�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
�L��
�V�K�L���̓��e���s�����ƂŁA��\���ɂ��邱�Ƃ��\�ł��B
posted by fanblog
2020�N05��17��
Kaggle�F�f�[�^�T�C�G���X�p�̃t���[�f�[�^
�f�[�^�T�C�G���X�p�̃t���[�f�[�^�B
�R���y�e�B�V�������J����Ă�����A�R�~���j�e�B����������Ǝ���w�K�ɂ͂����Ă��H
https://www.kaggle.com/
�R���y�e�B�V�������J����Ă�����A�R�~���j�e�B����������Ǝ���w�K�ɂ͂����Ă��H
https://www.kaggle.com/
�y���̃J�e�S���[�̍ŐV�L���z
-
no image
-
no image
-
no image
-
no image
-
no image
2020�N04��26��
2020�N04��19��
Speech to Text�iIBM Watson�j
�E�����F����API
�E�������Ȃ�A�����Ŏg����i�����j
�f����i���{��j
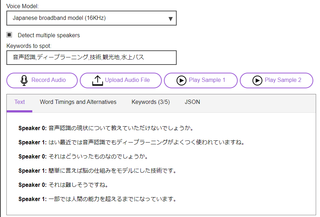
���W�I�����ǂ܂���Ƃ���Ȋ����B
Speaker 1: �����Ȃ��B
Speaker 1: �����{���ɂ��낢���l��l���ǂ�B
Speaker 1: �ǂ��܂ł����낤�Ȃ��Ďv���Ă˒m��Ȃ��l�ł��B
Speaker 0: ����B
Speaker 0: �����ȂU��Ԃ��ċx�݂��Ă����ł͂��̃����o�[����Ȃ��ƂȂ��B
Speaker 1: �R���B
Speaker 3: �������B
Speaker 0: ����Ȃ��Ƃ������g���Đ�ɏo����Ă��Ƃł���́B
Speaker 1: �����B
Speaker 0: ���������ł��ł����ɂł���ǂ�����āB
Speaker 0: ����B
Speaker 3: ���낻������Ȃ�ł��B
Speaker 1: ���߂̂���������Ƃ���B
Speaker 3: ���߂āB
Speaker 0: ���̈��݉�̂Ƃ������Ƃ���ŁB
Speaker 3: ���낻��j�A�ꕁ�ʂɁB
�b��2�l�̓��e�����A4�l���鈵���ɂȂ�����A���{��I�ɂ��������Ƃ�������邪�A
�����ނˉ����F���Ƃ��Ă͂ł��Ă����ہB
�����l�̉�b���b�ғ�����ł���Ƃ́AWatson������ׂ��B�B�B
�E�������Ȃ�A�����Ŏg����i�����j
�f����i���{��j
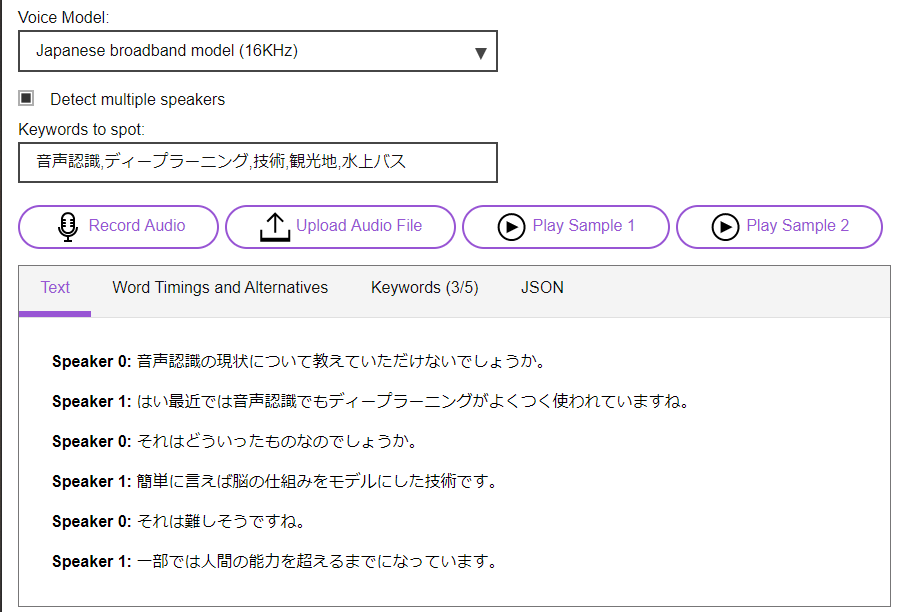
���W�I�����ǂ܂���Ƃ���Ȋ����B
Speaker 1: �����Ȃ��B
Speaker 1: �����{���ɂ��낢���l��l���ǂ�B
Speaker 1: �ǂ��܂ł����낤�Ȃ��Ďv���Ă˒m��Ȃ��l�ł��B
Speaker 0: ����B
Speaker 0: �����ȂU��Ԃ��ċx�݂��Ă����ł͂��̃����o�[����Ȃ��ƂȂ��B
Speaker 1: �R���B
Speaker 3: �������B
Speaker 0: ����Ȃ��Ƃ������g���Đ�ɏo����Ă��Ƃł���́B
Speaker 1: �����B
Speaker 0: ���������ł��ł����ɂł���ǂ�����āB
Speaker 0: ����B
Speaker 3: ���낻������Ȃ�ł��B
Speaker 1: ���߂̂���������Ƃ���B
Speaker 3: ���߂āB
Speaker 0: ���̈��݉�̂Ƃ������Ƃ���ŁB
Speaker 3: ���낻��j�A�ꕁ�ʂɁB
�b��2�l�̓��e�����A4�l���鈵���ɂȂ�����A���{��I�ɂ��������Ƃ�������邪�A
