新規記事の投稿を行うことで、非表示にすることが可能です。
2020年03月14日
その13 シェルスクリプトでChromeを起動、スクリーンショット撮影、終了
こちらを
参考に、
下記スクリプトを作成しました。
参考に、
下記スクリプトを作成しました。
#!/bin/sh
input=./data
/usr/bin/google-chrome https://fanblogs.jp/aimyself/ &
/usr/bin/gnome-screenshot --window --file=$input/output7.png --delay=5
/usr/bin/pkill --oldest --signal TERM -f chrome
【このカテゴリーの最新記事】
-
no image
-
no image
-
no image
-
no image
-
no image
2020年03月11日
その12 muttをインストールし、コマンドからメール送信
開発環境
・Ubuntu 18.04
追加機能
・msmtp version 1.6.6
・Mutt 1.9.4
こちらを参考に、
コマンドからメール送信をできるようにします。
$ sudo apt install msmtp
$ sudo apt install mutt
でインストール。
あとは、参考のページのとおりです。
・Ubuntu 18.04
追加機能
・msmtp version 1.6.6
・Mutt 1.9.4
こちらを参考に、
コマンドからメール送信をできるようにします。
$ sudo apt install msmtp
$ sudo apt install mutt
でインストール。
あとは、参考のページのとおりです。
2020年03月09日
その11 condaで仮想開発環境を使いこなす
こちらを参考にしました。
tensorflowについて
web上の財産を利用しようとした際、
そのバージョンが異なると利用できません。
そこで、各種バージョンを利用できるように、
condaで複数の仮想環境を構築し、
対応しています。
tensorflowについて
web上の財産を利用しようとした際、
そのバージョンが異なると利用できません。
そこで、各種バージョンを利用できるように、
condaで複数の仮想環境を構築し、
対応しています。
2020年03月01日
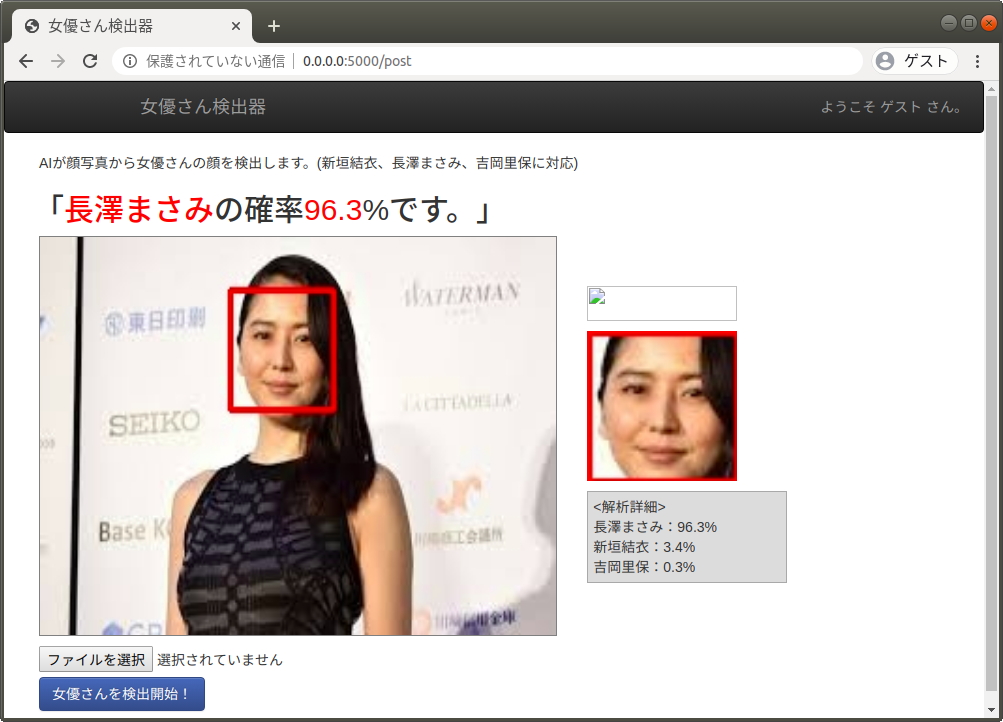
ディープラーニングで顔を識別するAIを作る①(学習データ準備編)
開発環境(仮想)
・Ubuntu 18.04
・python 2.7.17
・conda 4.8.2
・opencv 4.2.0(root環境)
・tensorflow 1.15.0
こちらを
教科書として参考にし、
自分でも作ってみようと作業を始めました。
でも、結構大変…。
いっぺんにはできなさそう。
教科書に習って、まずは①を行いました。
⓪はじめに
夢のコピー人形の作成には「AIとかディープラーニングが必須!」と思っていたので、
機械学習(ディープラーニング)の前提知識0ですが、試行錯誤で挑戦することに。
【つくるもの】
女優の新垣結衣さん、長澤まさみさん、吉岡里保さんの3人の顔を識別するAI。
【筆者(もう一人の自分)のプロフィール】
データ解析や機械学習の前提知識はなし。プログラミングは完全に独学の趣味で、
pythonをみたときに、これなら出来るかもと思ったのがきっかけ。
【機械学習&ディープラーニングで参考にさせて頂いている文献】
流石にディープラーニングをやるのに、機械学習について全く知らんのはまずいと思い、まずは色々とウェブ上の情報を見てみて、どんなことができてどんなことができないのかを知る。
(「TensorFlow」「ディープラーニング」で出てくるWEBの情報などは少し読んだ。後は「ニューラルネットワークってなんぞや?」ということを調べたり。)
特に参考にさせて頂いているのが、
TensorFlowによるももクロメンバー顔認識
ディープラーニングでザッカーバーグの顔を識別するAIを作る
TensorFlow2.0でアニメキャラ識別
1.3人の画像データを収集
自分の環境では、その1で導入した
GoogleChromeのImageDownloaderで
お一人あたり200~400枚を集めました。
集めた写真はそれぞれ
Aragaki1.jpeg
Aragaki2.jpeg
・
・
Nagasawa1.jpeg
Nagasawa2.jpeg
・
・
Yoshioka1.jpeg
Yoshioka2.jpeg
・
・
