2021年05月30日
私を模倣しないAI(ゲーム編)その1(強化学習)
主な開発環境
・Ubuntu 18.04
・python 3.7.10
・tensorflow 1.14
・gym 0.15.7
・baselines
私を模倣しなくとも、命令に応じて何度(何万回)もゲームをプレイして学習し、
最終的に私を上回るゲームプレイ能力を持ってしまうのがAIのすごさです。
前回、私を模倣するAIを作成しました。
これは私のゲームプレイの実力に左右されます。
つまり、私が上手であれば、上手なAIになりますし、
私が下手であれば、それを模倣するので、いい感じで下手になります。
今回は、私を見本にせずに、
ひたすら(total_timesteps=5000000)強化学習(PPO2)を行ってAIを作成中です。
ゲームは同じくBreakout-v0です。
training.pyとして以下を保存し起動する。
import gym
import time
from stable_baselines import PPO2
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines.gail import ExpertDataset, generate_expert_traj
from baselines.common.atari_wrappers import *
from stable_baselines.bench import Monitor
# ログフォルダの生成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 環境の生成
env = gym.make('Breakout-v0')
env = MaxAndSkipEnv(env, skip=4) # 4フレームごとに行動を選択
env = WarpFrame(env) # 画面イメージを84x84のグレースケールに変換
env = Monitor(env, log_dir, allow_early_resets=True)
env = DummyVecEnv([lambda: env])
# モデルの生成
model = PPO2('CnnPolicy', env, verbose=1)
# モデルの学習
model.learn(total_timesteps=5000000)
# モデルの保存
model.save('breakout_model')
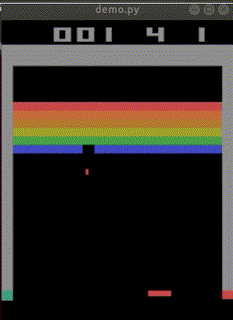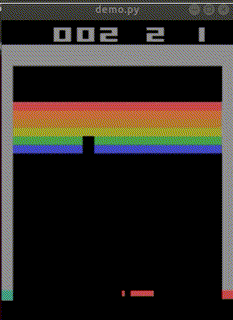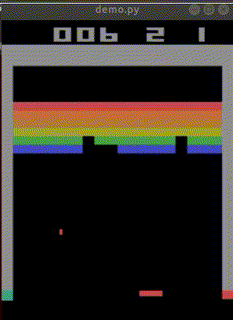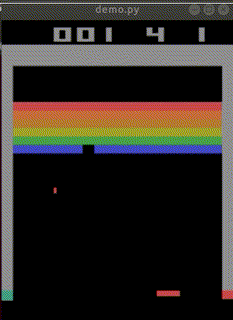
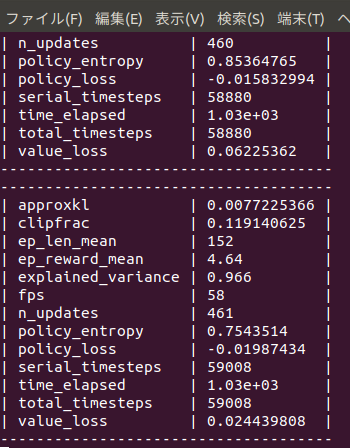
まだ学習途中ですが、
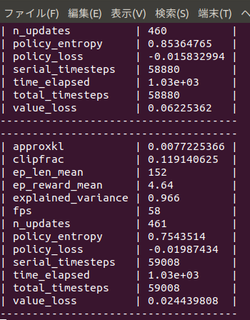
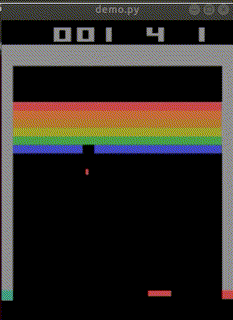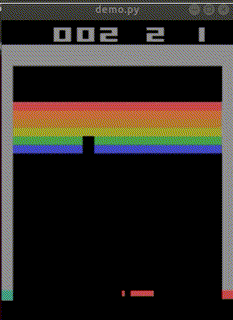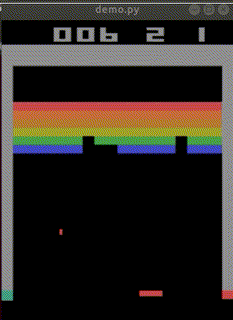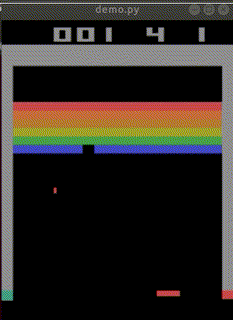
始めて10分でep_reward_mean=4を超えました。
4時間でep_reward_mean=9を超えるようになりました。
私のAIを追い抜きました。
悔しい・・・。
私の10年もののノートPCで500万回のtimestepsに24時間かかりました。
結局ep_reward_mean=10を超える程度のAIが出来上がりました。