�����ނˉ����F���Ƃ��Ă͂ł��Ă����ہB
�����l�̉�b���b�ғ�����ł���Ƃ́AWatson������ׂ��B�B�B
2020�N01��25��
Python�ŕϐ��̃������g�p�ʂ��݂�
�@�f�[�^���͂�Python�𗘗p���Ă���Ƃ��ɁA�������[�G���[�����������B�ǂ����̕ϐ��ŁA�������[���[�O���Ă���悤�������̂ŁA���ו��̊o���������������Ă����B
���R�[�h
�@�@getsizeof�𗘗p����
�@https://qiita.com/takahiro_itazuri/items/5013818ff2e3fb2367f9
�@�A�z��T�C�Y���擾����i�O���[�o���ϐ��ƃ��[�J���ϐ����w��\�j
�@https://qiita.com/AnchorBlues/items/46c6d93c60abc7e35ef6
���R�[�h
�@�@getsizeof�𗘗p����
�@https://qiita.com/takahiro_itazuri/items/5013818ff2e3fb2367f9
�@�A�z��T�C�Y���擾����i�O���[�o���ϐ��ƃ��[�J���ϐ����w��\�j
�@https://qiita.com/AnchorBlues/items/46c6d93c60abc7e35ef6
2019�N11��17��
Android 10
Android 10
�T�v
�@5G�f�o�C�X�̃A�v���g���A���̔F�V�X�e���A�Z�L�����e�B�̋����A�܂��݃f�o�C�X�ւ̊g���ANNAPI1.2�Ή��ȂǗl�X�ȕύX�_��������Ă��܂��B
�@��ȓ����Ƃ��ẮA3�̍��ڂ�����܂��B
�|�C���g
1.�v���C�o�V�[�ی�̌���
�E�Ώ۔͈͕ʃX�g���[�W
�E�ʒu���̗��p���ɑ��郆�[�U����̋���
�E�o�b�N�O���E���h����̃A�N�e�B�r�e�B�̋N��
�E�Đݒ�s�\�ȃn�[�h�E�F�AID
�E���C�����X�X�L�����Ɋւ��錠��
2. ����̕ύX�_
�A�v���̈��萫�ƌ݊����̊m�ۂ̂��߂�Android 9�iAPI Level 28�j����A�������ύX�_������܂��B
�E�W�F�X�`���[�i�r�Q�[�V����
�ENDK
�ETLS1.3���f�t�H���g�L��
�ȂǗl�X�ȕύX�_���K�p����Ă��܂��B
3. �V�@�\
�E�܂��݃f�o�C�X�ւ̑Ή�
�E5G�l�b�g���[�N
�E�ʒm���̃X�}�[�g���v���C
�E�_�[�N�e�[�}
�E�W�F�X�`���[�i�r�Q�[�V����
�E�ݒ�p�l��
�E�J�����ƃ��f�B�A
���ɂ��l�X�ȏ�o�Ă��܂��B
�ڍׂ́AGoogle�̌����T�C�g���m�F���Ă݂Ă��������B
�iGoogle Developers���������j
---
�y�֘A�L���z
---
�y�X�V�����z
191117�F�V�K�쐬
�w�j�L�r�W���P�A�x�G�X�e�̌�
2019�N04��05��
Android Q�i���j
Android Q�i���j
�T�v
�uAndroid Q�v�́A������� Android OS �̂悤�ł��B
�|�C���g
�v���C�o�V�[�ی�̌���
�E�t�@�C���̈Í���
�E�@�����ւ̃A�N�Z�X����O�ɋ����K�v
�E�����o�b�N�A�b�v
�Ȃǂ̃��[�U�ی�Ɋւ���@�\�����L���lj������悤�ł��B
���[�U�̈ʒu���̊Ǘ�����
�E�A�v�������ʒu�����擾�ł��邩���ڍׂɐ���\
�@�A�v�����s���A�펞�Ȃǂ̑I�����ł���悤��
���̂ق��̃v���C�o�V�[�ی�
�E�l���̕ی�@�\���g�[���Ă��܂�
�܂��݃X�N���[���ȂǑ��ʃf�o�C�X�ւ̗�������
