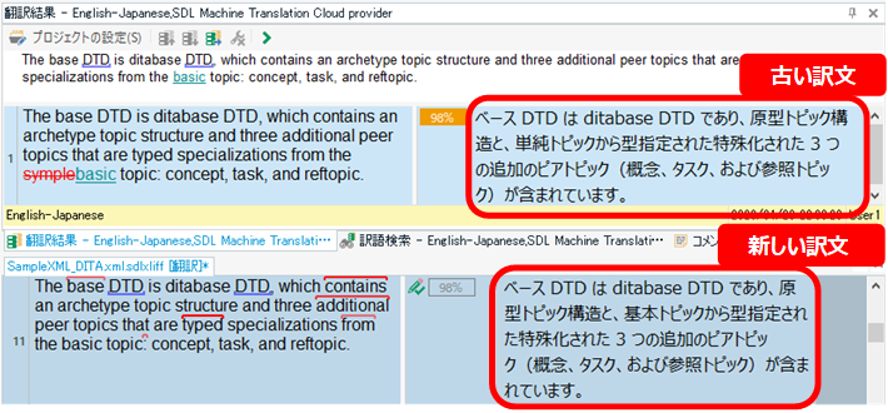
����A�R�~���j�e�B�Ɂu
�����G���[�v�Ƃ����������݂�����܂����BSDL �̕��̒��J�ȑΉ��ɂ��A�������u���߂̌����v�ł��邱�Ƃ��킩��A���͉��������悤�ł����B�����A���� SDL ����̍Ō�̉ɁA���̂悤�Ȏ�|�̃A�h�o�C�X������܂����B
�@�@�@�@
���߂̌������s������A���̌シ���Ɂu�̐����v�����s���āA
�@�@�@�@�G���[���o�Ȃ����Ƃ��m���߂�B���s������A�G���[���o�Ȃ����Ƃ����[�U�[���m�F���Ȃ��Ƃ����Ȃ��A�Ƃ����Ƃ��낪�����ɂ� Trados ���ۂ��ł����A���Ȗh�q�̂��߂ɂ͂��̃A�h�o�C�X�ɑf���ɏ]���Ă����̂��������Ǝv���܂��B
�����͂����Ă��A������s���̂͌����I�ł͂Ȃ��̂ŁA���́A�̕\�� (Ctrl+Shift+P) �@�\���g���ăv���r���[���Ă݂�悤�ɂ��Ă��܂� (�v���r���[�ɂ��ẮA�ȑO�̋L��
�u�̕\���v���g���Ă݂� ���Q�l�ɂ��Ă�������)�B�v���r���[�Ɩ����͌����ɂ͈قȂ鏈���ł����A���̌o���I�ɂ́A�v���r���[���ł���Ζ������ł��܂��B
�ȉ��ɁA���߂̌������s���ۂ̒��ӓ_�������������Ă݂����Ǝv���܂��B(���\�A��������܂��I)
�����͂ł��Ă��A�����������Ă��邱�Ƃ�����
���߂�����������̃G���[�Ƃ��ẮA��L�̃R�~���j�e�B�̓��e�̂悤�ɖ����̏��������s����P�[�X�����łȂ��A�����̏����͐��������̂ɁA�����������߂̎��ӂ̕����������Ă���Ƃ������P�[�X������܂��B���́APowerPoint �ʼn����̎�̃G���[�ɑ������܂����B���ɕ��G�ȍ\���̃t�@�C���ł͂Ȃ��A�Ȃ������Ȃ��Ă��܂��̂��͌��ǂ킩��܂���ł����B
�ǂ�ȃG���[���N���邩�킩��Ȃ��̂ŁA��͂�A������v���r���[�ł̊m�F�͌������Ȃ����Ȃ��Ǝv���܂��B�����̏ꍇ�́A�������G���[�Ȃ��������邱�Ƃ����łȂ��A�������ꂽ�t�@�C�����J���āA�����������߂̎��ӂ��m�F�����������S�ł��B
�����������߂����ɖ߂����Ƃ͂ł��Ȃ�
���߂́A������������ƌ��ɖ߂��܂���B�ʏ�� Ctrl+z (���ɖ߂�) �������͈͂ł͖߂��܂����A���ꂪ�����Ȃ��Ȃ���������߂��܂���B�u���߂̕����v�Ƃ����@�\������܂����A����́u���߂̌����v�Ƃ͕ʂ̋@�\�ł��B�����������߂��u�����v���Ă��A���̏�Ԃɖ߂�킯�ł͂���܂���B
