߊm�F���܂��傤�B
�m�F�|�C���g 3 �\ ���������܂���v�̊��p���ʂ����

3 �ڂ́u���������܂���v�v�ł��B����́A�V�K�|�邯��ǂ������悤�ȕ����J��Ԃ��o�ꂷ��悤�ȕ����ŁA���́u�����悤�ȕ��v���������Ƃ̈�v�Ɠ����悤�Ɂu�����܂���v�v�Ƃ��ăJ�E���g����Ƃ������̂ł��B
���Ƃ��A�V�K�|�镔���ɁuClick the Save button.�v�ƁuClick the OK button.�v�Ƃ�����������ƁA�ォ��o�ꂵ�������u���������܂���v�v�ƂȂ�A�������Ƃ̈�v�Ɠ����悤�Ɉ�v�����v�Z����܂��B
�ʏ�A���̐ݒ�́u�������v�ł��B���R�ł��B���ꂩ�玩���Ŗ̂ł�����A�V�K�|��Ƃ��Ă̗��������炢�܂��B����Ƃ��Ē���郁�����Ƃ̈�v�ŗ���������������͎̂d���Ȃ��Ƃ��Ă��A����ł��Ȃ��̂ɗ���������������̂͂�����Ɣ[���ł��܂���B
���́A����܂ł̎d���ł��̐ݒ肪�u�͂��v�ɂȂ��Ă������Ƃ�����܂����B�قƂ�ǂ̏ꍇ���P�Ȃ�ݒ�~�X�ŁA�|���Ђ���Ɋm�F�����炷���ɒ������Ă��炦�܂����B�܂��A���������܂���v���ǂꂭ�炢����̂��͂�����ƋC�ɂȂ�̂ŁA�u�͂��v�ɂ��ăJ�E���g���Ă݂����Ȃ�C�����͂킩��܂��B
�����A�Ӑ}�I�ɂ��̐ݒ肪�u�͂��v�ɂ���Ă��邱�Ƃ�����܂����B�����O�ɁA���������܂���v���K�p���ꂽ�J�E���g�\�������Ă����̂Ŋm�F�����Ƃ���A�u����͂��̐ݒ�ł��肢���܂��v�Ƃ̕ԓ��ł����B�������ɁA�u���O�ɉ��̒f����Ȃ������Ȃ肱�̐ݒ��K�p���Ă���̂͂���܂肶�Ⴀ��܂��H�v�� (�����) �R�c�����Ă��������܂����B���ʂƂ��āA�J�E���g�������Ă��炦�܂������A���܂肢���C���ł͂Ȃ��ł��ˁ`�B
�u���������܂���v�v��K�p����ƁA�J�E���g���͏��Ȃ��Ȃ�\���������̂ŁA��������u�͂��v�ɐݒ肳��Ă��Ȃ����A�O�̂��ߊm�F���邱�Ƃ������߂��܂��B
���āA����͂����܂łł��B�L���������Ă݂���\�z�ȏ�ɒ����Ȃ��Ă��܂����̂ŁA�㔼�͎����ɂ����Ă��������܂��B�ŋ߁A�u���O�̍X�V�p�x���Ⴍ�Ȃ��Ă��Ă��܂��Ă��܂����A�撣��܂��I ���y���݂ɁI�I
| �@�@ |
�^�O�FSDL Trados Studio �t�@�C���̉�� �J�E���g ���[�h�� ������ ���������܂���v �J��Ԃ� �t�@�C���Ԃ̌J��Ԃ������ �|��\�[�X ���������܂���v�̊��p���ʂ���� ���[�h�J�E���g
Tweet
2018�N06��03��
SDL Trados Studio 2019 �̐V�@�\ �\ �l�|��҂̎��_����
�O���͕������ׂ̍������b�ł����B���̂Ƃ��͎�����������̂��b�ɂ��悤�Ǝv���Ă����̂ł����A�ŋ߁ATrados �̐V�o�[�W���� 2019 �̏Љ�������̂ŁA����͂��̐V�o�[�W�����ɂ��Ă�����Ə����Ă݂����Ǝv���܂��B
SDL �̌����u���O�ɏЉ�L��������܂����B
SDL Trados Studio 2019�̐V�@�\
https://blog.sdltrados.com/jp/whats-new-trados-studio-2019/

���̌����u���O�������ƓǂƂ���ł́A�u�|���Ђ��炨�d�������炤�l�|��҂ɂƂ��ē��ɑ傫�ȐV�@�\�͂Ȃ��v�Ƃ�����ۂł������A�ǂ��ł��傤�H�H ����ȉ��߂ł����̂��Ȃ��B�ȉ��A���̌����u���O�ɏ�����Ă����e���ڂɂ��āA�l�|��҂Ƃ��Ďv�������Ƃ������Ă݂܂����B
Trados�r�M�i�[�̋��͂Ȗ��� �\ Walk Me
�e�@�\�ւ̐v���ȃA�N�Z�X �\ Tell Me
�e�@�\�ւ̐v���ȃA�N�Z�X �\ Tell Me
