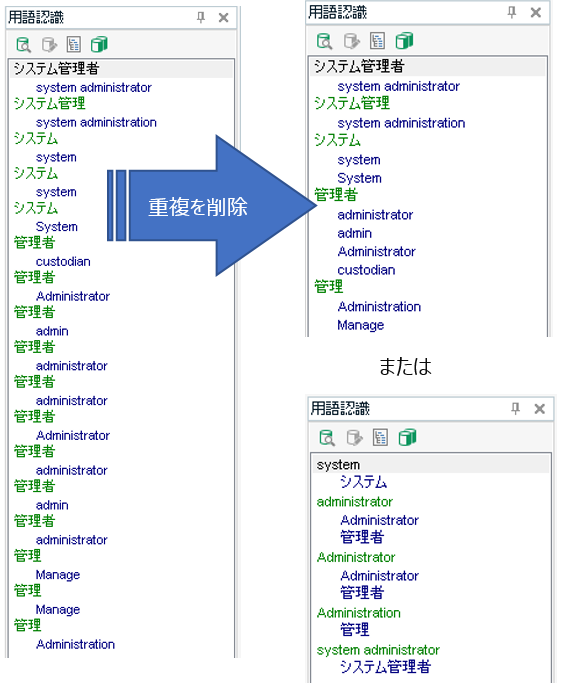
�O���Ɉ��������A�}�C�N���\�t�g�̗p��W�� Trados �Ŏg����悤�ɕϊ�������@��������܂��B������̓I�Ȏ菇��������܂����AGlossary Converter �̎g�����ɏڂ������͑O�҂̊T�v�����ł��������킩���Ē����邩�Ǝv���̂œǂݔ���Ă��������B
��������菇�́A�O�҂Ő��������Ƃ���A����Ȋ����ł��B
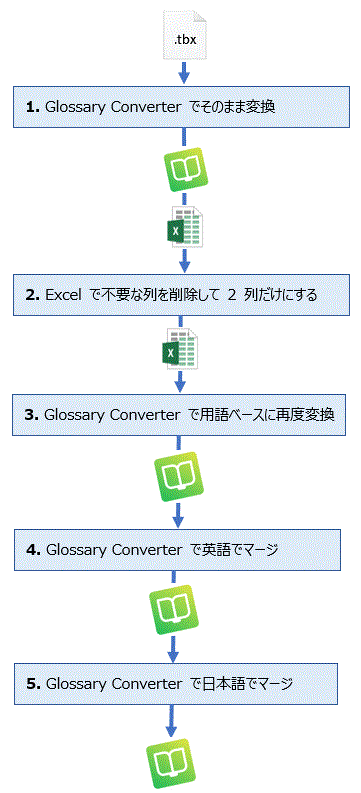
1. �}�C�N���\�t�g�̗p��W�t�@�C�� (tbx) ��p��x�[�X (sdltb) �ɕϊ����A����ɂ���� Excel �t�@�C�� (xlsx) �ɕϊ�����B
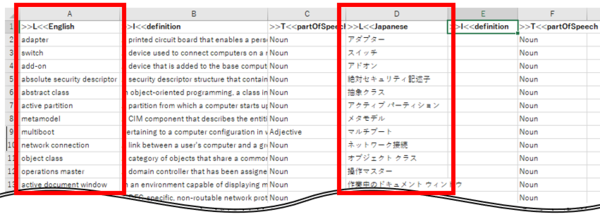
2. Excel �ŁA��`�Ȃǂ̕s�v�ȗ���폜���ĉp��Ɠ��{��� 2 ���ɂ���B
3. 2 ���ɂ��� Excel �t�@�C�� (xlsx) ��p��x�[�X (sdltb) �ɍēx�ϊ�����B
4. �o�͂��ꂽ�p��x�[�X (sdltb) ���A�p��Ń}�[�W����B
5. �}�[�W�����p��x�[�X (sdltb) ���A����ɓ��{��Ń}�[�W����B
�@�@
�܂��AGlossary Converter �̂���
�܂��AGlossary Converter �̃X�e�b�v�S�̂ɋ��ʂ���_��������܂��B
�� [settings] �Őݒ肵�Ă���A�h���b�O �A���h �h���b�v����Glossary Converter �̊�{�I�Ȏg�����́A�ȉ��̂Ƃ���ł��B
- [settings] �Őݒ肷��
- �ϊ����̃t�@�C�����h���b�O �A���h �h���b�v����
- �ϊ����̃t�@�C���Ɠ����t�H���_�[�ɕϊ���̃t�@�C�������������
�ǂ�ȃt�@�C����ϊ�����Ƃ����A���̎菇�͕ς��܂���B�����āAGlossary Converter �́A��x�s�����ݒ���o���Ă��܂��B�����ϊ������������Ƃ��͐ݒ���o���Ă��Ă����@�\���֗��ł����A����͂��낢��ȕϊ�������̂ŁA�e�X�e�b�v�ŁA�ݒ��ς��Ă���t�@�C�����h���b�O �A���h �h���b�v���܂��B
�Ȃ��A�h���b�O �A���h �h���b�v�ł��Ȃ��Ƃ��́AAlt+O �Ńt�@�C���I���̃_�C�A���O�{�b�N�X���\�������̂ŁA�t�@�C�����w�肵�ĕϊ����J�n���܂��B
