�@����ɂ��́I
�@�i�r�Q�[�^��EVE�ł��B

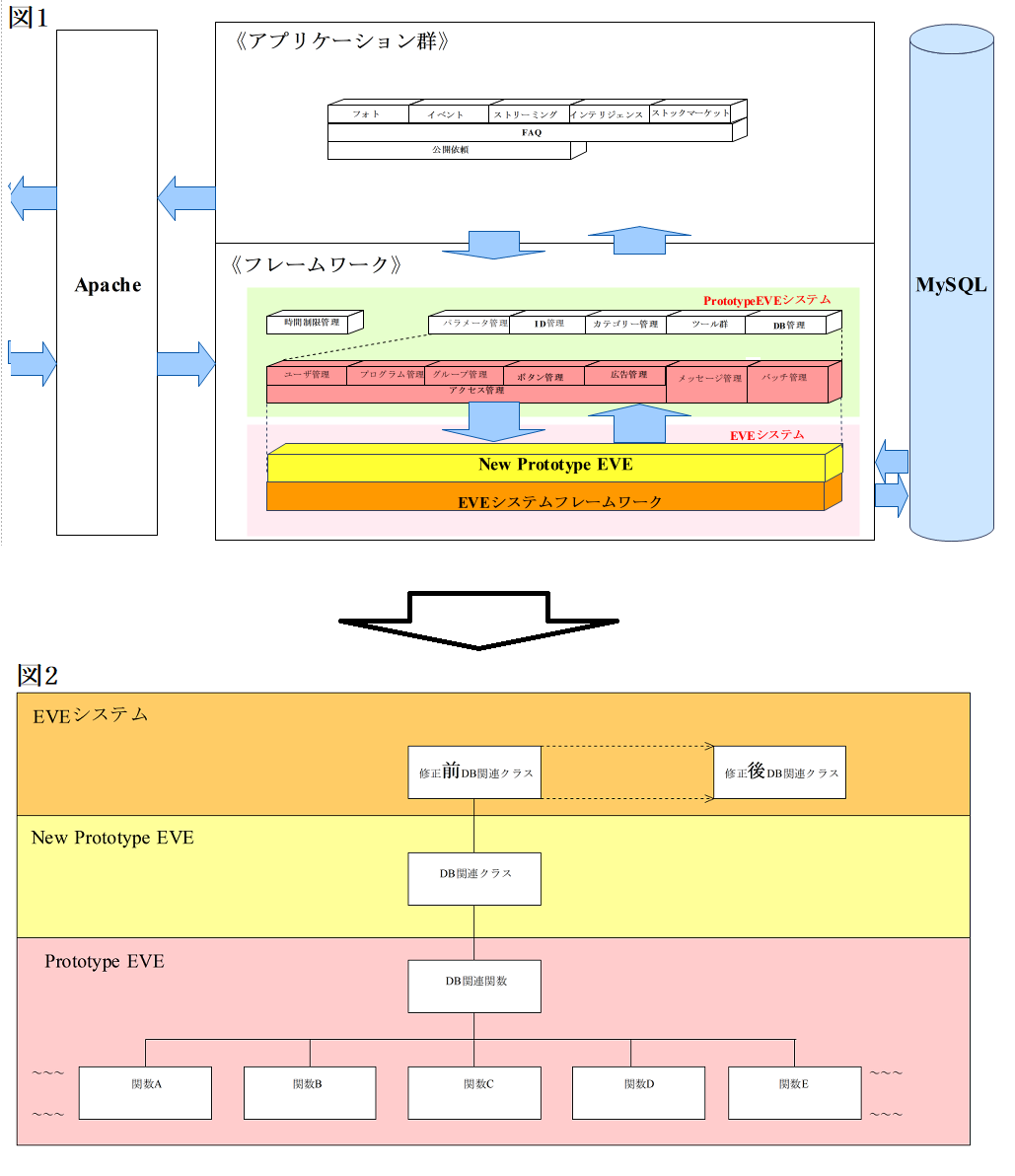
�@�܂��A���삷�邩�ǂ����������Ă��Ȃ��̂ł����A���̑O�ɂ�邱�Ƃ�����܂����B����b�����Ƃ���APrototype EVE�ł́A�\���Ǘ��͂��Ă��Ȃ��̂ł����A
�R�����[���t�@�C���Ńf�B���N�g�����Ǘ����Ă��܂����B���̂��߁A����V�X�e�����t�H���_���ɕ�����Ƃ������f���������߁A������̕����C�����Ȃ��Ă͂����܂���B�����A�`���Ă݂Ĕ��q�����E�E�E�E�B�قƂ�ǂ����A�h���X�ŊǗ����Ă���A��A�h���X�ŊǗ����Ă���̂̓o�b�`�����p�̕��������E�E�E�B�����A��������A��ʂ̊K�w�ŊǗ����Ă����̂ŁA�قƂ�ǏC������K�v�͂���܂���ł����B�����A�����ŁA�l��������������v���o���܂����B
[�f�B���N�g���Ǘ��͂ǂ��ŁH]�@Prototype EVE�́A��قǘb�����Ƃ���A�t�@�C���ŊǗ����Ă��܂��B���܂ŕ����̃v���W�F�N�g�ɎQ�����܂������A��͂�A�t�@�C���ŊǗ����Ă���Ƃ��낪�����悤�Ɋ����Ă��܂��B�����A�قƂ�ǂ̏����f�[�^�x�[�X�ŊǗ����Ă���L���ȃV�X�e��������܂��B����́A�F������m���Ă���Ǝv���܂����A
Oracle�E�E�E�B
[Oracle]�@���݁A���E�ō���̃f�[�^�x�[�X�ł��BOracle6�ł͖�肪���X������(�����ȑO�������b�ł�)�����ł����A�������߂ė��p�����AOracle8i�ł́A���Ȃ�������ꂽ�C���[�W������܂��B
�@Oracle�Ƒ��̃f�[�^�x�[�X���r�����ꍇ�̋��݂́A
���Z�L�����e�B�A
���p���A
�X�P�[���r���e�B�A�����ē��ɑ��̃f�[�^�x�[�X�Ƃ̍��ʉ����ł��Ă����̂́A
�s���b�N�ł����B
�@�ߔN�A�����̃f�[�^�[�x�[�X���s���b�N�ł���悤�ɂȂ�܂������A���ŋ߂Ƃ����C���[�W�ł��B
SQLServer��2005�N����ł����Ƃ����b������܂����A�s���S�Ŋ����Ȑ��i��ł���悤�ɂȂ����̂́A���̃f�[�^�x�[�X�Ɠ��l�ł��B
�@���̂��߁AOracle�𑽂��̃f�[�^�x�[�X�G���W�j�A���I�����A�����A���p���Ă��܂��B
