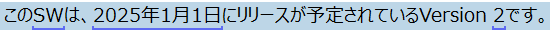�O���Ɉ��������ATrados ���Ń^�C�s���O�����炷���@���l���Ă݂܂��B����́A�v���W�F�N�g�̐ݒ�ł͂Ȃ��A[�t�@�C��] > [�I�v�V����] ����s�� Trados ���S�̂̐ݒ�ł��B�����̐ݒ�̏ڍׂɂ��ẮA�ȑO�̋L���uTrados �̐ݒ��ς���ɂ� �| [�t�@�C��] �� [�v���W�F�N�g�̐ݒ�]�v���Q�Ƃ��Ă��������B
[�t�@�C��] > [�I�v�V����] �̐ݒ�́A�v���W�F�N�g�̐ݒ�ƈقȂ�A��x�ݒ肷��ǂ̃v���W�F�N�g�ō�Ƃ����Ă��L���ł��B����͕֗��ł��锽�ʁA�v���W�F�N�g���Ƃɐݒ��ς��邱�Ƃ͂ł��Ȃ��Ƃ������Ƃł�����܂��B����̕��� (���p���A�p����) �ɂ���Đݒ��ς������Ȃ邱�Ƃ͂���܂����A�v���W�F�N�g��ς��Ă��ݒ�͕ς��Ȃ��̂ŁA���������ꍇ�͎蓮�Őݒ��ς��邵������܂���B(���ǁA�v���W�F�N�g���Ƃɐݒ��ς�����I �Ƃ������Ƃł��B)
����Љ��@�\�́A��� AutoSuggest �ł��BAutoSuggest �́A�p������� (�p�����͂���) �Ƃ��͂��܂��@�\���܂����A�a������� (���{�����͂���) �Ƃ��́AIME �Ƃ̊W��A���܂���҂ǂ���̓���ɂȂ�܂���B�a��̏ꍇ�́AAutoSuggest �͖����ɂ��� IME �̋@�\�����p����̂���̑I�����ł��B���̋L���̈ȉ��̐����́A�p������� (�p�����͂���) �ꍇ��O��Ƃ��Ă��܂��B�ł́A�n�߂Ă����܂��傤�B
AutoSuggest
AutoSuggest �̗L�������̐�ւ���ڍׂ̐ݒ�́A[�t�@�C��] > [�I�v�V����] > [AutoSuggest] ����s���܂��B
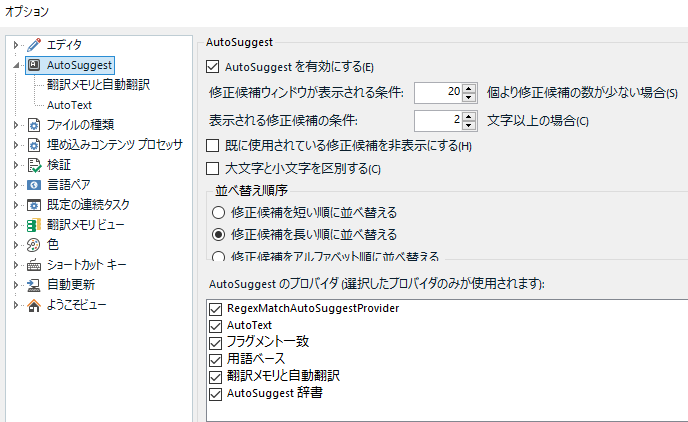
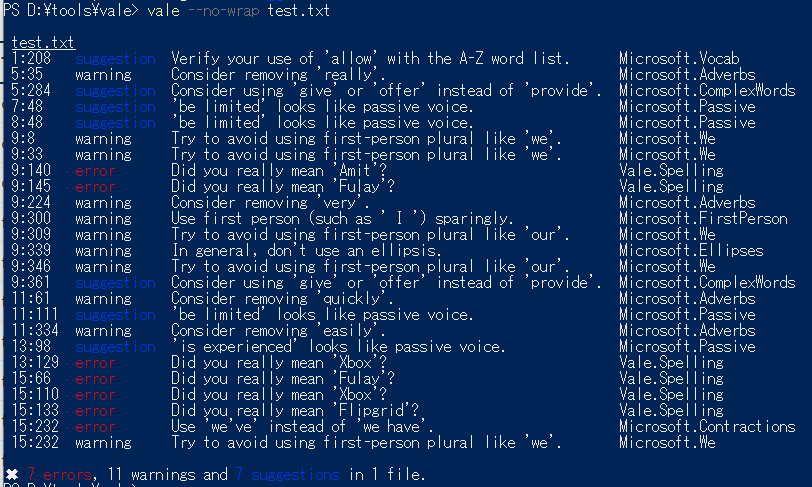
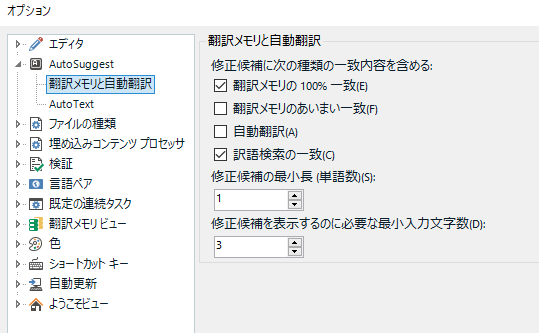
��ʉ����� [AutoSuggest �̃v���o�C�_] ���X�g�ŁAAutoSuggest �̌����ǂ����玝���Ă���̂����w��ł��܂��B���Ԃ��ύX�ł��܂��B���͂��ׂẴ`�F�b�N�{�b�N�X���I���ɂ��Ă��邱�Ƃ������ł����A�s�v�Ȃ��̂̓I�t�ɂł��܂��B
���̃��X�g�̈�ԏ�ɕ\������Ă��� [RegexMatchAutoSuggestProvider] �́AAutoSuggest �����������v���O�C���ł��B����ɂ��Ă͌�Ő������܂��B[AutoText] �� [�|�����Ǝ����|��] �ɂ��ẮA�ʂ̉�ʂŏڍׂ�ݒ�ł��܂��B�������q���܂��B
