新規記事の投稿を行うことで、非表示にすることが可能です。
2020年04月26日
2020年04月19日
Speech to Text(IBM Watson)
・音声認識のAPI
・制限内ならば、無料で使える(公式)
デモ例(日本語)
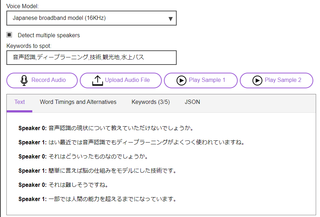
ラジオ音声読ませるとこんな感じ。
Speaker 1: うんうんうん凄いなあ。
Speaker 1: 凄い本当にいろいろ一人一人ずつ読んだら。
Speaker 1: どこまでいかんだろうなって思ってね知らない人でも。
Speaker 0: うんうんうん。
Speaker 0: そうなんか振り返って休みしてそうではそのメンバーそんなことない。
Speaker 1: 嘘を。
Speaker 3: つけそう。
Speaker 0: そんなことがいい使って先に出るってことできんの。
Speaker 1: そう。
Speaker 0: そうそうできできずにできるどうやって。
Speaker 0: うん。
Speaker 3: そろそろもうなんです。
Speaker 1: ためのかもちょっとうん。
Speaker 3: 求めて。
Speaker 0: 次の飲み会のといったところで。
Speaker 3: そろそろ男連れ普通に。
話者2人の内容だが、4人いる扱いになったり、日本語的におかしいところもあるが、
おおむね音声認識としてはできている印象。
複数人の会話も話者特定をできるとは、Watsonおそるべし。。。
・制限内ならば、無料で使える(公式)
デモ例(日本語)
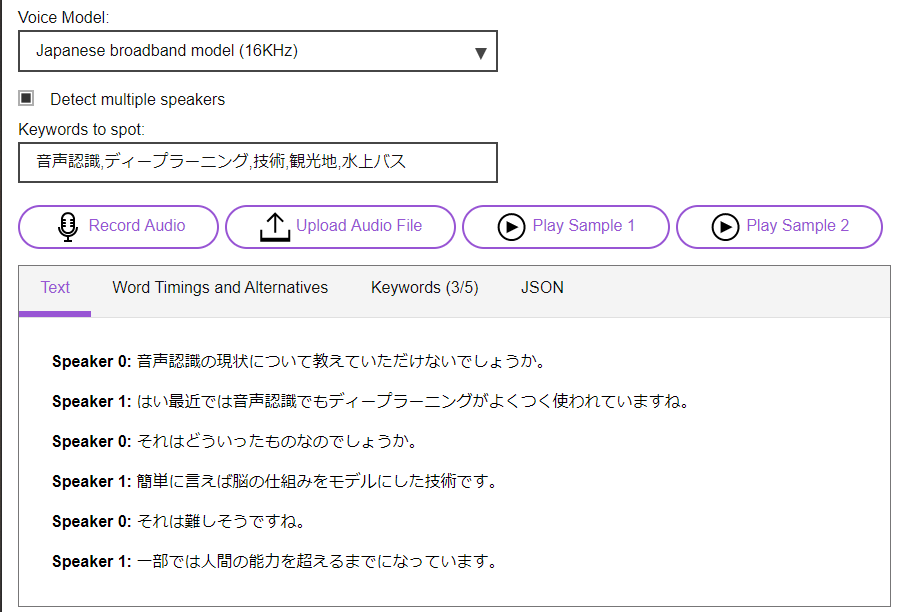
ラジオ音声読ませるとこんな感じ。
Speaker 1: うんうんうん凄いなあ。
Speaker 1: 凄い本当にいろいろ一人一人ずつ読んだら。
Speaker 1: どこまでいかんだろうなって思ってね知らない人でも。
Speaker 0: うんうんうん。
Speaker 0: そうなんか振り返って休みしてそうではそのメンバーそんなことない。
Speaker 1: 嘘を。
Speaker 3: つけそう。
Speaker 0: そんなことがいい使って先に出るってことできんの。
Speaker 1: そう。
Speaker 0: そうそうできできずにできるどうやって。
Speaker 0: うん。
Speaker 3: そろそろもうなんです。
Speaker 1: ためのかもちょっとうん。
Speaker 3: 求めて。
Speaker 0: 次の飲み会のといったところで。
Speaker 3: そろそろ男連れ普通に。
話者2人の内容だが、4人いる扱いになったり、日本語的におかしいところもあるが、
おおむね音声認識としてはできている印象。
複数人の会話も話者特定をできるとは、Watsonおそるべし。。。
2019年01月27日
自然言語処理(COTOHA API)のアップデート(2019.01.15〜)
COTOHA
追加項目
NTTコミュニケーションズで紹介されているように、COTOHA APIに機能が追加されました。(公式サイト)
追加された項目は、次の4項目です。
2つは、音声認識システムへの導入を強く意識している機能に思えます。
残り2つは汎用的な機能と思います。
アレクサなど音声認識アプリケーション開発にも、応用が効いてくると思います。
1. 言い淀み除去(β版)
言葉が詰まって出てこない際に、発話する「ええと」や「あのう」といった表現を除去できる機能です。
入力した文字列から言い淀み表現が除去されます。
例えば、「ええと、明日の天気は晴れです。」と入力した場合、「ええと、」が言い淀み表現として検出することが可能となる機能です。
2. 音声認識誤り検知(β版)
音声認識したテキストデータに認識ミスがあるかを検出・抽出することができる機能です。
認識ミスと思われる単語を出力してくれる機能です。
今後、音声認識誤り訂正のAPIが追加予定ということなので、自動検出+自動訂正も一括で行うことが可能となるかもしれません。
3. 感情分析(正式版)
こちらは、正式版となった機能です。文章が表現している感情を「ポジティブ」「ネガティブ」と判定することができます。yahooのリアルタイム検索の画面で、感情判定をご覧になったことがある方もいると思います。