�E�}���`��ʂȂǂ̑��쐫�����シ��悤�ł�
���̂ق�
�E�V���[�g�J�b�g�̃��[�U���L
�E�ݒ�p�l���̌���
�EAPI�̒lj��ɂ��ڑ�������
�EP2P�y�уC���^�[�l�b�g�ڑ��̌���
�E�J�������\�̌���
�EAPI�p�t�H�[�}���X�̌���
���ɂ��l�X�ȏ�o�Ă��܂��B
�ڍׂ́AGoogle�̌����T�C�g���m�F���Ă݂Ă��������B
�iGoogle Developers���������j
---
�y�֘A�L���z
---
�y�X�V�����z
190405�F�V�K�쐬

�z�[���y�[�W���쐬����Ȃ��O�[�y
2019�N01��27��
���R���ꏈ���iCOTOHA API�j�̃A�b�v�f�[�g�i2019.01.15�`�j
COTOHA
�lj�����
NTT�R�~���j�P�[�V�����Y�ŏЉ��Ă���悤�ɁACOTOHA API�ɋ@�\���lj�����܂����B�i�����T�C�g�j
�lj����ꂽ���ڂ́A����4���ڂł��B
2�́A�����F���V�X�e���ւ̓����������ӎ����Ă���@�\�Ɏv���܂��B
�c��2�͔ėp�I�ȋ@�\�Ǝv���܂��B
�A���N�T�Ȃlj����F���A�v���P�[�V�����J���ɂ��A���p�������Ă���Ǝv���܂��B
1. �������ݏ����i���Łj
�@���t���l�܂��ďo�Ă��Ȃ��ۂɁA���b����u�����Ɓv��u���̂��v�Ƃ������\���������ł���@�\�ł��B
�@���͂��������猾�����ݕ\������������܂��B
�@�Ⴆ�A�u�����ƁA�����̓V�C�͐���ł��B�v�Ɠ��͂����ꍇ�A�u�����ƁA�v���������ݕ\���Ƃ��Č��o���邱�Ƃ��\�ƂȂ�@�\�ł��B
2. �����F����茟�m�i���Łj
�@�����F�������e�L�X�g�f�[�^�ɔF���~�X�����邩�����o�E���o���邱�Ƃ��ł���@�\�ł��B
�@�F���~�X�Ǝv����P����o�͂��Ă����@�\�ł��B
�@����A�����F����������API���lj��\��Ƃ������ƂȂ̂ŁA�������o�{�����������ꊇ�ōs�����Ƃ��\�ƂȂ邩������܂���B
3. ����́i�����Łj
�@������́A�����łƂȂ����@�\�ł��B���͂��\�����Ă��銴����u�|�W�e�B�u�v�u�l�K�e�B�u�v�Ɣ��肷�邱�Ƃ��ł��܂��Byahoo�̃��A���^�C�������̉�ʂŁA�����������ɂȂ������Ƃ������������Ǝv���܂��B
�@�Ⴆ�A���i�Ȃǂ̃��r���[��͂ւ̉��p�������悤�Ɏv���܂��B���[�U�����ɕs���������Ă��邩�A���ɗ��_�����������������I�ɉ�͂ł����܂��B
4. �Ɖ���́i�����Łj
�@������u�������nj��t�v�̂悤�Ȏw����̌��m�ƁA�����̑Ώۂ���肷�邱�Ƃ��ł��܂��B
�@���ł��琳���łɂȂ������ƂŁA�����`�╡���P��ɂ��Ή��\�ɂȂ����悤�ł��B
�@���t�@�����X�ɗႪ����悤�ɁA�u���Y�͗F�l�ł��B�ނ̓X�e�[�L��H�ׂ��B�v�Ƃ���������͂��邱�ƂŁA�u���Y���ށv�Ɣ��肷�邱�Ƃ��\�ł��B
�I����
�@����̃A�b�v�f�[�g�Łu�����F���v�֘A��API���lj�����A�����F���̐��x����ɗ͂����Ă��邱�Ƃ��������܂��BYoutube�ł������\��������܂����A���x�Ƃ��Ă͖����Ɍ���Ɋ����Ȃ����e�ŁA���{��̉����F���̓���������Ă��܂��܂��B
�@COTOHA API�̐��\����ɂ͊��҂��������ł��B
