Trados �ɂ��������֗��ȋ@�\�͂���܂��BQuickPlace (�uCtrl+Alt+�����v�Ń^�O�Ȃǂ���͂ł�����1)�AQuickInsert�AAutoText��2�A�p��W�ȂǂȂǁA���낢��ɉ����Ď����Ă݂͂��̂ł����A�ǂ���꒷��Z����A�Ȃ��Ȃ��x�X�g�ȕ��@��������܂���ł����B
����Ȓ��ōŋ߁A���{��ˉp��̖|��̂Ƃ��́ARegex Match AutoSuggest Provider �Ƃ����v���O�C�����ƂĂ��֗����Ɗ����Ă��܂��B���̃v���O�C���͂��Ȃ�ȑO���炠�����悤�ŁA�������ڂɂ͂��Ă����̂ł����A�u���K�\���v�Ƃ��������ł�����Ɩʓ|�����Ȉ�ۂ�����A�f�ʂ肵�Ă��܂����B
���̃v���O�C���� AutoSuggest��2 �̊g���@�\�ł��B���t�̌`����ϊ����� AutoSuggest �ɕ\������A�Ƃ��������Ƃ��ł���悤�ł����A���͂܂������܂Ŏg�����Ȃ����A�����ς�p�����̒P����R�s�[���邽�߂Ɏg���Ă��܂��B
���ꂾ���ł��ƂĂ��֗��Ȃ̂ŁA����͂��̕��@���Љ�����Ǝv���܂��B
Regex Match AutoSuggest Provider ���_�E�����[�h���ăC���X�g�[������ƁA[�\��] �^�u�� [Regex Match AutoSuggest Provider] ���\������܂��B������N���b�N����ƁA���L�̂悤�Ȑݒ��ʂ��\������܂��B

[Regex Entries] �^�u�ňȉ��̂悤�ɐݒ肵�܂��B
Enabled
�`�F�b�N���Ă����Ƃ��̐ݒ肪�L���ɂȂ�܂��B�`�F�b�N���܂��B
Description
�ݒ�̖��O�ł��B�����ɂ킩��Ή��ł������ł��B����́A�u�p�����v�Ƃ��܂����B
Regex Pattern
���K�\����ݒ肵�܂��B�p�������琬��P����������邽�߁A�u(\p{IsBasicLatin})+�v�Ƃ��Ă��܂��B
�uIsBasicLatin�v�́A���̖��O�̂Ƃ���A�u��{�I�ȃ��e�������v�Ƀq�b�g���܂��B�p�������łȂ��A�����A�A�s���I�h�A�n�C�t���Ȃǂɂ��q�b�g���܂��B
Replace Pattern
�q�b�g�������ʁA������͂���̂���ݒ肵�܂��B�u$0�v(�h���Ɛ����̃[��) �Ƃ���ƁA�u�q�b�g�������̑S�́v�����̂܂ܓ��͂ł��܂��B
�ݒ�͂���Ŋ����ł��B
�g�����́A�ʏ�� AutoSuggest �Ɠ����ł��B�^�C�s���O���J�n�����^�C�~���O�œ��͌�₪�\������܂��B
�܂��AAutoSuggest �Ƃ͕ʂɁACtrl+Shift+F12 �������Ă����͂ł��܂��B�ȉ��̂悤�Ƀ|�b�v�A�b�v�œ��͌�₪�\������܂��B1 ���������͂��Ȃ��Ă����̂ŁA���́uCtrl+Shift+F12�v�͂ƂĂ��֗��ł��B
�� �W���@�\�� QuickPlace (Ctrl+Alt+�����) �ŕ\���������͌��

