2018年04月07日
《その356》エンディアン
リトルエンディアン・ビッグエンディアン
double型の内部表現では 64ビットが使われています。
前回《355》、double型データの 64ビットを、8ビットずつ順に読み取って、8個のchar型データを作成し、そのビットの並びを文字列に変換しました。そして、その8個のchar型データ(8ビット)をつなぎ合わせて、double型データの並びを表す文字列を作りましたが、
その際の、char型データ文字列のつなぎ方は、処理系に依存します。
前回《355》の例でいうと、8バイトのdouble型データが、下位バイトが低アドレス側に配置される形式で格納されているのか、その逆であるのかが、処理系に依存するということです。
・下位バイトが低アドレスをもつ方式は リトルエンディアン
・下位バイトが高アドレスをもつ方式は ビッグエンディアン
と呼ばれています。
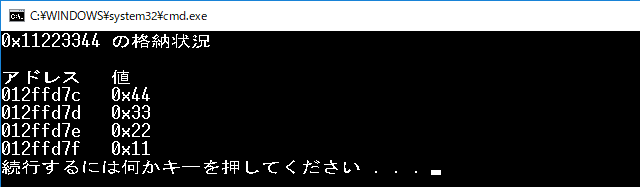
次のプログラムは、自分の使っている処理系が、そのどちらなのかを調べるためのものです。この出力結果から、リトルエンディアンであることがわかりました。
#include <iomanip>
#include <iostream>
using namespace std;
int main() {
const unsigned long bits
= numeric_limits<unsigned char>::digits;
const int n = sizeof(int) / sizeof(char);
int x = 0x11223344;
cout << hex << showbase;
cout << x << " の格納状況\n\n";
char* p = (char*)&x;
cout << "アドレス 値\n";
for (int i = 0; i < n; i++) {
cout << noshowbase << setw(8)
<< setfill('0')
<< reinterpret_cast<int>((p + i))
<< " ";
cout << showbase
<< static_cast<int>(*(p + i))
<< '\n';
}
}
この記事へのコメント
コメントを書く
この記事へのトラックバックURL
https://fanblogs.jp/tb/7523312
※ブログオーナーが承認したトラックバックのみ表示されます。
この記事へのトラックバック