と言うように連番ファイルを作成するところまで到達しました。
要注意なのが、このあとに控えている作業では
連番が0からのファイル名で揃える必要があることです。
次の顔部分を切り取るプログラムを稼働させる際に、
番号0が存在していないと駄目であることに気づくまで、
2時間弱、webを調べまくり悪戦苦闘してしまいました。
結局、0.jpegは手作業で作りました。
この失敗をしないよう、本ブログに記録しておきます。
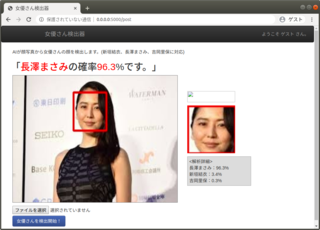
完成したものです。
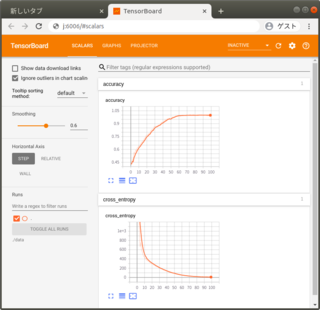
学習過程です。
上記はほぼ参考ページを写して作ったものですが、若干ですが、
開発環境に合わせて、書き換えております。
大きくは2つで
tensorflowのバージョン(1.15)にあわせて、
main.py内の何箇所をエラーに従って下記を参照に書き換え。
(旧 -> 1.0)
tf.audio_summary -> tf.summary.audio
tf.contrib.deprecated.histogram_summary -> tf.summary.histogram
tf.contrib.deprecated.scalar_summary -> tf.summary.scalar
tf.histogram_summary -> tf.summary.histogram
tf.image_summary -> tf.summary.image
tf.merge_all_summaries -> tf.summary.merge_all
tf.merge_summary -> tf.summary.merge
tf.scalar_summary -> tf.summary.scalar
tf.train.SummaryWriter -> tf.summary.FileWriter
もう一つは、ブラウザ上で診断するさいのweb.py内の
from werkzeug import secure_filename
↓
from werkzeug.utils import secure_filename
です。
・Ubuntu 18.04
・python 2.7.17
・conda 4.8.2
・opencv 4.2.0(root環境)
・tensorflow 1.15.0
こちらを
教科書として参考にし、
自分でも作ってみようと作業を始めました。
でも、結構大変…。
いっぺんにはできなさそう。
教科書に習って、まずは①を行いました。
⓪はじめに
夢のコピー人形の作成には「AIとかディープラーニングが必須!」と思っていたので、
機械学習(ディープラーニング)の前提知識0ですが、試行錯誤で挑戦することに。
【つくるもの】
女優の新垣結衣さん、長澤まさみさん、吉岡里保さんの3人の顔を識別するAI。
【筆者(もう一人の自分)のプロフィール】
データ解析や機械学習の前提知識はなし。プログラミングは完全に独学の趣味で、
pythonをみたときに、これなら出来るかもと思ったのがきっかけ。
【機械学習&ディープラーニングで参考にさせて頂いている文献】
流石にディープラーニングをやるのに、機械学習について全く知らんのはまずいと思い、まずは色々とウェブ上の情報を見てみて、どんなことができてどんなことができないのかを知る。
(「TensorFlow」「ディープラーニング」で出てくるWEBの情報などは少し読んだ。後は「ニューラルネットワークってなんぞや?」ということを調べたり。)
特に参考にさせて頂いているのが、
TensorFlowによるももクロメンバー顔認識
ディープラーニングでザッカーバーグの顔を識別するAIを作る
TensorFlow2.0でアニメキャラ識別
1.3人の画像データを収集
自分の環境では、その1で導入した
GoogleChromeのImageDownloaderで
お一人あたり200~400枚を集めました。
集めた写真はそれぞれ
Aragaki1.jpeg
Aragaki2.jpeg
・
・
Nagasawa1.jpeg
Nagasawa2.jpeg
・
・
Yoshioka1.jpeg
Yoshioka2.jpeg
・
・
と言うように連番ファイルを作成するところまで到達しました。
要注意なのが、このあとに控えている作業では
連番が0からのファイル名で揃える必要があることです。
次の顔部分を切り取るプログラムを稼働させる際に、
番号0が存在していないと駄目であることに気づくまで、
2時間弱、webを調べまくり悪戦苦闘してしまいました。