�@�Ɖ���͂Ȃǂ��w�ԂȂ�A���̂悤�Ȗ{���������߂ł��B
������� �q�ꍀ�\���E�Ɖ��E�k�b�\���̉�� �i���R���ꏈ���V���[�Y�j [ �����w ] |
---
�y�֘A�L���z
�E���R���ꏈ���iCOTOHA API�j�̂��Љ�
---
�y�X�V�����z
190127�F�V�K�쐬
---
2018�N12��03��
COTOHA���g���Ă݂� �[�\����� v1�[
�\����� v1
�T�v
NTT Communications�����N������Ă��鎩�R���ꏈ����API�ł��i��������Q���j�B
�����̊ȒP�Ȑ����́A�������̋L������B
�\����͂��g���Ă݂�
�T���v������K�p���Ă݂܂��傤�B
�y���͕��z
���͕����B
�y���̓R�}���h�z
curl -X POST -H "Content-Type:application/json" -H "charset:UTF-8" -H "Authorization:Bearer [Access Token]" -d '{"sentence":"���͕����B","type": "default"}' "https://[API Base URL]/parse"
�y�o�́z
{ "result" : [ { "chunk_info" : { "id" : 0, "head" : 1, "dep" : "D", "chunk_head" : 1, "chunk_func" : 2, "links" : [ ] }, "tokens" : [ { "id" : 0, "form" : "", "kana" : "", "lemma" : "", "pos" : "Undef", "features" : [ ], "attributes" : { } }, { "id" : 1, "form" : "��", "kana" : "�C�k", "lemma" : "��", "pos" : "����", "features" : [ ], "dependency_labels" : [ { "token_id" : 0, "label" : "dep" }, { "token_id" : 2, "label" : "case" } ], "attributes" : { } }, { "id" : 2, "form" : "��", "kana" : "�n", "lemma" : "��", "pos" : "�A�p����", "features" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 1, "head" : -1, "dep" : "O", "chunk_head" : 0, "chunk_func" : 1, "links" : [ { "link" : 0, "label" : "object" } ], "predicate" : [ ] }, "tokens" : [ { "id" : 3, "form" : "��", "kana" : "�A��", "lemma" : "����", "pos" : "�����ꊲ", "features" : [ "K" ], "dependency_labels" : [ { "token_id" : 1, "label" : "dobj" }, { "token_id" : 4, "label" : "aux" }, { "token_id" : 5, "label" : "punct" } ], "attributes" : { } }, { "id" : 4, "form" : "��", "kana" : "�N", "lemma" : "��", "pos" : "�����ڔ���", "features" : [ "�I�~" ], "attributes" : { } }, { "id" : 5, "form" : "�B", "kana" : "", "lemma" : "�B", "pos" : "��_", "features" : [ ], "attributes" : { } } ] } ], "status" : 0, "message" : "" }
�o�͌��ʂ����ɂ������߁A�������₷�����Ă݂܂��B
