新規記事の投稿を行うことで、非表示にすることが可能です。
2024年01月31日
NVIDIAのGeFORCE RTX搭載のPCを購入
タイトルのとおりです。
これまで、CPUのみでAI開発の遊びをおこなってきた貧乏人ですが、
とうとう、入手しました!、GPU搭載のPC!
これからは、GPU搭載のPCでのAI開発の遊びを
実体験をもとに紹介していきます。
これまで、CPUのみでAI開発の遊びをおこなってきた貧乏人ですが、
とうとう、入手しました!、GPU搭載のPC!
これからは、GPU搭載のPCでのAI開発の遊びを
実体験をもとに紹介していきます。
2024年01月04日
sudo service apache2 restart
ラズパイを再起動した際に、
必要に応じて、apache2の再起動も必要です。
備忘録として、コマンドを記載しておきます。
sudo service apache2 restart
必要に応じて、apache2の再起動も必要です。
備忘録として、コマンドを記載しておきます。
sudo service apache2 restart
2022年04月02日
openai gym 365/1
posted by もう一人の自分 at 18:43| openai gym
2021年09月14日
ubuntu 20.04 でconda 仮想環境ごとにjupyter notebookをつかうには
$ conda activate 仮想環境名
で仮想環境のコンソールを起動することができます。
機械学習のためには、
それぞれの仮想環境でtensorflowのバージョンを変更して利用したりできます。
起動したコンソール上では、指定したバージョンが稼働するのですが、
$ jupyter notebook
でバージョンを確認すると、インストールしたものと異なることがあります。
どうやら、jupyter notebookは、どれかの仮想環境上でtensorflowをインストールしたら
仮想環境を跨いで、起動できるようです。
そこで、それぞれの仮想環境にもjupyter notebookをインストールすることで
仮想環境ごとに、jupyter notebook上でも指定したバージョンのtensorflowモジュールを用いることができました。
方法は、
$ conda activate 仮想環境名
(仮想環境名)$ conda install jupyter
(仮想環境名)$ pip install jupyter notebook
これで、仮想環境上にインストールした特定のバージョンのものが利用できました。
で仮想環境のコンソールを起動することができます。
機械学習のためには、
それぞれの仮想環境でtensorflowのバージョンを変更して利用したりできます。
起動したコンソール上では、指定したバージョンが稼働するのですが、
$ jupyter notebook
でバージョンを確認すると、インストールしたものと異なることがあります。
どうやら、jupyter notebookは、どれかの仮想環境上でtensorflowをインストールしたら
仮想環境を跨いで、起動できるようです。
そこで、それぞれの仮想環境にもjupyter notebookをインストールすることで
仮想環境ごとに、jupyter notebook上でも指定したバージョンのtensorflowモジュールを用いることができました。
方法は、
$ conda activate 仮想環境名
(仮想環境名)$ conda install jupyter
(仮想環境名)$ pip install jupyter notebook
これで、仮想環境上にインストールした特定のバージョンのものが利用できました。
2021年06月20日
ラズパイでブラウザ画面をスクリーンショットして(メール送信)
主な開発環境
・Raspbian GNU/Linux 10 (buster)
「windy」 https://www.windy.com/って知っていますか?
風の予測を綺麗な映像にしたサービスです。
台風の予想や、出張の際の交通機関の運行状況を予測するのにうってつけです。
定期的に情報を入手するようにしています。
下記は、ラズパイで画像を取得し、メールで送るシステムです。
いらないと言えばいらないシステムですが、参考まで。^^
なお、メール送信の部分は追って紹介します。
・Raspbian GNU/Linux 10 (buster)
「windy」 https://www.windy.com/って知っていますか?
