新規記事の投稿を行うことで、非表示にすることが可能です。
2020年08月19日
【Pythonで株価予測 (3)】株式分割・併合データの適用
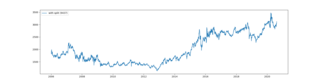
株価予測プログラムの続きです。株価予測プログラム(1)でProphetに株価を渡しますが、持っているデータが分割・併合の修正がされていないものでした。例えばNTTドコモ(9437)ですと、そのままプロットすると以下のようになります。

NTTドコモは2013年9月26日から1:100の分割がされています。


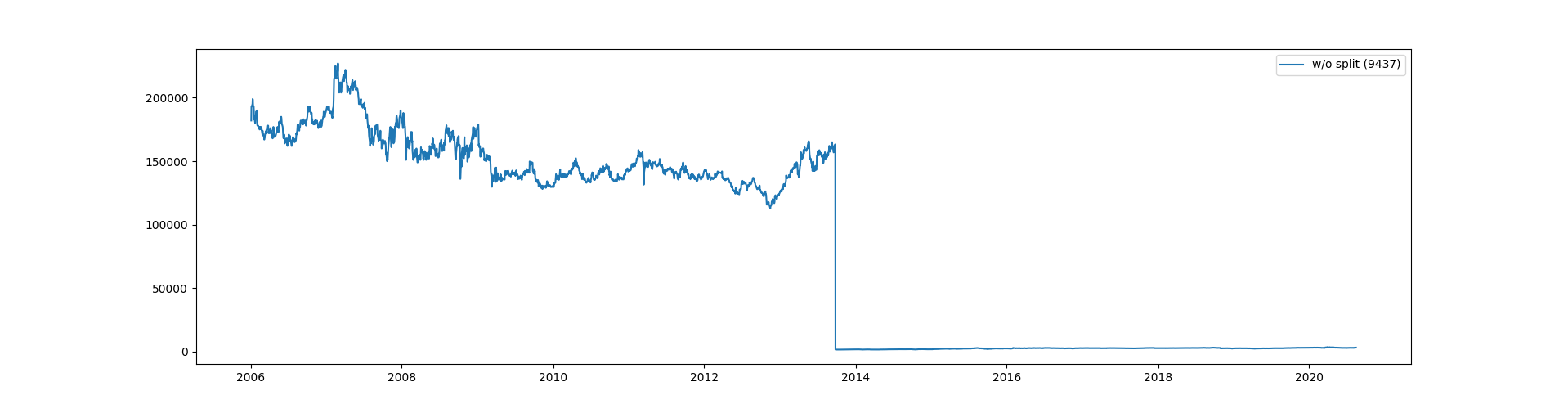
これでは予測ができませんので修正を施します。株価の分割・併合データの取得は株価予測プログラム(2) 株式分割・併合情報データの作成で作成したものです。これを読み込み、必要な株価コードの部分を探して分割前の日までを分割(この場合は100)で割ります。
これでプロットした図は次のようになります。
うまくいきましたので、これで予測に適用できそうです。ここしばらくは長期的に株価が上がっていますね。
↓こちらの本を参照しています。SciPy, NumPy, Pandasなど、一通りの照会がなされていて便利です。

NTTドコモは2013年9月26日から1:100の分割がされています。
これでは予測ができませんので修正を施します。株価の分割・併合データの取得は株価予測プログラム(2) 株式分割・併合情報データの作成で作成したものです。これを読み込み、必要な株価コードの部分を探して分割前の日までを分割(この場合は100)で割ります。
import sys
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
# 分割・併合データの読み込み
bunkatsu_data = pd.read_csv('bunkatsu.dat', sep=' ', names=['code', 'ds', 'ratio'])
bunkatsu_data['ds'] = bunkatsu_data['ds'].str.replace('/', '-')
# 株価の読み取り
code = 9437 # 株価コード
str_code = str(code)
filename = str_code + '_1'
read_data = pd.read_csv(filename, sep=' ', \
names=['ds', 'hajime', 'takane', 'yasune', 'y', 'dekidaka', 'NaN'])
analysis_data = read_data.loc[:, ['y', 'ds']]
analysis_data['ds'] = analysis_data['ds'].str.replace('/', '-')
# 株価コードの分割データのみ取り出す
bunkatsu_data = bunkatsu_data[bunkatsu_data['code'] == code].reset_index(drop=True)
# 分割データの適用
for i in range(len(bunkatsu_data)):
date = [int(s) for s in bunkatsu_data.at[i, 'ds'].split('-')] # 分割日