結局、0.jpegは手作業で作りました。
この失敗をしないよう、本ブログに記録しておきます。
完成したものです。
学習過程です。

上記はほぼ参考ページを写して作ったものですが、若干ですが、
開発環境に合わせて、書き換えております。
大きくは2つで
tensorflowのバージョン(1.15)にあわせて、
main.py内の何箇所をエラーに従って下記を参照に書き換え。
(旧 -> 1.0)
tf.audio_summary -> tf.summary.audio
tf.contrib.deprecated.histogram_summary -> tf.summary.histogram
tf.contrib.deprecated.scalar_summary -> tf.summary.scalar
tf.histogram_summary -> tf.summary.histogram
tf.image_summary -> tf.summary.image
tf.merge_all_summaries -> tf.summary.merge_all
tf.merge_summary -> tf.summary.merge
tf.scalar_summary -> tf.summary.scalar
tf.train.SummaryWriter -> tf.summary.FileWriter
もう一つは、ブラウザ上で診断するさいのweb.py内の
from werkzeug import secure_filename
↓
from werkzeug.utils import secure_filename
です。
2020年02月26日
その10 tensorflowのインストール
開発環境
・Ubuntu 18.04
・python 3.7.6→3.6.6
・conda 4.8.2
・opencv 4.2.0(root環境)
追加機能
・tensorflow 2.1.0→1.1.0
画像解析にopenCVのカスケード分類器を使いましたが、
googleが開発したTensorflowもあることを知り、
さっそくインストールしてみました。
こちらのTensorflowの公式ページの
インストールのページをみると、
2020年2月26日時点で、
Install TensorFlow 2
TensorFlow is tested and supported on the following 64-bit systems:
Python 3.5–3.7
Ubuntu 16.04 or later
Windows 7 or later
とありました。
私の開発環境はこれらをクリアしていたので、
$ anaconda-navigator
でroot環境下にて以下のとおりインストールしました。
# Requires the latest pip
$ pip install --upgrade pip
# Current stable release for CPU and GPU
$ pip install tensorflow
およおそ20分くらいで完了しました。
念の為、
$ pip list
でバージョンを確認したところ、
tensorflow 2.1.0 とありました。
次に
pythonでimportしてみたところ
>>> import tensorflow
2020-02-26 00:37:40.866798: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libnvinfer.so.6'; dlerror: libnvinfer.so.6: cannot open shared object file: No such file or directory
2020-02-26 00:37:40.866960: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libnvinfer_plugin.so.6'; dlerror: libnvinfer_plugin.so.6: cannot open shared object file: No such file or directory
2020-02-26 00:37:40.866989: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:30] Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
>>>