風の予測を綺麗な映像にしたサービスです。
台風の予想や、出張の際の交通機関の運行状況を予測するのにうってつけです。
定期的に情報を入手するようにしています。
下記は、ラズパイで画像を取得し、メールで送るシステムです。
いらないと言えばいらないシステムですが、参考まで。^^
#!/bin/sh
input=/home/pi/Pictures
export DISPLAY=:0
Xvfb :0 &
DISPLAY=:0 /usr/bin/chromium-browser https://www.windy.com/?gfs,$input2-21,27.000,140.000,5,i:pressure &
/usr/bin/scrot -d 60 -c $input/output7.png
/usr/bin/convert -crop 960x690+00+80 $input/output7.png $input/output7.png
/usr/bin/convert $input/output7.png -quality 20 $input/output7.jpg
/usr/bin/python3 /home/pi/mailtest.py
sleep 2
/usr/bin/pkill -o chromium
なお、メール送信の部分は追って紹介します。
2021年06月19日
OpenAI Gymの環境を自作してみるを真似てみる
主な開発環境
・Windows 10
・python 3.7.0
・tensorflow 1.14.0
・gym 0.18.0
・pygame 2.0.1
・baselines
アタリのゲームを用いて強化学習してきましたが、
ある程度遊びつくすと、自作環境で強化学習をやってみたくなるのが
自然の流れかと。
探してみると、
自作環境と強化学習を紹介してくれているページがございました。
https://kagglenote.com/ml-tips/my-environment-with-gym/のページを参考にしました。
簡潔で無駄のないプログラミングで大変参考になります。
なんとなく、描画(render)をpygameで行いたくなり、ちょっとだけいじってみました。
簡潔でなく、無駄のあるプログラミングになりましたが、そこはご愛敬で。
$ mygym .
.
├── env.py
└── training.py
env.pyにpygameをインポートし、さらにdef render():を下記に変更
training.pyでは強化学習にPPO2を採用
下記の動画は紹介した内容以上に変更し、背景に海を表現しました。その方法は後日。
大海原で餌をみつけるカツオの人工知能が完成しました。
しかし、これは餌の場所をあらかじめ知ることができる環境で学習しており、
実際の海では、遠くにある餌の場所など知る由もありません。
一体どうやって餌をさがしているのでしょうか?匂い?

・Windows 10
・python 3.7.0
・tensorflow 1.14.0
・gym 0.18.0
・pygame 2.0.1
・baselines
アタリのゲームを用いて強化学習してきましたが、
ある程度遊びつくすと、自作環境で強化学習をやってみたくなるのが
自然の流れかと。
探してみると、
自作環境と強化学習を紹介してくれているページがございました。
https://kagglenote.com/ml-tips/my-environment-with-gym/のページを参考にしました。
簡潔で無駄のないプログラミングで大変参考になります。
なんとなく、描画(render)をpygameで行いたくなり、ちょっとだけいじってみました。
簡潔でなく、無駄のあるプログラミングになりましたが、そこはご愛敬で。
$ mygym .
.
├── env.py
└── training.py
env.pyにpygameをインポートし、さらにdef render():を下記に変更
import pygame
def render(self):
#clock.tick(60) # 60fps
self.screen=pygame.display.set_mode((WINDOW_WIDTH, WINDOW_HEIGHT))
pygame.display.set_caption("virtual_sea")
self.screen.fill((0,0,0))
img=pygame.image.load("./resource/katsuwo.bmp").convert()
colorkey = img.get_at((0,0)) # 左上の色を透明色に
img.set_colorkey(colorkey, RLEACCEL)
img=pygame.transform.scale(img, (100, 100))
img_rect = img.get_rect()
self.screen.blit(img,tuple(self.katsuwo_position))
pygame.draw.circle(self.screen, (255,0,0),tuple(self.goal_position), 5,5)
pygame.display.update()
training.pyでは強化学習にPPO2を採用
from stable_baselines import PPO2
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from env import MyEnv
env = MyEnv()
model = PPO2(MlpPolicy, env, verbose=1, tensorboard_log="log")
model.learn(total_timesteps=20000)
model.save("myenv_ppo2")
学習のためのtraining.pyは以下のとおり。
# モデルのテスト
# 10回試行する
for i in range(3):
obs = env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
if dones:
break
下記の動画は紹介した内容以上に変更し、背景に海を表現しました。その方法は後日。
大海原で餌をみつけるカツオの人工知能が完成しました。
しかし、これは餌の場所をあらかじめ知ることができる環境で学習しており、
実際の海では、遠くにある餌の場所など知る由もありません。
一体どうやって餌をさがしているのでしょうか?匂い?