[AutoSuggest ����] �́A����̃���������p��𒊏o�����Ζ�W (.bpm �t�@�C��) �̂悤�Ȃ��̂ł��B���炭�A�t���[�����X�łł͂��̎��������邱�Ƃ��ł��Ȃ������̂ł����A�Ȃ�� Trados Studio 2021 ����͐����ł����悤�ɂȂ��Ă��܂��B(���́A���̋L���������Ă��āA���������@�\���t���[�����X�łɒlj�����Ă��邱�Ƃ����߂Ēm��܂����B�т����肵�܂����B) �������ŊȒP�ɐ������܂��B
���̉�ʂׂ̍����ݒ�́A�����Ɍ����āA�l�̍D�݂ł��B��������p��W�̏[���x�ɂ����܂����A����̖�������܂��B��₪���܂�ɑ����\�������悤�Ȃ� [�|�����Ǝ����|��] ���I�t�ɂ���Ƃ��A��Ƃ��Ă���v���W�F�N�g�ɍ��킹�Ėʓ|���炸�ɐݒ��ς��Ă��������B(�܂��A���ǁA�v���W�F�N�g���Ƃɐݒ��ς��邱�ƂɂȂ�̂Ŗʓ|�ł��B)
�ł́A�������̋@�\���ڂ������Ă����܂��B
�|�����Ǝ����|��
���̋@�\��L���ɂ���ƁA�\��������₪���Ȃ葽���Ȃ�܂��B���́A�������炷���߁A�����Ă��u�����܂���v�v�̃`�F�b�N�{�b�N�X�̓I�t�ɂ��Ă��܂��B
�@
AutoText
�ł悭�g�����������œo�^���Ă������Ƃ��ł��܂��BAutoText �́A�����ɊW�Ȃ��\�������̂������ł��B��������p��W�͌����ɊY�������傪�Ȃ���@�\���܂��AAutoText �͖̌���o�^���Ă���̂ŁA�ŏ��̐���������͂���Ό����ɊW�Ȃ���₪�\������Ă��܂��B�uperson in charge�v��ucompany/organization�v�ȂǁA��X���b�V�����܂ތ����o�^�ł��܂��B

AutoText �̃��X�g�̓t�@�C���Ƃ��ĕۑ��ł��܂��B�E���ɂ��� [�C���|�[�g]��[�G�N�X�|�[�g] �̃{�^�����g���܂��B���̃��X�g�́ATrados ���������肷��ƁA�V�����lj�������傪�����Ă��܂����Ƃ�����̂ŁA���܂߂ɃG�N�X�|�[�g���Ă������Ƃ������߂��܂��B
Regex Match AutoSuggest Provider
Regex Match AutoSuggest Provider �́AAutoSuggest ���������Ă����v���O�C���ł��B�����Ŏg�p�ł��܂��B�ڍׂɂ��ẮA�ȑO�̋L���u���v���O�C���� �����ɂ���p������ɃR�s�[���� (���ˉp�̏ꍇ)�v���Q�Ƃ��Ă��������B
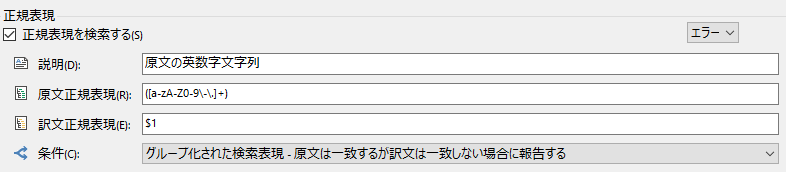
�ȑO�̋L���ł͉p�������R�s�[������@�����������Ă��܂��A�������A���낢��Ȏg�������ł��܂��B��{�I�ɂ͐��K�\���ł����A���ʂ̌���o�^���邾���Ȃ琳�K�\������Ɉӎ�����K�v�͂���܂���B
