2021年06月19日
OpenAI Gymの環境を自作してみるを真似てみる
主な開発環境
・Windows 10
・python 3.7.0
・tensorflow 1.14.0
・gym 0.18.0
・pygame 2.0.1
・baselines
アタリのゲームを用いて強化学習してきましたが、
ある程度遊びつくすと、自作環境で強化学習をやってみたくなるのが
自然の流れかと。
探してみると、
自作環境と強化学習を紹介してくれているページがございました。
https://kagglenote.com/ml-tips/my-environment-with-gym/のページを参考にしました。
簡潔で無駄のないプログラミングで大変参考になります。
なんとなく、描画(render)をpygameで行いたくなり、ちょっとだけいじってみました。
簡潔でなく、無駄のあるプログラミングになりましたが、そこはご愛敬で。
$ mygym .
.
├── env.py
└── training.py
env.pyにpygameをインポートし、さらにdef render():を下記に変更
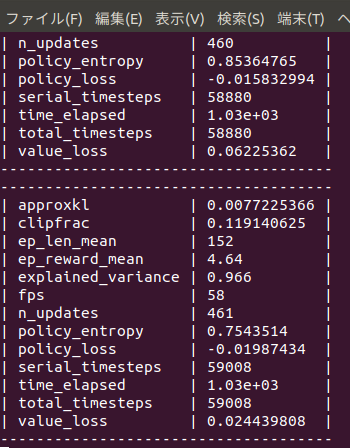
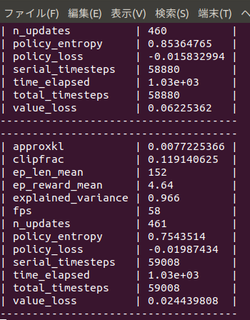
training.pyでは強化学習にPPO2を採用
下記の動画は紹介した内容以上に変更し、背景に海を表現しました。その方法は後日。
大海原で餌をみつけるカツオの人工知能が完成しました。
しかし、これは餌の場所をあらかじめ知ることができる環境で学習しており、
実際の海では、遠くにある餌の場所など知る由もありません。
一体どうやって餌をさがしているのでしょうか?匂い?

・Windows 10
・python 3.7.0
・tensorflow 1.14.0
・gym 0.18.0
・pygame 2.0.1
・baselines
アタリのゲームを用いて強化学習してきましたが、
ある程度遊びつくすと、自作環境で強化学習をやってみたくなるのが
自然の流れかと。
探してみると、
自作環境と強化学習を紹介してくれているページがございました。
https://kagglenote.com/ml-tips/my-environment-with-gym/のページを参考にしました。
簡潔で無駄のないプログラミングで大変参考になります。
なんとなく、描画(render)をpygameで行いたくなり、ちょっとだけいじってみました。
簡潔でなく、無駄のあるプログラミングになりましたが、そこはご愛敬で。
$ mygym .
.
├── env.py
└── training.py
env.pyにpygameをインポートし、さらにdef render():を下記に変更
import pygame
def render(self):
#clock.tick(60) # 60fps
self.screen=pygame.display.set_mode((WINDOW_WIDTH, WINDOW_HEIGHT))
pygame.display.set_caption("virtual_sea")
self.screen.fill((0,0,0))
img=pygame.image.load("./resource/katsuwo.bmp").convert()
colorkey = img.get_at((0,0)) # 左上の色を透明色に
img.set_colorkey(colorkey, RLEACCEL)
img=pygame.transform.scale(img, (100, 100))
img_rect = img.get_rect()
self.screen.blit(img,tuple(self.katsuwo_position))
pygame.draw.circle(self.screen, (255,0,0),tuple(self.goal_position), 5,5)
pygame.display.update()
training.pyでは強化学習にPPO2を採用
from stable_baselines import PPO2
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from env import MyEnv
env = MyEnv()
model = PPO2(MlpPolicy, env, verbose=1, tensorboard_log="log")
model.learn(total_timesteps=20000)
model.save("myenv_ppo2")
学習のためのtraining.pyは以下のとおり。
# モデルのテスト
# 10回試行する
for i in range(3):
obs = env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
if dones:
break
下記の動画は紹介した内容以上に変更し、背景に海を表現しました。その方法は後日。
大海原で餌をみつけるカツオの人工知能が完成しました。
しかし、これは餌の場所をあらかじめ知ることができる環境で学習しており、
実際の海では、遠くにある餌の場所など知る由もありません。
一体どうやって餌をさがしているのでしょうか?匂い?

【このカテゴリーの最新記事】
-
no image
-
-

-
-