2021年06月12日
私を模倣しないAI(ゲーム編)その3(強化学習その3)
主な開発環境
・Ubuntu 18.04
・python 3.7.10
・tensorflow 1.14
・gym 0.15.7
・baselines
強化学習その2を、
さらにtotal_timesteps=30000000
まで増やしてみました。
私の10年ものノートPCで、4日15時間(116時間)もかかりました。
(その後、別途250時間かけてtotal_timesteps=60000000もやってみました。)
月曜の朝から、金曜日の夜まで、ひたすらゲームの学習を行った計算になります。
時にscore=200に至るときもありますが、
めったにございません。まあ、こんなもんなんですかね。
実際に、強化学習をやってみると、
色々とわかることがありますね。
(total_timestep 左:3000万回 右:6000万回)
・Ubuntu 18.04
・python 3.7.10
・tensorflow 1.14
・gym 0.15.7
・baselines
強化学習その2を、
さらにtotal_timesteps=30000000
まで増やしてみました。
私の10年ものノートPCで、4日15時間(116時間)もかかりました。
(その後、別途250時間かけてtotal_timesteps=60000000もやってみました。)
月曜の朝から、金曜日の夜まで、ひたすらゲームの学習を行った計算になります。
時にscore=200に至るときもありますが、
めったにございません。まあ、こんなもんなんですかね。
実際に、強化学習をやってみると、
色々とわかることがありますね。
(total_timestep 左:3000万回 右:6000万回)
 |  |
2021年06月05日
私を模倣しないAI(ゲーム編)その2(強化学習その2)
主な開発環境
・Ubuntu 18.04
・python 3.7.10
・tensorflow 1.14
・gym 0.15.7
・baselines
前回の環境とモデルで学習させた結果、
結局、reward=10程度までしか、上達しませんでした。
もう少し、優秀な人工知能をつくろうと、
モデルをA2Cに、環境をmake_atari_envに、BreakoutのバージョンをNoFrameskip-v4に変えてみました。
学習時間は同じsteptimes=5000000です。。
私のノートPCで、学習に24時間ほどかかりました。
平均score=60まで上達しました。
私を模倣した人工知能よりは上手ですが、完全クリアまでに至りませんでした。

人工知能の能力は、アタリのゲームの半数以上において、人間が2時間プレー後に20回プレーした平均のスコアをこえるまでになっているそうです(https://qiita.com/ikeyasu/items/67dcddce088849078b85より)。
・Ubuntu 18.04
・python 3.7.10
・tensorflow 1.14
・gym 0.15.7
・baselines
前回の環境とモデルで学習させた結果、
結局、reward=10程度までしか、上達しませんでした。
もう少し、優秀な人工知能をつくろうと、
モデルをA2Cに、環境をmake_atari_envに、BreakoutのバージョンをNoFrameskip-v4に変えてみました。
学習時間は同じsteptimes=5000000です。。
私のノートPCで、学習に24時間ほどかかりました。
from stable_baselines.common.cmd_util import make_atari_env
from stable_baselines.common.policies import CnnPolicy