例えば、製品などのレビュー解析への応用が効くように思います。ユーザが何に不満を持っているか、何に利点を感じたかを自動的に解析できえます。
4. 照応解析(正式版)
いわゆる「こそあど言葉」のような指示語の検知と、それらの対象を特定することができます。
β版から正式版になったことで、複数形や複数単語にも対応可能になったようです。
リファレンスに例があるように、「太郎は友人です。彼はステーキを食べた。」という文を入力することで、「太郎=彼」と判定することが可能です。
終わりに
今回のアップデートで「音声認識」関連のAPIが追加され、音声認識の精度向上に力を入れていることが感じられます。Youtubeでも字幕表示がされますが、精度としては未だに見るに堪えない内容で、日本語の音声認識の難しさを感じてしまいます。
COTOHA APIの性能向上には期待をする限りです。
照応解析などを学ぶならば、このような本もおすすめです。
---
【関連記事】
・自然言語処理(COTOHA API)のご紹介
---
【更新履歴】
190127:新規作成
---
2018年12月03日
COTOHAを使ってみる ー構文解析 v1ー
構文解析 v1
概要
NTT Communicationsが今年から提供している自然言語処理のAPIです(こちらを参照)。
導入の簡単な説明は、こちらの記事から。
構文解析を使ってみる
サンプル文を適用してみましょう。
【入力文】
犬は歩く。
【入力コマンド】
curl -X POST -H "Content-Type:application/json" -H "charset:UTF-8" -H "Authorization:Bearer [Access Token]" -d '{"sentence":"犬は歩く。","type": "default"}' "https://[API Base URL]/parse"
【出力】
{ "result" : [ { "chunk_info" : { "id" : 0, "head" : 1, "dep" : "D", "chunk_head" : 1, "chunk_func" : 2, "links" : [ ] }, "tokens" : [ { "id" : 0, "form" : "", "kana" : "", "lemma" : "", "pos" : "Undef", "features" : [ ], "attributes" : { } }, { "id" : 1, "form" : "犬", "kana" : "イヌ", "lemma" : "犬", "pos" : "名詞", "features" : [ ], "dependency_labels" : [ { "token_id" : 0, "label" : "dep" }, { "token_id" : 2, "label" : "case" } ], "attributes" : { } }, { "id" : 2, "form" : "は", "kana" : "ハ", "lemma" : "は", "pos" : "連用助詞", "features" : [ ], "attributes" : { } } ] }, { "chunk_info" : { "id" : 1, "head" : -1, "dep" : "O", "chunk_head" : 0, "chunk_func" : 1, "links" : [ { "link" : 0, "label" : "object" } ], "predicate" : [ ] }, "tokens" : [ { "id" : 3, "form" : "歩", "kana" : "アル", "lemma" : "歩く", "pos" : "動詞語幹", "features" : [ "K" ], "dependency_labels" : [ { "token_id" : 1, "label" : "dobj" }, { "token_id" : 4, "label" : "aux" }, { "token_id" : 5, "label" : "punct" } ], "attributes" : { } }, { "id" : 4, "form" : "く", "kana" : "ク", "lemma" : "く", "pos" : "動詞接尾辞", "features" : [ "終止" ], "attributes" : { } }, { "id" : 5, "form" : "。", "kana" : "", "lemma" : "。", "pos" : "句点", "features" : [ ], "attributes" : { } } ] } ], "status" : 0, "message" : "" }