analysis_data.loc[pd.to_datetime(analysis_data['ds']) <= dt.datetime(date[0], date[1], date[2]), 'y'] \
= analysis_data['y'] / bunkatsu_data.at[i, 'ratio']
# プロット
x = pd.to_datetime(analysis_data['ds'])
fig = plt.figure(figsize=(20,5))
plt.plot(x, analysis_data['y'][:],label='with split ('+str_code+')')
plt.legend()
plt.show()
fig.savefig(str_code + '.png')
これでプロットした図は次のようになります。
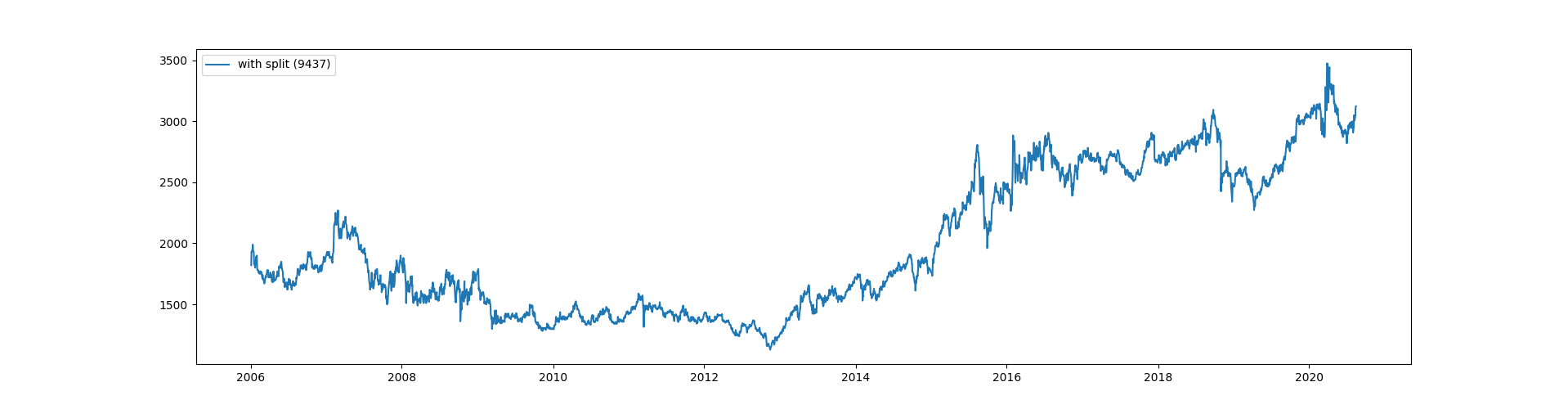
うまくいきましたので、これで予測に適用できそうです。ここしばらくは長期的に株価が上がっていますね。
↓こちらの本を参照しています。SciPy, NumPy, Pandasなど、一通りの照会がなされていて便利です。
 | 科学技術計算のためのPython入門ーー開発基礎,必須ライブラリ,高速化【電子書籍】[ 中久喜健司 ] 価格:3,520円 |
2020年08月15日
【Pythonで株価予測 (2)】株式分割・併合情報データの作成
つくり始めた株価予想プログラムで、私の持っている株価データは株式分割・併合が考慮されたものではありません。そこで、株式分割・併合のデータ作成のプログラムをつくります。
株式分割・併合のデータはカブドット・コムによいのがありました。(リンクは付けませんが、「株式分割 カブドットコム」とかで検索できます)
データ自体はJavascriptが走ってテーブルを作成するようですので、Pythonのrequestsではデータがとれませんでした。seleniumでソースを取得したいと思います。
tableタグのtbody内がデータですので、そこの各行からデータを取得します。分割は 1:3 のような形の場合は 3/1 = 3 というデータにしておきます。
あとは、併合も同様にして作っておけばよいですね。5株→1株なら0.2というデータになります。
処理時に上記ファイルを読み込んで、分割適用前までを分割数で割ればよいことになります。
 株価予測プログラム(2)
株価予測プログラム(2)
株式分割・併合のデータはカブドット・コムによいのがありました。(リンクは付けませんが、「株式分割 カブドットコム」とかで検索できます)
データ自体はJavascriptが走ってテーブルを作成するようですので、Pythonのrequestsではデータがとれませんでした。seleniumでソースを取得したいと思います。
#!/usr/bin/python3
import sys
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
options = webdriver.ChromeOptions()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
browser.get('上記、カブコムのURL')
http_src = browser.page_source
