


�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
�L��
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
posted by fanblog
2020�N06��15��
Google �̃e�N�j�J�� ���C�e�B���O �R�[�X
�ŋ߁AGoogle �̃e�N�j�J�� ���C�e�B���O �R�[�X���ǂ������Ƃ��낢��ȂƂ���ŏЉ��Ă����̂œǂ�ł݂܂����BGoogle �̃��C�e�B���O�ɂ��ẮA�ȑO�̋L�� ���J����Ă���X�^�C���K�C�h (���p�|�����) �ŃX�^�C���K�C�h�����グ�܂����B���̃X�^�C���K�C�h���R�[�X�̒��ŎQ�l�����Ƃ��ďЉ��Ă��܂��B
���� Technical Writing Courses �� 2 �̃R�[�X�ō\������Ă��܂��B
One ���e�N�j�J�� ���C�e�B���O���̂��ׂ̂̍��������ŁATwo �̓h�L�������g�S�̂ɂ��Ă�A�e�L�X�g�ȊO�̗v�f (�}��T���v���R�[�h) �ɂ��ĂȂǁA���C�e�B���O�̕⑫�����̂悤�Ȋ����ł��B
����̋L���ł́A���p�|��ɖ𗧂������Ȃ��ƂŁA�����m��Ȃ��������Ƃ𒆐S�ɂ��������ꕔ�������Љ�����Ǝv���܂��B���̃��C�e�B���O �R�[�X�ɂ͊�{�I�Ȃ��Ƃ��܂߂đ����̂��Ƃ�������Ă��܂��B�S�̂̓��e�ɂ��Ă̓R�[�X���̂� Summary (One�ATwo) ���Q�Ƃ��Ă��������B���R�Ȃ���A�ƂĂ��悭�܂Ƃ܂��Ă��܂��B
���{��ł́u���� (�t���X�y��)�v�Ɨ��ꂪ��ɂȂ��Ă��邱�Ƃ������ł��B���ꂪ�ǂꂭ�炢�Z�����Ă��邩�ɂ����܂����A���Ԃ�A���{���ǂސl�͉p��̃t���X�y�������܂�C�ɂ��Ȃ����炩�Ǝv���܂��B�܂��A���͂̒��ŗ��ꂪ���������炽�܂Ƀt���X�y���ɖ߂����A�Ƃ������C�����͕s�v�Ȃ悤�ł��B
�㖼���̎g�����ɂ��ẮAGoogle �̂��̃R�[�X�Ɍ��炸���낢��ȂƂ���Ő�������Ă���Ǝv���܂��B�㖼�����Ɏg��Ȃ��Ƃ������[���́A�ꏇ�̓���ւ�����������|��Ȃ�ł͂̒��ӓ_���Ǝv���Ă��܂������A�ŏ�����p��������l�����ӂ��K�v�Ȃ悤�ł��B�܂��A5 ��Ƃ�����͎��͏��߂Ēm��܂����B
�ӏ������̊e���ڂ́A������ł��啶���Ŏn�߂Ă��܂��Ă����悤�� (�P0�P)�@�s���I�h�́A�|��̏ꍇ�ł��A�����ɏ]���̂ł͂Ȃ��A���̃��[����K�p���邱�Ƃ������Ǝv���܂��B
�\����������ꍇ�A���ꂼ����e���Ⴄ�̂ɗ�̌��o���͂ǂ̕\�������Ƃ������Ƃ����X����܂��B���Ƃ��A���{��̌����ł́u���ځv��u���e�v�Ƃ��������o���������������C�����܂��B �ŁA���̉��ɕ������т�����ƕ���ł����肷��ƁA�����ǂދC���Ȃ��Ȃ�܂��B
�|��ł́A�����������Ȃ����肵�āA���̐����ς�邱�Ƃ��悭����܂��B���{��� 2 ���������̂ɁA�p���� 1 ���ɂȂ��Ă��܂����A�Ȃ�Ă��Ƃ͔���������������ł����ˁB�ǂ����낤�B�܂��A�Ȃ��邱�Ƃ͂��܂�Ȃ��̂ŁA�ׂ����肷���� 7 �����Ȃ����𒍈ӂ��������悳�����ł��B
�R�����g���Z�����ĈÍ��̂悤��������A�\�[�X�R�[�h�Ƃ܂�����������������A����Ȃ��Ƃ��悭����܂��B�܂��A�p��Ɠ����ɂȂ��Ă��܂��P�[�X��������ƍ���܂��B���Ƃ��A
�|��҂Ƃ��Ďg�����Ƃ͂��܂肠��܂��A���� Word �� Excel ����Ȃ̂ŁA���낢�뎎���Ă݂�̂��悳�����ł��B
���̃��C�e�B���O �R�[�X�͎�Ƀ\�t�g�E�F�A�J���Ҍ����Ȃ̂� IT ����̖|��ŕp�o����\������������܂����B�ᕶ���v���O���~���O�֘A�̂��̂������ł��B����Ȓ��Ŏ����C�ɂȂ����\���� 2 �����Љ�܂��B
�u�m���̎v�Ɩ�邱�Ƃ������ł��B�������悭�킩���Ă�����e�́A�킩��Ȃ��l�̋C�������킩�炸�A�Ԃ��Ă��܂������ł��Ȃ��A�Ƃ����Ƃ��Ɏg���錾�t�ł��B���́A�ŏ��Acurse �� course �ƌ��ԈႦ�Ă��܂��܂����Bcurse �Ȃ�� IT ����ł͂߂����ɓo�ꂵ�Ă��Ȃ��ł� (;�;)
code �͂����Ă��͖����ŁA�����ł��������Ƃ��Ďg���邱�Ƃ������Ǝv���܂��B�������ł́Aimplement �Ɠ������u�`����������v�Ƃ����Ӗ��̂悤�ł��B
����͈ȏ�ł��B�|��ł͌���������̂őS����K�p����̂͂Ȃ��Ȃ�����ł����A�p��l�C�e�B�u�łȂ��p��҂́A��������������Ɩ��̒ʂ����K�C�h���C����m���Ă����Ɖ����̂Ƃ��̔����Ƃ��Ă�����������Ȃ��ł��B�����ɂ��������Ă���܂�����āA�����̎咣�̍����Ɏg�������ł��B
 Tweet
Tweet
���� Technical Writing Courses �� 2 �̃R�[�X�ō\������Ă��܂��B
One ���e�N�j�J�� ���C�e�B���O���̂��ׂ̂̍��������ŁATwo �̓h�L�������g�S�̂ɂ��Ă�A�e�L�X�g�ȊO�̗v�f (�}��T���v���R�[�h) �ɂ��ĂȂǁA���C�e�B���O�̕⑫�����̂悤�Ȋ����ł��B
