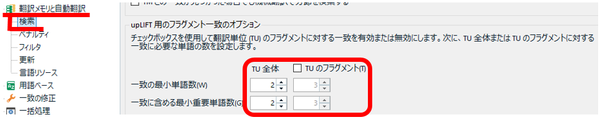
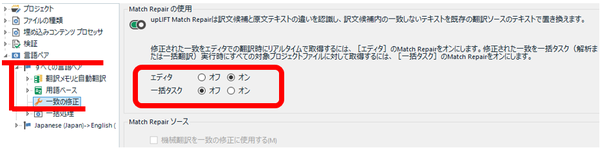
�ق�܉�̍u���ł́A�����ŗp��W���쐬������@�Ƃ��āA����Ɩ����N���b�v�{�[�h�ɃR�s�[���ė�������C�Ƀe�L�X�g �t�@�C���ɏ����o���X�N���v�g���Љ��܂����B���́u2 �̃e�L�X�g����C�Ƀt�@�C���ɏ����o���v�Ƃ��������� 2 �̃e�L�X�g���r���鑀��ɉ��p���܂����B��̓I�ɂ́AAutoHotKey ���g���� 2 �̃e�L�X�g���t�@�C���ɏ����o���AWinMerge ���g���Ď��ۂ̔�r���s���܂��B
���́AWinMerge �ł̃e�L�X�g��r�͈ȑO����悭�g���Ă����̂ł����A����A��r�Ώۂ� 2 �����ꂼ��N���b�v�{�[�h�ɃR�s�[���āA���ꂼ��\��t���ĂƂ������삪�ʓ|�ł����B����� AutoHotKey �ŏ��������ł�����Ԃ�����܂��B
�e�L�X�g���r�������Ȃ�Ƃ�
���āA���������Ȃ��e�L�X�g���r�������̂��Ƃ����ƁATrados �Ń��r���[��Ƃ����Ȃ���Ȃ�Ȃ�����ł��BTrados �Ȃ̂œ��R���������g���Ė|�ꂽ���̂����r���[����̂ł����A���ꂪ�Ȃ��Ȃ���ςł��B
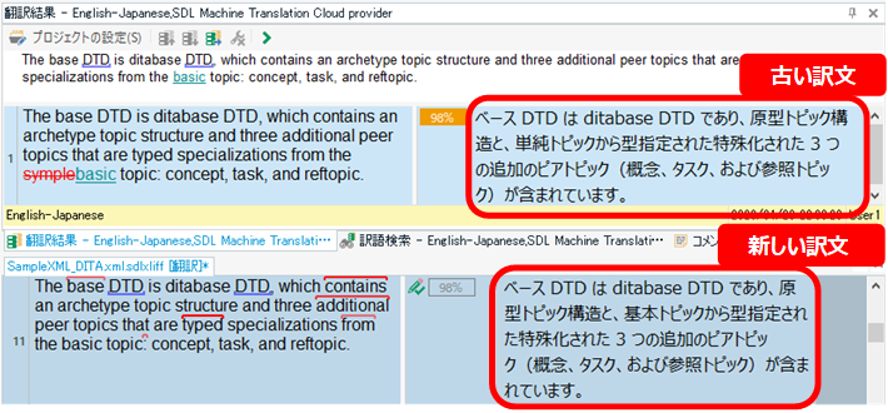
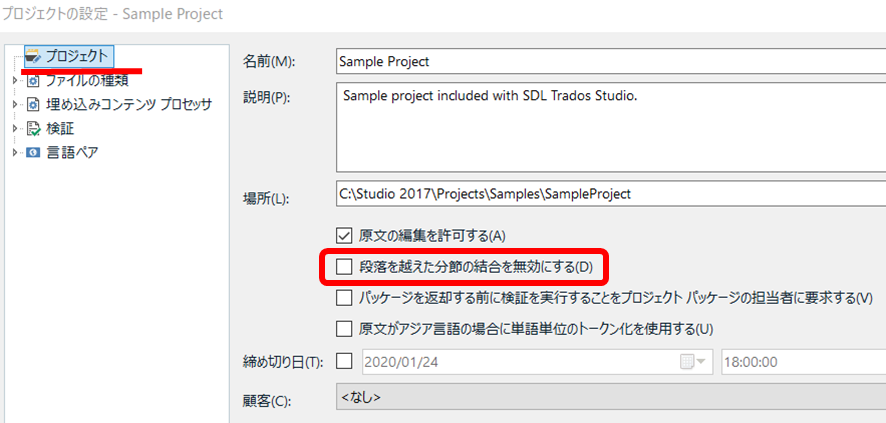
�t�@�W�[ �}�b�`�̕��߂����r���[����ꍇ�ATrados �̉�ʂ͏�}�̂悤�ɂȂ�܂��B�������̓��e�� [�|��] �E�B���h�E�ɕ\������A�G�f�B�^�����ɂ́A�|��҂����͂����V�������\������Ă��܂��B�����̃X�e�[�^�X�̗��Ɂu98%�v�Ɣ��g�ŕ\������Ă���̂ŁA98% �}�b�`�̃��������g���Ăǂ�����ҏW�����Ƃ������Ƃ܂ł͂킩��܂����A�ǂ���ҏW�����̂��͂킩��܂���B�����̈Ⴂ�́A[�|��] �E�B���h�E�ɕύX�����̂悤�Ȍ`���ŕ\������܂����A�ɂ��Ă͂��̂悤�ȕ\���͂���܂���B
���������Ƃ��ɁA���������̌Â��Ɩ|��҂���̐V�������r�ł���ƂƂĂ��֗��ł��B���}�̂悤�� 2 �̃e�L�X�g�� WinMerge �ŕ\������A�ǂ����ς�����̂����ЂƖڂł킩��܂��B

