


UI �̃f�[�^�́A�����Ă��A��ʏ�̗v�f 1 �ɂ����R�[�h�� 1 �s���݂���`�ɂȂ��Ă��܂��B���Ƃ��u�\���v�Ƃ����{�^���� 10 ��ʂɑ��݂��Ă��č��v�� 10 ����Ƃ���ƁA�f�[�^��ł́u�\���v�Ƃ������R�[�h�� 10 �s���݂��邱�ƂɂȂ�܂��B���������`���̃f�[�^�����̂܂ܗp��x�[�X�ɂ��Ă��܂��ƁATrados �̗p��F���E�B���h�E������Ȋ����ɂȂ�܂��B
�@�@�@�@
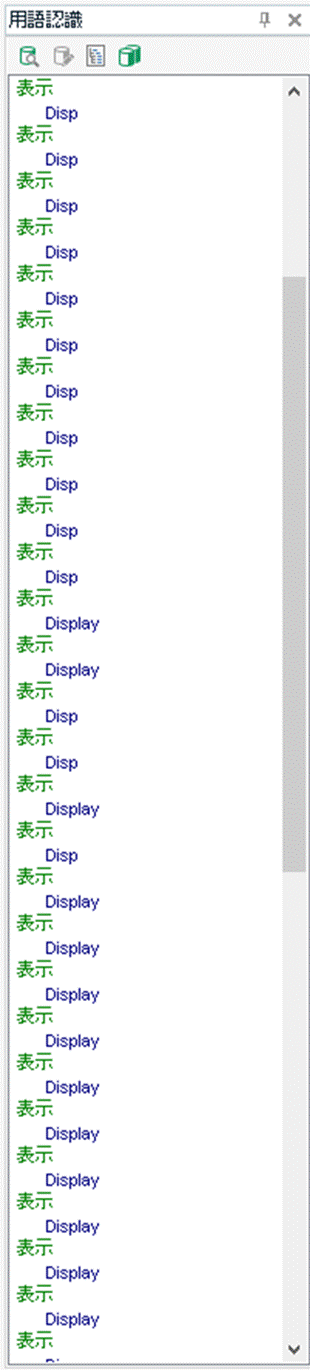
���������Ȃ�Ɨp��F���̈Ӗ�������܂���B�������ATrados �̗p��F���@�\�́A�p��x�[�X���傫���ꍇ�A���ׂĂ̗p����������Ă���܂���B����̋L���ł́A����ȕ��ɂȂ��Ă��܂� 34 ����̗p��x�[�X���ǂ������������O�`�肽���A����Ȃ��Đ����������Ǝv���܂��B����A�����s�����̂́A�ȉ��� 3 �ł��B
�@1. �d������p����폜����
�@2. �p��x�[�X�̌����ݒ������
�@3. Xbench ���g���Ď蓮�Ō�������
�ŏ����猾���Ă����܂����A�Ō�́u�蓮�Ō����v���܂����BXbench ���g�������A�N�V�����ł����A����ł������̗p��ł��̃����A�N�V�������K�v�ł����B
1. �d������p����폜����
UI �̃f�[�^�����̂܂ܗp��x�[�X�ɂ��Ă���|���Ђ���͑����̂ŁA�d�����폜���鏈���͂悭�K�v�ɂȂ�܂��B�����A����͂��܂�ɂ��ʂ������A���̍폜����ςł����B�����d�����폜������@�Ƃ��Ďv���t���̂́A�ȉ��� 3 ���炢�ł��B
�@(1) Glossary Converter �Ń}�[�W����
�@(2) Excel �������g��
�@(3) Excel �� [�d���̍폜] ���g�� (�啶������������ʂł��Ȃ�)
(1) Glossary Converter �Ń}�[�W����
�p��x�[�X �t�@�C�� (.sdltb) �� Glossary Converter �ŏ������܂��B���ꂪ�ł��ȒP�ŕ֗����Ǝv���܂��B�啶������������ʂł��܂��BGlossary Converter �́ASDL AppStore ���疳���Ń_�E�����[�h�ł���A�v���ł��B������@�ɂ��ẮA�ȑO�̋L���u�y��ҁz�}�C�N���\�t�g�̗p��W���g�������v���Q�Ƃ��Ă��������B