����̋L���ł́A���p�|��ɖ𗧂������Ȃ��ƂŁA�����m��Ȃ��������Ƃ𒆐S�ɂ��������ꕔ�������Љ�����Ǝv���܂��B���̃��C�e�B���O �R�[�X�ɂ͊�{�I�Ȃ��Ƃ��܂߂đ����̂��Ƃ�������Ă��܂��B�S�̂̓��e�ɂ��Ă̓R�[�X���̂� Summary (One�ATwo) ���Q�Ƃ��Ă��������B���R�Ȃ���A�ƂĂ��悭�܂Ƃ܂��Ă��܂��B
����@Acronyms
�@Technical Writing One > Words > Use acronyms properly- �t���X�y�����ɏ����A�u�t���X�y�� (����)�v�̌`�ɂ���B
- �t���X�y���Ɨ���������Ďg��Ȃ��B��x������g������A���̌�͂����Ɨ���ɂ���B
���{��ł́u���� (�t���X�y��)�v�Ɨ��ꂪ��ɂȂ��Ă��邱�Ƃ������ł��B���ꂪ�ǂꂭ�炢�Z�����Ă��邩�ɂ����܂����A���Ԃ�A���{���ǂސl�͉p��̃t���X�y�������܂�C�ɂ��Ȃ����炩�Ǝv���܂��B�܂��A���͂̒��ŗ��ꂪ���������炽�܂Ƀt���X�y���ɖ߂����A�Ƃ������C�����͕s�v�Ȃ悤�ł��B
�㖼���@Pronouns
�@Technical Writing One > Words > Disambiguate pronouns- �{���̖���������ɑ㖼�����g��Ȃ��B
- �{���̖����Ƃ̊Ԃ̌ꐔ�� 5 �����ꍇ�͑㖼�����g��Ȃ��B
�㖼���̎g�����ɂ��ẮAGoogle �̂��̃R�[�X�Ɍ��炸���낢��ȂƂ���Ő�������Ă���Ǝv���܂��B�㖼�����Ɏg��Ȃ��Ƃ������[���́A�ꏇ�̓���ւ�����������|��Ȃ�ł͂̒��ӓ_���Ǝv���Ă��܂������A�ŏ�����p��������l�����ӂ��K�v�Ȃ悤�ł��B�܂��A5 ��Ƃ�����͎��͏��߂Ēm��܂����B
�ӏ������@Lists
�@Technical Writing One > Lists and tables > Punctuate items appropriately- ���̂Ƃ��́A�啶���Ŏn�߁A�s���I�h��t����B
- �����łȂ��Ƃ��́A�������Ŏn�߁A�s���I�h�͕t���Ȃ��B
�ӏ������̊e���ڂ́A������ł��啶���Ŏn�߂Ă��܂��Ă����悤�� (�P0�P)�@�s���I�h�́A�|��̏ꍇ�ł��A�����ɏ]���̂ł͂Ȃ��A���̃��[����K�p���邱�Ƃ������Ǝv���܂��B
�\�@Tables
�@Technical Writing One > Lists and tables > Create useful tables- �e��ɁA�Ӗ��̂��錩�o����t����B
- �\�� 1 �}�X�ɂ́A2 ���܂ŁB�������ꍇ�́A�\�����l�������B
�\����������ꍇ�A���ꂼ����e���Ⴄ�̂ɗ�̌��o���͂ǂ̕\�������Ƃ������Ƃ����X����܂��B���Ƃ��A���{��̌����ł́u���ځv��u���e�v�Ƃ��������o���������������C�����܂��B �ŁA���̉��ɕ������т�����ƕ���ł����肷��ƁA�����ǂދC���Ȃ��Ȃ�܂��B
�i���@Paragraphs
�@Technical Writing One > Paragraphs > Don't make paragraphs too long or too short- 1 �i���́A�������Ă��Z�����Ă������Ȃ��B3 �` 5�����x�B7 �����邱�Ƃ͔�����B
- 1 ���݂̂̒i������������̂��悭�Ȃ��B
�|��ł́A�����������Ȃ����肵�āA���̐����ς�邱�Ƃ��悭����܂��B���{��� 2 ���������̂ɁA�p���� 1 ���ɂȂ��Ă��܂����A�Ȃ�Ă��Ƃ͔���������������ł����ˁB�ǂ����낤�B�܂��A�Ȃ��邱�Ƃ͂��܂�Ȃ��̂ŁA�ׂ����肷���� 7 �����Ȃ����𒍈ӂ��������悳�����ł��B
�\�[�X�R�[�h���̃R�����g�@Comments
�@Technical Writing Two > Creating sample code > Commented- �Z�������悢���A�Z�����A���m�����d������B
- �킩�肫���Ă��邱�Ƃ������Ȃ��B
�R�����g���Z�����ĈÍ��̂悤��������A�\�[�X�R�[�h�Ƃ܂�����������������A����Ȃ��Ƃ��悭����܂��B�܂��A�p��Ɠ����ɂȂ��Ă��܂��P�[�X��������ƍ���܂��B���Ƃ��A
Create �Ƃ������߂Ɂu�쐬�v�Ƃ����R�����g���t���Ă���ꍇ�A�p��̃R�����g��t���Ă��Ӗ����Ȃ��ł����A��҂̔��f�ŃR�����g�������킯�ɂ��������A�Y�܂����ł��B�������ߍ�}�c�[���@Illustration tools
�@Technical Writing Two > Illustrating > Illustration tools�|��҂Ƃ��Ďg�����Ƃ͂��܂肠��܂��A���� Word �� Excel ����Ȃ̂ŁA���낢�뎎���Ă݂�̂��悳�����ł��B
�C�ɂȂ����p��\��
���̃��C�e�B���O �R�[�X�͎�Ƀ\�t�g�E�F�A�J���Ҍ����Ȃ̂� IT ����̖|��ŕp�o����\������������܂����B�ᕶ���v���O���~���O�֘A�̂��̂������ł��B����Ȓ��Ŏ����C�ɂȂ����\���� 2 �����Љ�܂��B
- the curse of knowledge
�u�m���̎v�Ɩ�邱�Ƃ������ł��B�������悭�킩���Ă�����e�́A�킩��Ȃ��l�̋C�������킩�炸�A�Ԃ��Ă��܂������ł��Ȃ��A�Ƃ����Ƃ��Ɏg���錾�t�ł��B���́A�ŏ��Acurse �� course �ƌ��ԈႦ�Ă��܂��܂����Bcurse �Ȃ�� IT ����ł͂߂����ɓo�ꂵ�Ă��Ȃ��ł� (;�;)
- code (������)
�@If there is more than one way to code the task, code it in the manner ...
