


upLIFT �e�N�m���W�[�ɂ��Ă͈ȑO�ɉ��Ƃ肠���܂��� (�O���A���) ���A���̂Ƃ��͂܂��悭�킩���Ă��Ȃ����Ƃ��������̂ŁA�A�b�v�f�[�g���ꂽ�@�\�Ȃǂ��܂߂ĉ��߂Ă܂Ƃ߂Ă݂����Ǝv���܂��B�������A�o�[�W������ 2017 ��O��Ƃ��܂� (���݂܂���A�����܂� 2017 ���g���Ă���̂�)�B
upLIFT �e�N�m���W�[�ɂ��Ă� SDL ����̏��Ƃ��ẮA�ȉ��̃u���O�ɍŋ߂̏��܂Ƃ߂��Ă��܂��B�Q�l�ɂ��Ă��������B
SDL Trados Blog: �n�E�c�[�K�C�h
Trados Studio 2019 – �i���������{�ꌴ���̉��
���{�ꌴ���̏ꍇ�� SDL Trados Studio 2017 SR1 CU15 ���K�v
�܂��́A�o�[�W�����ł��B�p�� (�Ȃǂ̃��[���b�p����) �������̏ꍇ�� 2017 �̏����o�[�W�������� upLIFT ���g�����悤�ł����A���{�� (�Ȃǂ̃A�W�A����) �������̏ꍇ�� SR1 ���K�v�ł��B����ɁA������ SR1 �ɂ͕������̃J�E���g�ɕs� (?) ������A�����܂���v�̃J�E���g���傫����������ʂɂȂ�悤�Ȃ̂ŁACU15 ���K�v�ł��B
���{�ꌴ���̏ꍇ�́A�����̒P�ʂ��u�P��v�ł͂Ȃ��u�����v�ł��邱�Ƃ������̂ŁA�������̃J�E���g���@�͂��Ȃ�d�v�ł��BCU15 ���O�̂Ƃ��́A�����܂���v�̃J�E���g���|��҂ɂƂ��Ă��Ȃ�s���Ȋ����ɂȂ��Ă��܂����B��L�̃u���O�ɂ��ƁACU15 �ł��̕s��v�͉������ꂽ�悤�ł��B(���A���݂܂���A�{���ɉ������ꂽ�̂������͌����Ă��܂���B�ꉞ�A�M���邯�ǁA�ǂ��Ȃ̂��Ȃ��B)
�������A�ŐV�� CU ��K�p���Ă͂����Ȃ�
���������� �NjL 2019/12/26 ����������������������������������
�ȉ��̖��́A2017 �ł���������܂����B
SDL Trados Studio 2017 SR1 CU18 (Build 14.1.10018.54792) �ɍX�V����A��肪�������Ȃ��Ȃ�Ǝv���܂��B���́A��肪�������Ă����p�b�P�[�W�� 2 �����Ă݂܂������A2 �Ƃ������ɊJ�����Ƃ��ł��܂����B
���Ȃ荢���Ă����̂ŁA�������ăz���g�ɗǂ������ł��B
������������������������������������������������������������
CU15 �͕K�v�Ȃ̂ł����A�ŐV�� CU ��K�p����ƁA�O��̋L���ɏ������p�b�P�[�W���J���Ȃ��Ƃ�����肪�������܂��B���̖��̓t�@�C�����ȂǂɑS�p�������܂܂�Ă���ꍇ�ɔ������܂����A���{�ꌴ���̂Ƃ��̓t�@�C���������{��ł��邱�Ƃ������̂ŗv���ӂł��B
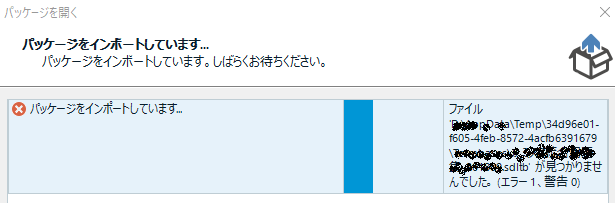
��L�̃u���O�ŕK�v�Ƃ���Ă���r���h:�@�@�@�@�@�@14.1.10015.44945
�R�~���j�e�B�Ŗ�肪��������Ƃ���Ă���r���h:�@14.1.10016.54660