���ɖ߂���i���Ȃ��̂ŁA�����������ăG���[�ɋC�t�����Ƃ��Ă��A�������̎��_����͂ǂ����邱�Ƃ��ł��܂���B�����Ȃ�ƍ���̂ŁA���́A���߂̌������s���O�ɂ܂��o�C�����K�� �t�@�C�����o�b�N�A�b�v����悤�ɂ��Ă��܂��B�o�b�N�A�b�v��������ŁA���߂̌��������āA�������v���r���[�����āA�������߂�������o�b�N�A�b�v�����t�@�C����߂��܂��B���Ȃ�A�ʓ|�ł��B
�ςȌ����͍s��Ȃ�
�O�q�̂悤�ɁA��������G���[�ɂȂ��Ă��܂��Ǝ�Ԃ�������̂ŁA�ŏ�����ςȌ����͍s��Ȃ��悤�ɒ��ӂ��邱�Ƃ���ł��BTrados �̃G�f�B�^��ł͘A�����Ă��镪�߂̂悤�Ɍ����Ă��A���ۂɂ͂����łȂ����Ƃ�����܂��B�P���ȉ��s�ŕ�������Ă��邾���Ȃ猋�����Ă� OK �ł����A�s�������̂���ӏ�������APowerPoint �̃X���C�h��ŗ��ꂽ�ꏊ�ɂ���e�L�X�g�Ȃǂ́A�G���[�ɂȂ肻���Ȃ̂Ŏ��͌������Ȃ��悤�ɂ��Ă��܂��B
�����������߂ɂ���Ɍ������s�����Ƃ͂ł��Ȃ� (�i�����z�������߂̏ꍇ)
2 �̕��߂�����������ŁA���́A���̉��̕��߂����������������Ƃ������Ƃ͂��т��т���܂��B�������A�i�����z�������߂̏ꍇ�A���������������߂ɂ���Ɍ������s�����Ƃ� (��{�I�ɂ�) �ł��܂���B�i�����z���Ȃ��ʏ�̕��ߓ��m�͌������J��Ԃ����Ƃ��ł��܂��B
�u�i�����z�������߁v�ł��邩�ǂ������d�v�ȃ|�C���g�Ȃ̂ł����ATrados �̃G�f�B�^��ɂ͂�����͂�����Ǝ����\��������܂���B�E�[�́u�����\���v�̏�������Ȃ�ƂȂ��킩��܂����A���߂���������Ƃ��ɂ����܂Ŋm�F�ł��邭�炢�Ȃ�A���������������������߂�I�����Y���Ȃ�ă~�X�͂��܂���B
�Ƃ����킯�ŁA�i�����z�������߂̌��������������킩��₷���\��������@�ƁA��������s��������Ɨ��Z�I�ȕ��@�����ɐ������܂��B
�������ꂽ���߂�\������
Trados �ɂ́A�i�����z���Č����������߂�\������Ƃ����I�v�V�������p�ӂ���Ă��܂��B
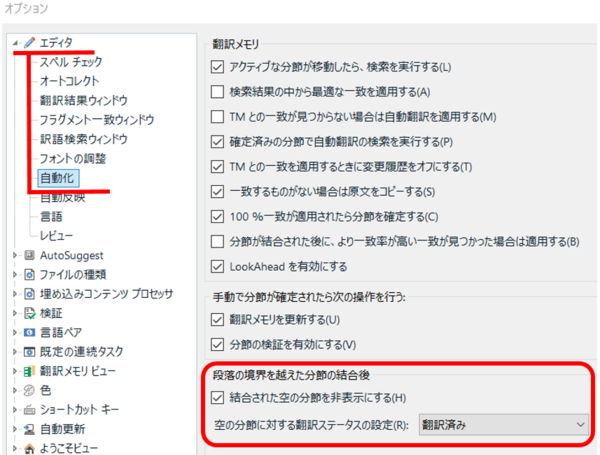
[
�t�@�C��] > [
�I�v�V����] > [
�G�f�B�^] > [
������] �ƑI������ƁA��}�̐ݒ��ʂ��\������܂��B�f�t�H���g�ł́A[
�������ꂽ��̕��߂��\���ɂ���] ���I���ɂȂ��Ă��邽�߁A�������ꂽ���߂͕\������܂���B���}�̗�ł́A���ߔԍ��� 19 ���� 21 �ɔ��ł��܂��B
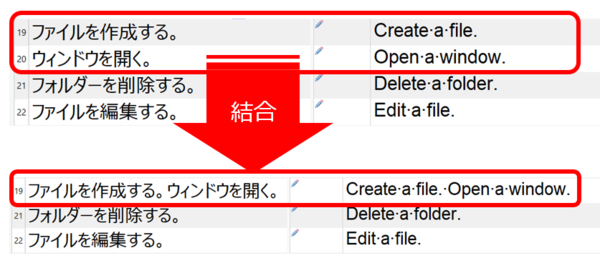
[