�� ���Ԃ��������}�C�N���\�t�g�̗p��W�͂ƂĂ��傫���̂ŁA�ϊ��ɂ��̂��������Ԃ�������܂��B�~�܂��Ă����Ȃ����ƐS�z�ɂȂ�܂����A�X�e�[�^�X�o�[�����Ȃ���A�C���ɁA�C���ɁA���҂����������B
1. �}�C�N���\�t�g�̗p��W�t�@�C����p��x�[�X�ɕϊ��A����� Excel �t�@�C���ɕϊ�
tbx �`���̗p��W�t�@�C���͂��̂܂܂ł͕ҏW���ɂ����̂ŁA�Ȃ�Ƃ� Excel �ŕҏW�ł���`�ɂ��܂��Btbx �t�@�C���� Excel �ŊJ�����Ƃ��ł��܂����AXML �̒m�����Ȃ��ƕҏW���₷���`�ɂ���͓̂�����߁A�����
�@ tbx �t�@�C���� Trados �̗p��x�[�X�ɕϊ��A
�A �p��x�[�X�� Excel �t�@�C���ɕϊ��Ƃ��� 2 �i�K�̕��@�����܂��B2 �i�K�͂�����Ǝ�Ԃł����A���̕��@�Ȃ畡�G�Ȃ��Ƃ������ōl���Ȃ��Ă� Glossary Converter ���K���ɕϊ����Ă���܂��B
�@ tbx �t�@�C����p��x�[�X�ɕϊ��E�ݒ�
�ŏ��́A�ݒ�s�v�ł��B
�E�ϊ�
tbx �t�@�C�����h���b�O �A���h �h���b�v���܂��B���ꂾ���ŁATrados �̗p��x�[�X (sdltb) ����������܂��B
�A �p��x�[�X�� Excel �t�@�C���ɕϊ��E�ݒ�
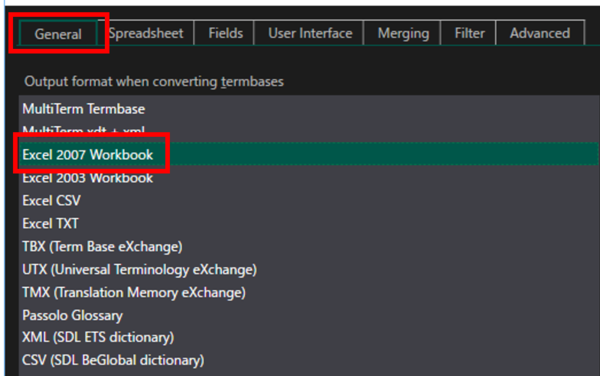
���x�́A[
settings] �ŏ����ݒ��ς��܂��B[
General] �^�u�ŁA�u
Excel 2007 Workbook�v���I������Ă��邱�Ƃ��m�F���܂� (�f�t�H���g�őI������Ă���͂�)�B
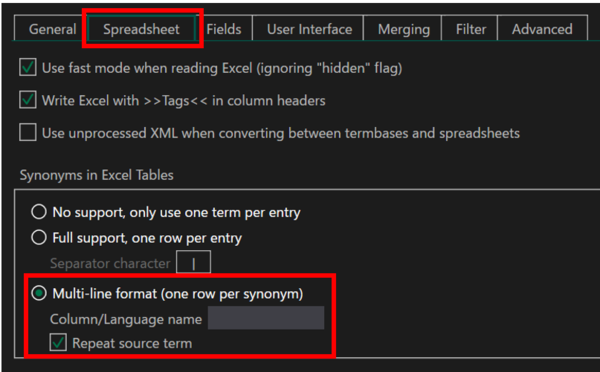
[
Spreadsheet] �^�u�ŁA�u
Multi-line format (one row per synonym)�v��I�����܂��B����ɁA[
Repeat source term] �`�F�b�N�{�b�N�X���I���ɂ��܂��B����ŁA�����̖�ꂪ����ꍇ�ɂ��ꂼ�ꂪ�ʃ��R�[�h�Ƃ��ĕ����̍s����������A�e�s�Ɍ��ꂪ���͂���܂��B[
Column/Language name] �́A����͋ő��v�ł��B�ɂ��Ă����ƁA�ŏ��̗���Ƃ��Ďg���܂��B
�E�ϊ�
�ݒ肪�ł�����A�p��x�[�X (sdltb) ���h���b�O �A���h �h���b�v���܂��B����ŁAExcel �t�@�C������������܂��B
2. Excel �ŁA��`�Ȃǂ̕s�v�ȗ���폜
�������ꂽ Excel �t�@�C�����J���āA��`�Ȃǂ̕s�v�ȗ���폜���A�p��Ɠ��{��� 2 ���ɂ��܂��B