なんか色々注意書きがでてしまいました。
なんだか、サービスを利用するためには、ちょっと足りないものがあるようです。
とりあえず、今日はここまで。
その後、いろいろ試したところ
tensorflow2.0以降とそれ以前では文法がかわっているらしく、
ネット上にある各種参考資料を、
そのまま利用できなかったので、
tensorflowをダウングレードすることにしました。
加えて、tensorflow1では、
pythonの最新バージョンに対応していないとの記事もみつけたので、
python3.6.6にダウングレードすることにしました。
$ pip uninstall tensorflow
(tensorflowをアンインストール)
$ conda install python==3.6.6
(python3.6.6をインストール)
$ pip install tensorflow==1.11.0
(tensorflow1.11.0 CPU版をインストール)
$ pip install keras
これで、tensorflowがとりあえず動きました。
・Ubuntu 18.04
・python 3.7.6→3.6.6
・conda 4.8.2
・opencv 4.2.0(root環境)
追加機能
・tensorflow 2.1.0→1.1.0
画像解析にopenCVのカスケード分類器を使いましたが、
googleが開発したTensorflowもあることを知り、
さっそくインストールしてみました。
こちらのTensorflowの公式ページの
インストールのページをみると、
2020年2月26日時点で、
Install TensorFlow 2
TensorFlow is tested and supported on the following 64-bit systems:
Python 3.5–3.7
Ubuntu 16.04 or later
Windows 7 or later
とありました。
私の開発環境はこれらをクリアしていたので、
$ anaconda-navigator
でroot環境下にて以下のとおりインストールしました。
# Requires the latest pip
$ pip install --upgrade pip
# Current stable release for CPU and GPU
$ pip install tensorflow
およおそ20分くらいで完了しました。
念の為、
$ pip list
でバージョンを確認したところ、
tensorflow 2.1.0 とありました。
次に
pythonでimportしてみたところ
>>> import tensorflow
2020-02-26 00:37:40.866798: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libnvinfer.so.6'; dlerror: libnvinfer.so.6: cannot open shared object file: No such file or directory
2020-02-26 00:37:40.866960: W tensorflow/stream_executor/platform/default/dso_loader.cc:55] Could not load dynamic library 'libnvinfer_plugin.so.6'; dlerror: libnvinfer_plugin.so.6: cannot open shared object file: No such file or directory
2020-02-26 00:37:40.866989: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:30] Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
>>>
なんか色々注意書きがでてしまいました。
なんだか、サービスを利用するためには、ちょっと足りないものがあるようです。
とりあえず、今日はここまで。
その後、いろいろ試したところ
tensorflow2.0以降とそれ以前では文法がかわっているらしく、
ネット上にある各種参考資料を、
そのまま利用できなかったので、
tensorflowをダウングレードすることにしました。
加えて、tensorflow1では、
pythonの最新バージョンに対応していないとの記事もみつけたので、