�������ꂽ��̕��߂��\���ɂ���] ���I�t�ɂ���ƁA���}�̂悤�ɁA�������ꂽ���߂��\������܂��B���ߔԍ� 20 ���\������A����������Ń��b�N����Ă���̂��킩��܂��B

1 ���ӓ_�Ƃ��āA���̃I�v�V�����́AUI �̕����̂Ƃ���A�u�i���̋��E���z�������߁v�ɂ����L���ɓ����܂���B�i���̋��E���z���Ȃ��ʏ�̕��߂́A���̃I�v�V������ݒ肵�Ă��\������܂���B
�i�����z���Č����������߂��A����Ɍ������s�����Ƃ��ł���H�I
�i�����z���Č����������߂ɂ���Ɍ������s�����Ƃ��ł��Ȃ��̂́A�P�ɕ��߂����b�N����Ă��邩��̂悤�ł��B�O�q�̂悤�ɁA�������ꂽ���߂͒��g����ɂȂ��������Ń��b�N����܂��B���̃��b�N���蓮�ʼn�������A�܂��������s�����Ƃ��ł��܂��B���}�́A���� 19 �� 20 ������������A���b�N���������Ă���A���� 21 �������������ʂł��B(����������́A�Ăу��b�N����Ă��܂��܂��B)

�܂��A�����ł����s����ȋ@�\�Ȃ̂ŁA���ׂĂ̑���͎��ȐӔC�ł��肢���܂��B�o�b�N�A�b�v�ƁA������v���r���[�ł̊m�F�͂��܂߂ɂ��Ă����̂����S�ł��B
�u�i�����z�������߂̌����v�̓p�b�P�[�W�̐ݒ�
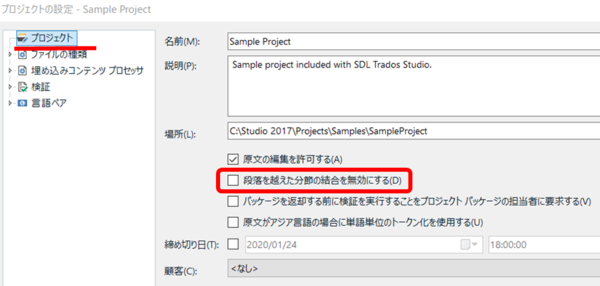
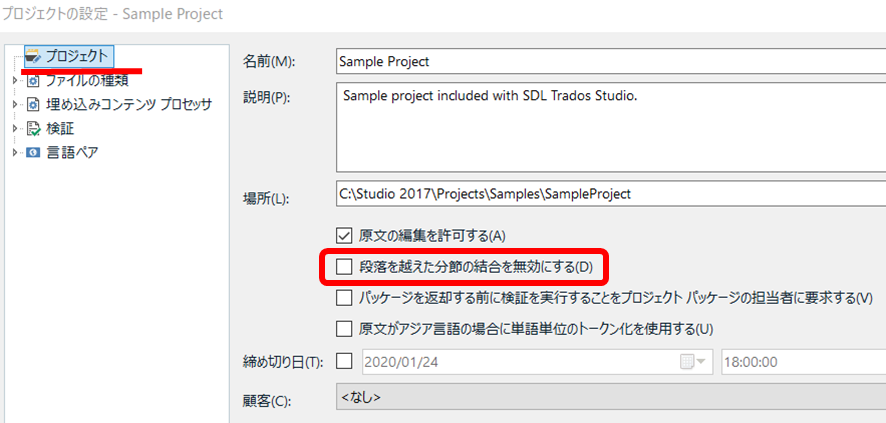
���낢��Ə����Ă��܂������A�i�����z�������߂̌������ł��邩�ǂ����̓p�b�P�[�W�̐ݒ�Ō��܂�܂��B[
�v���W�F�N�g�̐ݒ�] > [
�v���W�F�N�g] �ƑI������ƁA��}�̐ݒ��ʂ��\������܂��B�����ō쐬�����v���W�F�N�g�̏ꍇ�́A���̕ӂ�̃`�F�b�N�{�b�N�X�̐ݒ�������ŕύX�ł��܂����A�p�b�P�[�W�Ƃ��Ď�����ꍇ�́A�`�F�b�N�{�b�N�X���O���[�A�E�g����Ă��Đݒ��ύX�ł��܂���B
���̂��߁A�p�b�P�[�W�̍쐬�҂��u�i�����z�������߂̌����v��L���ɂ��Ă���Ă��Ȃ��ꍇ�A�p�b�P�[�W��������|��ґ��ł����L���ɂ��邱�Ƃ͂ł��܂���B�����Ă��́A�R�[�f�B�l�[�^�[����ɗL���ɂ��Ă��������Ƃ��肢����A�ݒ��ς��ăp�b�P�[�W�𑗂蒼���Ă��Ă���܂��B�����A�������炨�肢�����ꍇ�͓��ɁA���߂̌����������Ŗ������ł��Ȃ��Ȃ�܂����A�Ȃ�Ă��Ƃ͋�����Ȃ��̂ŁA�����ł��邩�̊m�F���܂��܂��d�v�ɂȂ�܂��B
����͈ȏ�ł��B���߂̌����́A�֗��ł͂���܂����A���Ȃ�s����ȋ@�\�ł��B�|��҂Ƃ��ẮA���߂̌������g��Ȃ��Ă��ςނ悤�Ɍ����𐮂��ė~�����Ȃ��Ǝv���܂��B