WinMerge ���g���Ĕ�r����
WinMerge �́A2 �̃e�L�X�g �t�@�C�����r���Ă����c�[���ł��B�ׂ����ݒ�͂��낢�날��܂����A���́A�P���Ɉȉ��̂悤�Ɏg���Ă��܂��B
�@�@��������
�@�@1. ���p�� org.txt �����B
�@�@2. �V�����p�� changed.txt �����B
�@�@3. ���� 2 �̃t�@�C���̑g�ݍ��킹���e���v���[�g�Ƃ��ĕۑ����Ă����B
�@�@����r���遄
�@�@1. WinMerge �ŁA�ۑ����Ă������e���v���[�g���J���B
�@�@2. �Â��� org.txt �ɓ��͂���B
�@�@3. �V������ changed.txt �ɓ��͂���B
�@�@4. Ctrl+F5 �������Ĕ�r����B
����̎��� AutoHotKey �̃X�N���v�g�ł́A���� WinMerge �Ńe���v���[�g���J����Ă��邱�Ƃ�O��Ƃ��܂��� (���݂܂���A�e���v���[�g�͎蓮�ŊJ���܂�)�B�ŁATrados ��ŌÂ��ƐV�������N���b�v�{�[�h�ɃR�s�[������ (�����܂Ŏ蓮�ł�)�A���Ƃ� AutoHotKey �� 2 �̖����ꂼ��̃t�@�C���ɓ��͂��āAWinMerge �̃E�B���h�E���A�N�e�B�u�ɂ���Ƃ���܂ł��s���܂��B
AutoHotKey �ł́A�E�B���h�E���A�N�e�B�u�ɂ������ Ctrl+F5 ����͂��邱�Ƃ��ł��܂����A���̊��ł́AWinMerge ���̂��烁�b�Z�[�W�{�b�N�X���\�������̂ŁA����� Ctrl+F5 ����͂��鏈���͍s���܂���ł����B(����̃X�N���v�g�́A�ق�܉�̃X�N���v�g���قڂ��̂܂g���Ă���̂ŁA�ڂ��������͏ȗ������Ă��炢�܂��B)
����ł��A���r���[�ɂ͎�Ԃ�������
�ق�܉�̊F����̔M�C�Ɉ��|����A�c�[�����ĂȂ�ĕ֗��Ȃ낤�Ɗ������A���̋��������̂܂܂ɋA��āA�����X�N���v�g�������܂����B���ۂɎ����āA�l���Ă�������������ł����Ƃ��́A����͂����������I�I�Ɗ������Ȃ�܂����B���A���炭���ċC���������������Ă���ƁAAutoHotKey �͕֗����Ƃ��Ă��A���r���[��Ǝ��̂͂���قǕς���Ă��Ȃ������Ǝv���Ă��܂����B������ǂ�ŁA��ǂ�ŁA�������̓��e���m�F���āA�� Trados �ł̃��r���[��Ƃ͂���ς��Ԃ�������܂��B