python3.6.6にダウングレードすることにしました。
$ pip uninstall tensorflow
(tensorflowをアンインストール)
$ conda install python==3.6.6
(python3.6.6をインストール)
$ pip install tensorflow==1.11.0
(tensorflow1.11.0 CPU版をインストール)
$ pip install keras
これで、tensorflowがとりあえず動きました。
2020年02月23日
好みの顔を選ぶコピー人形(カスケード分類器)
こちらを参考に作業しました。
およそ2150枚の写真を
一枚一枚確認し、
好みの顔が写っている写真1197枚に対して、
ラベル付(ラベル情報の取得)を行いました。
ラベル情報はinfo.datに保存され、
それをもとにベクトル画像ファイルを生成します。
$ opencv_createsamples -info info.dat -c preferface.vec -num 1197
あっという間に、ベクトル画像データが出来上がりました。
次に、このベクトル画像ファイルと
さきほどの2150枚の画像を用いて、
好みの顔のカスケード分類器を作成します。
$ opencv_traincascade -data ./cascade/ -vec preferface.vec -bg bg.txt -numPos 950 -numNeg 903
ベクトル画像ファイル生成に用いた1197枚のおよそ8割程度(今回は950枚)を教師データにすると、ちょうどよいそうです。なお、好みの顔が写っていない写真を903枚準備しました。
さて、学習にはPCの性能にもよりますが、
私のPCでは30分以上かかりますので、一旦筆を置きます。
結局、2時間以上学習にかかりました。
PCさんおつかれさんです。
結果です。

3年B組さんです。
なんと、片寄くんが外れています。
これを本当に私のコピー人形と言っていいのかな?汗)
およそ2150枚の写真を
一枚一枚確認し、
好みの顔が写っている写真1197枚に対して、
ラベル付(ラベル情報の取得)を行いました。
ラベル情報はinfo.datに保存され、
それをもとにベクトル画像ファイルを生成します。
$ opencv_createsamples -info info.dat -c preferface.vec -num 1197
あっという間に、ベクトル画像データが出来上がりました。
次に、このベクトル画像ファイルと
さきほどの2150枚の画像を用いて、
好みの顔のカスケード分類器を作成します。
$ opencv_traincascade -data ./cascade/ -vec preferface.vec -bg bg.txt -numPos 950 -numNeg 903
ベクトル画像ファイル生成に用いた1197枚のおよそ8割程度(今回は950枚)を教師データにすると、ちょうどよいそうです。なお、好みの顔が写っていない写真を903枚準備しました。
さて、学習にはPCの性能にもよりますが、
私のPCでは30分以上かかりますので、一旦筆を置きます。
結局、2時間以上学習にかかりました。
PCさんおつかれさんです。
結果です。

3年B組さんです。
なんと、片寄くんが外れています。
これを本当に私のコピー人形と言っていいのかな?汗)
タグ:カスケード分類器
好みの顔
日本結婚相談所連盟HPによれば、
人工知能を使うことで、
自分がお相手のプロフィールを見なくても、
良いお相手を探し出してくれるそうです。
これを読んでいるうちに、
「自分の好みの顔を選び出す」カスケード分類器を
作ってみたくなりました。
これで、私がいなくても、私の好みの顔を選び出します。
(なお、あくまで好みの顔なので、
その顔の方と友達になりたいか、お付き合いしたいか等の観点は入っていません。)
本ブログで紹介した開発環境を用いて、
現在、作成中。作業には
こちらを参考にしています。
最終的に、favariteface_cascade.xml を作成することが目的です。
只今、ダウンロードした膨大な数の写真を一枚一枚見て、
好みの顔があった場合に、ラベルづけする作業を行っています。
1000枚近く見ましたが、
3時間くらいを費やしています。
人工知能を使うことで、
自分がお相手のプロフィールを見なくても、
良いお相手を探し出してくれるそうです。
これを読んでいるうちに、
「自分の好みの顔を選び出す」カスケード分類器を
作ってみたくなりました。
これで、私がいなくても、私の好みの顔を選び出します。