code �͂����Ă��͖����ŁA�����ł��������Ƃ��Ďg���邱�Ƃ������Ǝv���܂��B�������ł́Aimplement �Ɠ������u�`����������v�Ƃ����Ӗ��̂悤�ł��B
����͈ȏ�ł��B�|��ł͌���������̂őS����K�p����̂͂Ȃ��Ȃ�����ł����A�p��l�C�e�B�u�łȂ��p��҂́A��������������Ɩ��̒ʂ����K�C�h���C����m���Ă����Ɖ����̂Ƃ��̔����Ƃ��Ă�����������Ȃ��ł��B�����ɂ��������Ă���܂�����āA�����̎咣�̍����Ɏg�������ł��B
2020�N05��28��
����ɍ��x�ȕ\���t�B���^���֗��I
����ASDL Trados Studio �� 2017 ���� 2019 �ɃA�b�v�O���[�h���܂����B�O��̋L���́u2019 �ւ̃A�b�v�O���[�h�v�Ƃ����^�C�g���������ɂ�������炸�A���݂܂���A2019 �ɂ��ĂقƂ�lj��������Ă��܂���ł����B2017 �̃o�O�����܂�ɑ����A�������C�ɂȂ��Ă��܂����B������ 2019 �ɂ��ď��������Ǝv���܂����ATrados �{�̂̐V�@�\�Ƃ��Ă͌l�|��҂ɖ𗧂傫�Ȃ��̂���������Ȃ��̂ŁA2019 �Ŏg����֗��ȃv���O�C�� Community Advanced Display Filter ���Љ�悤�Ǝv���܂��B
Community Advanced Display Filter �́ASDL �̃u���O�ł��u����ɍ��x�ȕ\���t�B���^�v�Ƃ��ďЉ��Ă��܂� (�v���O�C���̃C���X�g�[�����@����ڂ����������Ă���̂ŁA�Q�l�ɂ��Ă�������)�B���̃v���O�C���� 2017 �ł��g���܂����A�ŐV�̋@�\�� 2019 �ł����g���܂���B�܂��A�����o�[�W������ 2021 �ł́A���̃v���O�C�����W���@�\�Ƃ��Ė{�̂ɑg�ݍ��܂�邻���ł��B���݂̂悤�Ƀv���O�C���Ƃ��Ă̒ł͕ʓr�C���X�g�[�����K�v�ł����A�{�̂ɑ�����������������Ԃ��Ȃ��Ȃ�̂ł���ɕ֗��ɂȂ肻���ł��B
���āA��L�� SDL �̃u���O�̃^�C�g���ɂ́u����ɍ��x�ȕ\���t�B���^�v�Ə������ȕ\�����g���Ă��܂��B����́A�u����Ɂv�u���x�v�ł͂Ȃ��\���t�B���^�����݂��邩��ł��B
�@�@�@[���r���[] �^�u > �\���t�B���^
�@�A�@[�\��] �^�u > ���x�ȕ\���t�B���^
�@�B�@[�\��] �^�u > Community Advanced Display Filter�@<--- ���ꂪ�u����ɍ��x�ȕ\���t�B���^�v
�܂��A���x�ł͂Ȃ����ʂ̃t�B���^�� [���r���[] �^�u�ɂ���u�\���t�B���^�v�ł��B�ł���y�Ɏg����t�B���^�ŁA�X�e�[�^�X�Ȃǂ̏����� 1 �����I�����邩�A�������������������͂��Ďg�p���܂��B����ɑ��āA�����̏������w��ł���ȂǁA�����@�\����������Ă���t�B���^�� [�\��] �^�u����\������u���x�ȕ\���t�B���^�v�ł��B�����܂ł� 2 �����݂̂Ƃ��� Trados �{�̂ɑg�ݍ��܂�Ă���@�\�ŁA�����Ƃ͕ʂɃv���O�C���Ƃ��Ēlj����� Community Advanced Display Filter ���u����ɍ��x�ȕ\���t�B���^�v�ƂȂ�܂��B
�����ɂ����āA3 �ɕ�����Ă����Ԃ͂킩��ɂ����ł����A�e��ʂł̑�����ʓ|�ł��B�ł��A2019 �o�[�W������ Community Advanced Display Filter �͏��������g�����肪�ǂ��Ȃ��Ă��܂��B
2019 �o�[�W������ Community Advanced Display Filter �̎g���₷���Ƃ���́A�E�N���b�N�Ŏg����_�ł��B�G�f�B�^�ʼnE�N���b�N������ƁA���̂悤�ȃ��j���[���\������܂��B
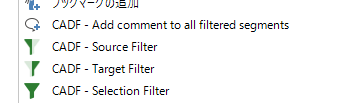
4 �̃R�}���h���p�ӂ���Ă��܂����A�����悭�g�p����͉̂��� 3 �ł��BSource Filter �� Target Filter �́A�J�[�\���̂��镪�߂̌����S�̂܂��͖S�̂Ńt�B���^�������܂��B�܂�A�����܂��͖��܂����������J��Ԃ��̕��߂�\���ł��܂��B
��ԉ��� Selection Filter �́A���ߓ��̑I������������Ńt�B���^�������܂��B�����Ɩ̂ǂ���őI�����Ă����v�ł��B����ɁA�����Ɩ̗����ŕ������I�����Ă����ƁA�����������Ƃ��ăt�B���^��������܂��B
�ŋ߁AMemsource ���g�����Ƃ������������́AMemsource �̃t�B���^�֗̕����ɂ������芵��Ă��܂��ATrados �̃t�B���^�ɂ��Ȃ�X�g���X�������Ă��܂����B�ł��A���̉E�N���b�N�̃��j���[�̂������� Memsource �Ɠ����悤�Ƀ����A�N�V�����Ńt�B���^����������悤�ɂȂ�܂����B�֗��ł��I