�� Regex Match AutoSuggest Provider �́uCtrl+Shift+F12�v�ŕ\���������͌��

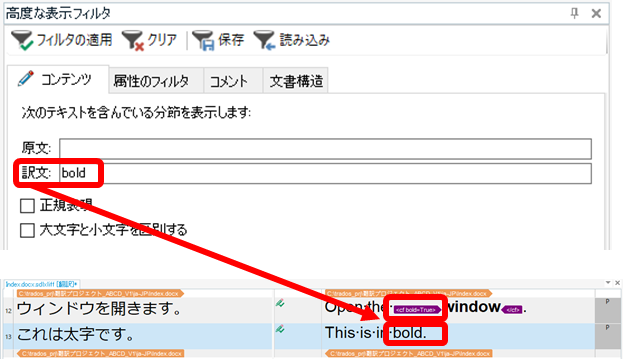
�u3.4.5-6�v�Ƃ����悤�ȃs���I�h��n�C�t���̓����������̏ꍇ�A QuickPlace (�uCtrl+Alt+�����v�œ��͂�����1) �ł́A��������������Ă��܂����͂��ɂ����̂ł����ARegex Match AutoSuggest Provider �ł́A�܂Ƃ߂� 1 �̌��Ƃ��ĕ\������܂��B
�uWindows 10�v�̂悤�ɋ������Ă��Ă� 1 �̌��Ƃ��ĕ\������܂��B�������ugetFile ()�v�̂悤�ȃL�������P�[�X����肠��܂���B
����Љ��ݒ�͈ȏ�ł��B1 �����ł����A���͂��Ȃ薞�����Ă��܂��I
���܂ł́A1 �� 1 �̒P��� AutoText ���p��W�ɓo�^���邱�Ƃ����������̂ł����A���{��ˉp��̏ꍇ�Ɍ����Ă݂�A���܂�o�^�����Ȃ��Ȃ�܂����B�����̒P����R�s�[����Ȃ� Regex Match AutoSuggest Provider�A�Ȃ�t���O�����g��v��3 �ŁA���Ƒ����v���W�F�N�g��������������܂��B
���āA�����ɂȂ��Ď������̃v���O�C�����C���X�g�[���������������́A�uIsBasicLatin�v���g�����ݒ�̐��������{��ŏ����Ă������̂����R�����������Ƃł����B�����A���݂܂���A���̃y�[�W���ǂ��ɂ������̂��킩��Ȃ��Ȃ��Ă��܂��܂����B�ȂA�����������Ȃ���ł���ˁB�ق��ɂ����낢�돑���Ă������C������̂����ǁA�ǂ��ɂ����Ă��܂����낤�B�c�O�ł��B
�uIsBasicLatin�v�ȊO���֗������Ȃ̂ŁA���Ԃ�����Ă����������낢��g���Ă݂����Ǝv���܂��B
���L�F
��1 �uQuickPlace�v�ʼnp�����Ȃǂ���͂���ɂ́A�������̐ݒ�Ŏ����F����L���ɂ��Ă����K�v������܂��B�����A���̐ݒ肪�Ȃ��Ȃ�����A���܂��ł��Ȃ����Ƃ�������ł�
��2 �uAutoText�v���܂ށuAutoSuggest�v�ׂ̍����ݒ�́A[�t�@�C��] > [�I�v�V����] > [AutoSuggest] ����s���܂��B��{�I�ɂ́AAutoSuggest �͓��{��ˉp��̖|��̂Ƃ��ɂ����֗��Ɏg���܂���B�p��˓��{��̂Ƃ��͓��͂��ɂ��������A�Ƃ�����ۂ�����܂��B(2017 ���炿����ƕς������������Ȃ��ł����A���̂Ƃ��뎄�͂��܂�g���Ă��܂���B)
��3 �u�t���O�����g��v�v�� SDL Trados 2017 ����̐V�@�\�ł� (���{��̏ꍇ�A���m�ɂ� SR1 ����̂悤�ł�)�B������A�悭�킩��Ȃ����Ƃ������A�܂��u�����Ă݂Ă���v��Ԃł����A��ۂƂ��ẮA���Ȃ�֗��I�ł��B�܂��A���̂����Љ�����Ǝv���܂��B
Tweet