from stable_baselines.common.vec_env import VecFrameStack
from stable_baselines import A2C
env = make_atari_env('BreakoutNoFrameskip-v4', num_env=1, seed=0)
env = VecFrameStack(env, n_stack=4)
model = A2C(CnnPolicy, env, lr_schedule='constant', verbose=1, tensorboard_log="/tmp/a2c_breakout_tensorboard")
model.learn(total_timesteps=5000000)
model.save("breakout_a2c")
平均score=60まで上達しました。
私を模倣した人工知能よりは上手ですが、完全クリアまでに至りませんでした。

人工知能の能力は、アタリのゲームの半数以上において、人間が2時間プレー後に20回プレーした平均のスコアをこえるまでになっているそうです(https://qiita.com/ikeyasu/items/67dcddce088849078b85より)。
2021年05月30日
私を模倣しないAI(ゲーム編)その1(強化学習)
主な開発環境
・Ubuntu 18.04
・python 3.7.10
・tensorflow 1.14
・gym 0.15.7
・baselines
私を模倣しなくとも、命令に応じて何度(何万回)もゲームをプレイして学習し、
最終的に私を上回るゲームプレイ能力を持ってしまうのがAIのすごさです。
前回、私を模倣するAIを作成しました。
これは私のゲームプレイの実力に左右されます。
つまり、私が上手であれば、上手なAIになりますし、
私が下手であれば、それを模倣するので、いい感じで下手になります。
今回は、私を見本にせずに、
ひたすら(total_timesteps=5000000)強化学習(PPO2)を行ってAIを作成中です。
ゲームは同じくBreakout-v0です。
training.pyとして以下を保存し起動する。
import gym
import time
from stable_baselines import PPO2
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines.gail import ExpertDataset, generate_expert_traj
from baselines.common.atari_wrappers import *
from stable_baselines.bench import Monitor
# ログフォルダの生成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 環境の生成
env = gym.make('Breakout-v0')
env = MaxAndSkipEnv(env, skip=4) # 4フレームごとに行動を選択
env = WarpFrame(env) # 画面イメージを84x84のグレースケールに変換
env = Monitor(env, log_dir, allow_early_resets=True)
env = DummyVecEnv([lambda: env])
# モデルの生成
model = PPO2('CnnPolicy', env, verbose=1)
# モデルの学習
model.learn(total_timesteps=5000000)
# モデルの保存
model.save('breakout_model')
まだ学習途中ですが、
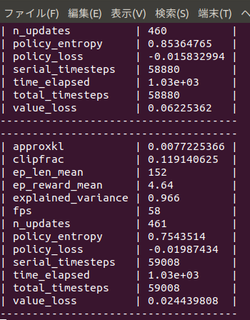
始めて10分でep_reward_mean=4を超えました。