2019 �o�[�W������ Community Advanced Display Filter �Ŏ����C�ɂȂ��Ă����@�\�� 1 ���uHighlight�v�ł��B
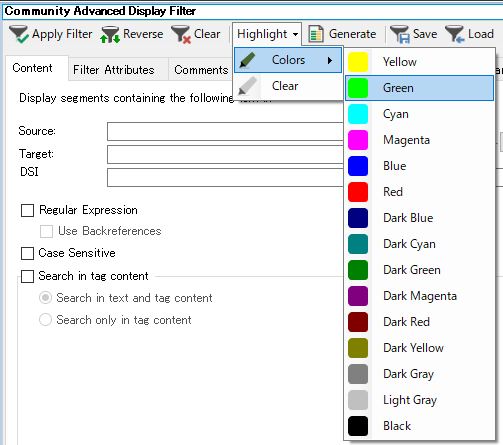
�����������w�肵�ăt�B���^����������A[Highlight] ����F��I�����āA�\�����̕��߂Ɍu���y���Ń}�[�N��t���邱�Ƃ��ł��܂��B[Clear] ��I������ƁA�lj������u���y�������ׂč폜�ł��܂��B

�֗������ȋ@�\�ł����A���ۂɎg���Ƃ��͂��������ӂ���_������܂��B
�� �X�e�[�^�X���ς��
�u���y����lj����鑀�������ƁA��}�̂悤�ɃX�e�[�^�X���u�|�v�ɂȂ��Ă��܂��܂��B�u���|��v�ł��u�|��ς݁v�ł����ׂāu�|�v�ɕς��܂��BTrados �ɂƂ��ẮA�l�Ԃ��s�����ʂ̕ҏW�Ɠ����F���ɂȂ�悤�ł��B�܂��A[Clear] �ō폜�����Ƃ����A�u�|�v�ɕς��܂��B
�� �G�f�B�^�̐ݒ�Łu������\������v
��}�̂悤�ɃG�f�B�^��Ōu���y���̐F��\������ɂ́A�G�f�B�^�� [�����̕\���X�^�C��] �ŏ�����\������悤�ɐݒ肵�Ă����K�v������܂��B
[�t�@�C��] > [�I�v�V����] > [�G�f�B�^] > [����^�G�f�B�^] ����ݒ肵�܂��B
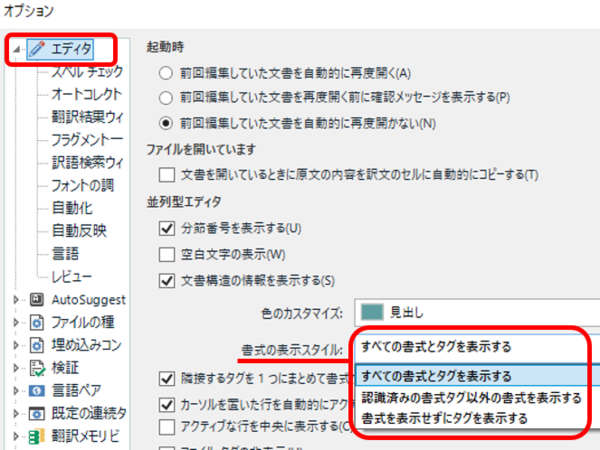
3 �̃I�v�V����������܂����A��ԉ��� [������\�������Ƀ^�O��\������] ��I�����Ă���ƁA�����ݒ�̃^�O���\������邾���ŁA��}�̂悤�ȗΐF�̌u���y���̕\���ɂ͂Ȃ�܂���B�u���y����\������ɂ́A��� 2 �̃I�v�V�����̂ǂ��炩��I������K�v������܂� (���̏����\���̐ݒ�ɂ��ẮA�ȑO�̋L�� �G�f�B�^��̃t�H���g��ς��� �ł������������Ă��܂�)�B���̂����߂� [���ׂĂ̏����ƃ^�O��\������] �ł��B
�� ���������Ƀ^�O���}�������
�����̕\���� [���ׂĂ̏����ƃ^�O��\������] �������߂���̂ɂ͗��R������܂��B����́A���̌u���y�����^�O�Ƃ��Ėɑ}������邩��ł��B���̌u���y���́ATrados �̃G�f�B�^��݂̂̃}�[�L���O�ł͂Ȃ��A�ʏ�̏����Ɠ����悤�Ƀ^�O�Ƃ��Ėɑ}������A���������ɂ��u���y���̏��������f����܂��B

�^�O�̓��e��\�����Ă݂�Ƃ킩��܂����A<cfhighlight> �Ƃ��������^�O���}������Ă��܂��B����́AWord �Ŏg����u���y���̃^�O�ł��B���̂��߁A���̂܂ܖ���������Όu���y���t���̏�ԂŖ���������܂��B�u���y���t���̖��ł���͕̂֗��ȏꍇ������܂����A���͏������ӂ��K�v�ł��B
�� Word �t�@�C���ȊO�͗v����
Office �����̏ꍇ�AWord �ɂ͌u���y���̋@�\������܂����AExcel �� PowerPoint �ɂ͂��̋@�\������܂��� (PowerPoint �̈ꕔ�̃o�[�W�����ɂ͂���悤�ł���)�B���̂��߁AWord �ȊO�̃t�@�C���� <cfhighlight> ��}�����Ă���������Ă��܂��܂��B�܂��A��������邾���Ȃ炢���̂ł����A�ꍇ�ɂ���ẮA�G���[�ɂȂ�������ł��Ȃ��Ȃ邱�Ƃ�����܂��B
HTML �� XML �ȂǁA�ق��̌`���̏ꍇ�����l�ŁA<cfhighlight> �^�O��}�����Ă��A���������Ɍu���y�����\�������킯�ł͂���܂���B�G�f�B�^��Ōu���y�����c���Ă����Ɩɗ]�v�ȃ^�O�����邱�ƂɂȂ�̂ŁA����������O�Ɍu���y���͂��ׂč폜���������悳�����ł��B
Community Advanced Display Filter �͂ƂĂ��֗��ł��B�֗��ł����A���������\���t�B���^���Ďg���ɂ����ł���ˁH�H �t�B���^�������ĕ��߂��\���ɂ���ƁA�|��Ώۂ̑O��̕��߂������Ȃ��Ȃ��Ƃ��ɂ������Ƃ��悭����܂��B�c�[�����g���Ă���ƕ����������������Ƃ��A�p�b�`���[�N�|��͂��߂Ƃ��A�����Ă���̂ɁA�Ȃ��\���t�B���^�����̋����Ȃ낤�Ƌ^��ł��B
�^�O�̒��g����������@�\�́A�̂̂悤�Ɍ����@�\�̒��ɂ����ė~�������A���b�N����Ă��镪�߂����ăW�����v���Ă����@�\���~�����Ƃ���ł��B��\���ɂ��Ȃ��ŁA�\�������܂܂ŃW�����v���ė~������ł��B��\���ɂ����Ⴈ�����Ƃ����̂́A�ǂ��炩�Ƃ����R�[�f�B�l�[�^�[����̔��z�̂悤�ȋC�����܂��B�ꊇ�Ń��b�N�����������Ƃ��A����̏����Ń��[�h�����J�E���g�������Ƃ��A����ȗp�r����Ȃ����Ǝv���܂��B���߂��ЂƂЂƂ�Ƃ��Ă����|��҂Ƃ��ẮA�����@�\�ƃW�����v�@�\�̏[�������҂��Ă��܂��B