Glossary Converter ���N������ [settings] ���N���b�N����Ɛݒ��ʂ��\������܂��B[Merging] �^�u�� [Merge Files] �`�F�b�N�{�b�N�X���I���ɂ���ƁA�d������p����}�[�W�ł��܂��B����͓��{�ꌴ���������̂ŁA�p��W�̓��{��̃t�B�[���h��ݒ肵�ă}�[�W���Ă݂܂����B
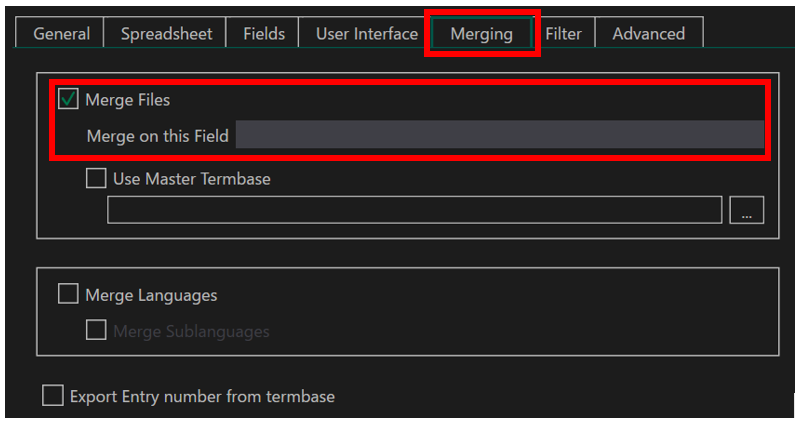
�ŁA���ʂ͂Ƃ����ƁA���߂ł����B�����́A�������s���B���������̂ł����A����r���ŃG���[�ɂȂ��Ă��܂��܂����B�Ƃ������ƂŁAGlossary Converter �͒��߂� Excel �ŏ������邱�Ƃɂ��܂����B
(2) Excel �������g��
Excel �ŏ�������ɂ́A���R�Ȃ��� Excel �t�@�C�����K�v�ł��B����́A�|���Ђ���p��x�[�X �t�@�C�� (.sdltb) �����łȂ��AExcel �t�@�C��������Ă����̂ł�����g���܂����B�����AExcel �t�@�C��������Ă��Ȃ��ꍇ�́AGlossary Converter ���g���ėp��x�[�X�� Excel �t�@�C���ɕϊ����܂��B
Excel �ɂ� [�d���̍폜] �Ƃ����@�\������A���͂�����g���Ώd�����Ă���f�[�^���ȒP�ɍ폜�ł��܂� (��q���܂�)�B�������A���̋@�\�͑啶������������ʂ��܂���B����̗p��x�[�X�� UI �ł���A��o�ł͑啶������������ʂ���K�v���������̂ŁA[�d���̍폜] �ł͂Ȃ��A�啶������������ʂł�����@���Ɏ����܂����B
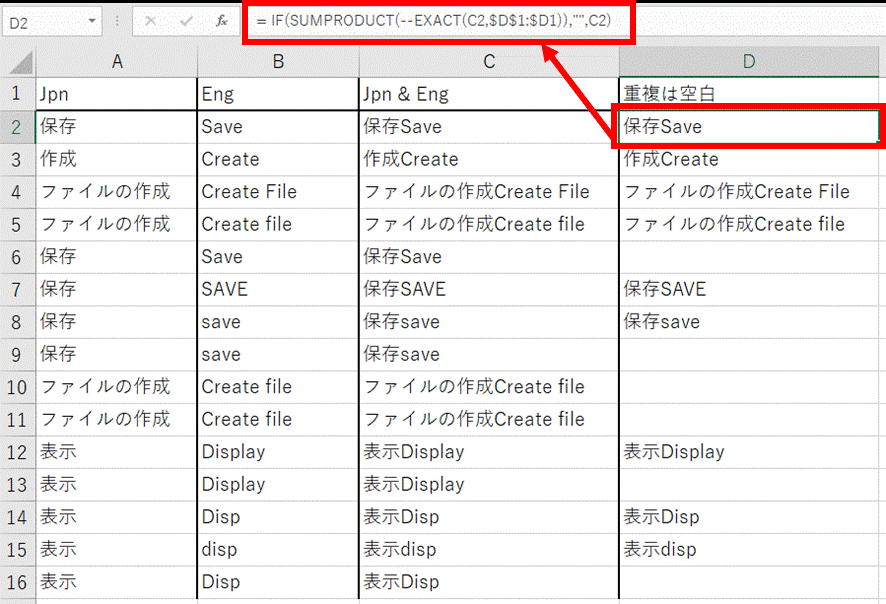
�@A ��: ���{��
�@B ��: �p��
�@C ��: ���{��Ɖp�����������
�@�@�@�@���� = A2&B2
�@D ��: ���{��Ɖp��̗����Ƃ������p�ꂪ���ɂ���ꍇ�͋ɂ���
�@�@�@�@���� = IF(SUMPRODUCT(--EXACT(C2,$D$1:$D1)),"",C2)