��͌��ʂ̊m�F
�u���͕����B�v�͈Ӗ��I�Ɂu���́v�Ɓu�����B�v��ɕ������邱�Ƃ��ł��܂��B
"id"��2��ޏo�Ă��Ă���A�W������������ɂ������Ǝv���܂��̂ŁA�F�Â��Ă��܂��B
�iid=1�������������A���ɂ�����������܂��j
�[�u���́v�[
"��"��"��"�F���Ə����̊W�����Ď��܂��B
{ "chunk_info" : { "id" : 0, "head" : 1, "dep" : "D", "chunk_head" : 1, "chunk_func" : 2, "links" : [ ] }, "tokens" : [ { "id" : 0, "form" : "", "kana" : "", "lemma" : "", "pos" : "Undef", "features" : [ ], "attributes" : { } }
{ "id" : 1, "form" : "��", "kana" : "�C�k", "lemma" : "��", "pos" : "����", "features" : [ ], "dependency_labels" : [ { "token_id" : 0, "label" : "dep" }, { "token_id" : 2, "label" : "case" } ], "attributes" : { } }
{ "id" : 2, "form" : "��", "kana" : "�n", "lemma" : "��", "pos" : "�A�p����", "features" : [ ], "attributes" : { } } ] }
"��"��"��"�F���Ə����̊W�����Ď��܂��B
{ "chunk_info" : { "id" : 0, "head" : 1, "dep" : "D", "chunk_head" : 1, "chunk_func" : 2, "links" : [ ] }, "tokens" : [ { "id" : 0, "form" : "", "kana" : "", "lemma" : "", "pos" : "Undef", "features" : [ ], "attributes" : { } }
{ "id" : 1, "form" : "��", "kana" : "�C�k", "lemma" : "��", "pos" : "����", "features" : [ ], "dependency_labels" : [ { "token_id" : 0, "label" : "dep" }, { "token_id" : 2, "label" : "case" } ], "attributes" : { } }
{ "id" : 2, "form" : "��", "kana" : "�n", "lemma" : "��", "pos" : "�A�p����", "features" : [ ], "attributes" : { } } ] }
�[�u�����B�v�[
"��"��"��"�F�u�����v�͓����̊��p�n�̂��߁A���̂悤�ɕ������ĕ\������܂��B
�܂��A���̕��߂́u���́v�ɌW��܂��B
{ "chunk_info" : { "id" : 1, "head" : -1, "dep" : "O", "chunk_head" : 0, "chunk_func" : 1, "links" : [ { "link" : 0, "label" : "object" } ], "predicate" : [ ] }
{ "id" : 3, "form" : "��", "kana" : "�A��", "lemma" : "����", "pos" : "�����ꊲ", "features" : [ "K" ], "dependency_labels" : [ { "token_id" : 1, "label" : "dobj" }, { "token_id" : 4, "label" : "aux" }, { "token_id" : 5, "label" : "punct" } ], "attributes" : { } }