�����ɈႢ�܂��BSDL �̃T�C�g����_�E�����[�h�ł���ŐV�̃t�@�C���́ASDL Trados Studio 2017 SR1 CU15 (SDLTradosStudio2017_SR1_44945.exe) �ł��B�Ȃ̂ŁA������C���X�g�[�����āA��͍X�V���Ȃ��A�Ƃ����̂��x�X�g���Ǝv���܂��B(���݂܂���A��������ۂɂ���Ă݂��킯�ł͂���܂���B)
[�A�W�A����̌����e�L�X�g�̏ꍇ�ɒP��P�ʂ̃g�[�N�������g�p����] �͍�Ǝ��̓���ɉe�����Ȃ�
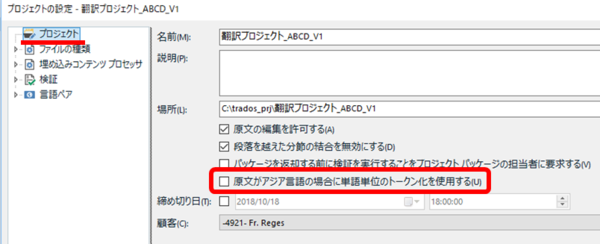
�v���W�F�N�g�̐ݒ�ɂ���I�v�V�����ł��B����́A��ɂ��������悤�ɁA�������̃J�E���g��P��x�[�X�ł͂Ȃ������x�[�X�ōs�����߂Ɂu�P��P�ʂ̃g�[�N�������g�p���Ȃ��v�ɂ��Ă����K�v������܂��B���̐ݒ�ɂ��Ď����s���Ɏv���Ă����̂́A�u�g�p���Ȃ��v�ɂ���Ɩ|���Ǝ��� upLIFT �̓���ɉe������̂ł͂Ȃ����H�Ƃ����_�ł����B����͉e�����Ȃ������ł��B���̐ݒ�́A�������̃J�E���g�ɉe�����邾���ŁA���ۂɖ|���Ƃ����Ă���Ƃ��̓���ɂ͉e�����܂���B�܂�A���̐ݒ�Łu�P��P�ʂ̃g�[�N�������g�p���Ȃ��v���Ƃɂ��Ă��Ă��A��Ǝ��� upLIFT �������Ǝg���܂��B
�f�t�H���g�Łu�g�p���Ȃ��v�ݒ�ɂȂ��Ă���Ǝv���܂����A�����J�E���g��������́A�ǂ������S���Ă��̂܂܁u�g�p���Ȃ��v�ɂ��Ă����Ă��������B���肢���܂��B
���������� �NjL 2020/03/31 ����������������������������������
���낢�덬�����Ă���܂������A������̐V�����L�� �u�P��P�ʂ̃g�[�N�����v�͒P�ꐔ�𐔂��邾�� ���������������B
���������A��L�̋L�q�̂Ƃ���ł����A
�E�������ł͂Ȃ��A�P�ꐔ�̃J�E���g�̂��߂̐ݒ�ł���
�E�|���Ǝ��Ɏg���K�v�͂Ȃ��̂ŁA�f�t�H���g�̂܂܃I�t�ɂ��Ă����悢
�Ƃ������ƂɂȂ�܂��B���̐ݒ�̃I���E�I�t�ɂ��|���Ǝ��̓�����͌��ʂ��ς��܂����A���̐ݒ�͂����܂ŒP�ꐔ�𐔂��邽�߂̂��̂Ȃ̂ŁA���i�̓I���ɂ���K�v�͂���܂���B�I�t�ɂ����܂܂ł� upLIFT �͗L���ł����A�P���t���[�Y�P�ʂł̃}�b�`�������ƌ������Ă��܂��B
������������������������������������������������������������
�������̃A�b�v�O���[�h�� 1 ���ł͂Ȃ�
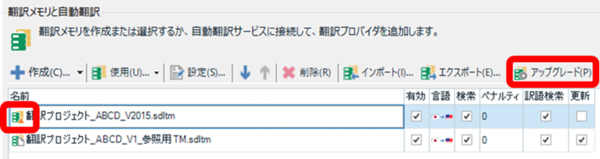