(なお、あくまで好みの顔なので、
その顔の方と友達になりたいか、お付き合いしたいか等の観点は入っていません。)
本ブログで紹介した開発環境を用いて、
現在、作成中。作業には
こちらを参考にしています。
最終的に、favariteface_cascade.xml を作成することが目的です。
只今、ダウンロードした膨大な数の写真を一枚一枚見て、
好みの顔があった場合に、ラベルづけする作業を行っています。
1000枚近く見ましたが、
3時間くらいを費やしています。
2020年02月19日
その9 scpでファイルの転送をする
複数のLan環境で、
複数のPCを操作できるようにすることで、
物理的に離れた場所からでも、
作業をやれるようにしています。
sshを用いたコマンドによる操作は、
不可欠ですが、
scpを使えばさらにはファイルの転送も可能です。
こちらを参考に、
ファイルをやり取りしてみました。
必要とするのは、
★リモート(電源つけっぱなしのUbuntu18.04)からローカル(移動中のスマホやPC)へのファイル転送です。
●ローカルからリモートへのファイル転送
$ scp ローカルファイルのPATH ユーザ名@ホスト名:/リモート先のPATH
●リモートからローカルへのファイル転送
$ scp ユーザ名@ホスト名:/リモート先のPATH ローカルファイルのPATH
●リモートからリモートへのファイル転送
$ scp ユーザ名@ホスト名:/リモート先のPATH ユーザ名@ホスト名:/リモート先のPATH
なお、
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
と警告が出て、ファイル転送ができないときは、
$ ssh-keygen -R ホスト名(IPアドレス)
を入力すると、一旦、環境がリセットされ、
改めて作業を行うと、ファイル転送ができるようになりました。
複数のPCを操作できるようにすることで、
物理的に離れた場所からでも、
作業をやれるようにしています。
sshを用いたコマンドによる操作は、
不可欠ですが、
scpを使えばさらにはファイルの転送も可能です。
こちらを参考に、
ファイルをやり取りしてみました。
必要とするのは、
★リモート(電源つけっぱなしのUbuntu18.04)からローカル(移動中のスマホやPC)へのファイル転送です。
●ローカルからリモートへのファイル転送
$ scp ローカルファイルのPATH ユーザ名@ホスト名:/リモート先のPATH
●リモートからローカルへのファイル転送
$ scp ユーザ名@ホスト名:/リモート先のPATH ローカルファイルのPATH
●リモートからリモートへのファイル転送
$ scp ユーザ名@ホスト名:/リモート先のPATH ユーザ名@ホスト名:/リモート先のPATH
なお、
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
と警告が出て、ファイル転送ができないときは、
$ ssh-keygen -R ホスト名(IPアドレス)
を入力すると、一旦、環境がリセットされ、
改めて作業を行うと、ファイル転送ができるようになりました。
2020年02月16日
PCに画像認識の学習をさせる
opencv_createsamples
opencv_traincascadeを利用して、
PCに画像認識の学習をさせてみました。
せっかくなので、
自分のプロフィール画像を認識する!?、
カスケード分類器を作りました。
こちらを参考に、以下の手順で学習させます。
①認識させたい画像を変形など様々な加工を繰り返し行い、1000枚の画像を生成します。
$ opencv_createsamples.exe -img ./ok/test.png -num 1000 -vec test.vec
(Ubuntuのコマンドで行う場合.exeはいりません)
②不正解画像と正解画像の違い(検出したいものの特徴)を抽出し
(これを「学習」といいます)、カスケード分類器を作成します。
$ opencv_traincascade.exe -data ./cascade/ -vec ./test.vec -bg ./ng/nglist.txt -numPos 800 -numNeg 67
不正解画像には綺麗な風景写真67枚を使用しました。
ステージ8で学習が中断となりましたが、
とりあえず、ステージ7までの学習結果に基づく、
カスケード分類器(プロフィール画像を認識する?もの)が
完成しました。
学習に要した時間は、わずか4分10秒でした。
随分と短い学習時間です。本当に分類できるのか?