3. Excel �t�@�C����p��x�[�X�ɍēx�ϊ�����
�p��Ɠ��{��� 2 ���ɂ��� Excel �t�@�C�����A�p��x�[�X (sdltb) �̌`�ɖ߂��܂��B
�E�ݒ�
���̃X�e�b�v�ł͕s�v�ł��B
�E�ϊ�
Excel �t�@�C�����h���b�O �A���h �h���b�v���܂��B����ŁA�p��x�[�X (sdltb) ����������܂��B
4. �o�͂��ꂽ�p��x�[�X���A�p��Ń}�[�W
���̎��_�̗p��x�[�X (sdltb) �́A�܂������̖�ꂪ�ʃ��R�[�h�Ƃ��Ďc���Ă����ԂȂ̂ŁA�܂��p��Ń}�[�W���ďd����������폜���܂��B�p���܂��͓��p�̂ǂ��炩����������Ŏg���Ƃ��́A���̕����� 1 ���}�[�W����Α��v�ł��B
�E�ݒ�
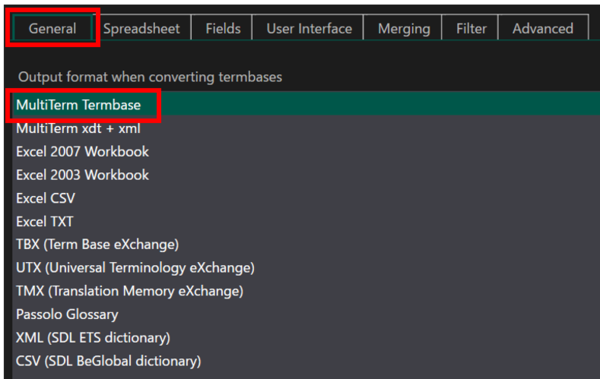
[
General] �^�u�ŁA�u
MultiTerm Termbase�v��I�����܂��B����ŁA�p��x�[�X (sdltb) ��p��x�[�X (sdltb) �ɕϊ�����A�Ƃ����ݒ�ɂȂ�܂��B
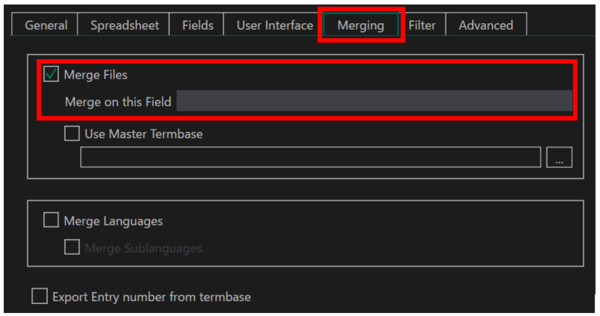
[
Merging] �^�u�ŁA[
Merge Files] �`�F�b�N�{�b�N�X���I���ɂ��܂��B[
Merge on this Field] �͋̂܂܂ɂ��܂��B�ɂ��Ă����ƁA�ϊ��������n�܂��Ă���v�����v�g���\�������̂ł����Őݒ肵�܂��B
�E�ϊ�
���}�̂悤�Ɂu
merge�v�ƕ\������Ă��邱�Ƃ��m�F���āA �p��x�[�X (sdltb) ���h���b�O �A���h �h���b�v���܂��B�}�[�W�̊�ɂ���t�B�[���h��q�˂�v�����v�g���\�������̂ŁA�p�� (English) ��I�����܂��B�ϊ����I���ƁA���̃t�@�C�����Ɂu.output�v��lj��������O�ŐV�����p��x�[�X����������܂��B
5. �p��x�[�X���A����ɓ��{��Ń}�[�W
�p��Ń}�[�W�����p��x�[�X������ɓ��{��Ń}�[�W���܂��B(������������A���̃X�e�b�v�͕s�v�Ȃ�Ȃ����Ƃ��v���̂ł����A�O�̂��߂��Ă����܂��B)
�E�ݒ�
[
General] �^�u�ŁA�u
MultiTerm Termbase�v���I������Ă��邱�Ƃ��m�F���܂��B�O�̃X�e�b�v�őI�������̂ŁA���̐ݒ肪���̂܂c���Ă���Ǝv���܂��B
[
Merging] �^�u�ŁA[
