新規記事の投稿を行うことで、非表示にすることが可能です。
2020年08月19日
東海東京フィナンシャル・ホールディングス(8616)の株主優待のカタログの品が到着
東海東京フィナンシャル・ホールディングス(8616)の株主優待のカタログで注文した品が到着しました。3,000株だったのでカタログから2品選べます。今回は「ヱビスビール」と「湯布院 風曜日 ジャムセット」を選びました。
ヱビスビールは350ml×6本+250ml×2本です。

うちは私も妻も飲みますので、この量なら1日で終わります。“YEBISU”の文字が存在感ありますねー。

ジャムセットは3つです。


ピンク色で「湯布院 風曜日」と金文字のとてもかわいい箱に入っています。ギフトにいいですね。大分県産のものでつくったジャムのようです(ゆずは宮崎県産も入っていました)。

東海東京フィナンシャル・ホールディングスは、権利確定日は3月末、1,000株で2,000円相当を1品、3,000株で2品になります。カタログは18個のギフトがありました。カタログ到着は6月26日でした。7月5日に返送し、8月19日に到着しました。
ヱビスビールは350ml×6本+250ml×2本です。

うちは私も妻も飲みますので、この量なら1日で終わります。“YEBISU”の文字が存在感ありますねー。
 | エビスビール ギフトセット YE2DS エビス ビール 送料無料 送料込 御中元 お中元 父の日 お歳暮 御年賀 ギフト ビール缶セット ビールギフト 価格:2,544円 |
ジャムセットは3つです。


ピンク色で「湯布院 風曜日」と金文字のとてもかわいい箱に入っています。ギフトにいいですね。大分県産のものでつくったジャムのようです(ゆずは宮崎県産も入っていました)。
 | 価格:3,024円 |
東海東京フィナンシャル・ホールディングスは、権利確定日は3月末、1,000株で2,000円相当を1品、3,000株で2品になります。カタログは18個のギフトがありました。カタログ到着は6月26日でした。7月5日に返送し、8月19日に到着しました。
【Pythonで株価予測 (3)】株式分割・併合データの適用
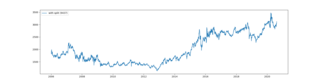
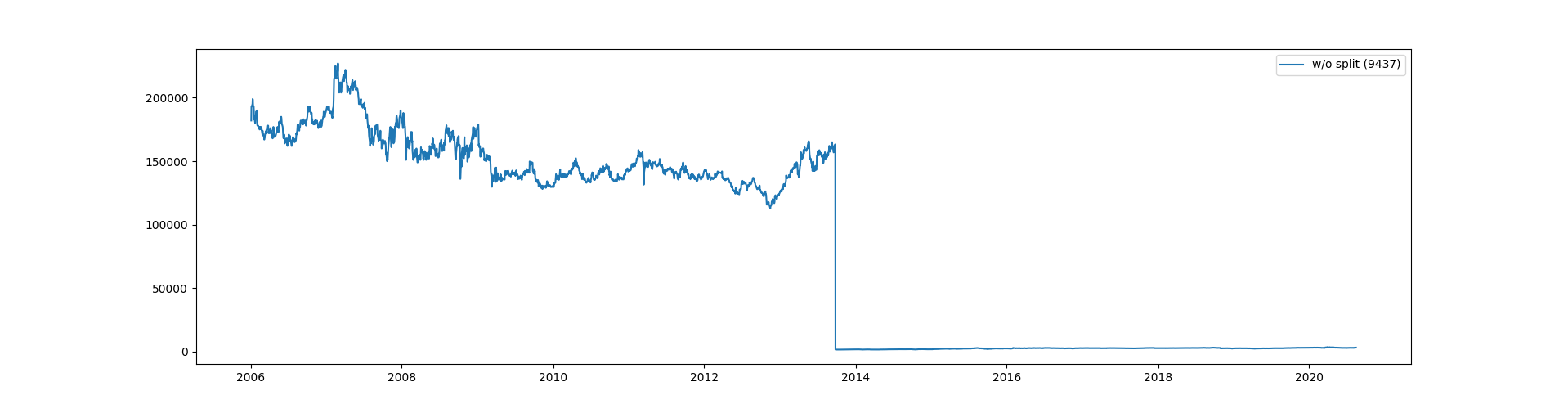
株価予測プログラムの続きです。株価予測プログラム(1)でProphetに株価を渡しますが、持っているデータが分割・併合の修正がされていないものでした。例えばNTTドコモ(9437)ですと、そのままプロットすると以下のようになります。