4時間でep_reward_mean=9を超えるようになりました。
私のAIを追い抜きました。
悔しい・・・。
私の10年もののノートPCで500万回のtimestepsに24時間かかりました。
結局ep_reward_mean=10を超える程度のAIが出来上がりました。
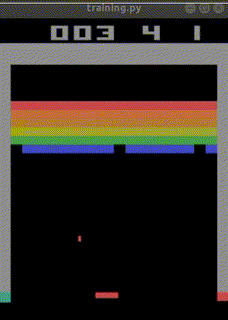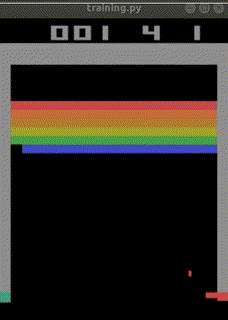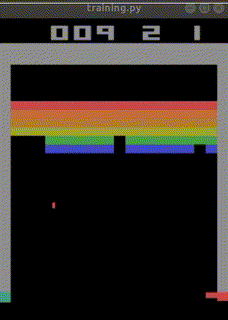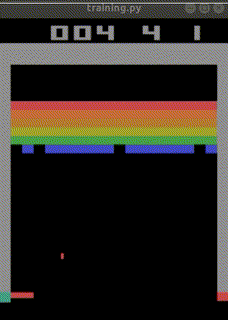
なお、下記のURLでは、
total_timesteps=30000000(3000万回)でほぼクリアまでたどり着く
人工知能ができあがったとも報告されています。
https://ktpcschool.hamazo.tv/e8255086.html
・Ubuntu 18.04
・python 3.7.10
・tensorflow 1.14
・gym 0.15.7
・baselines
私を模倣しなくとも、命令に応じて何度(何万回)もゲームをプレイして学習し、
最終的に私を上回るゲームプレイ能力を持ってしまうのがAIのすごさです。
前回、私を模倣するAIを作成しました。
これは私のゲームプレイの実力に左右されます。
つまり、私が上手であれば、上手なAIになりますし、
私が下手であれば、それを模倣するので、いい感じで下手になります。
今回は、私を見本にせずに、
ひたすら(total_timesteps=5000000)強化学習(PPO2)を行ってAIを作成中です。
ゲームは同じくBreakout-v0です。
training.pyとして以下を保存し起動する。
import gym
import time
from stable_baselines import PPO2
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines.gail import ExpertDataset, generate_expert_traj
from baselines.common.atari_wrappers import *
from stable_baselines.bench import Monitor
# ログフォルダの生成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 環境の生成
env = gym.make('Breakout-v0')
env = MaxAndSkipEnv(env, skip=4) # 4フレームごとに行動を選択
env = WarpFrame(env) # 画面イメージを84x84のグレースケールに変換
env = Monitor(env, log_dir, allow_early_resets=True)
env = DummyVecEnv([lambda: env])
# モデルの生成
model = PPO2('CnnPolicy', env, verbose=1)
# モデルの学習
model.learn(total_timesteps=5000000)
# モデルの保存
model.save('breakout_model')
まだ学習途中ですが、
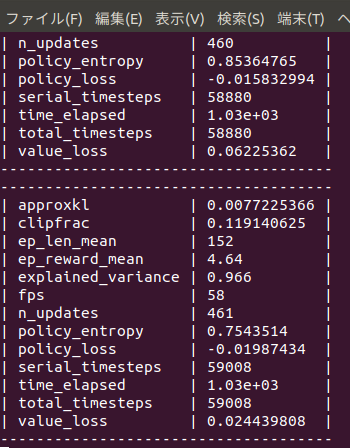
始めて10分でep_reward_mean=4を超えました。
4時間でep_reward_mean=9を超えるようになりました。
私のAIを追い抜きました。
悔しい・・・。
私の10年もののノートPCで500万回のtimestepsに24時間かかりました。
結局ep_reward_mean=10を超える程度のAIが出来上がりました。