Merge Files] �`�F�b�N�{�b�N�X���I������Ă��邱�Ƃ��m�F���܂��B������A�O�̃X�e�b�v�őI�����Ă���̂ł��̂܂܃I���ɂȂ��Ă���͂��ł��B[
Merge on this Field] �́A�O�̃X�e�b�v�� �uEnglish�v ���c���Ă�����A�ɖ߂��܂��B
�E�ϊ�
�O�̃X�e�b�v�Ɠ����悤�Ɂu
merge�v�ƕ\������Ă��邱�Ƃ��m�F���āA �p��x�[�X (sdltb) ���h���b�O �A���h �h���b�v���܂��B�}�[�W�̊�ɂ���t�B�[���h��q�˂�v�����v�g���܂��\�������̂ŁA���x�͓��{�� (Japanese) ��I�����܂��B�ϊ����I���ƁA���̃t�@�C�����ɂ���Ɂu.output�v��lj��������O�ŐV�����p��x�[�X����������܂��B����ŁA�����ł��B
����Ń}�C�N���\�t�g�̗p��W�̏����͊����ł��B�X�e�b�v�������Ȃ��Ă��܂����A����̕��@�͎��s����̖��A�Ȃ�ׂ����S�ȕ��@�Ƃ��čl���܂����B������ł����A�}�[�W�@�\�͗p��x�[�X����p��x�[�X�ւ̕ϊ��łȂ��Ă��AExcel ����p��x�[�X�ւ̕ϊ��ł��g���܂��B�Ȃ̂ŁA�X�e�b�v 3 �� Excel ����p��x�[�X�ւ̕ϊ��͏ȗ����邱�Ƃ��\���Ǝv���܂��B���A���ۂɂ���Ă݂�ƁA�����ɂ��܂������܂���ł����B�d�����Ă�����̒��Ŕ����Ă��܂����̂��������肵�āA�Ȃ�ƂȂ��M�p�Ȃ�Ȃ������ł����B����������̂��A�Ȃ�������̂��Ȃǂ��l����̂�������Ɩʓ|�ɂȂ�A���X�X�e�b�v�͑����܂����A����̕��@�ɂ��܂����B
�܂��AExcel ���ԂɊ܂߂��̂ɂ́A���� 1 ���R������܂��BExcel �ł��낢��ׂ����ҏW�������������̂ł��B�}�C�N���\�t�g�̗p��W�̓}�C�N���\�t�g�̃X�^�C���K�C�h�ɏ]���Ă���̂ŁA�J�^�J�i�̘A��̊Ԃɂ̓X�y�[�X�������Ă��܂����A�S�p�����Ɣ��p�����̊Ԃɂ��X�y�[�X�������Ă��܂��B���ꂪ�A�ʉ�Ђ̖|��Ɏg���Ƃ��ɂ͂�����Ɩʓ|�Ȃ�ł��BExcel �t�@�C���ɂ��Ă��܂��A���̕ӂ���X�^�C���K�C�h�ɍ��킹�ĕҏW���邱�Ƃ��ł��܂��B������K�\�����g���� (�F����A�����ӂł���ˁH�H) ���낢����H���ł��܂��B
����́A���̗p��x�[�X�� Trados �̃G�f�B�^�Ŏg���Ƃ��ɋC��t����ݒ�Ȃǂ��Љ�����Ǝv���܂��B