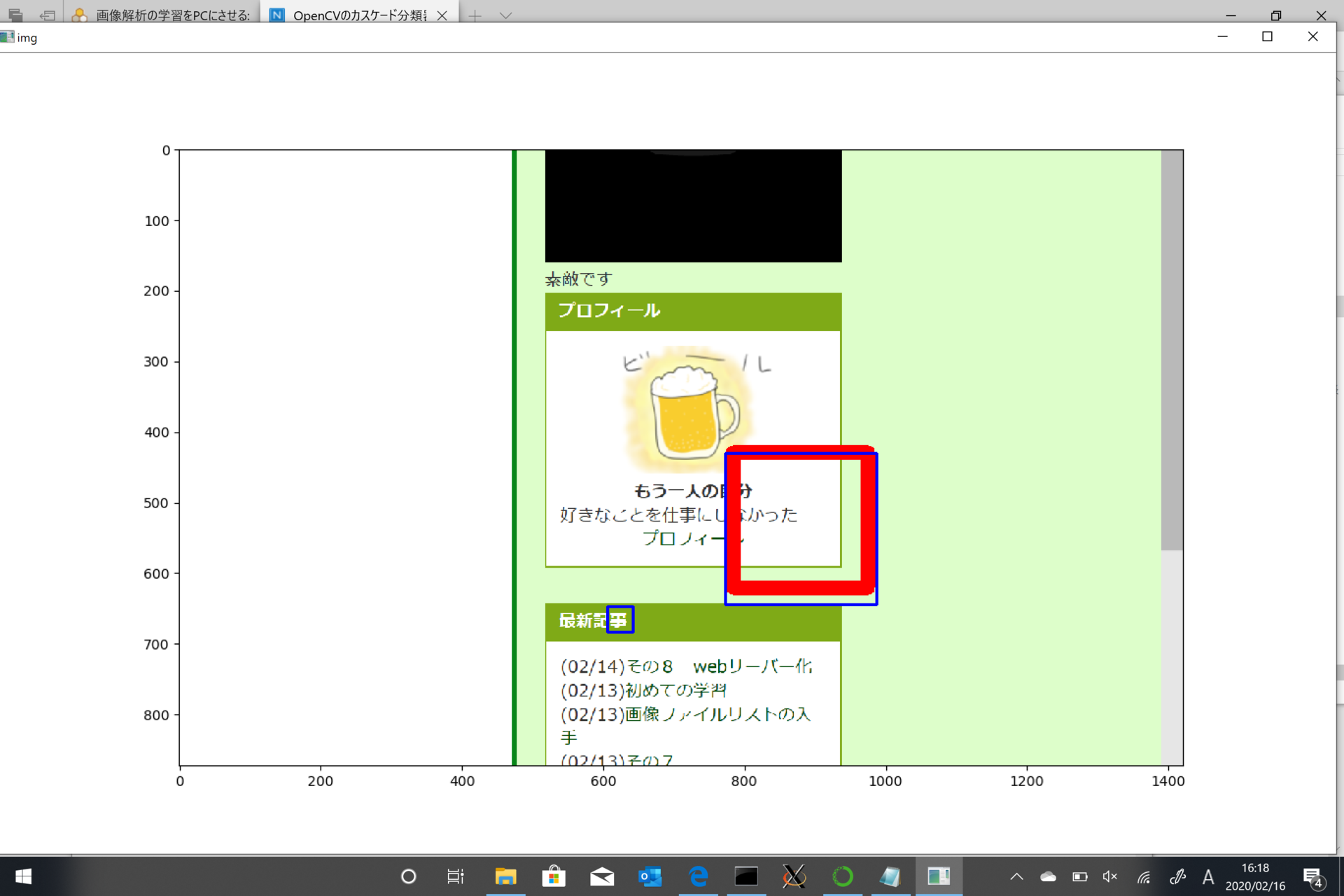
見事に失敗!!