���r���[�̗������}�b�`���Ŋ�������Ă��邯��
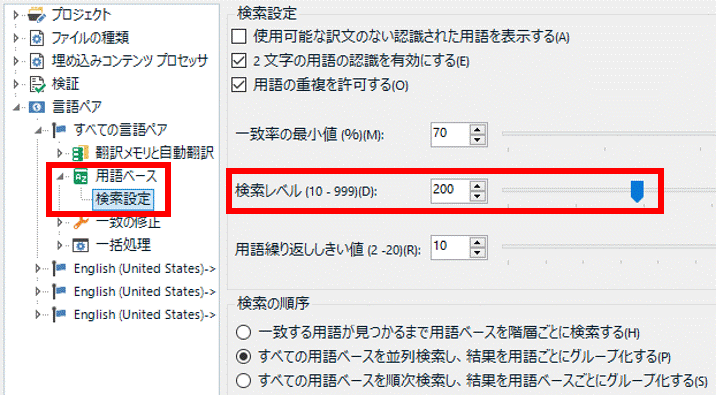
���r���[��Ƃ̎�Ԃ�����ȂɋC�ɂȂ錴���́A���̒P���ł��B���͖|���Ђ��烌�r���[���˗�����邱�Ƃ������̂ł����A�����Ă��̖|���Ђ̓��r���[�̂Ƃ����|��Ɠ����悤�Ƀ}�b�`���ł̊�����K�p���Ă��܂��B�Ȃ̂ŁA�}�b�`���������̃��r���[�P���́A�ƂĂ��A�ƂĂ��A�ƂĂ������Ȃ�܂��B�����_�ȉ� 3 �����炢�܂Ōv�Z���K�v�Ȋ����ł��B
�������������Ă����r���[�̍�Ɨʂ͂���Ȃɕς��Ȃ�
���̊��o�I�ɂ́A���r���[�̂Ƃ��́A�}�b�`���郁�����������Ă�����قǍ�Ǝ��Ԃ͕ς��܂���B���������g�����Ǝ��̂ɂ��낢����͂��邩������܂��A����ł��|���Ƃł́A�}�b�`���������ΐV�������͂��镶���͏��Ȃ��čςނƂ��������͂���Ǝv���܂��B�ł��A���r���[��Ƃł́A�͊��ɓ��͂���Ă���̂ŕ����̓��͗ʂ͍ŏ����瑽������܂���B�����������邩��Ƃ����ĕ����������ǂ߂�悤�ɂȂ�킯�ł͂Ȃ����A�}�b�`���������Γǂޗʂ͑����邵�A�}�b�`���ł̊����͎���Ƃɍ����Ă��Ȃ��̂ł͂Ǝ��͊����Ă��܂��B
�ł��A�|���Ђɔ��_�ł��Ȃ� (;�;)
�}�b�`���ł̊����͎���Ƃɍ���Ȃ��Ǝv�����A�|���Ђɂ������_�������Ƃ͂܂�����܂���B�ǂ̂悤�ɔ��_���ׂ����A�Ȃ��Ȃ��ǂ��Ă������т܂���B���r���[�ł̓������������Ă������̓��͗ʂ͕ς��Ȃ��A�Ƃ����̂� 1 �̗��R�ɂȂ肻���ł����A����A99% �}�b�`�� 0% �}�b�`�ō�Ɨʂ��������ƕ������A�����Ƃ͌����Ȃ��悤�ȋC�����Ă��܂��B
���r���[�����̃}�b�`���ł̊������āA��ʓI�Ȃ�ł��傤���B������������A���r���[�̂Ƃ��͊�������Ȃ��Ƃ��A��������Ƃ��Ă��|��̂Ƃ��Ƃ͗����Ⴄ�Ƃ��A����ȉ�Ђ������ł��傤���B�|���Ђւ̔��_�Ɏg����ޗ��݂����Ȃ��̂���������A���Ђ��Ђ��������������B
| �@�@ |
Tweet