browser.quit()
tableタグのtbody内がデータですので、そこの各行からデータを取得します。分割は 1:3 のような形の場合は 3/1 = 3 というデータにしておきます。
rows = soup.find('tbody').find_all('tr')
f = open('bunkatsu.dat', mode='w')
for row in rows:
cols = row.find_all('td')
f.write(cols[1].text + ' ') # コード
f.write(cols[4].text + ' ') # 分割適用前の最終日
bunkatsu_data = cols[3].text.split(':')
f.write(str( float(bunkatsu_data[1])/float(bunkatsu_data[0]) ) + '\n') # 分割比
f.close()
あとは、併合も同様にして作っておけばよいですね。5株→1株なら0.2というデータになります。
処理時に上記ファイルを読み込んで、分割適用前までを分割数で割ればよいことになります。
 | 価格:4,070円 |
2020年08月11日
【Pythonで株価予測 (1)】Pythonの勉強がてら、株価予測プログラムを作ってみる
pythonは全く使っていませんが、さすがにそろそろ覚えないと色々と不都合が生じてきました。
そこで、pythonの勉強がてら、株価予想のプログラムを作ってみます。というか、色々なウェブサイトから引っ張ってきて、貼り付けているだけですが。
時系列予想のライブラリとしては、Prophetを使います。
持っているデータはこんな感じ。綜合警備保障(2331)です。
左から、日付、始値、高値、安値、終値、出来高です。最後に空白がはいっているため、pandasで読み込んだ際、NaNの列が出来てしまいます。使うのは日付と終値だけです。
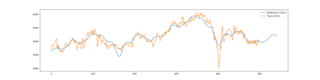
うーん、予想できているのか、いないのか。8月中はパッとしないが、9月から上がるのかな。
自分で作っているデータは出来高0の日は終値が0となっていたり(そんな銘柄は無視してもよいかとも思いますが)、株式分割・併合で不連続が生じてしまっていますので、それを修正する処理を今後加えたいと思います。




そこで、pythonの勉強がてら、株価予想のプログラムを作ってみます。というか、色々なウェブサイトから引っ張ってきて、貼り付けているだけですが。
時系列予想のライブラリとしては、Prophetを使います。
持っているデータはこんな感じ。綜合警備保障(2331)です。
2006/1/4 1810 1822 1806 1815 74000
2006/1/5 1830 1834 1810 1815 314000
2006/1/6 1845 1859 1835 1847 317900
:
2020/8/5 5010 5040 4970 5020 171600
2020/8/6 4970 5010 4940 4960 160600
2020/8/7 4975 5050 4975 5010 119500
左から、日付、始値、高値、安値、終値、出来高です。最後に空白がはいっているため、pandasで読み込んだ際、NaNの列が出来てしまいます。使うのは日付と終値だけです。