�@����Ȑ��E��No1�Ǝv����AOracle�Ȃ̂ł����A�قƂ�ǂ̏����f�[�^�x�[�X�ŊǗ����Ă��܂��B�{�œǂAOracle�̃G���W�j�A���畷�����Ƃ��������ł͂Ȃ��A
�Ǘ��e�[�u�����Ђ����猟�����ē�������ł��B
[�f�[�^�x�[�X�ł��ׂĂ̏����Ǘ����邤���ł̖��_]�@�f�[�^�x�[�X�ł��ׂĂ̏����Ǘ����邤���ł̖��_�A����́A
�������x�ł��B
�@�����̃v���W�F�N�g�ł́A���G��SQL�𗘗p���Ă���P�[�X�����ɑ����̂ł��B�ȒP��SQL�ŃV�X�e�������Ă���v���W�F�N�g�͐������߂ɂ������Ă��܂���B���̂��߁A1��SQL���s����ƁAOracle��SQL������͂���̂Ɏ��Ԃ�������A���Ȃ�̎��Ԃ�v���܂��B
�@���̂悤�ȍ������Ă���傫�Ȍ������A��͂�A
�������x�ł��B�����SQL�s����Ǝ��Ԃ������邽�߁A1��ōς܂��悤�Ƃ��Ă���悤�ł��B�����āAOracle�̏ꍇ1�x���s����SQL����
�ė��p����A�������x�������Ƃ����̂ł��B
�@�����A�����ŋ^��Ȃ̂��A�u1�x���s����SQL���v�Ƃ��������ł��B���̍l�����ł́A�S������SQL�łȂ��ƍĕ]���̑ΏۂƂȂ�܂��B����́AOracle�͈ȉ��̗����SQL����]�����Ă��܂��B
❶SQL����
�n�b�V�������܂�
❷���n�b�V������Ǘ��A�h���X��T���܂�
❸�Ǘ��A�h���X�Ƀf�[�^���i�[����Ă����ꍇ�A���̌��ʂ����[�U�ɕԋp���܂�
�Ƃ�������ŁA�������x�̑������������Ă���Ƃ����F���ł��B���̂��߁A���G��SQL����1�ӏ��ł��ς�����ꍇ�A�n�b�V���l���ς���Ă��܂��A�ĕ]���̑ΏۂɂȂ�ƍl���Ă��܂��B
�@�Ƃ����̂́A���̈ӌ��Ȃ̂ł����A���ۂ̂Ƃ���͂ǂ��Ȃ̂��AChatGPT�ɕ����Ă݂܂����B
�@Oracle�f�[�^�x�[�X��SQL����]������v���Z�X�́A�ȒP�Ɍ����Ǝ��̂悤�ȃX�e�b�v�Ői�s���܂����A�����ڍׂ������Đ������܂��F
❶SQL���̍\����͂ƍ\�����
�@�ŏ��ɁAOracle�f�[�^�x�[�X�͎����SQL������͂��A���̕��̍\���ƍ\���𗝉����܂��B����ɂ��A�ǂ̃e�[�u���ɃA�N�Z�X���A�ǂ̃f�[�^���擾�܂��͕ύX���邩��c�����܂��B