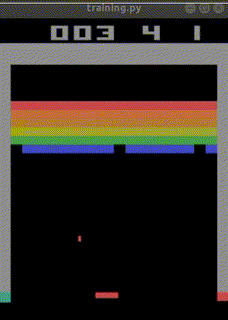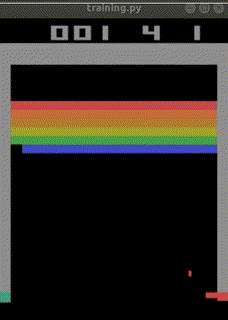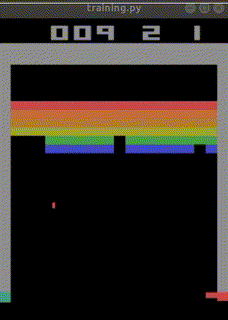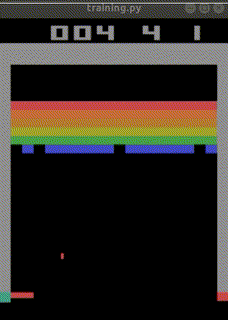
なお、下記のURLでは、
total_timesteps=30000000(3000万回)でほぼクリアまでたどり着く
人工知能ができあがったとも報告されています。
https://ktpcschool.hamazo.tv/e8255086.html
・Ubuntu 18.04
・python 3.7.10
・tensorflow 1.14
・gym 0.15.7
・baselines
私を模倣しなくとも、命令に応じて何度(何万回)もゲームをプレイして学習し、
最終的に私を上回るゲームプレイ能力を持ってしまうのがAIのすごさです。
前回、私を模倣するAIを作成しました。
これは私のゲームプレイの実力に左右されます。
つまり、私が上手であれば、上手なAIになりますし、
私が下手であれば、それを模倣するので、いい感じで下手になります。
今回は、私を見本にせずに、
ひたすら(total_timesteps=5000000)強化学習(PPO2)を行ってAIを作成中です。
ゲームは同じくBreakout-v0です。
training.pyとして以下を保存し起動する。
import gym
import time
from stable_baselines import PPO2
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines.gail import ExpertDataset, generate_expert_traj
from baselines.common.atari_wrappers import *
from stable_baselines.bench import Monitor
# ログフォルダの生成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 環境の生成
env = gym.make('Breakout-v0')
env = MaxAndSkipEnv(env, skip=4) # 4フレームごとに行動を選択
env = WarpFrame(env) # 画面イメージを84x84のグレースケールに変換
env = Monitor(env, log_dir, allow_early_resets=True)
env = DummyVecEnv([lambda: env])
# モデルの生成
model = PPO2('CnnPolicy', env, verbose=1)
# モデルの学習
model.learn(total_timesteps=5000000)
# モデルの保存
model.save('breakout_model')
まだ学習途中ですが、
始めて10分でep_reward_mean=4を超えました。
4時間でep_reward_mean=9を超えるようになりました。
私のAIを追い抜きました。
悔しい・・・。
私の10年もののノートPCで500万回のtimestepsに24時間かかりました。
結局ep_reward_mean=10を超える程度のAIが出来上がりました。
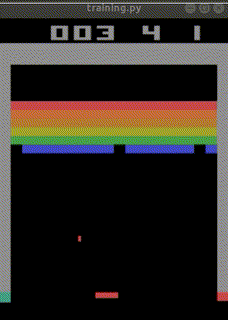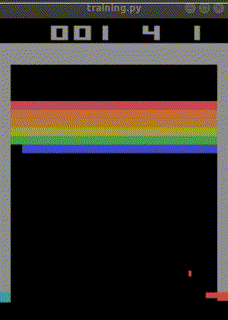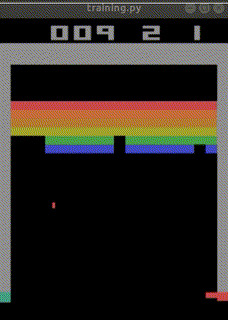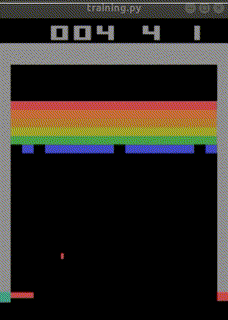
なお、下記のURLでは、
total_timesteps=30000000(3000万回)でほぼクリアまでたどり着く
人工知能ができあがったとも報告されています。
https://ktpcschool.hamazo.tv/e8255086.html
【このカテゴリーの最新記事】
-
no image
-

-
-

-