����͈ȏ�ł��B����ASDL �̃I�����C�� ���[�h�V���[�ɎQ�����܂������A����̓��e�͎�Ɋ�ƌ����̊��������܂����B�O��͖|��Ҍ����������C������̂Ńo�����X������Ă���̂�������Ȃ��ł����A������A�|��҂̑��݂��Y����Ȃ��悤�A�ق��ڂ��Ƃł����������Ă��������Ȃ��Ǝv���Ă��܂��B
Community Advanced Display Filter �́ASDL �̃u���O�ł��u����ɍ��x�ȕ\���t�B���^�v�Ƃ��ďЉ��Ă��܂� (�v���O�C���̃C���X�g�[�����@����ڂ����������Ă���̂ŁA�Q�l�ɂ��Ă�������)�B���̃v���O�C���� 2017 �ł��g���܂����A�ŐV�̋@�\�� 2019 �ł����g���܂���B�܂��A�����o�[�W������ 2021 �ł́A���̃v���O�C�����W���@�\�Ƃ��Ė{�̂ɑg�ݍ��܂�邻���ł��B���݂̂悤�Ƀv���O�C���Ƃ��Ă̒ł͕ʓr�C���X�g�[�����K�v�ł����A�{�̂ɑ�����������������Ԃ��Ȃ��Ȃ�̂ł���ɕ֗��ɂȂ肻���ł��B
�\���t�B���^�� 3 ����
���āA��L�� SDL �̃u���O�̃^�C�g���ɂ́u����ɍ��x�ȕ\���t�B���^�v�Ə������ȕ\�����g���Ă��܂��B����́A�u����Ɂv�u���x�v�ł͂Ȃ��\���t�B���^�����݂��邩��ł��B
�@�@�@[���r���[] �^�u > �\���t�B���^
�@�A�@[�\��] �^�u > ���x�ȕ\���t�B���^
�@�B�@[�\��] �^�u > Community Advanced Display Filter�@<--- ���ꂪ�u����ɍ��x�ȕ\���t�B���^�v
�܂��A���x�ł͂Ȃ����ʂ̃t�B���^�� [���r���[] �^�u�ɂ���u�\���t�B���^�v�ł��B�ł���y�Ɏg����t�B���^�ŁA�X�e�[�^�X�Ȃǂ̏����� 1 �����I�����邩�A�������������������͂��Ďg�p���܂��B����ɑ��āA�����̏������w��ł���ȂǁA�����@�\����������Ă���t�B���^�� [�\��] �^�u����\������u���x�ȕ\���t�B���^�v�ł��B�����܂ł� 2 �����݂̂Ƃ��� Trados �{�̂ɑg�ݍ��܂�Ă���@�\�ŁA�����Ƃ͕ʂɃv���O�C���Ƃ��Ēlj����� Community Advanced Display Filter ���u����ɍ��x�ȕ\���t�B���^�v�ƂȂ�܂��B
�����ɂ����āA3 �ɕ�����Ă����Ԃ͂킩��ɂ����ł����A�e��ʂł̑�����ʓ|�ł��B�ł��A2019 �o�[�W������ Community Advanced Display Filter �͏��������g�����肪�ǂ��Ȃ��Ă��܂��B
�E�N���b�N�Ŏg����
2019 �o�[�W������ Community Advanced Display Filter �̎g���₷���Ƃ���́A�E�N���b�N�Ŏg����_�ł��B�G�f�B�^�ʼnE�N���b�N������ƁA���̂悤�ȃ��j���[���\������܂��B

4 �̃R�}���h���p�ӂ���Ă��܂����A�����悭�g�p����͉̂��� 3 �ł��BSource Filter �� Target Filter �́A�J�[�\���̂��镪�߂̌����S�̂܂��͖S�̂Ńt�B���^�������܂��B�܂�A�����܂��͖��܂����������J��Ԃ��̕��߂�\���ł��܂��B
��ԉ��� Selection Filter �́A���ߓ��̑I������������Ńt�B���^�������܂��B�����Ɩ̂ǂ���őI�����Ă����v�ł��B����ɁA�����Ɩ̗����ŕ������I�����Ă����ƁA�����������Ƃ��ăt�B���^��������܂��B
�ŋ߁AMemsource ���g�����Ƃ������������́AMemsource �̃t�B���^�֗̕����ɂ������芵��Ă��܂��ATrados �̃t�B���^�ɂ��Ȃ�X�g���X�������Ă��܂����B�ł��A���̉E�N���b�N�̃��j���[�̂������� Memsource �Ɠ����悤�Ƀ����A�N�V�����Ńt�B���^����������悤�ɂȂ�܂����B�֗��ł��I
�t�B���^�\�����ꂽ���߂��u���y���Ń}�[�N����
2019 �o�[�W������ Community Advanced Display Filter �Ŏ����C�ɂȂ��Ă����@�\�� 1 ���uHighlight�v�ł��B

�����������w�肵�ăt�B���^����������A[Highlight] ����F��I�����āA�\�����̕��߂Ɍu���y���Ń}�[�N��t���邱�Ƃ��ł��܂��B[Clear] ��I������ƁA�lj������u���y�������ׂč폜�ł��܂��B

�֗������ȋ@�\�ł����A���ۂɎg���Ƃ��͂��������ӂ���_������܂��B
�� �X�e�[�^�X���ς��
�u���y����lj����鑀�������ƁA��}�̂悤�ɃX�e�[�^�X���u�|�v�ɂȂ��Ă��܂��܂��B�u���|��v�ł��u�|��ς݁v�ł����ׂāu�|�v�ɕς��܂��BTrados �ɂƂ��ẮA�l�Ԃ��s�����ʂ̕ҏW�Ɠ����F���ɂȂ�悤�ł��B�܂��A[Clear] �ō폜�����Ƃ����A�u�|�v�ɕς��܂��B