D ��̐������ȒP�ɐ�������ƁAEXACT �ő啶�����������܂߂Ĉ�v���Ă��邩���`�F�b�N���ASUMPRODUCT ���g�����v�Z�� D ��Ɋ��ɑ��݂��Ă��Ȃ������`�F�b�N���Ă��܂��B
�����Ă��̗p��W�͂���ŏ����ł���̂ł����A����͂��̕��@�����߂ł����BSUMPRODUCT �� D ��S�̂��`�F�b�N���邱�ƂɂȂ�̂ŁA34 ���s�͑��������悤�ł��B��������͂�����A����Ɍ��ʂ��߂炸�A�J�[�\�����O���O���Ɖ�����܂܂ł����B���炭�҂��Ă��܂��������������������̂ŁA��������߂܂����B(�C���ɑ҂��Ă�������������琬�������̂�������Ȃ��ł����A�҂�����܂���ł����B)
(3) Excel �� [�d���̍폜] ���g��
�d�����Ȃ��̂ŁA�啶���������̋�ʂ͒��߂āA[�d���̍폜] ���g���܂����B�������ɂ���͐������܂����B�ŁA�d�����폜������̌ꐔ�͂Ƃ����ƁA�� 15 ����ł����B���Ȃ茸��܂����I

Excel �ŏd�����폜������A���� Excel �t�@�C����p��x�[�X �t�@�C���ɕϊ����A�v���W�F�N�g�ɐݒ肵����A����Ȋ����ł����B�����Ԃ������肵�܂����B
�@�@�@

2. �p��x�[�X�̌����ݒ������
�ł��A����ň��S�͂ł��܂���B�d�����폜���Ă��A�܂� 15 ����ł�����B���́A��Ƃ����Ă��邤���ɁA�p��x�[�X�ɑ��݂���̂ɗp��F������Ă��Ȃ����̂����邱�ƂɋC�t���܂����B�����ŁA�p��x�[�X�̌����ݒ�������������܂����B
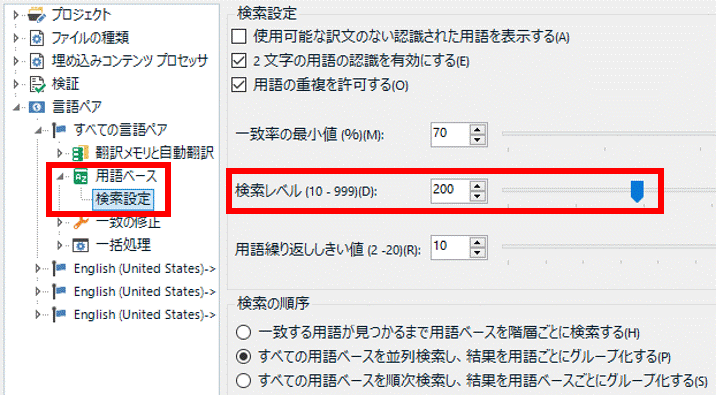
[�v���W�F�N�g�̐ݒ�] > [����y�A] > [���ׂĂ̌���y�A] > [�p��x�[�X] > [�����ݒ�] �ƑI������Ə�}�̉�ʂ��\������܂��B���̉�ʂŗp��x�[�X�̌������@�����낢��Ɛݒ�ł��܂��B���̉�ʂ̐ݒ�ɂ��ẮA�ȑO�̋L���u�p��x�[�X�̐ݒ��v���Q�l�ɂ��Ă��������B
�p�ꂪ�F������Ă��Ȃ������́A�����炭 [�������x��] �ł��B�u���x���v�Ƃ����̂����ۂɉ����Ӗ����Ă���̂��͕s���ł����A������傫�����������F�������p��͑����Ȃ�܂��B�����A���ׂĂ̗p�ꂪ�F������Ă���Ƃ͂����Ȃ��悤�ł��B