出力結果が見にくいため、少し見やすくしてみます。
解析結果の確認
「犬は歩く。」は意味的に「犬は」と「歩く。」二つに分解することができます。
"id"が2種類出てきており、係り方が少し見にくいかと思いますので、色づけています。
(id=1が少し見分け就きにくいかもしれませんが)
ー「犬は」ー
"犬"→"は":主語と助詞の関係が見て取れます。
{ "chunk_info" : { "id" : 0, "head" : 1, "dep" : "D", "chunk_head" : 1, "chunk_func" : 2, "links" : [ ] }, "tokens" : [ { "id" : 0, "form" : "", "kana" : "", "lemma" : "", "pos" : "Undef", "features" : [ ], "attributes" : { } }
{ "id" : 1, "form" : "犬", "kana" : "イヌ", "lemma" : "犬", "pos" : "名詞", "features" : [ ], "dependency_labels" : [ { "token_id" : 0, "label" : "dep" }, { "token_id" : 2, "label" : "case" } ], "attributes" : { } }
{ "id" : 2, "form" : "は", "kana" : "ハ", "lemma" : "は", "pos" : "連用助詞", "features" : [ ], "attributes" : { } } ] }
"犬"→"は":主語と助詞の関係が見て取れます。
{ "chunk_info" : { "id" : 0, "head" : 1, "dep" : "D", "chunk_head" : 1, "chunk_func" : 2, "links" : [ ] }, "tokens" : [ { "id" : 0, "form" : "", "kana" : "", "lemma" : "", "pos" : "Undef", "features" : [ ], "attributes" : { } }
{ "id" : 1, "form" : "犬", "kana" : "イヌ", "lemma" : "犬", "pos" : "名詞", "features" : [ ], "dependency_labels" : [ { "token_id" : 0, "label" : "dep" }, { "token_id" : 2, "label" : "case" } ], "attributes" : { } }
{ "id" : 2, "form" : "は", "kana" : "ハ", "lemma" : "は", "pos" : "連用助詞", "features" : [ ], "attributes" : { } } ] }
ー「歩く。」ー
"歩"→"く":「歩く」は動詞の活用系のため、このように分解して表現されます。
また、この文節は「犬は」に係ります。
{ "chunk_info" : { "id" : 1, "head" : -1, "dep" : "O", "chunk_head" : 0, "chunk_func" : 1, "links" : [ { "link" : 0, "label" : "object" } ], "predicate" : [ ] }
{ "id" : 3, "form" : "歩", "kana" : "アル", "lemma" : "歩く", "pos" : "動詞語幹", "features" : [ "K" ], "dependency_labels" : [ { "token_id" : 1, "label" : "dobj" }, { "token_id" : 4, "label" : "aux" }, { "token_id" : 5, "label" : "punct" } ], "attributes" : { } }