NTTドコモは2013年9月26日から1:100の分割がされています。


これでは予測ができませんので修正を施します。株価の分割・併合データの取得は株価予測プログラム(2) 株式分割・併合情報データの作成で作成したものです。これを読み込み、必要な株価コードの部分を探して分割前の日までを分割(この場合は100)で割ります。
これでプロットした図は次のようになります。
うまくいきましたので、これで予測に適用できそうです。ここしばらくは長期的に株価が上がっていますね。
↓こちらの本を参照しています。SciPy, NumPy, Pandasなど、一通りの照会がなされていて便利です。

NTTドコモは2013年9月26日から1:100の分割がされています。
これでは予測ができませんので修正を施します。株価の分割・併合データの取得は株価予測プログラム(2) 株式分割・併合情報データの作成で作成したものです。これを読み込み、必要な株価コードの部分を探して分割前の日までを分割(この場合は100)で割ります。
import sys
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
# 分割・併合データの読み込み
bunkatsu_data = pd.read_csv('bunkatsu.dat', sep=' ', names=['code', 'ds', 'ratio'])
bunkatsu_data['ds'] = bunkatsu_data['ds'].str.replace('/', '-')
# 株価の読み取り
code = 9437 # 株価コード
str_code = str(code)
filename = str_code + '_1'
read_data = pd.read_csv(filename, sep=' ', \
names=['ds', 'hajime', 'takane', 'yasune', 'y', 'dekidaka', 'NaN'])
analysis_data = read_data.loc[:, ['y', 'ds']]
analysis_data['ds'] = analysis_data['ds'].str.replace('/', '-')
# 株価コードの分割データのみ取り出す
bunkatsu_data = bunkatsu_data[bunkatsu_data['code'] == code].reset_index(drop=True)
# 分割データの適用
for i in range(len(bunkatsu_data)):
date = [int(s) for s in bunkatsu_data.at[i, 'ds'].split('-')] # 分割日
analysis_data.loc[pd.to_datetime(analysis_data['ds']) <= dt.datetime(date[0], date[1], date[2]), 'y'] \
= analysis_data['y'] / bunkatsu_data.at[i, 'ratio']
# プロット
x = pd.to_datetime(analysis_data['ds'])
fig = plt.figure(figsize=(20,5))
plt.plot(x, analysis_data['y'][:],label='with split ('+str_code+')')
plt.legend()
plt.show()
fig.savefig(str_code + '.png')
これでプロットした図は次のようになります。
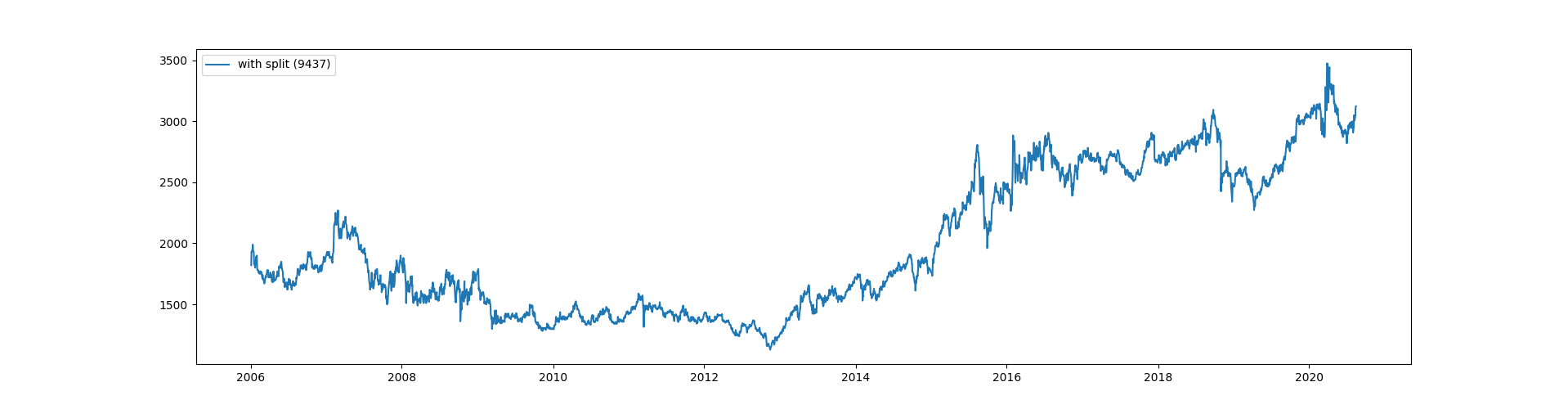
うまくいきましたので、これで予測に適用できそうです。ここしばらくは長期的に株価が上がっていますね。
↓こちらの本を参照しています。SciPy, NumPy, Pandasなど、一通りの照会がなされていて便利です。
 | 科学技術計算のためのPython入門ーー開発基礎,必須ライブラリ,高速化【電子書籍】[ 中久喜健司 ] 価格:3,520円 |