�ꉞ�A�w���v�͈ȉ��̂悤�ɂȂ��Ă��܂����A�u���K�́v��u��K�́v����̓I�ɂǂꂭ�炢�̌ꐔ���w���̂��͂킩��܂���B����́A����l�� 200 �� 500 �ɕύX���č�Ƃ��܂��� (�������x�́A���ɋC�ɂȂ�܂���ł���)�B�����A���܂�ɗp�ꂪ�����̂� [�p��̏d����������] �̓I�t�ɂ��܂����B

���낢���J�����̂ł����A���ǁA�p��F���ŕK�����ׂĂ̗p���F������͖̂����Ȃ̂��Ȃ��A�Ǝv���Ă��܂��B[�������x��] �� 500 �ɂ��Ă��A�F������Ă��Ȃ��p��͂���܂����B�ő�l�� 999 �ł����A�w���v�̕��ʂ��炷��ƁA�ő�l�ɐݒ肵������Ƃ����Ă��ׂČ��������Ƃ������Ƃł͂Ȃ������ȋC�����܂��B
3. Xbench ���g���Ď蓮�Ō�������
�Ō�̎�i�́AXbench �ł̌����ł��B���i����A�p��F�������ɗ��炸�AXbench �ł̌����p����悤�ɂ͂��Ă��܂����A����͂����܂ŔO�̂��߂ł��B����́A�p��F���E�B���h�E�͂����ς������A�啶������������ʂ����ɏd�����폜���Ă��܂��Ă��邵�A[�������x��] �̉e���ŔF������Ă��Ȃ��p������肻�������A�Ƃ������Ƃ� Xbench �ł̌����������Ȃ�܂����B
Xbench �Ō��������邽�߂ɂ́AMultiTerm ���g���ėp��x�[�X���� xml �t�@�C�����G�N�X�|�[�g���āA����� Xbench �ɐݒ肷��Ƃ������@���x�X�g���Ǝv���Ă��܂��B���̕ӂ�̏ڍׂ́A�܂�������A�Ƃ������Ƃɂ������Ǝv���܂��B
����́A�ȏ�ł��B34 ����͂ƂĂ�����܂����B�����Ő����������@�́A�����܂Łu�p��W�ɑ��݂��邱�Ƃ�F������v�܂ł̕��@�ł��B���ۂɂ́A�p��W�ɑ��݂���Ȃ猳�� Excel �t�@�C�����Q�Ƃ��Ă݂���A�����̑I����������Ȃ�O����Q�Ƃ��Ă݂���A�Ƃ܂��܂���Ƃ͑����܂��B�p��W�����������A�K�ʈȏ�ɂ��������Ă��|��҂Ƃ��Ă͎�Ԃ������邾���A�Ƃ������Ƃ������������Ē����L���ɂ��Ă݂܂����B�Ō�܂ł��ǂ݂�������A���肪�Ƃ��������܂����B
| �@�@ |