�� �G�f�B�^�̐ݒ�Łu������\������v
��}�̂悤�ɃG�f�B�^��Ōu���y���̐F��\������ɂ́A�G�f�B�^�� [�����̕\���X�^�C��] �ŏ�����\������悤�ɐݒ肵�Ă����K�v������܂��B
[�t�@�C��] > [�I�v�V����] > [�G�f�B�^] > [����^�G�f�B�^] ����ݒ肵�܂��B
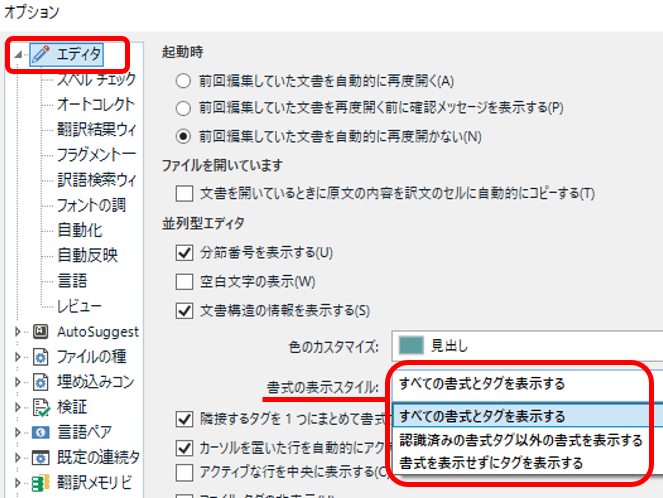
3 �̃I�v�V����������܂����A��ԉ��� [������\�������Ƀ^�O��\������] ��I�����Ă���ƁA�����ݒ�̃^�O���\������邾���ŁA��}�̂悤�ȗΐF�̌u���y���̕\���ɂ͂Ȃ�܂���B�u���y����\������ɂ́A��� 2 �̃I�v�V�����̂ǂ��炩��I������K�v������܂� (���̏����\���̐ݒ�ɂ��ẮA�ȑO�̋L�� �G�f�B�^��̃t�H���g��ς��� �ł������������Ă��܂�)�B���̂����߂� [���ׂĂ̏����ƃ^�O��\������] �ł��B
�� ���������Ƀ^�O���}�������
�����̕\���� [���ׂĂ̏����ƃ^�O��\������] �������߂���̂ɂ͗��R������܂��B����́A���̌u���y�����^�O�Ƃ��Ėɑ}������邩��ł��B���̌u���y���́ATrados �̃G�f�B�^��݂̂̃}�[�L���O�ł͂Ȃ��A�ʏ�̏����Ɠ����悤�Ƀ^�O�Ƃ��Ėɑ}������A���������ɂ��u���y���̏��������f����܂��B

�^�O�̓��e��\�����Ă݂�Ƃ킩��܂����A<cfhighlight> �Ƃ��������^�O���}������Ă��܂��B����́AWord �Ŏg����u���y���̃^�O�ł��B���̂��߁A���̂܂ܖ���������Όu���y���t���̏�ԂŖ���������܂��B�u���y���t���̖��ł���͕̂֗��ȏꍇ������܂����A���͏������ӂ��K�v�ł��B
�� Word �t�@�C���ȊO�͗v����
Office �����̏ꍇ�AWord �ɂ͌u���y���̋@�\������܂����AExcel �� PowerPoint �ɂ͂��̋@�\������܂��� (PowerPoint �̈ꕔ�̃o�[�W�����ɂ͂���悤�ł���)�B���̂��߁AWord �ȊO�̃t�@�C���� <cfhighlight> ��}�����Ă���������Ă��܂��܂��B�܂��A��������邾���Ȃ炢���̂ł����A�ꍇ�ɂ���ẮA�G���[�ɂȂ�������ł��Ȃ��Ȃ邱�Ƃ�����܂��B
HTML �� XML �ȂǁA�ق��̌`���̏ꍇ�����l�ŁA<cfhighlight> �^�O��}�����Ă��A���������Ɍu���y�����\�������킯�ł͂���܂���B�G�f�B�^��Ōu���y�����c���Ă����Ɩɗ]�v�ȃ^�O�����邱�ƂɂȂ�̂ŁA����������O�Ɍu���y���͂��ׂč폜���������悳�����ł��B
�\���t�B���^�����łȂ��A������W�����v���������ė~����
Community Advanced Display Filter �͂ƂĂ��֗��ł��B�֗��ł����A���������\���t�B���^���Ďg���ɂ����ł���ˁH�H �t�B���^�������ĕ��߂��\���ɂ���ƁA�|��Ώۂ̑O��̕��߂������Ȃ��Ȃ��Ƃ��ɂ������Ƃ��悭����܂��B�c�[�����g���Ă���ƕ����������������Ƃ��A�p�b�`���[�N�|��͂��߂Ƃ��A�����Ă���̂ɁA�Ȃ��\���t�B���^�����̋����Ȃ낤�Ƌ^��ł��B
�^�O�̒��g����������@�\�́A�̂̂悤�Ɍ����@�\�̒��ɂ����ė~�������A���b�N����Ă��镪�߂����ăW�����v���Ă����@�\���~�����Ƃ���ł��B��\���ɂ��Ȃ��ŁA�\�������܂܂ŃW�����v���ė~������ł��B��\���ɂ����Ⴈ�����Ƃ����̂́A�ǂ��炩�Ƃ����R�[�f�B�l�[�^�[����̔��z�̂悤�ȋC�����܂��B�ꊇ�Ń��b�N�����������Ƃ��A����̏����Ń��[�h�����J�E���g�������Ƃ��A����ȗp�r����Ȃ����Ǝv���܂��B���߂��ЂƂЂƂ�Ƃ��Ă����|��҂Ƃ��ẮA�����@�\�ƃW�����v�@�\�̏[�������҂��Ă��܂��B
����͈ȏ�ł��B����ASDL �̃I�����C�� ���[�h�V���[�ɎQ�����܂������A����̓��e�͎�Ɋ�ƌ����̊��������܂����B�O��͖|��Ҍ����������C������̂Ńo�����X������Ă���̂�������Ȃ��ł����A������A�|��҂̑��݂��Y����Ȃ��悤�A�ق��ڂ��Ƃł����������Ă��������Ȃ��Ǝv���Ă��܂��B
| �@�@ |
�^�O�F�����̕\���X�^�C�� Highlight ���� �W�����v 2017 2021 2019 �o�[�W���� �v���O�C�� �A�v�� ���x�ȕ\���t�B���^ �\���t�B���^ Community Advanced Display Filter �u���y�� �g���u���V���[�e�B���O ����
Tweet
2020�N05��10��
2019 �ւ̃A�b�v�O���[�h
�ŋ߁A�悤�₭���l�����̘b���������悤�ɂȂ�܂����B�ł��A���������ƌ�����Ƃ���͂���ŐS�z�ɂȂ�A���Ƃ����Ă��̂܂��l�𑱂���킯�ɂ��������A�C�������h����ςȂ��̖����ł��B
����Ȓ��A�����ɂȂ��� 2019 �ɃA�b�v�O���[�h���܂����B�������� 2017 ���g�������悤�Ǝv���Ă����̂ł����A2021 �o��̃j���[�X���āA���ɔ����Ă��܂��܂����B���́A���낢��ƃo�O�������č����Ă����Ƃ���ł����B
�܂��A���N��
�@�@�p�b�P�[�W���J���Ȃ�
�@�@�@�@(�R�~���j�e�B: Studio2017���A�b�v�f�[�g��A�ԋp�p�b�P�[�W���J���Ȃ�)
�Ƃ�����肪����܂����B����͒v���I�ł����B���̖����������邽�߂ɁA2017 �� CU18 �ɍX�V����K�v������܂����B
�ŁA���̍X�V���������͂킩��Ȃ��̂ł����A
�@�@�������ɓo�^�����������ɂ̓q�b�g���Ă��Ȃ�
�@�@�@�@(�R�~���j�e�B: TM�ɓo�^�������\������Ȃ����Ƃ�����܂�)
�Ƃ�����肪�������Ă��܂����B�������ɓo�^�������q�b�g���Ă��Ȃ����Ƃ����܂ɂ���A���������Ȃ��Ǝv���Ă��܂����B�ł��A���炭 (�����炭 2�A3��) ����ƃq�b�g���Ă���悤�ɂȂ�̂ŁA�����̊��Ⴂ���Ƃ��l���Ă��܂����B(�����A���̖��́A��L�̃R�~���j�e�B�̓��e�ɂ��ƁA2019 �ł���������悤�Ȃ̂ŁA2019 �ɃA�b�v�O���[�h��������Ƃ����ĉ��������킯�ł͂Ȃ������ł��B)
�ŁA���̖���
�@�@�����t�@�C�����J���ăR�����g��}������ƁA�㏑���ۑ��ł��Ȃ��Ȃ�
�@�@�@�@(�R�~���j�e�B: Cannot save multiple files in Editor (Studio 2017 CU18))
�ł����B��������ɂƂ��Ă͒v���I�ł����B�������t�@�C�������\�܂܂�Ă���v���W�F�N�g����Ƃ��Ă��āA�����t�@�C�����܂Ƃ߂ĊJ�����Ƃ͓�����O�ɂȂ��Ă��܂����B���̂悤�ȃv���W�F�N�g�Ŗ|���Ђւ̐\�����莖�����L�^����Ƃ��ɕ֗��Ȃ̂��R�����g�@�\�� Comment View Plugin �ł��B��ƒ��� Trados ��ŃR�����g��t���Ă����A�Ō�� Comment View Plugin ���g���ăR�����g�� Excel �t�@�C���ɏo�͂��āA�|���Ђւ̐\������Ƃ��܂��B
�Ƃ��낪�A�����t�@�C�����J���č�Ƃ��A�R�����g��lj����āA�����㏑���ۑ������悤�Ƃ���ƁA���Ȃ��݂̃G���[�u�I�u�W�F�N�g�Q�Ƃ��I�u�W�F�N�g �C���X�^���X�ɐݒ肳��Ă��܂���v�ɂȂ��Ă��܂��܂��B
�@�@
���ǁA�R�����g����������폜���Ȃ��ƃt�@�C�����㏑���ۑ��ł��܂���ł����BComment View Plugin �������̂��Ǝv���ăv���O�C���������Ă݂���ASDL Freshstart ���g���Đݒ�����Z�b�g���Ă݂���ƁA���낢�뎎���Ă݂܂��������߂ł����B��L�̃R�~���j�e�B�̓��e�ɂ��ƁA���̖��� CU18 �̃o�O�̂悤�ł��B
�ŁA�ݒ�����Z�b�g������Ō������̂�
�@�@AutoText ���g���Ȃ�
�@�@�@�@(�i���b�W�x�[�X: "Failed to create setting page" error in SDL Studio 2017 CU18 when selecting AutoText)
�Ƃ������ł��BSDL Freshstart ���g���Đݒ�����Z�b�g����ƁA���� AutoText ��V���[�g�J�b�g�L�[�̐ݒ肪�����Ă��܂����Ƃ�����܂��B�Ȃ̂ŁA���Z�b�g��������ŁAAutoText �̐ݒ���m���߂悤�Ǝv���ĊJ������A����ȉ�ʂɂȂ��Ă��܂����B
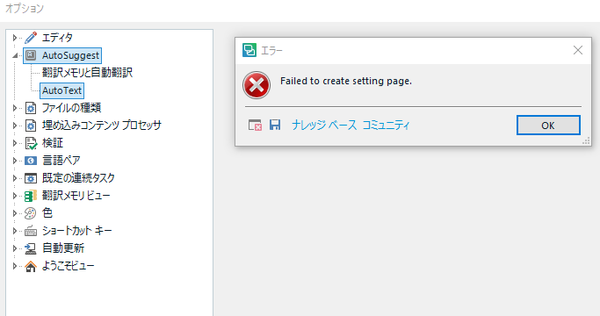
SDL Freshstart ���g������ł������A�o�b�N�A�b�v�̂��߂ɐݒ�t�@�C���̖��O���蓮�ŕύX����Ȃǂ̑�������Ă��܂����B�����A����͂����ݒ�t�@�C���̉������Ă��܂����Ȃ��Ǝv���A���S�ȍăC���X�g�[���܂ł��Ă��܂��܂����B���A���ǁA���͉�������܂���ł����B������A��L�̃i���b�W�x�[�X�ɂ���悤�ɁACU18 �̃o�O�̂悤�ł��B
�ŁA�ǂ����悤���ƔY��ł����Ƃ���ɁA�� 2019 �ɃA�b�v�O���[�h����� 2021 �̃����[�X���ɖ����ŃA�b�v�O���[�h�ł���Ƃ������[�����͂��A�����A�b�v�O���[�h���邵���Ȃ��̂��Ȃ��Ǝv���A����̌��f�Ɏ������킯�ł��B
�Ȃ������C�����Ȃ��ł��Ȃ��ł����A�V�����o�[�W�����Ɋ��҂��邵���Ȃ������ł��BTrados ����A�z���g�Ɋ撣���āI�I