upLIFT �e�N�m���W�[����������Ă���A���ʂ̃o�[�W�����ō�����������̓A�b�v�O���[�h���Ďg�����ƂɂȂ��Ă��܂��B�ŏ��Ƀv���W�F�N�g���J�����Ƃ��ɁA�ݒ��ʂ�G�f�B�^�ȂǁA���낢��ȂƂ���Ɍx�����o�Ă��܂��B���̃A�b�v�O���[�h�ł����A1 ����s�����炻��ŏI���ł͂���܂���B������x����������������A�ēx�A�b�v�O���[�h������K�v������܂��B�܂��A2017 SR1 CU15 �ȍ~�ŐV�K�쐬�����������ł��A������x�܂ŗʂ�������ƃA�b�v�O���[�h���K�v�ɂȂ�܂��B
���́A������x�����\������Ă��Ă��Ȃ�ł�܂������A���ꂪ����ȓ���̂悤�ł��B�x�����\�����ꂽ��f���ɃA�b�v�O���[�h���܂��傤 (���Ȃ�ʓ|�ł���)�B
[TU �̃t���O�����g] ��L���ɂ���
�v���W�F�N�g�̐ݒ�ɂ��� [TU �̃t���O�����g] �`�F�b�N�{�b�N�X���I���ɂ��܂��B����̓f�t�H���g�ł̓I�t�ł����A�I���ɂ���������v������������̂ŁA���́A����A�I���ɕύX���Ă��܂��B
�v���W�F�N�g�̐ݒ�: [����y�A] > [�|�����Ǝ����|��] > [����] > [upLIFT �p�̃t���O�����g��v�̃I�v�V����]
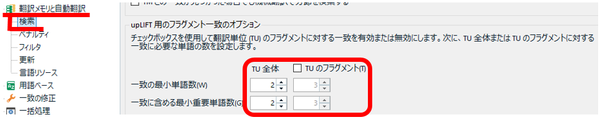
�P�ꐔ�́A�ȑO�̃Z�~�i�[�� SDL ���u2�v�𐄏����Ă����̂ŁA���̂悤�ɐݒ肵�Ă��܂��B�����A�������̓��e�ɂ���Ă͈�v�������Ȃ肷���邱�Ƃ�����܂��B���̏ꍇ�́u3�v�ɂ���ƈ�v�����Ȃ��Ȃ�܂��B
�ڂ����́A�ȑO�̋L�����Q�Ƃ��Ă��������B
���삪�x���Ƃ��� [��v�̏C��] ���ɂ���
upLIFT ����������Ă���A�������̌����Ȃǂ̓��삪���Ȃ�x���Ȃ��đς����Ȃ��Ƃ������Ƃ����т��т���܂��B����ȂƂ��́A�G�f�B�^��ł� [Match Repair �̎g�p] ���ɂ���Ɖ��P���邱�Ƃ������Ǝv���܂��B�G�f�B�^�ƈꊇ�^�X�N���ꂼ��ɂ��Đݒ�ł��܂����A�f�t�H���g�ŃG�f�B�^�̂ݗL���ɂȂ��Ă��܂��B
�v���W�F�N�g�̐ݒ�: [����y�A] > [��v�̏C��] > [Match Repair �̎g�p]
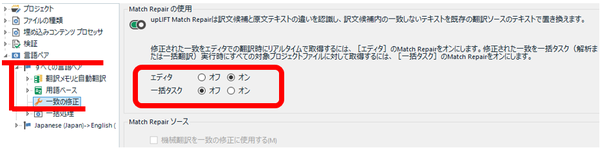
���̋@�\�� SDL ����̐����ł͕K���Љ��܂����A���l�̊��z�Ƃ��ẮA����قǖ𗧂��܂���B�����ɂ��ē��삪�����Ȃ�Ȃ�A���̕��������Ǝv���Ă��܂��B
����ɂ��Ă��A�ڂ����́A�ȑO�̋L�����Q�Ƃ��Ă��������B
����́A�ȏ�ł��B���ɐV�������͂Ȃ��̂ł����A�O����p�b�P�[�W���J���Ȃ��Ƃ�����肪 2017 �őΉ�����Ȃ������ǂ����Ă����߂��ꂸ�A�A�A �����������Ă݂܂����B
| �@�@ |
�^�O�F������ �J�E���g 2017 SR1 CU15 �t���O�����g��v Match Repair �̎g�p upLIFT �e�N�m���W�[ TU �̃t���O�����g ��v�̏C�� �������A�W�A����̏ꍇ�ɒP��P�ʂ̃g�[�N�������g�p���� �����܂���v�̎����C�� ������ �A�b�v�O���[�h �p�b�P�[�W���J���Ȃ� �P��P�ʂ̃g�[�N����
Tweet