�uWalk Me�v�͎�ɏ��S�Ҍ����A�uTell Me�v�͋@�\��ݒ���ȒP�Ɍ�������A�Ƃ������Ƃł��B���낢��Ƃ킩��₷���Ȃ�̂͊�����ł��B
�����u���O�Ɍf�ڂ���Ă����X�N���[���V���b�g�ł́A�����{�b�N�X�ɉp�����͂��ċ@�\���������Ă��܂��B����́A�܂��x�[�^�ł�����ł���ˁA�����ƁB�L���̖`���ɂ��u�ꕔ���{�ꉻ����Ă��Ȃ��v�ƒ��ӏ���������܂����B�����łł͓��{��Ō����ł��܂���ˁH�H �����łȂ��ƁA���͍���܂��B
�V�����v���W�F�N�g�쐬�E�B�U�[�h
�uMetro Map�v�Ƃ����X�g���[�����C���ɂ���Ă킩��₷���Ȃ邻���ł��B�悭�ʔ̃T�C�g�ȂǂŁA�u���i�̑I�� -> �m�F -> ���x�����v�ƃX�e�b�v�̈ꗗ���\������邱�Ƃ�����܂����A����Ɠ����ł��B
���͖|���Ђ���p�b�P�[�W������č�Ƃ��邱�Ƃ������A�����ŐV�����v���W�F�N�g���쐬���邱�Ƃ͂��܂肠��܂��AMetro Map �̓v���W�F�N�g�̐V�K�쐬�E�B�U�[�h�ȊO�ɂ��g���Ă���悤�Ȃ̂ŁA���낢��킩��₷���Ȃ��Ă���Ɗ������ł��B
�v���W�F�N�g�t�@�C���̒lj���ύX�ɂ��_��ɑΏ�
�v���W�F�N�g���쐬������Ńt�@�C����lj�������X�V�����肷�邱�Ƃ��ȒP�ɂȂ��������ł��B����́A�l�̖|��҂ł�������ƋC�ɂȂ�܂��B�p�b�P�[�W������č�Ƃ��n�߂Ă��܂�����͂ǂ��Ȃ�̂ł��傤�H�H
��Ƃ��J�n���Ă��܂����t�@�C���̍X�V�͂ƂĂ�����܂��B�������͂���Ƃ��Ă��A�����Ȃǂ����Ă���\��������̂ŁA�P���Ɉꊇ�|��킯�ɂ͂������A�����ʓ|�Ȏv�������Ă��܂��B
��Ƃ��J�n�����o�C�����K�� �t�@�C�����A�ύX�ɂȂ������������X�V���Ă����A�Ƃ����̂ł���ƂĂ��֗������Ɏv���܂��B�ł��A�{���ɂ���Ȃ��Ƃł���̂ł��傤���H �p�b�P�[�W����������Ńt�@�C���̍X�V��Ƃ����Ȃ���Ȃ�Ȃ��ƂȂ�ƁA�t�@�C������������ꍇ�Ȃǂ͎�Ԃ������肻���ł����A�X�V�����̃��[�h�����ǂ̂悤�ɃJ�E���g�����̂������Ȃ�C�ɂȂ�܂��B�܂��A������Ɗ��ҁH�H���Ă݂܂��B
���؋@�\�̐ݒ肪���ꂲ�Ƃɉ\��
���݂܂���A���͉p��Ɠ��{��݂̂Ȃ̂ŁA���܂�W���Ȃ��ł��B
�|�����̓��e����茩�₷��
�u�|�����v�r���[�ŁA1 �y�[�W�ɕ\����������ύX�ł���悤�ɂȂ�A���݂���y�[�W�����\�������悤�ɂȂ��������ł��B�ׂ����@�\�ł���������Ɗ������ł��B��������ҏW���Ă���ƁA���������ǂꂾ��������������̂��킩�炸�A���肵�Ă��܂����Ƃ��������̂ŁA���������@�\�͂�����������Ȃ��ł��B
Visio�t�@�C���ɑΉ�
Visio �t�@�C���Ɂu�Ή��v���������ł��B������āAVisio �������Ă��Ȃ����ł�������v���r���[���ł���A�Ƃ������Ƃł͂Ȃ��ł���ˁH �c�O�Ȃ���A���� Visio �������Ă��܂���B�t���[�`���[�g����� Visio �t�@�C�����A�v���r���[�ł��Ȃ����ǃo�C�����K�� �t�@�C���ŖĂˁA�Ƃ����˗���������A���������Ă��f�肵�����Ȃ�܂��B
�����u���O�ŏЉ��Ă����@�\�͈ȏ�ł��B2017 �̂Ƃ��� upLift �e�N�m���W�[�̂悤�ȑ傫�ȐV�@�\�͂Ȃ������Ȃ̂ŁA�A�b�v�O���[�h���邩�ǂ����͖|���Ђ���̏ɂ��ł��傤���B2019 �ō�����o�C�����K�� �t�@�C���� 2017 �ł̓v���r���[������ł��Ȃ��A�Ƃ������Ԃɂ����͂Ȃ��ė~�����Ȃ��ł��B������āA�l�|��҂ɂƂ��Ắu���ʌ݊����Ȃ��v�̂Ƃقړ����ł��B
����͈ȏ�ł��B ���炭�́A���҂����߂āA�o�ߊώ@���Ă݂悤���Ǝv���܂��B
Tweet