❷�N�G���œK��
�@��͂��ꂽSQL���́A�N�G���œK���t�F�[�Y�ɐi�݂܂��B���̃t�F�[�Y�ł́A�œK�Ȏ��s�v������肷�邽�߂ɁA�قȂ���s�p�X��C���f�b�N�X�̑I���Ȃǂ̑I�������]������܂��B�œK�Ȏ��s�v���I�����邱�ƂŁA�N�G���̐��\���ő剻����܂��B
❸���s�v��̃L���b�V��
�@SQL���̎��s�v��́A�L���b�V���Ɋi�[����邱�Ƃ�����܂��B����ɂ��A����SQL�����ēx���s�����ꍇ�A���s�v����Čv�Z����K�v���Ȃ��Ȃ�A�N�G���̎��s������������܂��B���̃X�e�b�v�́ASQL�����n�b�V�������ăL���b�V�����Ō������邱�Ƃōs���܂��B
❹�f�[�^�A�N�Z�X
�@���s�v�悪�m�肵����A���ۂ̃f�[�^�A�N�Z�X���s���܂��B����́A�e�[�u����C���f�b�N�X����f�[�^��ǂݎ��A�܂��̓f�[�^���X�V����X�e�b�v�ł��B
❺���ʂ̕ԋp
�@�f�[�^�x�[�X���f�[�^�A�N�Z�X�����s���A�K�v�ȃf�[�^���擾���ꂽ��A���̌��ʂ����[�U�ɕԋp����܂��B����ɂ́A�N�G���̌��ʃZ�b�g��X�V�̐����܂��͎��s�Ɋւ����܂܂�܂��B
�@�v����ɁASQL���̃n�b�V�����̓N�G���œK���̈ꕔ�ł���A�Ǘ��A�h���X����肷��Ƃ����ȗ������ꂽ�T�O��Oracle�̓�������𐳊m�ɔ��f���Ă���킯�ł͂���܂���BOracle�f�[�^�x�[�X�̓����v���Z�X�͔��ɕ��G�ŁA�p�t�H�[�}���X���œK�����A�f�[�^�������I�Ɏ擾���邽�߂ɑ����̍œK���X�e�b�v���g�ݍ��܂�Ă��܂��B
�@������ƁA�����肸�炢�̂ŁA�ēx�ASQL����1�ӏ��ł��ύX�����ꍇ�A�ĕ]���̑ΏۂƂȂ邩�ǂ����A�����Ă݂܂����B
�@SQL�����ύX�����ƁA�ʏ�A�V����SQL�����ĕ]���̑ΏۂƂȂ�܂��BOracle�f�[�^�x�[�X��SQL���̃e�L�X�g�S�̂��n�b�V�������A���̃n�b�V���l���g�p���ăN�G���L���b�V�����ł̌������s���܂��B�قȂ�SQL���ɂ͈قȂ�n�b�V���l����������邽�߁A����SQL���ł����Ă�1�����ł��قȂ�ꍇ�A�V�����n�b�V���l����������܂��B