たった4分の学習では足りなかったか。
まあ、不正解画像に対しては、「認識されません。」となったので、
見たことがない状況では間違ってしまうという感じでしょうか。
例えるなら、
過去問のとおりに、問題が出ていれば解けるが、
ちょっと、変えられるとダメ。みたいな感じか?もっと学習
opencv_traincascadeを利用して、
PCに画像認識の学習をさせてみました。
せっかくなので、
自分のプロフィール画像を認識する!?、
カスケード分類器を作りました。
こちらを参考に、以下の手順で学習させます。
①認識させたい画像を変形など様々な加工を繰り返し行い、1000枚の画像を生成します。
$ opencv_createsamples.exe -img ./ok/test.png -num 1000 -vec test.vec
(Ubuntuのコマンドで行う場合.exeはいりません)
②不正解画像と正解画像の違い(検出したいものの特徴)を抽出し
(これを「学習」といいます)、カスケード分類器を作成します。
$ opencv_traincascade.exe -data ./cascade/ -vec ./test.vec -bg ./ng/nglist.txt -numPos 800 -numNeg 67
不正解画像には綺麗な風景写真67枚を使用しました。
ステージ8で学習が中断となりましたが、
とりあえず、ステージ7までの学習結果に基づく、
カスケード分類器(プロフィール画像を認識する?もの)が
完成しました。
学習に要した時間は、わずか4分10秒でした。
随分と短い学習時間です。本当に分類できるのか?
見事に失敗!!
たった4分の学習では足りなかったか。
まあ、不正解画像に対しては、「認識されません。」となったので、
見たことがない状況では間違ってしまうという感じでしょうか。
例えるなら、
過去問のとおりに、問題が出ていれば解けるが、
ちょっと、変えられるとダメ。みたいな感じか?もっと学習
2020年02月14日
その8 webサーバー化
開発環境
・Ubuntu 18.04
・python 3.7.6
・conda 4.8.2
・opencv 4.2.0(root環境)
追加機能
・Apache 2.4.29
情報を
できる限り色々な手段で
保存しておいたほうが良いと
考えています。
そこで、いつでもどこでも
確認したい情報は、webサーバーに保存しておきます。
こちらを参考に導入しました。
これで、/var/www/html内に自分の作成したwebページを掲載できる。
・Ubuntu 18.04
・python 3.7.6
・conda 4.8.2
・opencv 4.2.0(root環境)
追加機能
・Apache 2.4.29
情報を
できる限り色々な手段で
保存しておいたほうが良いと
考えています。
そこで、いつでもどこでも
確認したい情報は、webサーバーに保存しておきます。
こちらを参考に導入しました。
$ sudo apt update
$ sudo apt upgrade
ufw(ファイアウォール)をインストール
$ sudo apt install ufw
インストール直後はufwはファイアウォールとして指定されないためufwを有効化
$ sudo ufw enable
「このコマンドを実行するとssh接続が切れるかも知れませんがいいですか?」と聞かれるので y を入力してEnter
sshのポートを開く
$ sudo ufw allow 22
Apacheが使用するポートを開く
$ sudo ufw allow 80
Apacheをインストールする
$ sudo apt install apache2
$ sudo apt install curl
Apacheが稼働している事を確認する
$ curl localhost && echo success || echo failed
successと表示されれば成功
サーバー化したフォルダの権限を変更
$ sudo chmod 777 /var/www/html
これで、/var/www/html内に自分の作成したwebページを掲載できる。