{ "id" : 4, "form" : "く", "kana" : "ク", "lemma" : "く", "pos" : "動詞接尾辞", "features" : [ "終止" ], "attributes" : { } }
{ "id" : 5, "form" : "。", "kana" : "", "lemma" : "。", "pos" : "句点", "features" : [ ], "attributes" : { } } ] } ], "status" : 0, "message" : "" }
"歩"→"く":「歩く」は動詞の活用系のため、このように分解して表現されます。
また、この文節は「犬は」に係ります。
{ "chunk_info" : { "id" : 1, "head" : -1, "dep" : "O", "chunk_head" : 0, "chunk_func" : 1, "links" : [ { "link" : 0, "label" : "object" } ], "predicate" : [ ] }
{ "id" : 3, "form" : "歩", "kana" : "アル", "lemma" : "歩く", "pos" : "動詞語幹", "features" : [ "K" ], "dependency_labels" : [ { "token_id" : 1, "label" : "dobj" }, { "token_id" : 4, "label" : "aux" }, { "token_id" : 5, "label" : "punct" } ], "attributes" : { } }
{ "id" : 4, "form" : "く", "kana" : "ク", "lemma" : "く", "pos" : "動詞接尾辞", "features" : [ "終止" ], "attributes" : { } }
{ "id" : 5, "form" : "。", "kana" : "", "lemma" : "。", "pos" : "句点", "features" : [ ], "attributes" : { } } ] } ], "status" : 0, "message" : "" }
もっと詳しく知りたい場合は、こちらをご確認ください。
自然言語処理の説明はまた、別途実施したいと思います。
---
【関連記事】
・自然言語処理(COTOHA)のご紹介
---
【更新履歴】
181203:初期作成
2018年11月18日
自然言語処理(COTOHA API)のご紹介
COTOHA
概要
NTT Communicationsが今年から提供している自然言語処理のAPIです(こちらを参照)。
簡単に説明すると、日本語の文章を解析して、その後のデータ分析に応用できるようにするデータの処理方法を提供してくれているものです。
商用利用には、使用料が掛かりますが、開発目的で利用する分には料金はかからないです(利用可能な機能に制限はありますが)。
日本語の自然言語処理は、英語と比べると単語ごとにスペースが入らず、単語ごとに区切ることが課題となっていました。その際に、文字ごとのつながりを「辞書」を用いて、単語に区切っています。
このCOTOHAでは、日本語に特化した辞書を利用することで、より精度よく自然な形で自然言語処理ができるようになっているようです。
実際に使ってみる
まず、こちらの公式サイトで登録をする必要があります。
解析デモ
解析した際のデモ例です。
解析する文字列として、「意味を解析する」を利用しています。
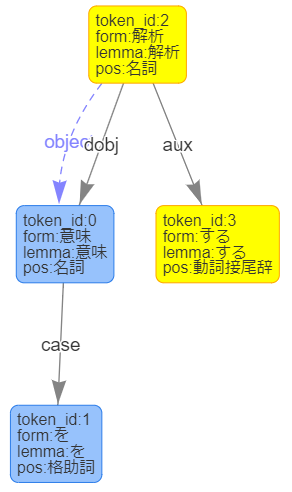
・aux:動詞/形容詞のうち非自立のもの。
・dobj:目的格で述語に係る名詞句。
・case:助詞による格の表示。
自然言語を勉強するには
〇プログラミングを勉強したことがある方なら、一度は聞いたことはあるであろうオライリーの本。
 | ゼロから作るDeep Learning 2 自然言語処理編 [ 斎藤 康毅 ] 価格:3,888円 |
---
【関連記事】
・COTOHAを使ってみる ー構文解析 v1ー
---
【更新履歴】
181118:初期作成
190103:関連記事追加
タグ:言語処理