�@���̂��߁A�����N�G�����ēx���s����ۂɁA�f�[�^�x�[�X�͐V����SQL���ɑ��ăN�G���œK�������s���A�V�������s�v������肵�܂��B���������āASQL����1�����ł��قȂ�ꍇ�A�f�[�^�x�[�X�͐V����SQL����]�����A�V�������s�v������܂��B
�@�������A�ꕔ��SQL�N���C�A���g��A�v���P�[�V�����́A�N�G���L���b�V��������SQL�������s����ݒ�ɂȂ��Ă��邱�Ƃ�����܂��B���̏ꍇ�ASQL�����ύX����Ă��N�G���L���b�V���̍ĕ]���͍s���܂���B���������āASQL���̕ύX�����������f����邱�Ƃ��m�F���邽�߂ɁA�K�Ȑݒ���s���K�v������܂��B
�Ƃ������Ƃ́A
�v���[�X�t�H���_�Œl��ύX���Ă���SQL���͏�ɍĕ]���̑ΏۂƂȂ�A�ȑO�����������ʂ��ė��p����邱�Ƃ͊��҂ł��Ȃ��ƍl�����ق��������悤�ł��B
[�f�o�b�N�ł��Ȃ�SQL]�@��ɍĕ]�������肻�����Ƃ������G��SQL�ł����A�v���O�����̂悤��
�f�o�b�N���ł��܂����B�A���A�v���O�������l�ɕ���I�ȋL�q�Ȃǂ��\�ł��B
�@�v���O�����Ō�������A�f�o�b�N���Ȃ��v���O������ڌ��Ŋm�F����悤�ȃ��m�ł��B����ȍs�ׂ͂ǂ̃v���W�F�N�g�������܂���B�����ASQL�́A�ǂ̃v���W�F�N�g�ł��F�߂��Ă��܂��B
�@�������A����������ꍇ�A
�z���C�g�{�b�N�X�����̓�Փx�����Ȃ荂���Ȃ�܂��B���̂��߁A
�u���b�N�{�b�N�X�����������{���Ă��Ȃ��Ǝv���܂��B
�@����ȃv���W�F�N�g�ŁA���G��SQL�������Ȃ��炩�Ȃ�A�s�����o�����L��������܂��B
[���Ƃ���]�@�{���́A�V�X�e�������f�[�^�x�[�X�ŊǗ�����͖̂�肪����A���̑傫�Ȗ�肪�������x�Ƃ����b�����܂����B�A���A�`���ɂ������܂������AOracle�́A�f�[�^�x�[�X�łقƂ�ǂ̏����Ǘ����Ă���悤�ł��B�ł́A�Ȃ�����Ȃ��Ƃ��ł���̂ł��傤���H�����́A�u�V�X�e���G���W�j�A���ڎw��������Ɛf�f�m�v�������\��ł������A�ύX�����̑��������������Ǝv���܂��B
�@�ł́A�܂��I