{ "id" : 4, "form" : "��", "kana" : "�N", "lemma" : "��", "pos" : "�����ڔ���", "features" : [ "�I�~" ], "attributes" : { } }
{ "id" : 5, "form" : "�B", "kana" : "", "lemma" : "�B", "pos" : "��_", "features" : [ ], "attributes" : { } } ] } ], "status" : 0, "message" : "" }
"��"��"��"�F�u�����v�͓����̊��p�n�̂��߁A���̂悤�ɕ������ĕ\������܂��B
�܂��A���̕��߂́u���́v�ɌW��܂��B
{ "chunk_info" : { "id" : 1, "head" : -1, "dep" : "O", "chunk_head" : 0, "chunk_func" : 1, "links" : [ { "link" : 0, "label" : "object" } ], "predicate" : [ ] }
{ "id" : 3, "form" : "��", "kana" : "�A��", "lemma" : "����", "pos" : "�����ꊲ", "features" : [ "K" ], "dependency_labels" : [ { "token_id" : 1, "label" : "dobj" }, { "token_id" : 4, "label" : "aux" }, { "token_id" : 5, "label" : "punct" } ], "attributes" : { } }
{ "id" : 4, "form" : "��", "kana" : "�N", "lemma" : "��", "pos" : "�����ڔ���", "features" : [ "�I�~" ], "attributes" : { } }
{ "id" : 5, "form" : "�B", "kana" : "", "lemma" : "�B", "pos" : "��_", "features" : [ ], "attributes" : { } } ] } ], "status" : 0, "message" : "" }
�����Əڂ����m�肽���ꍇ�́A�����������m�F���������B
���R���ꏈ���̐����͂܂��A�ʓr���{�������Ǝv���܂��B
---
�y�֘A�L���z
�E���R���ꏈ���iCOTOHA�j�̂��Љ�
---
�y�X�V�����z
181203�F�����쐬
2018�N11��18��
���R���ꏈ���iCOTOHA API�j�̂��Љ�
COTOHA
�T�v
NTT Communications�����N������Ă��鎩�R���ꏈ����API�ł��i��������Q���j�B
�ȒP�ɐ�������ƁA���{��̕��͂���͂��āA���̌�̃f�[�^���͂ɉ��p�ł���悤�ɂ���f�[�^�̏������@����Ă���Ă�����̂ł��B
���p���p�ɂ́A�g�p�����|����܂����A�J���ړI�ŗ��p���镪�ɂ͗����͂�����Ȃ��ł��i���p�\�ȋ@�\�ɐ����͂���܂����j�B
���{��̎��R���ꏈ���́A�p��Ɣ�ׂ�ƒP�ꂲ�ƂɃX�y�[�X�����炸�A�P�ꂲ�Ƃɋ�邱�Ƃ��ۑ�ƂȂ��Ă��܂����B���̍ۂɁA�������Ƃ̂Ȃ�����u�����v��p���āA�P��ɋ���Ă��܂��B
����COTOHA�ł́A���{��ɓ������������𗘗p���邱�ƂŁA��萸�x�悭���R�Ȍ`�Ŏ��R���ꏈ�����ł���悤�ɂȂ��Ă���悤�ł��B
���ۂɎg���Ă݂�
�܂��A������̌����T�C�g�œo�^������K�v������܂��B
��̓f��
��͂����ۂ̃f����ł��B
��͂��镶����Ƃ��āA�u�Ӗ�����͂���v�𗘗p���Ă��܂��B
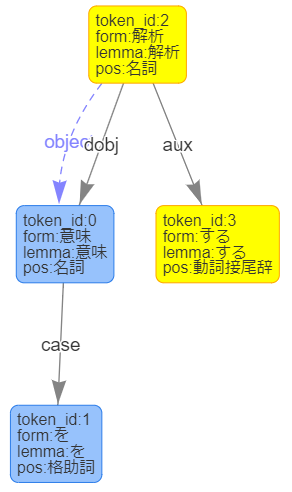
�Eaux�F����/�`�e���̂������̂��́B
�Edobj�F�ړI�i�ŏq��ɌW�閼����B
