

新規記事の投稿を行うことで、非表示にすることが可能です。
2023年03月01日
32bitの方が64bitより高速で精度がよい
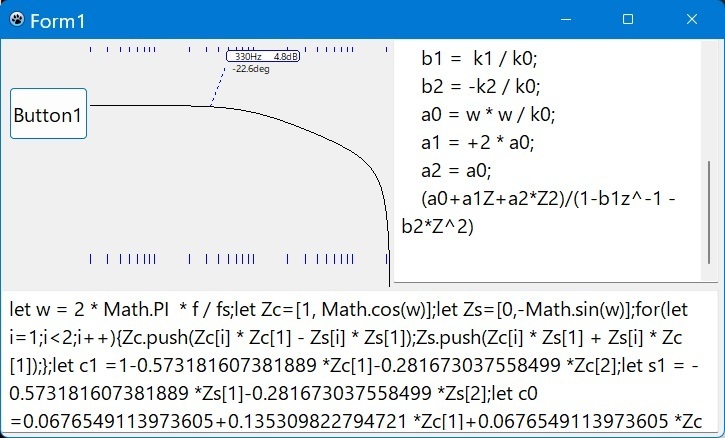
SIMDでD[i]:=D[i] + coff*S[i]を計算するのはだいたい終わって、
SIMDでΣai*biの計算を作ってる。
それで面白い事に気づいた。
SIMDを使わないLazarusの計算結果は32bitLazarusの方が早いのだ。しかもΣai*biに限れば Lazarusは単精度のままでも非常に精度がよい。
違いが出るのはWin64では浮動小数点にFPU(x87)を使わない事にある。
FPUを使うと変数は単精度でも内部での処理は常に80bitになる。
Win64ではSSE命令で処理するから単精度の積和は精度が悪い。
もっとも遅いのはLazarusのコンパイラがSSEを使っても並列化をしてくれない事にある。
結果、現在作成中のAVXのΣai*biの計算では1桁もの差が出る。
SIMDでΣai*biの計算を作ってる。
それで面白い事に気づいた。
SIMDを使わないLazarusの計算結果は32bitLazarusの方が早いのだ。しかもΣai*biに限れば Lazarusは単精度のままでも非常に精度がよい。
違いが出るのはWin64では浮動小数点にFPU(x87)を使わない事にある。
FPUを使うと変数は単精度でも内部での処理は常に80bitになる。
Win64ではSSE命令で処理するから単精度の積和は精度が悪い。
もっとも遅いのはLazarusのコンパイラがSSEを使っても並列化をしてくれない事にある。
結果、現在作成中のAVXのΣai*biの計算では1桁もの差が出る。