���Ƃ��A���{��ł悭�g����ۈ͂ݐ������ȉ��̂悤�ɕϊ��ł��܂� (�@ �� (1) �ɕϊ�����)�B
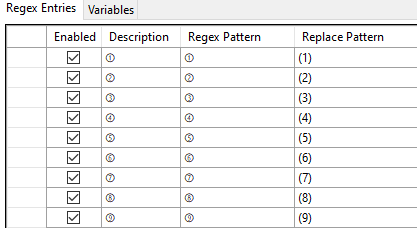
�ȉ��́A�����������ɕϊ����Ă��܂��B�S�p�ɑΉ����邽�ߏ����������K�\�����g���Ă��܂� (���݂܂���A���Ԃ����Ȃ��Ƃɓ��ɈӖ��͂���܂���)�B

��}�̂悤�ɐݒ肵���ꍇ�A11 �ɑ��Ă� November �� January �̗��������Ƃ��ĕ\������܂��B�܂��A�P�ɐ������w�肵�Ă��邾���Ȃ̂ŁA�����Ƃ͊W�̂Ȃ������̏ꍇ�����������Ƃ��ĕ\������܂��B���̕ӂ�́A���Ƃ��Ă͋��e�͈͓��ł��B
AutoSuggest ����
�Ō�� AutoSuggest �����ł��B�O�q�̂Ƃ���A���̎����͂���܂Ńt���[�����X�łł͍쐬�ł��Ȃ������̂ŁA���͎g�������Ƃ�����܂���B�ǂ̒��x�𗧂̂��͖��m���ł����A�傫�ȃ�����������Ă���ꍇ�͕֗��ɋ@�\����̂ł͂Ȃ����Ǝv���܂��B
AutoSuggest �����̌X�̐ݒ�́A[�t�@�C��] > [�I�v�V����] �ł͂Ȃ��A�v���W�F�N�g�̐ݒ肩��s���܂��B�v���W�F�N�g�̐ݒ�� [����y�A] > [����̌���y�A] > [AutoSuggest ����] ���N���b�N����ƈȉ��̉�ʂ��\������܂� (����Ɉˑ�������̂Ȃ̂ŁA[���ׂĂ̌���y�A] �ł͂Ȃ��AJapanese �ȂǓ���̌���y�A����ݒ肵�܂�)�B

�܂��A�������쐬���܂��B���̉�ʂ� [����] �{�^�����N���b�N����ƃE�B�U�[�h���J�n����܂��B�E�B�U�[�h��i�߂Ă����A�����t�@�C�� (.bpm) ���ł�������܂��B���������傫���Ƃ��Ȃ莞�Ԃ�������Ǝv����̂ŁA�ݒ��K�X�������Ă݂Ă��������B�܂��A�����̍쐬�́A���̉�ʂł͂Ȃ��A[�|����] �r���[����s�����Ƃ��ł��܂��B
�����t�@�C�����쐬���ꂽ��A[�lj�] �{�^�����N���b�N���Ă��̃t�@�C����o�^���܂��B����ŁA�����͊����ł��B�����̓��e�����ɕ\������Ă���͂��ł��B
����͈ȏ�ł��BAutoSuggest �́A�ݒ�ɂ���ẮA���҂ǂ���̌�₪�\������Ȃ�������A�\��������₪���������肷�邱�Ƃ�����܂��B�x�X�g�Ȑݒ��������̂͂Ȃ��Ȃ�����ł����A���낢��Ƃ��������������B��Ƃ��Ă���v���W�F�N�g�ɉ����āA���܂߂ɐݒ��ς��邱�Ƃ�����Ǝv���܂� (�����v���Ă͂��܂����A���ۂ̂Ƃ���͖ʓ|�ł�)�B
| �@�@ |
�^�O�FAutoText Regex Match AutoSuggest Provider AutoSuggest���� AutoSuggest [�t�@�C��] > [�I�v�V����]
Tweet