新規記事の投稿を行うことで、非表示にすることが可能です。
2018年04月07日
《その358》float型の内部表現
float型の内部表現
float型のサイズは、通常 4バイト(32ビット)です。
下記のプログラムでは、3つの float型実数、
-12.75
16.5
0.0625
について、各値がどのような内部表現で格納されているかを調べるために、実際の記憶域のビットの並びを画面に出力しています。
float型の実際の内部表現は、下記のプログラムの出力結果で確認できますが、その前に、
-12.75 を例に、内部表現を表現ルールに従って導いてみたいと思います。
前述しましたように、一般的な環境においては、1つの float型浮動小数点数を表現するのに、コンピュータ内部で 32ビットが使われます。
00000000 00000000 00000000 00000000
32ビットを上記のように表すと、
・最初の 1ビット(0 で表した部分)は、符号
・次の 8ビット(0 で表した部分)は、指数部
・残りの 23ビット(0 で表した部分)は、仮数部
という構成になっています。
-12.75 は負の数ですから、最初の符号ビットは
1
です。
次に、12.75 を 2進表記で表すと、
1100.11
すなわち
1.10011 × (2 の 3乗)
です。
指数部には、指数に 127 を加えて格納するルールになっています。
したがって
3 + 127 = 130
130 の 2進表記は
10000010
で、これが指数部になります。
次に仮数部ですが、
1.10011 の整数部分を省き、
10011 を格納するルールです。
仮数部は 23ビットありますから、
1001100 00000000 00000000
となり、これが仮数部です。
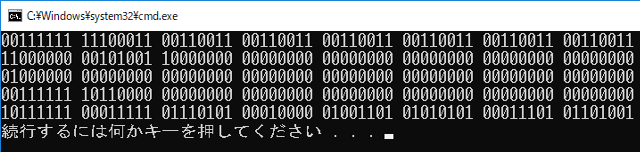
以上より、float型 −12.75 は、コンピュータ内部に、
11000001 01001100 00000000 00000000
という表現で格納されます。
この内部表現は、下記のプログラムの出力結果と一致します。
以下は、プログラムです。実際の記憶域のビットの並びを画面に出力します。
#include <string>
#include <iostream>
using namespace std;
const unsigned bits
= numeric_limits<unsigned char>::digits;
string bits_of(char x) {
string temp;
for (unsigned i = 0; i < bits; i++) {
if ((x >> i) & 1U)
temp = '1' + temp;
else
temp = '0' + temp;
}
temp += '\0';
return temp;
}
void func(float& ref) {
char* ptr = reinterpret_cast<char*>(&ref);
string x;
for (int i = 0;
i < sizeof(float) / sizeof(char);
i++
)
x = bits_of(*(ptr + i)) + x;
cout << x << '\n';
}
int main() {
float x;
x = -12.75; func(x);
x = 16.5; func(x);
x = 0.0625; func(x);
}

《その357》double型の内部表現(3)
double型の内部表現
本ブログの《350》double型の内部表現(2)では、数値の内部表現構造を、内部表現の表現ルールに従って、作成しました。
しかし、ルールに基づいて作成した内部構造が、実際の内部構造と一致しているかどうかの確認は、まだ行っていません。
そこで今回は、実際の内部構造を調べて、本ブログ《350》の結果と一致するかどうかを調べます。
本ブログ《350》のときと同様の値、
0.6
-12.75
2.0
0.0625
-0.00012
について、実際の内部構造を確認します。
下記のプログラムでは、前回《356》と同様の考え方を使っています。
前回は、ビットの並びを表す string型文字列の作成を、 main関数で行っていましたが、今回のプログラムでは、関数 func で行うようにした点だけが異なります。
以下は、プログラムです。出力結果を比較すると、本ブログ《350》の結果と一致していることがわかります。
#include <string>
#include <iostream>
using namespace std;
const unsigned bits
= numeric_limits<unsigned char>::digits;
string bits_of(char x) {
string temp;
for (unsigned i = 0; i < bits; i++) {
if ((x >> i) & 1U)
temp = '1' + temp;
else
temp = '0' + temp;
}
temp += '\0';
return temp;
}
void func(double& ref) {
char* ptr = reinterpret_cast<char*>(&ref);
string x;
for (int i = 0;
i < sizeof(double) / sizeof(char);
i++
)
x = bits_of(*(ptr + i)) + x;
cout << x << '\n';
}
int main() {
double x;
x = 0.6; func(x);
x = -12.75; func(x);
x = 2.0; func(x);
x = 0.0625; func(x);
x = -0.00012; func(x);
}
《その356》エンディアン
リトルエンディアン・ビッグエンディアン
double型の内部表現では 64ビットが使われています。
前回《355》、double型データの 64ビットを、8ビットずつ順に読み取って、8個のchar型データを作成し、そのビットの並びを文字列に変換しました。そして、その8個のchar型データ(8ビット)をつなぎ合わせて、double型データの並びを表す文字列を作りましたが、
その際の、char型データ文字列のつなぎ方は、処理系に依存します。
前回《355》の例でいうと、8バイトのdouble型データが、下位バイトが低アドレス側に配置される形式で格納されているのか、その逆であるのかが、処理系に依存するということです。
・下位バイトが低アドレスをもつ方式は リトルエンディアン
・下位バイトが高アドレスをもつ方式は ビッグエンディアン
と呼ばれています。
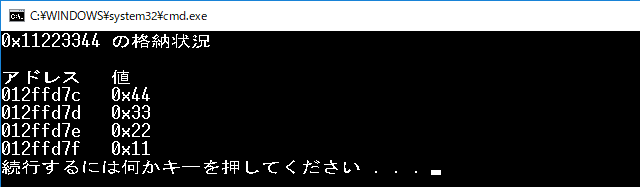
次のプログラムは、自分の使っている処理系が、そのどちらなのかを調べるためのものです。この出力結果から、リトルエンディアンであることがわかりました。
#include <iomanip>
#include <iostream>
using namespace std;
int main() {
const unsigned long bits
= numeric_limits<unsigned char>::digits;
const int n = sizeof(int) / sizeof(char);
int x = 0x11223344;
cout << hex << showbase;
cout << x << " の格納状況\n\n";
char* p = (char*)&x;
cout << "アドレス 値\n";
for (int i = 0; i < n; i++) {
cout << noshowbase << setw(8)
<< setfill('0')
<< reinterpret_cast<int>((p + i))
<< " ";
cout << showbase
<< static_cast<int>(*(p + i))
<< '\n';
}
}