����Ȓ��A�����ɂȂ��� 2019 �ɃA�b�v�O���[�h���܂����B�������� 2017 ���g�������悤�Ǝv���Ă����̂ł����A2021 �o��̃j���[�X���āA���ɔ����Ă��܂��܂����B���́A���낢��ƃo�O�������č����Ă����Ƃ���ł����B
�܂��A���N��
�@�@�p�b�P�[�W���J���Ȃ�
�@�@�@�@(�R�~���j�e�B: Studio2017���A�b�v�f�[�g��A�ԋp�p�b�P�[�W���J���Ȃ�)
�Ƃ�����肪����܂����B����͒v���I�ł����B���̖����������邽�߂ɁA2017 �� CU18 �ɍX�V����K�v������܂����B
�ŁA���̍X�V���������͂킩��Ȃ��̂ł����A
�@�@�������ɓo�^�����������ɂ̓q�b�g���Ă��Ȃ�
�@�@�@�@(�R�~���j�e�B: TM�ɓo�^�������\������Ȃ����Ƃ�����܂�)
�Ƃ�����肪�������Ă��܂����B�������ɓo�^�������q�b�g���Ă��Ȃ����Ƃ����܂ɂ���A���������Ȃ��Ǝv���Ă��܂����B�ł��A���炭 (�����炭 2�A3��) ����ƃq�b�g���Ă���悤�ɂȂ�̂ŁA�����̊��Ⴂ���Ƃ��l���Ă��܂����B(�����A���̖��́A��L�̃R�~���j�e�B�̓��e�ɂ��ƁA2019 �ł���������悤�Ȃ̂ŁA2019 �ɃA�b�v�O���[�h��������Ƃ����ĉ��������킯�ł͂Ȃ������ł��B)
�ŁA���̖���
�@�@�����t�@�C�����J���ăR�����g��}������ƁA�㏑���ۑ��ł��Ȃ��Ȃ�
�@�@�@�@(�R�~���j�e�B: Cannot save multiple files in Editor (Studio 2017 CU18))
�ł����B��������ɂƂ��Ă͒v���I�ł����B�������t�@�C�������\�܂܂�Ă���v���W�F�N�g����Ƃ��Ă��āA�����t�@�C�����܂Ƃ߂ĊJ�����Ƃ͓�����O�ɂȂ��Ă��܂����B���̂悤�ȃv���W�F�N�g�Ŗ|���Ђւ̐\�����莖�����L�^����Ƃ��ɕ֗��Ȃ̂��R�����g�@�\�� Comment View Plugin �ł��B��ƒ��� Trados ��ŃR�����g��t���Ă����A�Ō�� Comment View Plugin ���g���ăR�����g�� Excel �t�@�C���ɏo�͂��āA�|���Ђւ̐\������Ƃ��܂��B
�Ƃ��낪�A�����t�@�C�����J���č�Ƃ��A�R�����g��lj����āA�����㏑���ۑ������悤�Ƃ���ƁA���Ȃ��݂̃G���[�u�I�u�W�F�N�g�Q�Ƃ��I�u�W�F�N�g �C���X�^���X�ɐݒ肳��Ă��܂���v�ɂȂ��Ă��܂��܂��B
�@�@
���ǁA�R�����g����������폜���Ȃ��ƃt�@�C�����㏑���ۑ��ł��܂���ł����BComment View Plugin �������̂��Ǝv���ăv���O�C���������Ă݂���ASDL Freshstart ���g���Đݒ�����Z�b�g���Ă݂���ƁA���낢�뎎���Ă݂܂��������߂ł����B��L�̃R�~���j�e�B�̓��e�ɂ��ƁA���̖��� CU18 �̃o�O�̂悤�ł��B
�ŁA�ݒ�����Z�b�g������Ō������̂�
�@�@AutoText ���g���Ȃ�
�@�@�@�@(�i���b�W�x�[�X: "Failed to create setting page" error in SDL Studio 2017 CU18 when selecting AutoText)
�Ƃ������ł��BSDL Freshstart ���g���Đݒ�����Z�b�g����ƁA���� AutoText ��V���[�g�J�b�g�L�[�̐ݒ肪�����Ă��܂����Ƃ�����܂��B�Ȃ̂ŁA���Z�b�g��������ŁAAutoText �̐ݒ���m���߂悤�Ǝv���ĊJ������A����ȉ�ʂɂȂ��Ă��܂����B

SDL Freshstart ���g������ł������A�o�b�N�A�b�v�̂��߂ɐݒ�t�@�C���̖��O���蓮�ŕύX����Ȃǂ̑�������Ă��܂����B�����A����͂����ݒ�t�@�C���̉������Ă��܂����Ȃ��Ǝv���A���S�ȍăC���X�g�[���܂ł��Ă��܂��܂����B���A���ǁA���͉�������܂���ł����B������A��L�̃i���b�W�x�[�X�ɂ���悤�ɁACU18 �̃o�O�̂悤�ł��B
�ŁA�ǂ����悤���ƔY��ł����Ƃ���ɁA�� 2019 �ɃA�b�v�O���[�h����� 2021 �̃����[�X���ɖ����ŃA�b�v�O���[�h�ł���Ƃ������[�����͂��A�����A�b�v�O���[�h���邵���Ȃ��̂��Ȃ��Ǝv���A����̌��f�Ɏ������킯�ł��B
�Ȃ������C�����Ȃ��ł��Ȃ��ł����A�V�����o�[�W�����Ɋ��҂��邵���Ȃ������ł��BTrados ����A�z���g�Ɋ撣���āI�I
| �@�@ |
�^�O�F�o�[�W���� 2019 2017 2021 2017 SR1 CU18 AutoText SDL Freshstart �v���O�C�� �A�v�� Comment View Plugin �g���u���V���[�e�B���O
Tweet