�Ecase�F�����ɂ��i�̕\���B
���R����������ɂ�
�Z�v���O���~���O����������Ƃ�������Ȃ�A��x�͕��������Ƃ͂���ł��낤�I���C���[�̖{�B
 | �[��������Deep Learning 2 ���R���ꏈ���� [ �֓� �N�B ] ���i:3,888�~ |
---
�y�֘A�L���z
�ECOTOHA���g���Ă݂� �[�\����� v1�[
---
�y�X�V�����z
181118�F�����쐬
190103�F�֘A�L���lj�
�^�O�F���ꏈ��
2018�N10��21��
SQLite �g����
SQLite�ɂ���
�T�v
SQLite�̓p�u���b�N�h���C���̃����[�V���i���f�[�^�x�[�X�iRelational Database Management System�j�ł��B
�y���Ȃ��߁A�A�v���P�[�V������T�[�o�[�ɑg�ݍ��܂�ė��p���邱�Ƃ��ł��܂��B
Android Studio �ł����p���邱�Ƃ��ł��A�ȒP�Ȏg�����́A�������ɂ܂Ƃ߂Ă��܂��B
Python�ł��p�b�P�[�W���p�ӂ���Ă���A�����̃v���O��������ŗ��p���邱�Ƃ��ł��܂��B
�_�E�����[�h
�����T�C�g����A�e�험�p�p�r�Ń_�E�����[�h���邱�Ƃ��\�ł��B
�ȒP�Ȏg����
�Z Linux �R�}���h�ŊȒP�ɐ������܂��B
1. �f�[�^�x�[�X���쐬����B
�@sqlite3 sample.sqlite3
�@�usample.sqlite3�v�Ƃ����f�[�^�x�[�X���쐬����܂��B
2. �f�[�^�x�[�X�ɃA�N�Z�X����B
�@sqlite3 sample.sqlite3
�@�菇1�ō쐬�����usample.sqlite3�v�ɃA�N�Z�X�ł��܂��B
�[2-1. �e�[�u�����쐬����B
�@�@�@CREATE TABLE table_sample(col1, col2,...);
�@�@�@�f�[�^�x�[�X�ɃA�N�Z�X������ԂŁA���̃R�}���h��ł��ƂŃe�[�u�����쐬���邱�Ƃ��ł��܂��B
�@�@�@�e�[�u���̗�Ƀf�[�^�^��t�^���邱�Ƃ��ł��܂��B
�@�@�@CREATE TABLE table_sample(col1 text, col2 integer,...);
�[2-2. �e�[�u���ꗗ���m�F����B
�@�@�@.tables
�@�@�@�e�[�u���ꗗ���m�F�ł��܂��B
�[2-3. �e�[�u���̒��g���m�F����B
�@�@�@SELECT * FROM table_sample;
�@�@�@�e�[�u���̑S�v�f���m�F�ł��܂��B
�@�@�@.header on
�@�@�@�Ƃ��邱�ƂŁA�e�[�u���𒆐g���m�F����ۂɃJ���������\������܂��B
�[2-4. �e�[�u�����폜����B
�@�@�@DROP TABLE sample_table;
�[2-5. �e�[�u���ɗv�f��lj�����B
�@�@�@INSERT INTO sample_table values("test",10,...);
�[2-6. �e�[�u���̗v�f���폜����B
�@�@�@DELETE FROM sample_table WHERE col2 > 1;
�@�@�@���̂悤�ɗv�f���w�肷�邱�ƂŁA����̃f�[�^���폜���邱�Ƃ��ł��܂��B
3. �f�[�^�x�[�X���폜����B
�@�usample.sqlite3�v��rm�ō폜���邱�ƂŁA�폜����܂��B
---
�y�֘A�L���z
�E
---
�y�X�V�����z
181021�F�����쐬
 | Introducing SQLite for Mobile Developers�y�d�q���Ёz[ Jesse Feiler ] ���i:2,495�~ |