import os
import sys
import pandasas pd
from fbprophet import Prophet
import matplotlib.pyplotas plt
code = str(2331)
read_data = pd.read_csv('data/'+code, sep=' ', \
names=['ds', 'hajime', 'takane', 'yasune', 'y', 'dekidaka', 'NaN'])
# 直近500日ぐらいのデータを使用する
analysis_data = read_data.loc[:, ['y', 'ds']].iloc[-500:, :].reset_index()
analysis_data['ds'= analysis_data['ds'].str.replace('/', '-')
Maximum_value = analysis_data['y'].max()
analysis_data['cap'] = Maximum_value
model = Prophet(growth='logistic')
model.fit(analysis_data)
future = model.make_future_dataframe(periods=60, freq = 'd')
future['cap'] = Maximum_value
future = future[ future['ds'].dt.weekday < 5 ]
forecast = model.predict(future)
# 図を作成
fig = plt.figure(figsize=(20,5))
plt.plot(forecast['yhat'][:],label='Prediction ('+code+')')
plt.plot(analysis_data['y'][:],label='True ('+code+')')
plt.legend()
fig.savefig(code + '.png')
# 直近30日の平均株価に対し、予想値の上昇率を計算
Mean = analysis_data['y'].iloc[-30:].mean()
Fct_value = forecast['yhat'].iat[-1]
Rate = (Fct_value - Mean)/Mean*100
output_string = code+': ' \
+str(int(Mean))+' -> ' + str(int(Fct_value)) + ' (' + str(int(Rate)) + '%)'
if Rate > 10.0:
print('!!! ', output_string)
elif Rate > 5.0:
print('!! ', output_string)
else:
print(output_string)
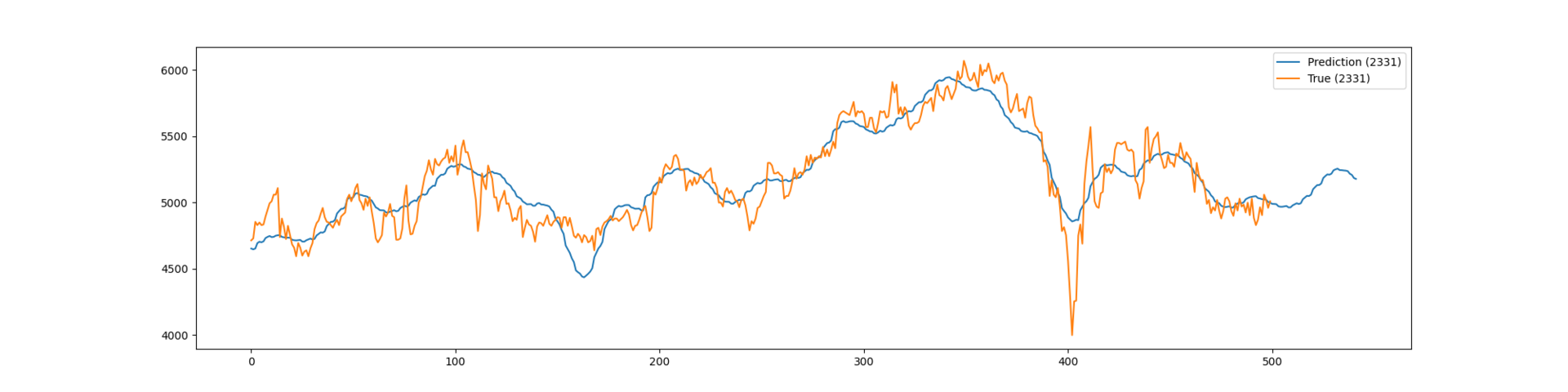
うーん、予想できているのか、いないのか。8月中はパッとしないが、9月から上がるのかな。
自分で作っているデータは出来高0の日は終値が0となっていたり(そんな銘柄は無視してもよいかとも思いますが)、株式分割・併合で不連続が生じてしまっていますので、それを修正する処理を今後加えたいと思います。