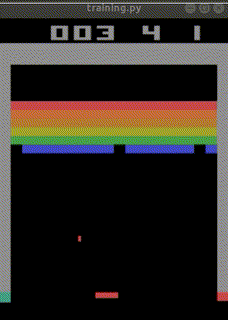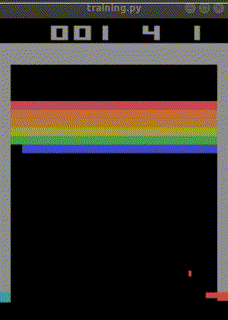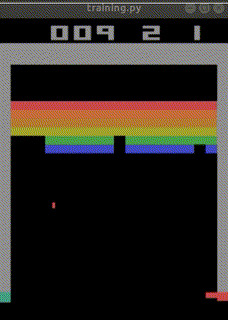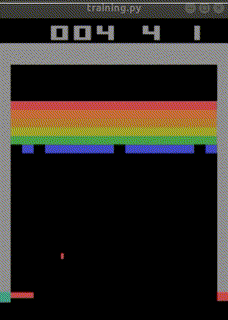
なお、下記のURLでは、
total_timesteps=30000000(3000万回)でほぼクリアまでたどり着く
人工知能ができあがったとも報告されています。
https://ktpcschool.hamazo.tv/e8255086.html
私を模倣するAI(ゲーム編)その2(模倣学習)
主な開発環境
・Raspbian GNU/Linux 10 (buster)
・python 3.7.3
・tensorflow 1.13.1(1.14.0ではtensorflow.cotribがみつかりませんとエラーが出ます)
・gym 0.15.7
・baselines
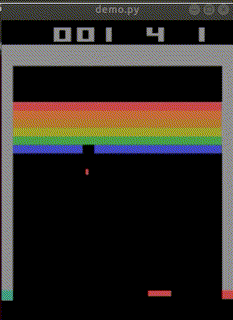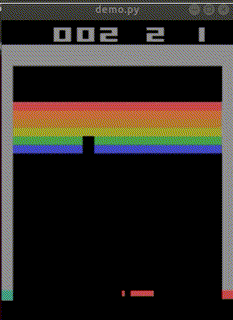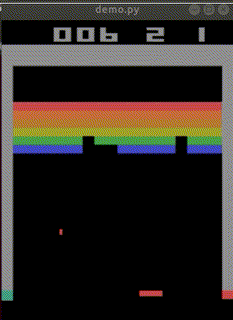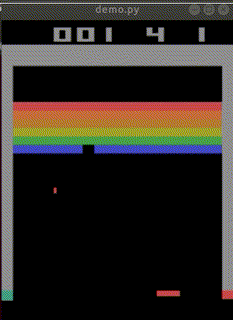
その1 で私がゲームをしたものがdemoとして出力されます。
それを読み込んで、模倣学習し、モデルとします。
https://ailog.site/2020/05/18/0518/を参考にしました。
以下は、私のdemoのみを利用するように変更した箇所です。
env = gym.make('Breakout-v0') #Breakout-v0に変更
env = MaxAndSkipEnv(env, skip=1) # 1フレームごとに行動を選択
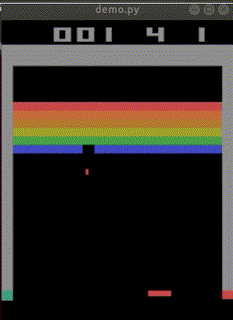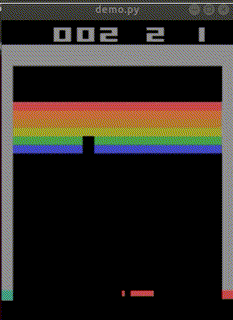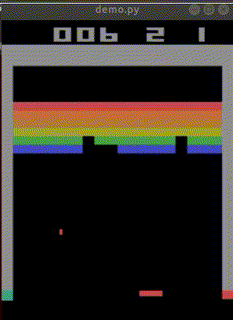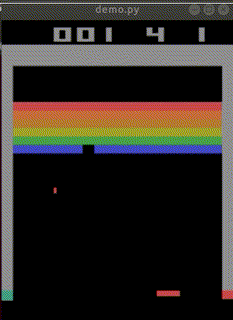
完成した「私を模倣したAI」はbreakout_modelとして保存されました。
私のノートパソコンでは、CPUしか使えないのですが、
モデルの生成に約6時間くらいかかりました。
なお、クリアできた見本は1回もありませんでした。
下手なところが、私らしい…。
平均score=4.63(n=30)でした。
・Raspbian GNU/Linux 10 (buster)
・python 3.7.3
・tensorflow 1.13.1(1.14.0ではtensorflow.cotribがみつかりませんとエラーが出ます)
・gym 0.15.7
・baselines
その1 で私がゲームをしたものがdemoとして出力されます。
それを読み込んで、模倣学習し、モデルとします。
https://ailog.site/2020/05/18/0518/を参考にしました。
以下は、私のdemoのみを利用するように変更した箇所です。
env = gym.make('Breakout-v0') #Breakout-v0に変更
env = MaxAndSkipEnv(env, skip=1) # 1フレームごとに行動を選択
完成した「私を模倣したAI」はbreakout_modelとして保存されました。
私のノートパソコンでは、CPUしか使えないのですが、
モデルの生成に約6時間くらいかかりました。
なお、クリアできた見本は1回もありませんでした。
下手なところが、私らしい…。
平均score=4.63(n=30)でした。